") 基于圖遍歷的Flink任務(wù)畫(huà)布模式下零代碼開(kāi)發(fā)實(shí)現(xiàn)方案
基于圖遍歷的Flink任務(wù)畫(huà)布模式下零代碼開(kāi)發(fā)實(shí)現(xiàn)方案
作者:京東物流 吳云濤
前言
提交一個(gè)DataSteam 的 Flink應(yīng)用,需要經(jīng)過(guò) StreamGraph、JobGraph、ExecutionGraph 三個(gè)階段的轉(zhuǎn)換生成可成執(zhí)行的有向無(wú)環(huán)圖(DAG),并在 Flink 集群上運(yùn)行。而提交一個(gè) Flink SQL 應(yīng)用,其執(zhí)行流程也類(lèi)似,只是多了一步使用 flink-table-planer 模塊從SQL轉(zhuǎn)換成 StreamGraph 的過(guò)程。以下是利用Flink的 StreamGraph 通過(guò)低代碼的方式,來(lái)實(shí)現(xiàn)StreamGraph的生成,并最終實(shí)現(xiàn) Flink 程序零代碼開(kāi)發(fā)的解決方案。
一、Flink 相關(guān)概念
在Flink程序中,每個(gè)算子被稱作Operator,通過(guò)各個(gè)算子的處理最終得到期望的加工后數(shù)據(jù)。比如下面這段程序中,增加了Source, Fiter, Map, Sink 4個(gè)算子。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream dataStream = env.addSource(new FlinkKafkaConsumer("topic")); DataStream filteredStream = dataStream.filter(new FilterFunction() { @Override public boolean filter(Object value) throws Exception {return true;} }); DataStream mapedStream = filteredStream.map(new MapFunction() { @Override public Object map(Object value) throws Exception {return value;} }); mapedStream.addSink(new DiscardingSink()); env.execute("test-job");
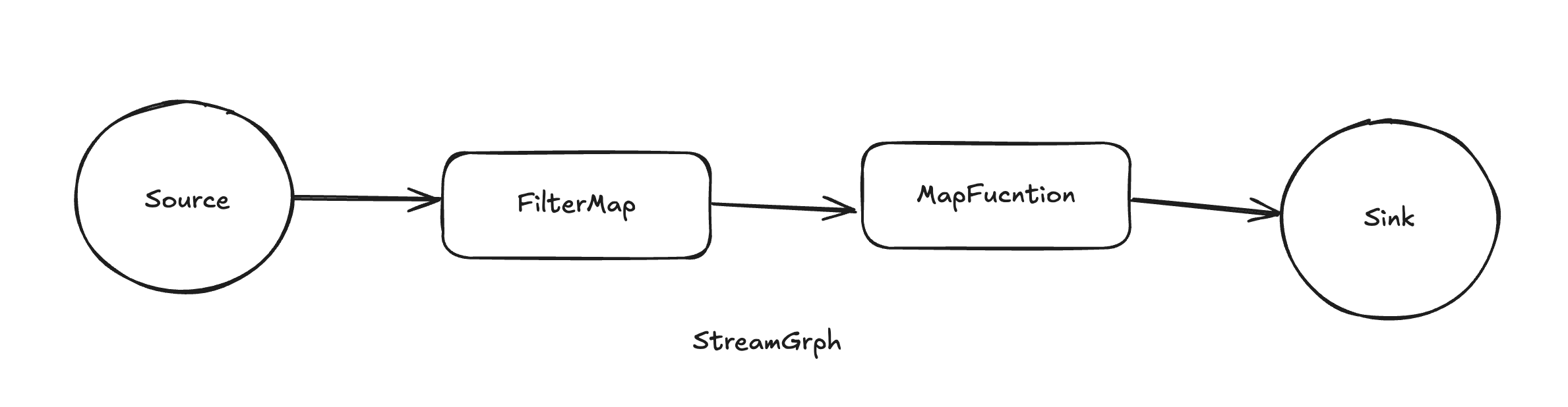
StreamGraph
Flink的邏輯執(zhí)行圖,描述了整個(gè)流處理任務(wù)的流程和數(shù)據(jù)流轉(zhuǎn)遞規(guī)則,包括了數(shù)據(jù)源(Source)、轉(zhuǎn)換算子(Transform)、數(shù)據(jù)目的端(Sink)等元素,以及它們之間的依賴關(guān)系和傳輸規(guī)則。StreamGraph是通過(guò)Flink的API或者DSL來(lái)構(gòu)建的向無(wú)環(huán)圖(DAG),它與JobGraph之間是一一對(duì)應(yīng)的關(guān)系。StreamGraph中的頂點(diǎn)稱為streamNode,是用來(lái)表示Operator算子的類(lèi),包含了算子uid、并行度,是否共享slot(SlotSharingGroup)等信息。邊稱作streamEdge。通過(guò)StreamingJobGraphGenerator類(lèi)生成JobGraph。
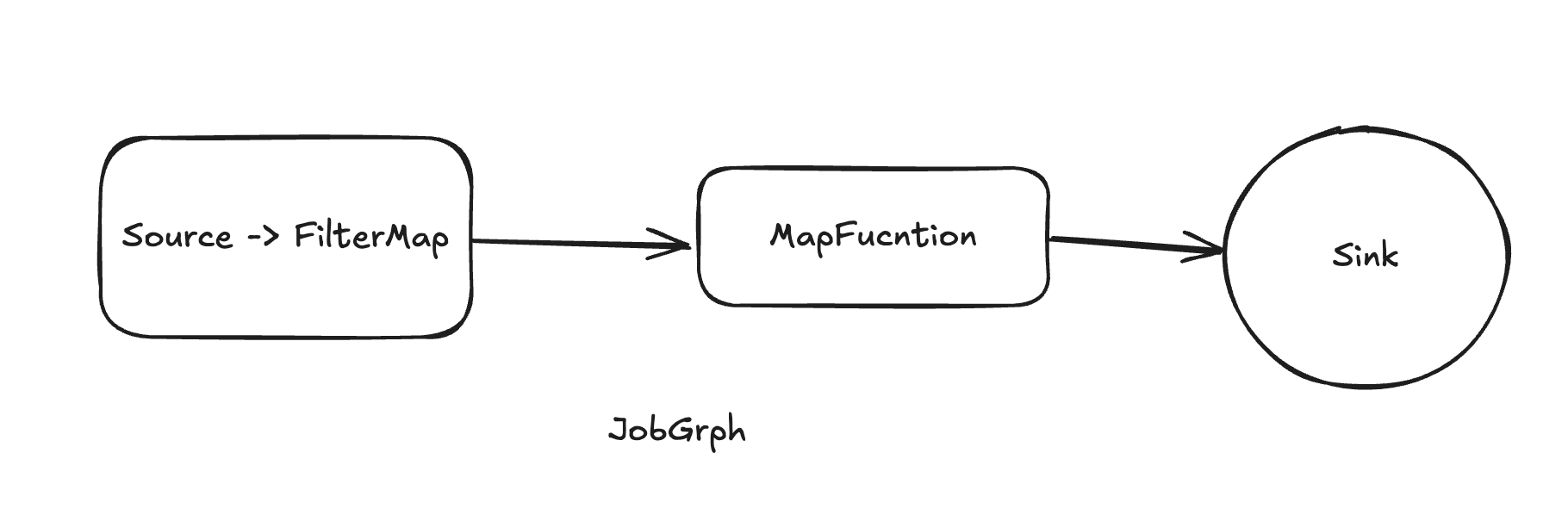
JobGraph
StreamGraph 經(jīng)過(guò) flink-optimizer 模塊優(yōu)化后生成 JobGraph。生成 JobGraph 時(shí),會(huì)將多個(gè)滿足條件的算子chain 鏈接到一起作為一個(gè)頂點(diǎn)(JobVertex), 在運(yùn)行時(shí)對(duì)應(yīng)1個(gè) Task。Task 是 Flink 程序的基本執(zhí)行單元,任務(wù)調(diào)度時(shí)將Task分配到TaskManager上執(zhí)行。
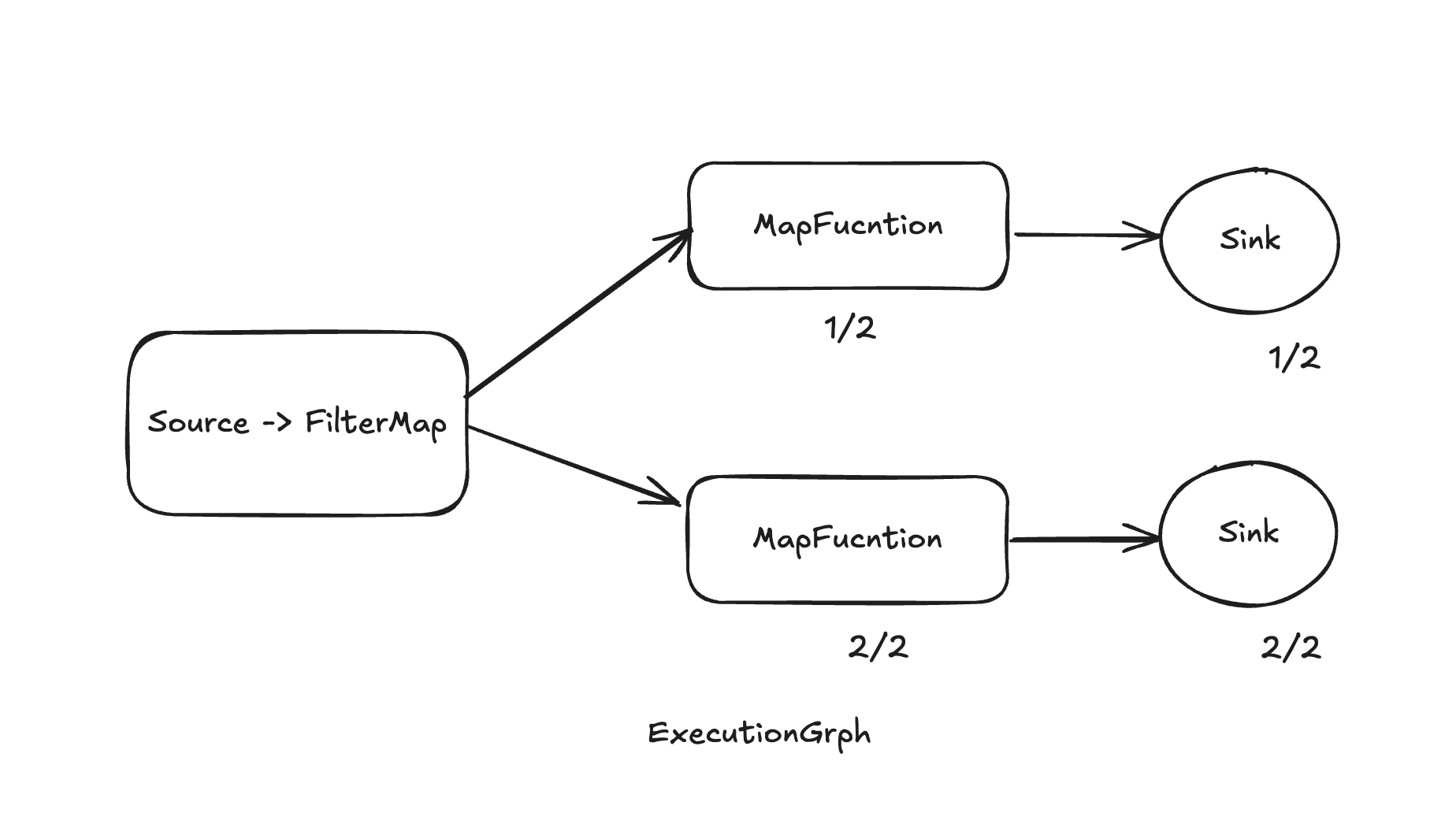
ExecutionGraph
物理執(zhí)行圖是由JobGraph轉(zhuǎn)換而來(lái),描述了整個(gè)流處理任務(wù)的物理執(zhí)行細(xì)節(jié),包括了任務(wù)的調(diào)度、任務(wù)的執(zhí)行順序、任務(wù)之間的數(shù)據(jù)傳輸、任務(wù)的狀態(tài)管理等。Task會(huì)在步驟中拆分為多個(gè)SubTask。對(duì)應(yīng)Task中的每個(gè)并行度。
Physical Graph
PhysicalGraph是在執(zhí)行時(shí)的ExecutionGraph。ExecutionGraph中的每一個(gè)頂點(diǎn)ExecutionJobVertex都對(duì)應(yīng)一個(gè)或多個(gè)頂點(diǎn)ExecutionVertex,它們是物理執(zhí)行圖中的節(jié)點(diǎn)。
二、畫(huà)布模式實(shí)現(xiàn)思路
實(shí)現(xiàn)流程
首先,我們采用畫(huà)布模式(拖拉拽方式)來(lái)實(shí)現(xiàn)Flink程序的組裝,將極大程度上方便我們復(fù)用部分加工的算子,最終實(shí)現(xiàn)零代碼的Flink應(yīng)用開(kāi)發(fā)。我們通過(guò)繪圖的方式,直接將內(nèi)置的算子繪制在圖標(biāo)上。如下所示:
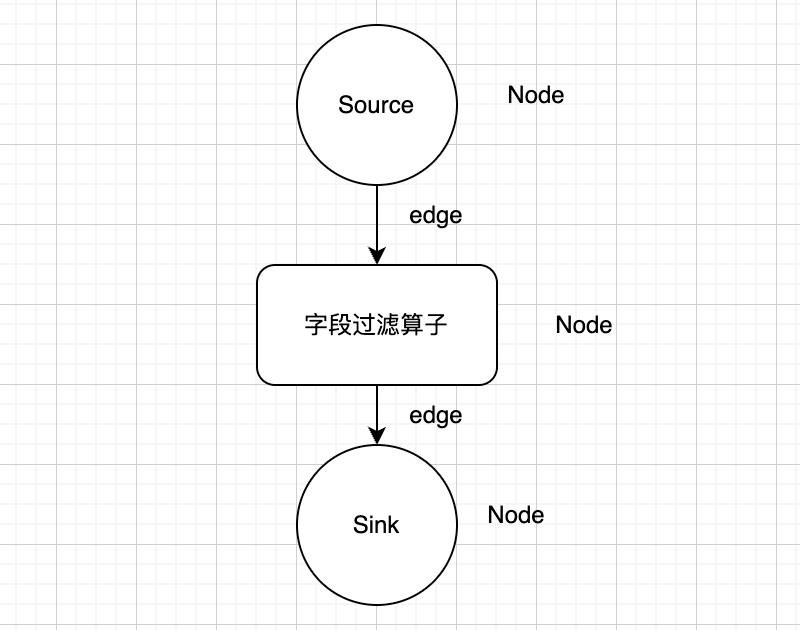
構(gòu)建有向無(wú)環(huán)圖(DAG),并持久化。通過(guò)拖拉拽的方式(畫(huà)布模式)構(gòu)建你的Flink應(yīng)用,后端的持久化存儲(chǔ)采用鄰接表方式。我們?cè)?mysql 關(guān)系數(shù)據(jù)庫(kù)中將 Node(算子:Source、Sink、中間加工邏輯算子)存儲(chǔ)到 flink_node 表中;將邊存到一張 flink_realation 表中。
重新組將Flink作業(yè)
要組裝以上畫(huà)布模式的Flink應(yīng)用,首先需要初始化好 StreamExecutionEnvironment 相關(guān)參數(shù),其次將上述表中的 flink_node 和flink_edge 轉(zhuǎn)化為DataStream,并將轉(zhuǎn)化出的 DataStream 合理地拼接成一個(gè) DataStream API Flink 應(yīng)用程序。
在將flink_node、flink_edge轉(zhuǎn)為為DataStream時(shí)選擇何種遍歷算法來(lái)組裝呢?我們知道有向無(wú)環(huán)圖的遍歷最常用的有:深度優(yōu)先遍歷(DFS)和廣度優(yōu)先遍歷(BFS)。這里我們采用了BFS算法+層序遍歷的方式,BFS便于在組裝的過(guò)程中將已visit到的node節(jié)點(diǎn)拼裝到其parent 的節(jié)點(diǎn)上。
總結(jié)
在實(shí)際的實(shí)現(xiàn)過(guò)程中,遇到的問(wèn)題往往比以上復(fù)雜很多。比如需要將更多的信息存儲(chǔ)在node節(jié)點(diǎn)和edge邊上。node上需要存儲(chǔ)并行度、算子處理前后的表schema等;edge需要存儲(chǔ)keyby的字段、上下游之間的數(shù)據(jù)shuffle的方式等等。此外在內(nèi)置的算子無(wú)法滿足用戶需求時(shí),還需要考慮如何友好的支持自定義算子(UDF)的嵌入等問(wèn)題。
審核編輯 黃宇
-
開(kāi)發(fā)
+關(guān)注
關(guān)注
0文章
370瀏覽量
40836 -
代碼
+關(guān)注
關(guān)注
30文章
4779瀏覽量
68524
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
隔空科技聯(lián)合涂鴉智能推出微波雷達(dá)感應(yīng)燈零代碼實(shí)現(xiàn)方案

RA-RTT體驗(yàn)零代碼點(diǎn)亮LED燈
什么是零代碼應(yīng)用開(kāi)發(fā)平臺(tái)?它有哪些功能模塊
實(shí)現(xiàn)零代碼開(kāi)發(fā)還需要多長(zhǎng)時(shí)間
零代碼開(kāi)發(fā)平臺(tái)工作原理
什么是零代碼開(kāi)發(fā)
零代碼與低代碼快速開(kāi)發(fā)平臺(tái)有什么區(qū)別
零代碼開(kāi)發(fā)平臺(tái)能夠給企業(yè)帶來(lái)哪些好處
淺談零代碼開(kāi)發(fā)的價(jià)值在哪里
零代碼平臺(tái)和低代碼平臺(tái)分別適合開(kāi)發(fā)哪些應(yīng)用程序
零代碼開(kāi)發(fā)平臺(tái)為什么會(huì)受到企業(yè)管理者的歡迎
玩轉(zhuǎn)5元MCU,合宙Air32零代碼實(shí)現(xiàn)USB轉(zhuǎn)串口

零代碼如何實(shí)現(xiàn)造數(shù)據(jù)
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車(chē)電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論