 Docker和k8s的核心概念
Docker和k8s的核心概念
背景
這是在HWL負責網校云業務線測試時,給同事分享的基礎概念文檔。
一、Docker核心概念
1、為什么是Docker
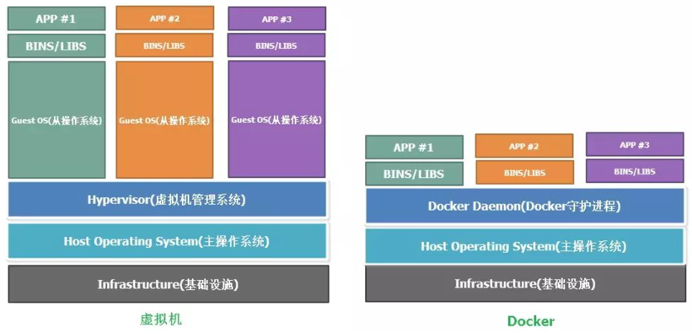
虛擬機:
基礎設施(Infrastructure)。服務器,或者是云主機。
主操作系統(Host Operating System)。服務器上運行的操作系統
虛擬機管理系統(Hypervisor)。利用Hypervisor,可以在主操作系統之上運行多個不同的從操作系統。
從操作系統(Guest Operating System)。假設你需要運行3個相互隔離的應用,則需要使用Hypervisor啟動3個從操作系統,也就是3個虛擬機。這些虛擬機都非常大,也許有700MB,這就意味著它們將占用2.1GB的磁盤空間。更糟糕的是,它們還會消耗很多CPU和內存。
各種依賴。每一個從操作系統都需要安裝許多依賴。
應用。安裝依賴之后,就可以在各個從操作系統分別運行應用了,這樣各個應用就是相互隔離的。
Docker:
Docker守護進程(Docker Daemon)。Docker守護進程取代了Hypervisor,它是運行在操作系統之上的后臺進程,負責管理Docker容器。
各種依賴。對于Docker,應用的所有依賴都打包在Docker鏡像中,Docker容器是基于Docker鏡像創建的。
應用。應用的源代碼與它的依賴都打包在Docker鏡像中,不同的應用需要不同的Docker鏡像。不同的應用運行在不同的Docker容器中,它們是相互隔離的。
對比虛擬機與Docker
Docker守護進程可以直接與主操作系統進行通信,為各個Docker容器分配資源;它還可以將容器與主操作系統隔離,并將各個容器互相隔離。虛擬機啟動需要數分鐘,而Docker容器可以在數毫秒內啟動。由于沒有臃腫的從操作系統,Docker可以節省大量的磁盤空間以及其他系統資源。

2、Docker架構
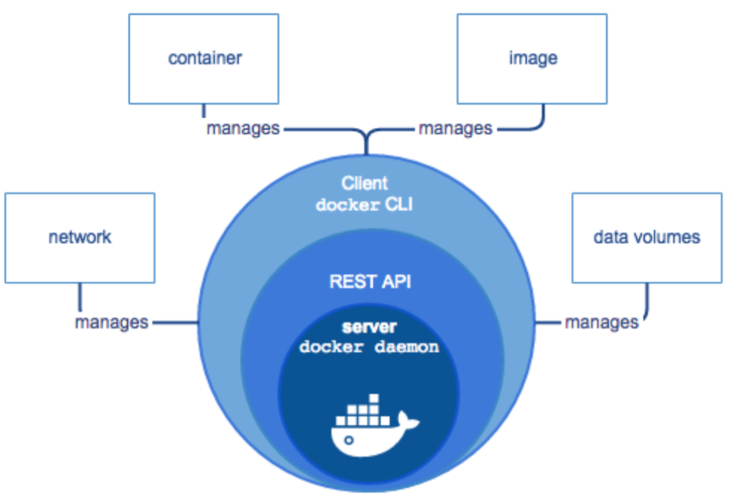
Docker使用客戶端- 服務器(C/S)架構,使用遠程API管理和創建Docker 容器。Docker 客戶端與Docker 守護進程通信,后者負責構建、運行和分發Docker容器。
Docker客戶端和守護進程可以在同一系統上運行,也可以將Docker客戶端連接到遠程Docker守護進程。Docker客戶端和守護進程使用REST API,通過UNIX套接字或網絡接口進行通信。
Client
客戶端通過命令行或其他工具與守護進程通信,客戶端會將這些命令發送給守護進程,然后執行這些命令。命令使用Docker API,Docker客戶端可以與多個守護進程通信。
Docker daemon
Docker守護進程(docker daemon)監聽Docker API請求并管理Docker對象,如鏡像,容器,網絡和卷。守護程序還可以與其他守護程序通信以管理Docker服務。
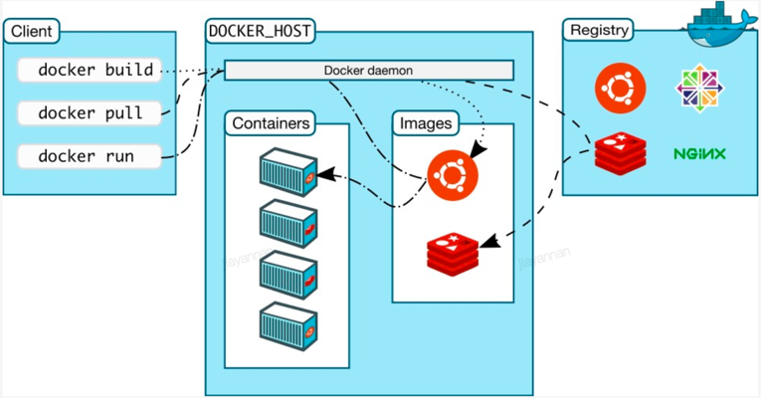
Docker Host
Docker Host是物理機或虛擬機,用于執行Docker守護進程的倉庫。
Docker Registry
Docker倉庫用于存儲Docker鏡像,可以是Docker Hub這種公共倉庫,也可以是個人搭建的私有倉庫。使用docker pull或docker run命令時,將從配置的倉庫中提取所需的鏡像。使用docker push命令時,鏡像將被推送到配置的倉庫。
DockerImage
Docker 鏡像可以看作是一個特殊的文件系統,除了提供容器運行時所需的程序、庫、資源、配置等文件外,還包含了一些為運行時準備的一些配置參數(如匿名卷、環境變量、用戶等)。
鏡像可以用來創建Docker 容器,一個鏡像可以創建很多容器。Docker 提供了一個很簡單的機制來創建鏡像或者更新現有的鏡像,用戶甚至可以直接從其他人那里下載一個已經做好的鏡像來直接使用。
Docker Container
Docker 利用容器來運行應用。容器是從鏡像創建的運行實例。它可以被啟動、開始、停止、刪除。每個容器都是相互隔離的、保證安全的平臺。
可以把容器看做是一個簡易版的Linux 環境(包括root用戶權限、進程空間、用戶空間和網絡空間等)和運行在其中的應用程序。
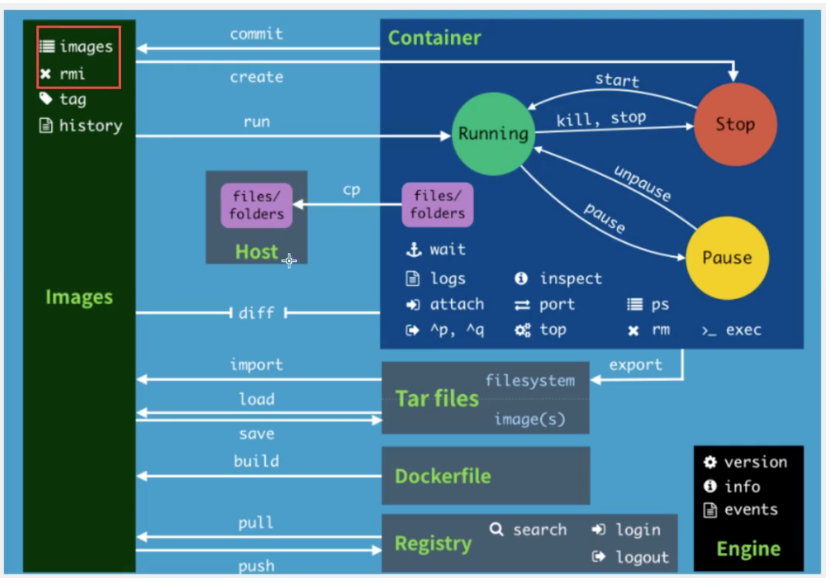
3、Docker CLI
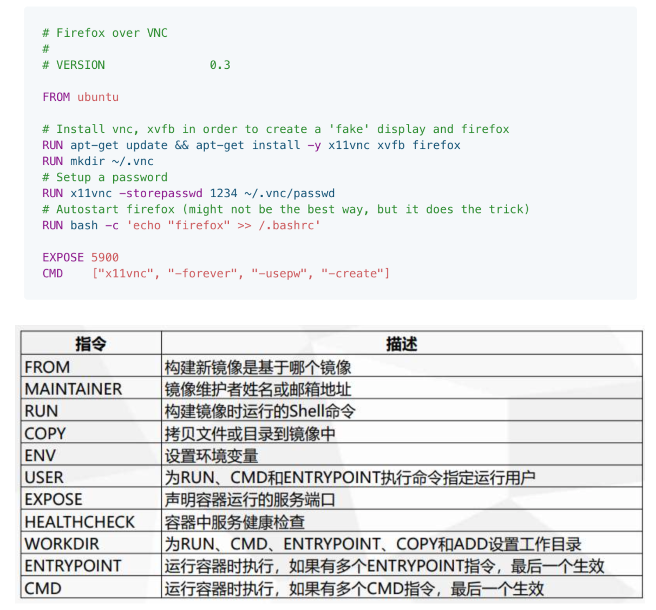
4、Dockerfile
5、Docker Compose
Compose 是用于定義和運行多容器Docker 應用程序的工具。通過Compose,您可以使用YML 文件來配置應用程序需要的所有服務。然后,使用一個命令,就可以從YML 文件配置中創建并啟動所有服務。

6、Docker Swarm集群管理
Swarm是Docker 引擎內置(原生)的集群管理和編排工具,它將Docker 主機池轉變為單個虛擬Docker 主機。
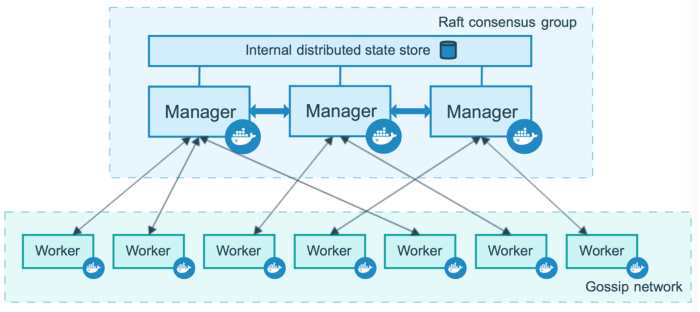
Docker Swarm 適用于簡單和快速開發至關重要的環境,而Kubernetes 適合大中型集群運行復雜應用程序的環境。
兩者不是競爭對手,各有利弊,因需選擇。
二、Kubernetes是什么及架構
1、k8s是什么
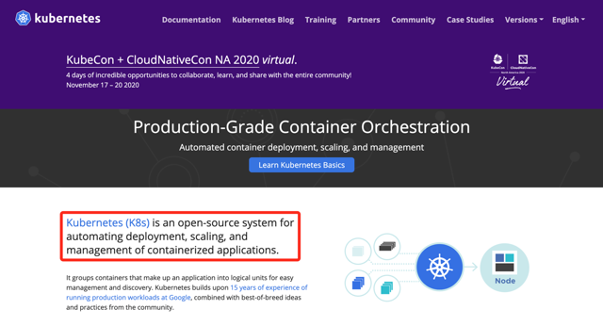
先來一張Kubernetes官網的截圖,可以看到,官方對Kubernetes的定義:Kubernetes(k8s)是一個自動化部署、擴展和管理容器化應用程序的開源系統。
Kubernetes這個單詞是希臘語,它的中文翻譯是“舵手”或者“飛行員”。在一些常見的資料中也會看到“ks”這個詞,也就是“k8s”,它是通過將8個字母“ubernete ”替換為“8”而導致的一個縮寫。Kubernetes為什么要用“舵手”來命名呢?
這是一艘載著一堆集裝箱的輪船,輪船在大海上運著集裝箱奔波,把集裝箱送到它們該去的地方。Container這個英文單詞也有另外的一個意思就是“集裝箱”。Kubernetes也就借著這個寓意,希望成為運送集裝箱的一個輪船,來幫助我們管理這些集裝箱,也就是管理這些容器。
這個就是為什么會選用Kubernetes這個詞來代表這個項目的原因。更具體一點地來說:Kubernetes是一個自動化的容器編排平臺,它負責應用的部署、應用的彈性以及應用的管理。
2、k8s能做什么
服務的發現與負載的均衡
容器的自動裝箱,也會把它叫做scheduling,就是“調度”,把一個容器放到一個集群的某一個機器上,Kubernetes會幫助我們去做存儲的編排,讓存儲的聲明周期與容器的生命周期建立連接
容器的自動化恢復。在一個集群中,經常會出現宿主機的問題,導致容器本身的不可用,Kubernetes會自動地對這些不可用的容器進行恢復
應用的自動發布與應用的回滾,以及與應用相關的配置密文的管理
對于job類型任務,Kubernetes可以去做批量的執行
為了讓這個集群、這個應用更富有彈性,Kubernetes支持容器的水平伸縮
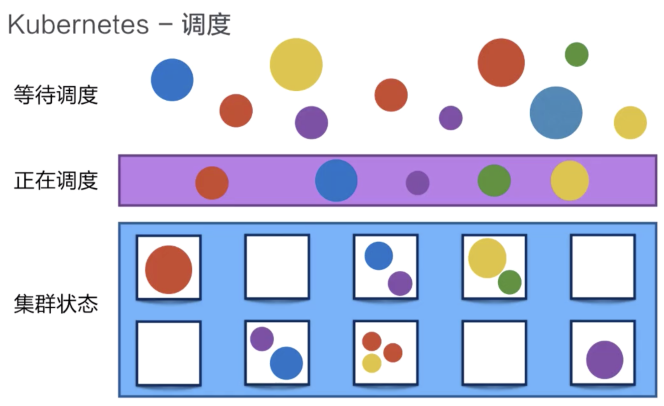
2.1調度
Kubernetes可以把用戶提交的容器放到Kubernetes管理的集群的某一臺節點上去。Kubernetes的調度器是執行這項能力的組件,它會觀察正在被調度的這個容器的大小、規格。
比如,容器所需要的CPU以及它所需要的內存,然后在集群中找一臺相對比較空閑的機器來進行一次放置的操作。
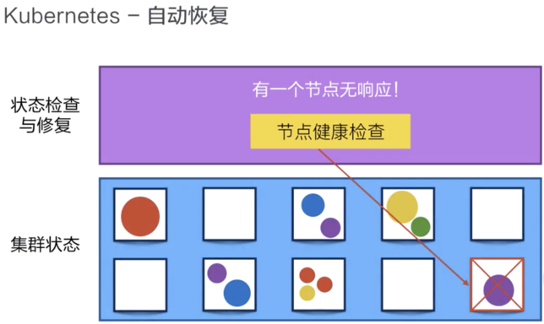
2.2自動修復
Kubernetes有節點健康檢查的功能,它會監測這個集群中所有的宿主機,當宿主機本身出現故障,或者軟件出現故障的時候,這個節點健康檢查會自動對它進行發現。
接下來Kubernetes會把運行在這些失敗節點上的容器進行自動遷移,遷移到一個正在健康運行的宿主機上,來完成集群內容器的自動恢復。
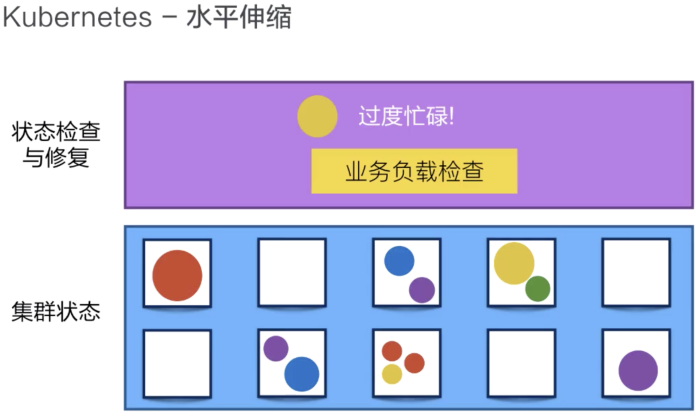
2.3水平伸縮
Kubernetes有業務負載檢查的能力,它會監測業務上所承擔的負載,如果這個業務本身的CPU利用率或內存占用過高,或者響應時間過長,它可以對這個業務進行一次擴容。
比如,下面的例子中,黃顏色的過度忙碌,Kubernetes就可以把黃顏色負載從一份變為三份。接下來,它就可以通過負載均衡把原來打到第一個黃顏色上的負載平均分到三個黃顏色的負載上去,以此來提高響應速度。
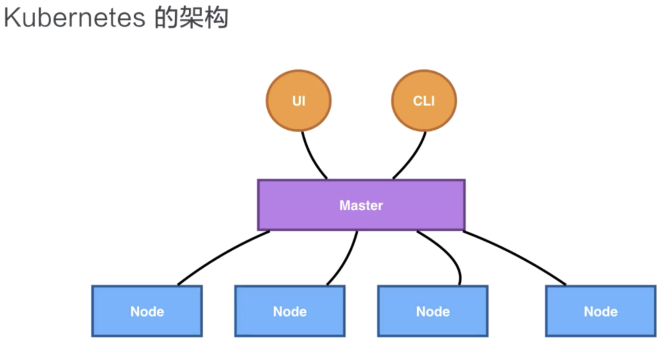
3、k8s的架構
Kubernetes架構是一個比較典型的二層架構和server-client架構。Master作為中央管控節點,與Node建立連接。
所有UI的、clients、user側的組件,只會和Master進行連接,把希望的狀態或者想執行的命令下發給Master,Master會把這些命令或者狀態下發給相應的節點,進行最終的執行。
Master
Kubernetes的Master包含四個主要的組件:API Server、Controller、Scheduler以及etcd。
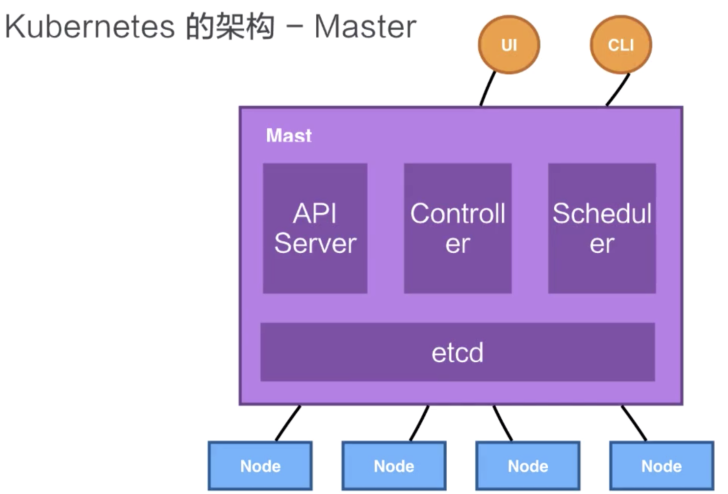
API Server:提供了資源操作的唯一入口,并提供認證、授權、訪問控制、API注冊和發現等機制。
Kubernetes中所有的組件都會和API Server進行連接,組件與組件之間一般不進行獨立的連接,都依賴于API Server進行消息的傳送;
Controller:控制器,它負責維護集群的狀態,比如故障檢測、自動擴展、滾動更新等。上面的2個例子,第1個自動對容器進行修復、第2個自動水平擴張,都是由Controller完成的;
Scheduler:是調度器,負責資源的調度,按照預定的調度策略將Pod調度到相應的機器上。例如上面的例子,把用戶提交的pod,依據它對CPU、memory請求的大小,找一臺合適的節點,進行放置;
etcd:是一個分布式的存儲系統,保存了整個集群的狀態,比如Pod、Service等對象信息。API Server中所需要的原信息都被放置在etcd中,etcd本身是一個高可用系統,通過etcd保證整個Kubernetes的Master組件的高可用性。
Node
Kubernetes的Node是真正運行業務負載的,每個業務負載會以Pod的形式運行。一個Pod中運行的一個或者多個容器。
kubelet:Master在Node節點上的Agent,是真正去運行Pod的組件,也是Node上最關鍵的組件,負責本Node節點上Pod的創建、修改、監控、刪除等生命周期管理,同時Kubelet定時“上報”本Node的狀態信息到APIServer。
它通過API Server接收到所需要Pod運行的狀態。然后提交到Container Runtime組件中。
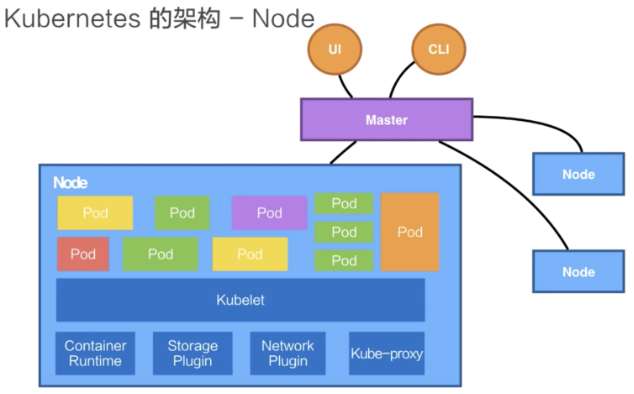
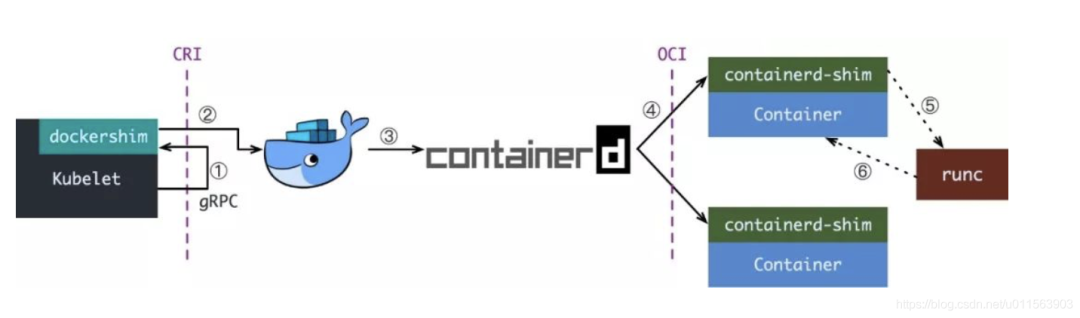
Container Runtime:容器運行時。負責鏡像管理以及Pod和容器的真正運行(CRI),可以理解為類似JVM
Storage Plugin或者Network Plugin:對存儲跟網絡進行管理
在OS上去創建容器所需要運行的環境,最終把容器或者Pod運行起來,也需要對存儲跟網絡進行管理。Kubernetes并不會直接進行網絡存儲的操作,他們會靠Storage Plugin或者Network Plugin來進行操作。用戶自己或者云廠商都會去寫相應的Storage Plugin或者Network Plugin,去完成存儲操作或網絡操作。
Kube-proxy:負責為Service提供cluster內部的服務發現和負載均衡,完成service組網
在Kubernetes自己的環境中,也會有Kubernetes的Network,它是為了提供Service network來進行搭網組網的。真正完成service組網的組件是Kube-proxy,它是利用了iptable的能力來進行組建Kubernetes的Network,就是cluster network。
組件間的通信
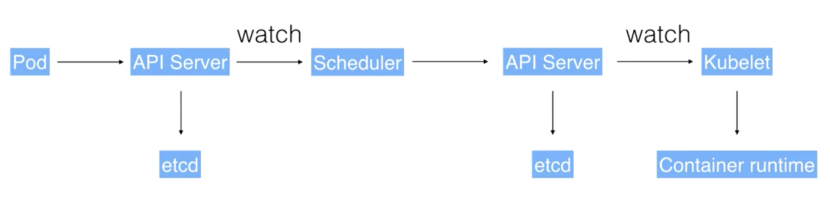
步驟說明:
1.通過UI或者CLI提交1個Pod給Kubernetes進行部署,這個Pod請求首先會提交給API Server,下一步API Server會把這個信息寫入到存儲系統etcd,之后Scheduler會通過API Server的watch機制得到這個信息:有1個Pod需要被調度。
2. Scheduler會根據node集群的內存狀態進行1次調度決策,在完成這次調度之后,它會向API Server報告:“OK!這個Pod需要被調度到XX節點上。”
API Server接收后,會把這次的操作結果再次寫到etcd中。
3. API Server通知相應的節點進行這個Pod真正的執行啟動。相應節點的kubelet會得到通知,然后kubelet會去調Container runtime來真正去啟動配置這個容器和這個容器的運行環境,去調度Storage Plugin來去配置存儲,network Plugin去配置網絡。
三、Kubernetes核心概念
第一個概念:Pod
Pod是Kubernetes的最小調度以及資源單元。可以通過Kubernetes的Pod API生產一個Pod,讓Kubernetes對這個Pod進行調度,也就是把它放在某一個Kubernetes管理的節點上運行起來。一個Pod簡單來說是對一組容器的抽象,它里面會包含一個或多個容器。
比如下圖,它包含了兩個容器,每個容器可以指定它所需要資源大小
當然,在這個Pod中也可以包含一些其他所需要的資源:比如說我們所看到的Volume卷這個存儲資源。

第二個概念:Volume
管理Kubernetes存儲,用來聲明在Pod中的容器可以訪問的文件目錄,一個卷可以被掛載在Pod中一個或者多個容器的指定路徑下面。
而Volume本身是一個抽象的概念,一個Volume可以去支持多種的后端的存儲。Kubernetes的Volume支持很多存儲插件,可以支持本地的存儲和分布式的存儲,比如像ceph,GlusterFS;也可以支持云存儲,比如阿里云上的云盤、AWS上的云盤、Google上的云盤等等。

第三個概念:Deployment
Deployment是在Pod上更為上層的一個抽象,它可以定義一組Pod的副本數目、以及Pod的版本。一般用Deployment來做應用的真正的管理,而Pod是組成Deployment最小的單元。
Kubernetes通過Controller(控制器)維護Deployment中Pod的數目,Controller也會去幫助Deployment自動恢復失敗的Pod。
比如,可以定義一個Deployment,這個Deployment里面需要2個Pod,當1個Pod失敗的時候,控制器就會監測到,再去新生成1個Pod,把Deployment中的Pod數目從1個恢復到2個。通過控制器,也可以完成發布策略,比如進行滾動升級、重新生成的升級或者進行版本回滾。

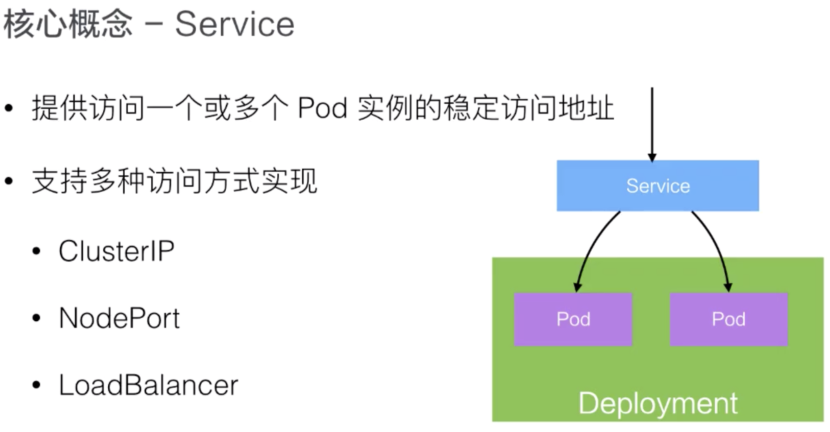
第四個概念:Service
Service:提供1個或者多個Pod實例的穩定訪問地址
比如,一個Deployment可能有2個甚至更多個完全相同的Pod。對于外部的用戶來講,訪問哪個Pod都是一樣的,所以希望做一次負載均衡,在做負載均衡的同時,只需要訪問某一個固定的VIP,也就是Virtual IP地址,而不需要得知每一個具體的Pod的IP地址。
如果1個Pod失敗了,可能會換成另外一個新的。提供了多個具體的Pod地址,對外部用戶來說,要不停地去更新Pod地址。當這個Pod再失敗重啟之后,如果有一個抽象,把所有Pod的訪問能力抽象成1個第三方的IP地址,實現這個的Kubernetes的抽象就叫Service。
實現Service有多種入口方式:
ClusterIP:Service 在集群內的唯一ip 地址,我們可以通過這個ip,均衡的訪問到后端的Pod,而無須關心具體的Pod。
NodePort:Service 會在集群的每個Node 上都啟動一個端口,我們可以通過任意Node 的這個端口來訪問到Pod。
LoadBalancer:在 NodePort的基礎上,借助公有云環境創建一個外部的負載均衡器,并將請求轉發到 NodeIP:NodePort。
ExternalName:將服務通過 DNS CNAME記錄方式轉發到指定的域名(通過 spec.externlName設定)。
第五個概念:Namespace
Namespace:用來做一個集群內部的邏輯隔離,包括鑒權、資源管理等。Kubernetes的每個資源,比如Pod、Deployment、Service都屬于一個Namespace,同一個Namespace中的資源需要命名的唯一性,不同的Namespace中的資源可以重名。

K8S的API
Kubernetes API是由HTTP+JSON組成的:用戶訪問的方式是HTTP,訪問API中content的內容是JSON格式的。
用Kubectl命令、Kubernetes UI或者Curl,直接與Kubernetes交互都是使用HTTP + JSON的形式。
如下圖,對于這個Pod類型的資源,它的HTTP訪問的路徑就是API,apiVesion: V1,之后是相應的Namespaces,以及Pods資源,最終是Podname,也就是Pod的名字。

當提交一個Pod,或者get一個Pod的時候,它的content內容都是用JSON或者是YAML表達的。上圖中YAML的例子,在這個YAML文件中,對Pod資源的描述分為幾個部分。
第一個部分,一般是API的version。比如在這個例子中是V1,它也會描述我在操作哪個資源;kind如果是pod,在Metadata中,就寫上這個Pod的名字;比如nginx。也會給pod打一些label,在Metadata中,有時候也會去寫annotation,也就是對資源的額外的一些用戶層次的描述。
比較重要的一個部分叫Spec,Spec也就是希望Pod達到的一個預期的狀態。比如pod內部需要有哪些container被運行;這里是一個name為nginx的container,它的image是什么?它暴露的port是什么?
當從Kubernetes API中去獲取這個資源的時候,一般在Spec下面會有一個status字段,它表達了這個資源當前的狀態;比如一個Pod的狀態可能是正在被調度、或者是已經running、或者是已經被terminates(被執行完畢)。
Label是一個比較有意思的metadata,可以是一組KeyValue的集合。
如下圖,第一個pod中,label就可能是一個color等于red,即它的顏色是紅顏色。當然也可以加其他label,比如說size: big就是大小,定義為大的,它可以是一組label。
這些label是可以被selector(選擇器)所查詢的。就好比sql類型的select語句。

通過label,kubernetes的API層就可以對這些資源進行篩選。
例如,Deployment可能代表一組Pod,是一組Pod的抽象,一組Pod就是通過label selector來表達的。當然Service對應的一組Pod來對它們進行統一的訪問,這個描述也是通過label selector來選取的一組Pod。
鏈接:https://www.cnblogs.com/ailiailan/p/18522478
-
服務器
+關注
關注
12文章
9123瀏覽量
85328 -
操作系統
+關注
關注
37文章
6801瀏覽量
123285 -
Docker
+關注
關注
0文章
457瀏覽量
11846
原文標題:Docker和k8s核心概念(理解友好版)
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
全面提升,阿里云Docker/Kubernetes(K8S) 日志解決方案與選型對比
全面提升,阿里云Docker/Kubernetes(K8S) 日志解決方案與選型對比
OpenStack與K8s結合的兩種方案的詳細介紹和比較
k8s容器運行時演進歷史
Docker不香嗎為什么還要用K8s
簡單說明k8s和Docker之間的關系
K8S集群服務訪問失敗怎么辦 K8S故障處理集錦

mysql部署在k8s上的實現方案
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres
什么是K3s和K8s?K3s和K8s有什么區別?
k8s生態鏈包含哪些技術
k8s云原生開發要求






 工商網監
工商網監
評論