


學Python最簡單的方法是什么?
作為一名程序員或者準程序員,對于面向對象編程簡直熟悉的不能再熟悉。作為當今最流行的編程思想之一(或許可以去掉“之一”),無論是在面試還是工作中,面向對象都是無法避開的話題。
對于Python程序員來說,OOP(面向對象編程)的三大特性——數據封裝、繼承和多態通常是面試中的重點考察問題,因此大部分人對此也相當熟悉。
不過,OOP的優缺點你真的了解嗎?今天這篇文章會帶領大家了解一下三大特點中繼承的優缺點。
類
OOP()即所謂面向對象編程,是一種程序設計思想。OOP把對象作為程序的基本單元,一個對象包含了數據和操作數據的函數。面向對象的程序設計把計算機程序視為一組對象的集合,而每個對象都可以接收其他對象發過來的消息,并處理這些消息,計算機程序的執行就是一系列消息在各個對象之間傳遞。
面向對象最重要的概念就是類(Class)和實例(Instance),必須牢記類是抽象的模板,而實例是根據類創建出來的一個個具體的“對象”,每個對象都擁有相同的方法,但各自的數據可能不同。
假設我們要創建一個Student類,在Python中,定義類是通過class關鍵字:
class后面緊接著是類名,即Student,類名通常是大寫開頭的單詞,緊接著是(object),表示該類是從哪個類繼承下來的,繼承的概念我們后面再講,通常,如果沒有合適的繼承類,就使用object類,這是所有類最終都會繼承的類。
定義好了Student類,就可以根據Student類創建出Student的實例,創建實例是通過類名+()實現的:
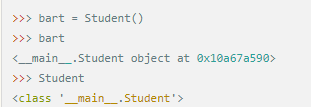
可以看到,變量bart指向的就是一個Student的實例,后面的0x10a67a590是內存地址,每個object的地址都不一樣,而Student本身則是一個類。
可以自由地給一個實例變量綁定屬性,比如,給實例bart綁定一個name屬性:

由于類可以起到模板的作用,因此,可以在創建實例的時候,把一些我們認為必須綁定的屬性強制填寫進去。通過定義一個特殊的__init__方法,在創建實例的時候,就把name,score等屬性綁上去:

注意:特殊方法“__init__”前后分別有兩個下劃線!!!
注意到__init__方法的第一個參數永遠是self,表示創建的實例本身,因此,在__init__方法內部,就可以把各種屬性綁定到self,因為self就指向創建的實例本身。
有了__init__方法,在創建實例的時候,就不能傳入空的參數了,必須傳入與__init__方法匹配的參數,但self不需要傳,Python解釋器自己會把實例變量傳進去:

和普通的函數相比,在類中定義的函數只有一點不同,就是第一個參數永遠是實例變量self,并且,調用時,不用傳遞該參數。除此之外,類的方法和普通函數沒有什么區別,所以,你仍然可以用默認參數、可變參數、關鍵字參數和命名關鍵字參數。
繼承
什么是繼承?
繼承是一種創建類的方法,在python中,一個類可以繼承來自一個或多個父類。原始類稱為基類或超類。

查看繼承:

什么時候用繼承?
假如已經有幾個類,而類與類之間有共同的變量屬性和函數屬性,那就可以把這幾個變量屬性和函數屬性提取出來作為基類的屬性。而特殊的變量屬性和函數屬性,則在本類中定義,這樣只需要繼承這個基類,就可以訪問基類的變量屬性和函數屬性。可以提高代碼的可擴展性。
繼承和抽象(先抽象再繼承)
抽象即提取類似的部分。基類就是抽象多個類共同的屬性得到的一個類。

Garen類和Riven類都有nickname、aggressivity、life_value、script四個變量屬性和attack()函數屬性,這里可以抽象出一個Hero類,里面有里面包含這些屬性。

嚴格來說,上述Hero.init(self,…),不能算作子類調用父類的方法。因為我們如果去掉(Hero)這個繼承關系,代碼仍能得到預期的結果。
總結python中繼承的特點:
在子類中,并不會自動調用基類的init(),需要在派生類中手動調用。
在調用基類的方法時,需要加上基類的類名前綴,且需要帶上self參數變量。
先在本類中查找調用的方法,找不到才去基類中找。
繼承的優缺點探討
子類化內置類型的缺點
1. 內置類型的方法不會調用子類覆蓋的方法
內置類可以子類化,但是內置類型的方法不會調用子類覆蓋的方法。下面以繼承dict的自定義子類重寫__setitem__為例說明:

從輸出可以看到,鍵值對one=1和three=3存入a時均調用了dict的__setitem__,只有[]運算符會調用我們預先覆蓋的方法。
問題的解決方式在于不去子類化dict,而是子類化colections.UserDict。
2、子類化collections中的類
用戶自定義的類應該繼承collections模塊,如UserDict,UserList,UserString。這些類做了特殊設計,因此易于拓展。子類化UserDict的代碼如下:

小結:上述問題只發生在C語言實現的內置類型子類化情況中,而且只影響直接繼承內置類型的自定義類。相反,子類化使用Python編寫的類,如UserDict或MutableMapping就不會有此問題。
多重繼承
1. 方法解析順序(Method Resolution Order,MRO)
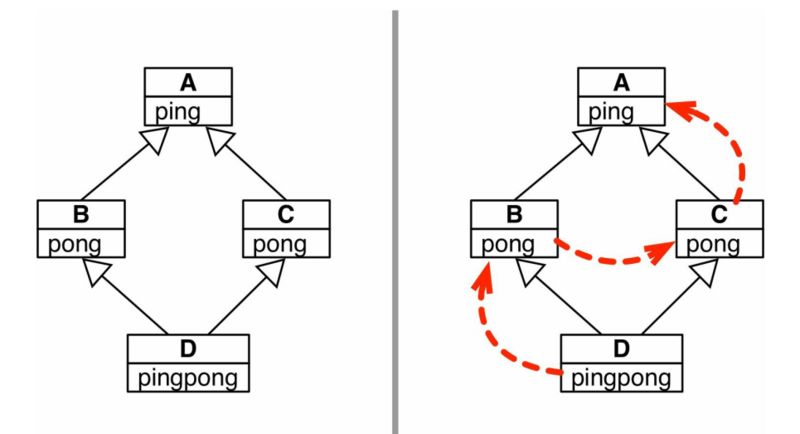
在多重繼承中存在不相關的祖先類實現同名方法引起的沖突問題,這種問題稱作“菱形問題”。Python依靠特定的順序遍歷繼承圖,這個順序叫做方法解析順序。如圖,左圖是類的UML圖,右圖中的虛線箭頭是方法解析順序:
2、super
提到類的屬性__mro__,就會提到super:
super 是個類,既不是關鍵字也不是函數等其他數據結構。
作用:super是子類用來調用父類方法的。
語法:super(a_type, obj);
a_type是obj的__mro__,當然也可以是__mro__的一部分,同時issubclass(obj,a_type)==true
舉個例子, 有個 MRO: [A, B, C, D, E, object]
我們這樣調用:super(C, A).foo()
super 只會從 C 之后查找,即: 只會在 D 或 E 或 object 中查找 foo 方法。
下面構造一個菱形問題的多重繼承來深化理解:

輸出如下:

分析:d.pingpong()執行super.ping(),super按照MRO查找父類的ping方法,查詢在類B到ping之后輸出了B.ping()。
3. 處理多重繼承的建議
(1)把接口繼承和實現繼承區分開;
繼承接口:創建子類型,是框架的支柱;
繼承實現:通過重用避免代碼重復,通常可以換用組合和委托模式。
(2)使用抽象基類顯式表示接口;
(3)通過混入重用代碼;混入類為多個不相關的子類提供方法實現,便于重用,但不會實例化。并且具體類不能只繼承混入類。
(4)在名稱中明確指明混入;Python中沒有把類聲明為混入的正規方式,Luciano推薦在名稱中加入Mixin后綴。如Tkinter中的XView應變成XViewMixin。
(5)抽象基類可以作為混入,反過來則不成立;抽象基類與混入的異同:
抽象基類會定義類型,混入做不到;
抽象基類可以作為其他類的唯一基類,混入做不到;
抽象基類實現的具體方法只能與抽象基類及其超類中的方法協作,混入沒有這個局限。
(6)不要子類化多個具體類;具體類可以沒有,或者至多一個具體超類。例如,Class Dish(China,Japan,Tofu)中,如果Tofu是具體類,那么China和Japan必須是抽象基類或混入。
(7)為用戶提供聚合類;聚合類是指一個類的結構主要繼承自混入,自身沒有添加結構或行為。Tkinter采納了此條建議。
(8)優先使用對象組合,而不是類繼承。優先使用組合可以令設計更靈活。組合和委托可以代替混入,但不能取代接口繼承去定義類型層次結構。
-
數據
+關注
關注
8文章
7264瀏覽量
92373 -
python
+關注
關注
56文章
4831瀏覽量
87747 -
OOP
+關注
關注
0文章
14瀏覽量
8931
原文標題:Python 繼承概念的這些優缺點你知道嗎?
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論