") 數據準備指南:10種基礎特征工程方法的實戰(zhàn)教程
數據準備指南:10種基礎特征工程方法的實戰(zhàn)教程
來源:DeepHub IMBA
作者:Muhammad Ihsan
在數據分析和機器學習領域,從原始數據中提取有價值的信息是一個關鍵步驟。這個過程不僅有助于輔助決策,還能預測未來趨勢。為了實現這一目標,特征工程技術顯得尤為重要。
特征工程是將原始數據轉化為更具信息量的特征的過程。本文將詳細介紹十種基礎特征工程技術,包括其基本原理和實現示例。首先,我們需要導入必要的庫以確保代碼的正常運行。以下是本文中使用的主要庫:
import pandas as pd # 用于數據處理和操作
import numpy as np # 用于數值計算
import matplotlib.pyplot as plt # 用于數據可視化
import gensim.downloader as api # 用于下載gensim提供的語料庫
from gensim.models import Word2Vec # 用于詞嵌入
from sklearn.pipeline import Pipeline # 用于構建數據處理管道
from sklearn.decomposition import PCA # 用于主成分分析
from sklearn.datasets import load_iris # 用于加載iris數據集
from sklearn.impute import SimpleImputer # 用于數據插補
from sklearn.compose import ColumnTransformer # 用于對數據集應用轉換
from sklearn.feature_extraction.text import TfidfVectorizer # 用于TF-IDF實現
from sklearn.preprocessing import MinMaxScaler, StandardScaler # 用于數據縮放
1、數據插補
數據插補是處理缺失數據的重要技術,它通過用其他值替換缺失數據來完善數據集。在實際應用中,許多算法(如線性回歸和邏輯回歸)無法直接處理包含缺失值的數據集。因此我們通常有兩種選擇:
刪除包含缺失值的行或列
對缺失值進行插補
數據插補的方法多樣,包括:
使用常數值填充(如0、1、2等)
使用統計量填充(如均值或中位數)
使用相鄰數據值填充(如前值或后值)
構建預測模型估計缺失值
以下是一個數據插補的實現示例:
data = pd.DataFrame({
'doors': [2, np.nan, 2, np.nan, 4],
'topspeed': [100, np.nan, 150, 200, np.nan],
'model': ['Daihatsu', 'Toyota', 'Suzuki', 'BYD','Wuling']
})
doors_imputer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value=4))
])
topspeed_imputer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median'))
])
pipeline = ColumnTransformer(
transformers=[
('doors_imputer', doors_imputer, ['doors']),
('topspeed_imputer', topspeed_imputer, ['topspeed'])
],
remainder='passthrough'
)
transformed = pipeline.fit_transform(data)
transformed_df = pd.DataFrame(transformed, columns=['doors', 'topspeed', 'model'])
在這個例子中創(chuàng)建了一個包含汽車數據的DataFrame,其中doors和topspeed列存在缺失值。對于doors列,使用常數4進行填充(假設大多數汽車有4個門)。對于topspeed列,使用中位數進行填充。
下圖展示了插補前后的數據對比:
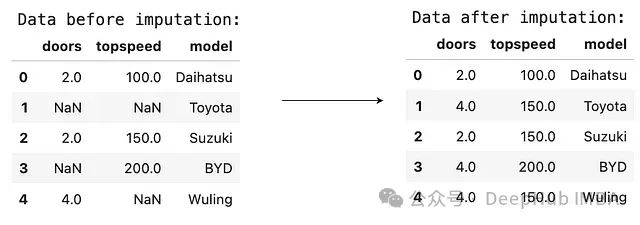
可以觀察到doors列的缺失值被填充為4,而topspeed列的缺失值被填充為數據的中位數。
2、數據分箱
數據分箱是將連續(xù)變量轉換為離散分類變量的技術。這種技術在日常生活中常被無意識地使用,例如將人按年齡段分類。數據分箱的主要目的包括:
- 簡化數據,將連續(xù)值轉換為離散類別
- 處理非線性關系
減少數據中的噪聲和異常值
以下是一個數據分箱的實現示例:
np.random.seed(42)
data = pd.DataFrame({'age' : np.random.randint(0, 100, 100)})
data['category'] = pd.cut(data['age'], [0, 2, 11, 18, 65, 101], labels=['infants', 'children', 'teenagers', 'adults', 'elders'])
print(data)
print(data['category'].value_counts())
data['category'].value_counts().plot(kind='bar')
在這個例子中,我們生成了100個0到100之間的隨機整數作為年齡數據,然后將其分為五個類別:嬰兒、兒童、青少年、成年人和老年人。以下是分箱結果的可視化:
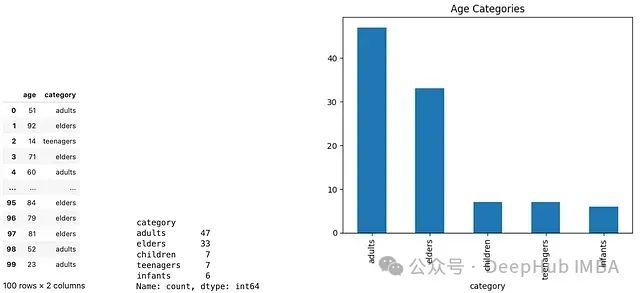
通過數據分箱,可以更直觀地理解數據的分布情況。在某些算法中,經過分箱處理的離散數據可能比原始的連續(xù)數據更有優(yōu)勢。
3、對數變換
對數變換是將特征值從x轉換為log(x)的技術。這種方法常用于處理高度偏斜的數據分布或存在大量異常值的情況。
對數變換在線性回歸和邏輯回歸等模型中特別有用,因為它可以將乘法關系轉換為加法關系,從而簡化模型。
以下是對數變換的實現示例:
rskew_data = np.random.exponential(scale=2, size=100)
log_data = np.log(rskew_data)
plt.title('Right Skewed Data')
plt.hist(rskew_data, bins=10)
plt.show()
plt.title('Log Transformed Data')
plt.hist(log_data, bins=20)
plt.show()
在這個例子中,生成了100個右偏的數據點,然后對其進行對數變換。下圖展示了變換前后的數據分布對比: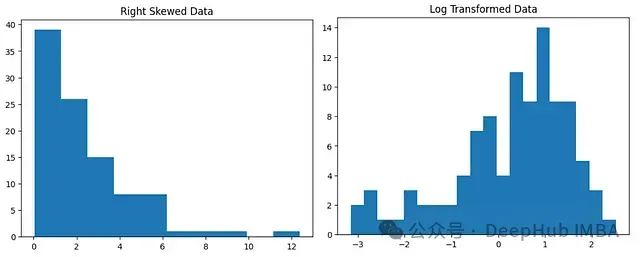
需要注意的是,對數變換并不會自動將數據分布變?yōu)檎龖B(tài)分布,它主要用于減少數據的偏度。
4、數據縮放
數據縮放是將數據調整到特定范圍或滿足特定條件的預處理技術。常見的縮放方法包括:
- 最小-最大縮放:將數據調整到[0, 1]區(qū)間
- 標準化:將數據調整為均值為0,標準差為1的分布
最小-最大縮放主要用于將數據歸一化到特定范圍,而標準化則考慮了數據的分布特征。以下是數據縮放的實現示例:
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
scaler = MinMaxScaler()
minmax = scaler.fit_transform(data)
scaler = StandardScaler()
standard = scaler.fit_transform(data)
df = pd.DataFrame({'original':data.flatten(),'Min-Max Scaling':minmax.flatten(),'Standard Scaling':standard.flatten()})
df
下圖展示了原始數據、最小-最大縮放后的數據和標準化后的數據的對比:
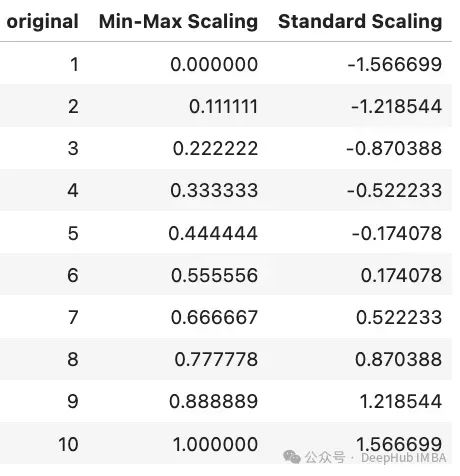
可以觀察到,最小-最大縮放將數據調整到[0, 1]區(qū)間,而標準化后的數據均值接近0,標準差接近1。
5、One-Hot編碼
One-Hot編碼是處理分類數據的常用方法,特別適用于那些沒有固有順序的名義變量。這種技術將每個分類變量轉換為一系列二進制特征。
One-Hot編碼的工作原理如下:
- 對于分類特征中的每個唯一值,創(chuàng)建一個新的二進制列。
在新創(chuàng)建的列中,如果原始數據中出現了相應的分類值,則標記為1,否則為0。
這種方法也被稱為虛擬編碼(dummy encoding)。
以下是One-Hot編碼的實現示例:
data = pd.DataFrame({'models':['toyota','ferrari','byd','lamborghini','honda','tesla'],
'speed':['slow','fast','medium','fast','slow','medium']})
data = pd.concat([data, pd.get_dummies(data['speed'], prefix='speed')],axis=1)
data
下圖展示了編碼后的結果:

'speed'列被轉換為三個新的二進制列:'speed_fast'、'speed_medium'和'speed_slow'。每行在這些新列中只有一個1,其余為0,對應原始的速度類別。
當分類變量的唯一值數量很大時,One-Hot編碼可能會導致特征空間的急劇膨脹。在這種情況下,可能需要考慮其他編碼方法或降維技術。
6、目標編碼
目標編碼是一種利用目標變量來編碼分類特征的方法。這種技術特別適用于高基數的分類變量(即具有大量唯一值的變量)。目標編碼的基本步驟如下:
- 對于分類特征中的每個類別,計算對應的目標變量統計量(如均值)。
- 用計算得到的統計量替換原始的類別值。
以下是目標編碼的一個簡單實現:
fruits = ['banana','apple','durian','durian','apple','banana']
price = [120,100,110,150,140,160]
data = pd.DataFrame({
'fruit': fruits,
'price': price
})
data['encoded_fruits'] = data.groupby('fruit')['price'].transform('mean')
data
結果如下圖所示:
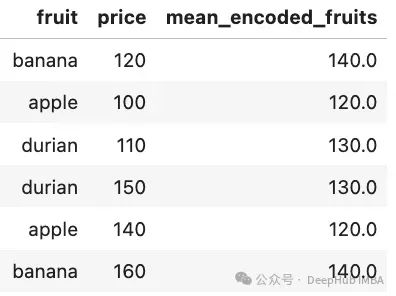
我們用每種水果的平均價格替換了原始的水果名稱。這種方法不僅可以處理高基數的分類變量,還能捕捉類別與目標變量之間的關系。使用目標編碼時需要注意以下幾點:
- 可能導致數據泄露,特別是在不做適當的交叉驗證的情況下。
- 對異常值敏感,可能需要進行額外的異常值處理。
- 在測試集中遇到訓練集中未出現的類別時,需要有合適的處理策略。
7、主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA)是一種常用的無監(jiān)督學習方法,主要用于降維和特征提取。PCA通過線性變換將原始特征投影到一個新的特征空間,使得新的特征(主成分)按方差大小排序。
PCA的主要步驟包括:
數據標準化
計算協方差矩陣
計算協方差矩陣的特征值和特征向量
選擇主成分
投影數據到新的特征空間
以下是使用PCA的一個示例,我們使用著名的Iris數據集:
iris_data = load_iris()
features = iris_data.data
targets = iris_data.target
features.shape
# 輸出: (150, 4)
pca = PCA(n_components=2)
pca_features = pca.fit_transform(features)
pca_features.shape
# 輸出: (150, 2)
for point in set(targets):
plt.scatter(pca_features[targets == point, 0], pca_features[targets == point,1], label=iris_data.target_names[point])
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.title('PCA on Iris Dataset')
plt.legend()
plt.show()
結果如下圖所示: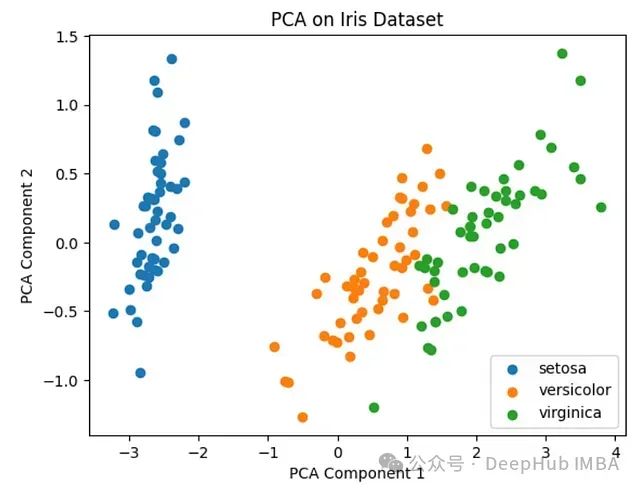
在這個例子中將原始的4維特征空間降至2維。從圖中可以看出,即使在降維后,不同類別的數據點仍然保持了良好的可分性。
PCA的優(yōu)點包括:
減少數據的維度,降低計算復雜度。
去除噪聲和冗余信息。
有助于數據可視化。
PCA也有一些局限性:
可能導致一定程度的信息損失。
轉換后的特征難以解釋,因為每個主成分都是原始特征的線性組合。
- 僅捕捉線性關系,對于非線性關系效果可能不佳。
8、 特征聚合
特征聚合是一種通過組合現有特征來創(chuàng)建新特征的方法。這種技術常用于時間序列數據、分組數據或者需要綜合多個特征信息的場景。
常見的特征聚合方法包括:
統計聚合:如平均值、中位數、最大值、最小值等。
時間聚合:如按天、周、月等時間單位聚合數據。
分組聚合:根據某些類別特征對數據進行分組,然后在每個組內進行聚合。
以下是一個特征聚合的示例:
quarter = ['Q1','Q2','Q3','Q4']
car_sales = [10000,9850,13000,20000]
motorbike_sales = [14000,18000,9000,11000]
sparepart_sales = [5000, 7000,3000, 10000]
data = pd.DataFrame({'car':car_sales,
'motorbike':motorbike_sales,
'sparepart':sparepart_sales}, index=quarter)
data['avg_sales'] = data[['car','motorbike','sparepart']].mean(axis=1).astype(int)
data['total_sales'] = data[['car','motorbike','sparepart']].sum(axis=1).astype(int)
data
結果如下圖所示:
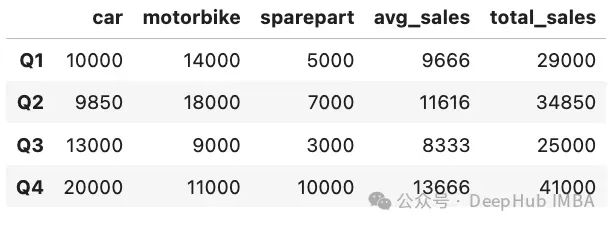
在這個例子中創(chuàng)建了兩個新的特征:
'avg_sales':每個季度不同產品的平均銷售額。
'total_sales':每個季度所有產品的總銷售額。
這種聚合可以幫助我們從不同角度理解數據,發(fā)現可能被單個特征忽略的模式。
特征聚合的優(yōu)點包括:
可以捕捉多個特征之間的關系。
減少特征的數量,有助于模型的解釋和計算效率。
- 可能創(chuàng)造出更有預測力的特征。
在使用特征聚合時也需要注意:
聚合可能會導致一些細節(jié)信息的丟失。
需要領域知識來決定哪些聚合是有意義的。
- 過度聚合可能會導致過擬合。
9、TF-IDF(詞頻-逆文檔頻率)
TF-IDF(Term Frequency-Inverse Document Frequency)是一種廣泛用于文本分析和信息檢索的特征提取技術。它結合了詞頻(TF)和逆文檔頻率(IDF)兩個指標,用于評估一個詞對于一個文檔集或一個語料庫中的某一個文檔的重要程度。
TF-IDF的計算基于以下兩個概念:
詞頻(TF):衡量一個詞在文檔中出現的頻率。計算公式為:TF(t,d) = (詞t在文檔d中出現的次數) / (文檔d中的總詞數)
- 逆文檔頻率(IDF):衡量一個詞在整個文檔集中的普遍重要性。計算公式為:IDF(t) = log(總文檔數 / 包含詞t的文檔數)
TF-IDF的最終得分是TF和IDF的乘積:TF-IDF(t,d) = TF(t,d) * IDF(t)
以下是使用TF-IDF的一個示例:
texts = ["I eat rice with eggs.",
"I also love to eat fried rice. Rice is the most delicious food in the world"]
vectorizer = TfidfVectorizer()
tfidfmatrix = vectorizer.fit_transform(texts)
features = vectorizer.get_feature_names_out()
data = pd.DataFrame(tfidfmatrix.toarray(), columns=features)
print("TF-IDF matrix")
data
結果如下圖所示:

在這個例子中:
第一行代表句子 "I eat rice with eggs."
- 第二行代表句子 "I also love to eat fried rice. Rice is the most delicious food in the world"
可以觀察到,"rice" 這個詞在第一個句子中的TF-IDF值(0.409)比在第二個句子中的值(0.349)更高。這是因為雖然 "rice" 在第二個句子中出現得更頻繁,但第一個句子更短,使得 "rice" 在其中的相對重要性更高。
TF-IDF的主要優(yōu)點包括:
能夠反映詞語在文檔中的重要程度。
可以過濾掉常見詞語,突出關鍵詞。
- 計算簡單,易于理解和實現。
TF-IDF也有一些局限性:
沒有考慮詞序和語法結構。
對于極短文本可能效果不佳。
- 不能捕捉詞語之間的語義關系。
10、文本嵌入
文本嵌入是將文本數據(如單詞、短語或文檔)映射到連續(xù)向量空間的技術。這種技術能夠捕捉詞語之間的語義關系,是現代自然語言處理中的基礎技術之一。
常見的文本嵌入方法包括:
Word2Vec
GloVe (Global Vectors for Word Representation)
FastText
- BERT (Bidirectional Encoder Representations from Transformers)
以下是使用Word2Vec進行文本嵌入的示例:
corpus = api.load('text8')
model = Word2Vec(corpus)
dog = model.wv['dog']
print("Embedding vector for 'dog':\n", dog)
輸出結果示例:
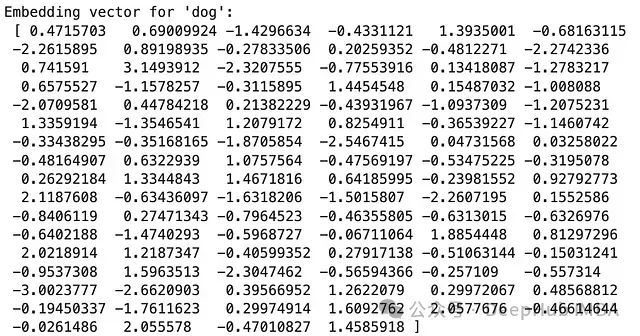
我們使用了gensim庫提供的text8語料庫(包含維基百科文本的前100,000,000個字節(jié))來訓練Word2Vec模型。每個詞被映射到一個100維的向量空間中。
文本嵌入的一個重要特性是能夠捕捉詞語之間的語義關系。我們可以通過計算詞向量之間的相似度來展示這一點:
cat = model.wv['cat']
car = model.wv['car']
dogvscat = model.wv.similarity('dog','cat')
dogvscar = model.wv.similarity('dog','car')
print("Similarity:")
print("Dog vs Cat: ", dogvscat)
print("Dog vs Car: ", dogvscar)
輸出結果:

從結果可以看出,"dog"和"cat"的相似度明顯高于"dog"和"car"的相似度,這符合我們的語義直覺。
文本嵌入的主要優(yōu)點包括:
能夠捕捉詞語之間的語義關系。
可以處理高維稀疏的文本數據,將其轉換為低維稠密的向量表示。
- 通過遷移學習,可以在小規(guī)模數據集上也能獲得良好的表現。
文本嵌入也存在一些挑戰(zhàn):
訓練高質量的嵌入模型通常需要大量的文本數據和計算資源。
詞語的多義性可能無法被單一的靜態(tài)向量完全捕捉。
- 對于特定領域的任務,可能需要在領域特定的語料上重新訓練或微調嵌入模型。
總結
本文介紹了十種基本的特征工程技術,涵蓋了數值型、分類型和文本型數據的處理方法。每種技術都有其特定的應用場景和優(yōu)缺點。在實際應用中,選擇合適的特征工程技術需要考慮數據的特性、問題的性質以及模型的要求。often需要結合多種技術來獲得最佳的特征表示。還有許多其他高級的特征工程技術未在本文中涉及,如時間序列特征工程、圖像特征提取等。隨著機器學習和深度學習技術的發(fā)展,特征工程的重要性可能會有所變化,但理解和掌握這些基本技術仍然是數據科學實踐中的重要基礎。
特征工程不僅是一門技術,更是一門藝術。它需要領域知識、直覺和經驗的結合。通過不斷的實踐和實驗,我們可以逐步提高特征工程的技能,從而為后續(xù)的機器學習任務奠定堅實的基礎。
-
數據
+關注
關注
8文章
7002瀏覽量
88941 -
機器學習
+關注
關注
66文章
8406瀏覽量
132558 -
數據分析
+關注
關注
2文章
1445瀏覽量
34050
發(fā)布評論請先 登錄
相關推薦
五種先進的SSD故障預測特征選擇方法盤點

【圖書分享】《STM32庫開發(fā)實戰(zhàn)指南》
數據挖掘與機器學習項目特征工程實戰(zhàn)

HarmonyOS測試技術與實戰(zhàn)-HarmonyOS分布式應用特征與挑戰(zhàn)







 工商網監(jiān)
工商網監(jiān)
評論