

1.問題描述
在介紹skid buffer之前,我們先來假設(shè)這樣一種情況,在一個多級流水模型之中,比如最為經(jīng)典的順序五級流水的處理器模型中,各級之間通過僅通過valid-ready的握手信號進行數(shù)據(jù)傳遞,(需要注意的是,這里的輸入側(cè)和輸出側(cè)的握手信號是不建議直連的,這樣不符合流水設(shè)計思想的同時,還會加中時序壓力)當其中某級發(fā)生阻塞的時候,比如lsu的執(zhí)行訪存指令,但是cache未命中,需要從更下級的儲存器去請求數(shù)據(jù)的時候,此時需要通過握手信號來需要阻塞流水線,理所應(yīng)當?shù)模覀兝蚻su的input_ready信號來阻塞來自上級流水的輸入(比如EXU),可是問題是此時上上級(比如IDU)并未被阻塞,還在向上級(EXU)傳輸數(shù)據(jù),同樣的情況發(fā)生在所有的上游模塊。這篇文章便是用來解決上述問題。
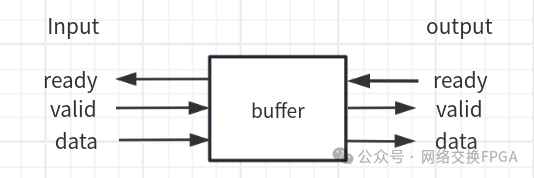
2.Half-Buffer
2.1 Half-Buffer是什么?
引發(fā)上述問題的原因是未能及時阻塞之前的流水線,再深究其原因,是因為其輸入側(cè)和輸出側(cè)的握手允許在相同時鐘周期完成,所以阻塞的信息沒有同步到上級。為了解決以上問題,我們現(xiàn)在為流水線每級做如下限定:
1.輸入側(cè)和輸出側(cè)不能同時完成握手操作。
2.在沒有有效數(shù)據(jù)之前之前只能進行輸入握手,在內(nèi)部有有效數(shù)據(jù)后,只能做輸出握手,在完成握手后才能重新開始輸入。
而這種方法叫做Half-Buffer,他內(nèi)部只有一個buffer來緩存數(shù)據(jù),所以他不支持輸入和輸出側(cè)同時完成握手。他的缺點是顯而易見的,每次啟動或停止的時候需要兩個時鐘周期的同時,還讓最大帶寬減半。但是,對于內(nèi)部需要多個時鐘周期來計算結(jié)果的模塊而言,其影響并沒有那么大。
2.2 Half-Buffer源碼分析
這里我們選取fpgacpu網(wǎng)站上的源碼進行講解,網(wǎng)址會帖在文末。
首先是接口部分,需要注意的是,此處的CIRCULAR_BUFFER部分非0 時候,是允許內(nèi)部有效數(shù)據(jù)在未完成輸出側(cè)握手的情況下接受新數(shù)據(jù)對原有數(shù)據(jù)進行覆蓋的。因為這種模式我們使用不多,這里現(xiàn)不做介紹。
`default_nettype none module Pipeline_Half_Buffer #( parameter WORD_WIDTH = 0, parameter CIRCULAR_BUFFER = 0 // non-zero to enable ) ( input wire clock, input wire clear, input wire input_valid, output reg input_ready, input wire [WORD_WIDTH-1:0] input_data, output reg output_valid, input wire output_ready, output wire [WORD_WIDTH-1:0] output_data ); localparam WORD_ZERO = {WORD_WIDTH{1'b0}};
這部分是half_buffer部分,可以看到其內(nèi)部只有一個buffer用來儲存數(shù)據(jù):
reg half_buffer_load = 1'b0;
Register
#(
.WORD_WIDTH (WORD_WIDTH),
.RESET_VALUE (WORD_ZERO)
)
half_buffer
(
.clock (clock),
.clock_enable (half_buffer_load),
.clear (clear),
.data_in (input_data),
.data_out (output_data)
);
空滿信號的產(chǎn)生模塊:
reg set_to_empty = 1'b0;
reg set_to_full = 1'b0;
wire buffer_full;
Register
#(
.WORD_WIDTH (1),
.RESET_VALUE (1'b0)
)
empty_full
(
.clock (clock),
.clock_enable (set_to_full),
.clear (set_to_empty),
.data_in (1'b1),
.data_out (buffer_full)
);
然后是最為重要的邏輯模塊,我們可以發(fā)現(xiàn),在非循環(huán)模式下,input_ready和output_valid是互斥的,這也就完成了我們之前所說的每次只能完成一邊的握手。
在完成輸入握手之后將full信號拉高,并將數(shù)據(jù)寫入buffer,在完成輸出握手之后,將empty信號拉高。同時我們看到,在初始情況下,內(nèi)部為empty,所以必須先完成empty->full->empty這個流程,這與我們預(yù)期相符。
always @(*) begin
input_ready = (buffer_full == 1'b0) || (CIRCULAR_BUFFER != 0);
output_valid = (buffer_full == 1'b1);
set_to_full = (input_valid == 1'b1) && (input_ready == 1'b1);
set_to_empty = (output_valid == 1'b1) && (output_ready == 1'b1) && (set_to_full == 1'b0);
set_to_empty = (set_to_empty == 1'b1) || (clear == 1'b1);
half_buffer_load = (set_to_full == 1'b1);
end
endmodule
3.Skid Buffer
3.1 Skid Buffer是什么?
那么有沒有其他方法能夠解決問題的同時,避免到Half-Buffer帶來的損耗呢?如果輸入輸出同時允許握手帶來的后果是可能在阻塞的情況下沖刷掉內(nèi)部的有效數(shù)據(jù),那么如果我們讓內(nèi)部不止一個Buffer是不可以解決這個問題呢?
Skid Buffer就是這么來的,它其實是是一個最小的FIFO,深度為2,一個用于輸出,一個用來緩存,同時在緩存的這個周期,就能將下一級的阻塞信號傳遞到上級,這樣便可以在允許兩次同時握手,消除Half-Buffer帶來的兩個周期和最大帶寬的損耗的同時,擁有更好的布局布線空間。
3.2 Skid Buffer源碼分析
這里我們同樣選取fpgacpu網(wǎng)站上的源碼進行講解(ps:這個真的是最近發(fā)現(xiàn)的最寶藏的網(wǎng)站,之后如果有時間,可以會出一個專門介紹和解析這個網(wǎng)站源碼的一個專欄)
首先是接口部分,需要注意的是,此處的CIRCULAR_BUFFER部分非0 時候,是指可以在內(nèi)部數(shù)據(jù)已經(jīng)滿的情況下,進行覆蓋,同理,我們對該模式不做解析。
`default_nettype none
module Pipeline_Skid_Buffer
#(
parameter WORD_WIDTH = 0,
parameter CIRCULAR_BUFFER = 0 // non-zero to enable
)
(
input wire clock,
input wire clear,
input wire input_valid,
output wire input_ready,
input wire [WORD_WIDTH-1:0] input_data,
output wire output_valid,
input wire output_ready,
output wire [WORD_WIDTH-1:0] output_data
);
localparam WORD_ZERO = {WORD_WIDTH{1'b0}};
然后是數(shù)據(jù)部分,我們可以清楚地看到,此處使用了兩個Buffer,data_buffer_out為緩存buffer,output_Data為輸出的數(shù)據(jù),通過2mux1來決定輸出來源于緩存還是input_data。他這個地方還有個聰明之處在于他將數(shù)據(jù)通路和狀態(tài)解耦,這樣大大的便捷了整體的設(shè)計,是一個值得學(xué)習(xí)的地方。
reg data_buffer_wren = 1'b0; // EMPTY at start, so don't load.
wire [WORD_WIDTH-1:0] data_buffer_out;
Register
#(
.WORD_WIDTH (WORD_WIDTH),
.RESET_VALUE (WORD_ZERO)
)
data_buffer_reg
(
.clock (clock),
.clock_enable (data_buffer_wren),
.clear (clear),
.data_in (input_data),
.data_out (data_buffer_out)
);
reg data_out_wren = 1'b1; // EMPTY at start, so accept data.
reg use_buffered_data = 1'b0;
reg [WORD_WIDTH-1:0] selected_data = WORD_ZERO;
always @(*) begin
selected_data = (use_buffered_data == 1'b1) ? data_buffer_out : input_data;
end
Register
#(
.WORD_WIDTH (WORD_WIDTH),
.RESET_VALUE (WORD_ZERO)
)
data_out_reg
(
.clock (clock),
.clock_enable (data_out_wren),
.clear (clear),
.data_in (selected_data),
.data_out (output_data)
);
接下來是最為重要的控制部分,首先我們先來將系統(tǒng)劃分為以下幾個狀態(tài):
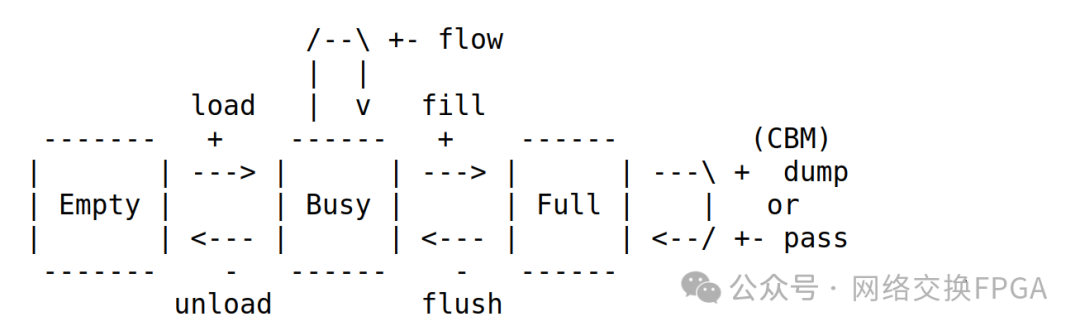
Empty:輸出和緩存區(qū)都沒有數(shù)據(jù)。
Busy :在輸出寄存器有一個有效值待處理,緩存區(qū)為空。
Full : 輸出寄存器和緩存區(qū)都有有效數(shù)據(jù)待處理 。
需要注意的是,在Empty下,只支持輸入側(cè)的握手,在Full模式下,只支持輸出側(cè)的握手,這樣可以有效防止數(shù)據(jù)的覆蓋和重復(fù)讀取。
我們來看一下每個狀態(tài)之間的轉(zhuǎn)換條件:
load:緩存區(qū)和輸出寄存器為空,數(shù)據(jù)直接載入輸出寄存器。(輸入握手,輸出沒握手)
fill:輸出寄存器為空,將數(shù)據(jù)載入緩存區(qū)。(輸入握手,輸出沒握手)
flow:輸出寄存器的值被下級接收的同時,將輸入的數(shù)據(jù)載入到輸出寄存器。(輸入輸出同時握手)
flush:輸出寄存器的值被下級接受,將緩存區(qū)的有效數(shù)據(jù)載入輸出寄存器(輸入沒握手,輸出握手)
unload:輸出寄存器的被下級接受,現(xiàn)在輸出和緩存區(qū)都為空。(輸入沒握手,輸出握手)。
在得到所有的轉(zhuǎn)化條件之后,我們還需要去決定輸入的ready和輸出valid信號。我們只需要在當前非滿時拉高ready信號,在當前非空的時候拉高valid信號即可。
Register
#(
.WORD_WIDTH (1),
.RESET_VALUE (1'b1) // EMPTY at start, so accept data
)
input_ready_reg
(
.clock (clock),
.clock_enable (1'b1),
.clear (clear),
.data_in ((state_next != FULL) || (CIRCULAR_BUFFER != 0)),
.data_out (input_ready)
);
Register
#(
.WORD_WIDTH (1),
.RESET_VALUE (1'b0)
)
output_valid_reg
(
.clock (clock),
.clock_enable (1'b1),
.clear (clear),
.data_in (state_next != EMPTY),
.data_out (output_valid)
);
然后,在輸入握手時插入數(shù)據(jù),在輸出握手時移除數(shù)據(jù):
reg insert = 1'b0;
reg remove = 1'b0;
always @(*) begin
insert = (input_valid == 1'b1) && (input_ready == 1'b1);
remove = (output_valid == 1'b1) && (output_ready == 1'b1);
end
最后便是狀態(tài)的轉(zhuǎn)化和數(shù)據(jù)通路的選擇部分,在此不做贅述。
reg load = 1'b0; // Empty datapath inserts data into output register.
reg flow = 1'b0; // New inserted data into output register as the old data is removed.
reg fill = 1'b0; // New inserted data into buffer register. Data not removed from output register.
reg flush = 1'b0; // Move data from buffer register into output register. Remove old data. No new data inserted.
reg unload = 1'b0; // Remove data from output register, leaving the datapath empty.
reg dump = 1'b0; // New inserted data into buffer register. Move data from buffer register into output register. Discard old output data. (CBM)
reg pass = 1'b0; // New inserted data into buffer register. Move data from buffer register into output register. Remove old output data. (CBM)
always @(*) begin
load = (state == EMPTY) && (insert == 1'b1) && (remove == 1'b0);
flow = (state == BUSY) && (insert == 1'b1) && (remove == 1'b1);
fill = (state == BUSY) && (insert == 1'b1) && (remove == 1'b0);
unload = (state == BUSY) && (insert == 1'b0) && (remove == 1'b1);
flush = (state == FULL) && (insert == 1'b0) && (remove == 1'b1);
dump = (state == FULL) && (insert == 1'b1) && (remove == 1'b0) && (CIRCULAR_BUFFER != 0);
pass = (state == FULL) && (insert == 1'b1) && (remove == 1'b1) && (CIRCULAR_BUFFER != 0);
end
always @(*) begin
data_out_wren = (load == 1'b1) || (flow == 1'b1) || (flush == 1'b1) || (dump == 1'b1) || (pass == 1'b1);
data_buffer_wren = (fill == 1'b1) || (dump == 1'b1) || (pass == 1'b1);
use_buffered_data = (flush == 1'b1) || (dump == 1'b1) || (pass == 1'b1);
end
endmodule
4.剛玉中的流水代碼分析
在開源代碼剛玉中大量運用了流水線,我們以其為例子進行分析。我們以其axi_register_rd中對于ar port的流水處理進行分析。
剛玉采用了三種可選方式,bypass,Half-Buffer以及Skid-Buffer。我們針對其后兩種進行分析。需要說明的是,其中s_axi為輸入側(cè),m_axi為輸出側(cè)。ps:剛玉的作者Alex的代碼水平真的十分高,他經(jīng)常用一些互斥條件的組合來代替狀態(tài)機的書寫,所以對我來說想要理解往往需要花費一定的時間。
4.1 剛玉中的Half-Buffer
// enable ready input next cycle if output buffer will be empty
wire s_axi_arready_early = !m_axi_arvalid_next;
always @* begin
// transfer sink ready state to source
m_axi_arvalid_next = m_axi_arvalid_reg;
store_axi_ar_input_to_output = 1'b0;
if (s_axi_arready_reg) begin
m_axi_arvalid_next = s_axi_arvalid;
store_axi_ar_input_to_output = 1'b1;
end else if (m_axi_arready) begin
m_axi_arvalid_next = 1'b0;
end
end
我們可以看到,只有在輸出側(cè)在下一拍為低的時候,才拉高輸入側(cè)的ready信號,保證每一拍只有一側(cè)的握手是可以完成的。
然后在輸入側(cè)ready的情況下,將上一級的有效信號傳遞到輸出寄存器,這里比較有意思的是,他沒有等到輸入握手成功再傳遞,而是直接傳遞,這是因為輸入側(cè)的ready和輸出側(cè)的valid是互斥的,即使沒有握手就傳遞,也不會出現(xiàn)兩邊同時握手的情況。
如果輸入側(cè)的ready無效,但是輸入側(cè)的ready有效時,將下一拍的輸出側(cè)的有效信號拉低,我當初看到這里很疑惑,后來一想其實很簡單,因為輸入側(cè)的ready無效就意味著當前拍的輸出側(cè)valid肯定是拉高的,這句話其實可以理解成完成輸出側(cè)握手后,將已經(jīng)處理過的有效信號拉低的操作。
4.2 剛玉中的Skid-Buffer
wire s_axi_arready_early = m_axi_arready | (~temp_m_axi_arvalid_reg & (~m_axi_arvalid_reg | ~s_axi_arvalid));
always @* begin
// transfer sink ready state to source
m_axi_arvalid_next = m_axi_arvalid_reg;
temp_m_axi_arvalid_next = temp_m_axi_arvalid_reg;
store_axi_ar_input_to_output = 1'b0;
store_axi_ar_input_to_temp = 1'b0;
store_axi_ar_temp_to_output = 1'b0;
if (s_axi_arready_reg) begin
// input is ready
if (m_axi_arready | ~m_axi_arvalid_reg) begin
// output is ready or currently not valid, transfer data to output
m_axi_arvalid_next = s_axi_arvalid;
store_axi_ar_input_to_output = 1'b1;
end else begin
// output is not ready, store input in temp
temp_m_axi_arvalid_next = s_axi_arvalid;
store_axi_ar_input_to_temp = 1'b1;
end
end else if (m_axi_arready) begin
// input is not ready, but output is ready
m_axi_arvalid_next = temp_m_axi_arvalid_reg;
temp_m_axi_arvalid_next = 1'b0;
store_axi_ar_temp_to_output = 1'b1;
end
end
首先還是先來分析輸入側(cè)的ready信號,可以看到,他拉高的條件有兩個,首先是輸入側(cè)的ready為高,這是為什么?我們來簡單分析一下,當輸出側(cè)的ready為高的時候,他的輸出寄存器主要有效,那么一定會被讀取,所以當前狀態(tài)永遠不會是full,所以可以拉高。
第二個條件:
(~temp_m_axi_arvalid_reg & (~m_axi_arvalid_reg | ~s_axi_arvalid))
我們來解析一下,首先他要求緩存寄存器為空的同時,輸入側(cè)和輸出寄存器不能同時有待處理的請求,這個也很好理解,我們這個系統(tǒng)最大的待處理請求只能是兩個,如果不滿足以上條件,那么系統(tǒng)中可能會出現(xiàn)待處理請求,緩存區(qū)的請求有被覆蓋的風險。
if (s_axi_arready_reg) begin
// input is ready
if (m_axi_arready | ~m_axi_arvalid_reg) begin
// output is ready or currently not valid, transfer data to output
m_axi_arvalid_next = s_axi_arvalid;
store_axi_ar_input_to_output = 1'b1;
end else begin
// output is not ready, store input in temp
temp_m_axi_arvalid_next = s_axi_arvalid;
store_axi_ar_input_to_temp = 1'b1;
end
然后就是接下來的部分,我們看到,在輸入側(cè)ready的情況下,如果輸出側(cè)ready有效或者沒有待處理的請求時,可以將新的請求從輸入加載到輸出寄存器。又是很奇怪是不是?這里真的感嘆一句Alex的水平之高,好了,我們來認真分析一下,如果輸出側(cè)ready有效,那意味著當前狀態(tài)不為full,那么任何被傳遞的請求都是可以被下級處理的,同理,如果下級已經(jīng)沒有待處理的請求,那么自然可以加載新的有效請求。然后,如果下級不能處理新的請求的時候,也就是對應(yīng)我們之前的BUSY狀態(tài)下,可以完成輸入側(cè)握手,不能完成輸出側(cè)握手的時候,我們就需要把輸入側(cè)的請求存入緩存區(qū)。
end else if (m_axi_arready) begin
// input is not ready, but output is ready
m_axi_arvalid_next = temp_m_axi_arvalid_reg;
temp_m_axi_arvalid_next = 1'b0;
store_axi_ar_temp_to_output = 1'b1;
end
最后,便是輸出側(cè)可以完成握手,但是輸入側(cè)不能完成的時候,對應(yīng)之前的flush狀態(tài),輸出寄存器被下級讀取之后,我們把緩存區(qū)的數(shù)據(jù)載入到輸出寄存器即可。
5.結(jié)語
文章主要分析了流水線中的Half-Buffer與Skid-Buffer的使用,之后如果有機會,將繼續(xù)分享更多DE技巧。
-
處理器
+關(guān)注
關(guān)注
68文章
19658瀏覽量
232467 -
流水線
+關(guān)注
關(guān)注
0文章
123瀏覽量
26381 -
模型
+關(guān)注
關(guān)注
1文章
3448瀏覽量
49706
原文標題:Half-Buffer與Skid-Buffer介紹及其在流水線中的應(yīng)用
文章出處:【微信號:gh_cb8502189068,微信公眾號:網(wǎng)絡(luò)交換FPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA中的流水線設(shè)計
現(xiàn)代RISC中的流水線技術(shù)
周期精確的流水線仿真模型
流水線中的相關(guān)培訓(xùn)教程[1]
流水線中的相關(guān)培訓(xùn)教程[3]
流水線中的相關(guān)培訓(xùn)教程[4]
采用單通道通訊協(xié)議設(shè)計高速異步流水線控制器STFB電路的設(shè)計
各種流水線特點及常見流水線設(shè)計方式
滾筒輸流水線故障排除方法
如何選擇合適的LED生產(chǎn)流水線輸送方式
嵌入式_流水線






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論