


作者 / 主任工程師 Cormac Brick,軟件工程師 Advait Jain,軟件工程師 Haoliang Zhang
我們很高興地發布 Google AI Edge Torch,可將 PyTorch 編寫的模型直接轉換成 TFLite 格式 (.tflite),且有著優異的模型覆蓋率和 CPU 性能。TFLite 已經支持 Jax、Keras 和 TensorFlow 編寫的模型,現在我們加入了對 PyTorch 的支持,進一步豐富了框架選擇。
這一新產品現已作為 Google AI Edge 的一部分提供。Google AI Edge 是一套易于使用的工具,包含可直接使用的機器學習 (ML) 任務、構建機器學習流水線的框架,以及運行流行的大語言模型 (LLM) 和自定義模型的能力——所有這些都可在設備上運行。本文是 Google AI Edge 博客連載中的第一篇,用于幫助開發者們構建 AI 功能,并輕松地將其部署至多個平臺。
今天發布的 AI Edge Torch Beta 版本包含以下特性:
直接集成 PyTorch
出色的 CPU 性能和初步 GPU 支持
在 torchvision、timm、torchaudio 和 HuggingFace 里的 70 多個模型上得到驗證
支持超過 70% 的 PyTorch core_aten 算子
兼容現有的 TFLite 運行時,無需更改部署代碼
支持在工作流的多個階段進行模型探索器 (Model Explorer) 可視化
以 PyTorch 為中心的簡潔體驗
Google AI Edge Torch 從一開始就致力于為 PyTorch 社區提供卓越的開發體驗,API 使用起來感覺非常原生,并提供簡便的模型轉換路徑。
import torchvision import ai_edge_torch # Initialize model resnet18 = torchvision.models.resnet18().eval() # Convert sample_input = (torch.randn(4, 3, 224, 224),) edge_model = ai_edge_torch.convert(resnet18, sample_input) # Inference in Python output = edge_model(*sample_input) # Export to a TfLite model for on-device deployment edge_model.export('resnet.tflite'))
在底層,ai_edge_torch.convert()使用 torch.export 集成了 TorchDynamo——在 PyTorch 2.x 中,這個方法用于將 PyTorch 模型導出為標準化的模型形式,從而在不同環境中運行。我們目前的實現支持超過 70% 的 core_aten 算子,這個比例會在構建 ai_edge_torch 1.0 版本的過程中大幅增加。我們還提供了 PT2E 量化的示例,這是 PyTorch2 原生的量化方法,以簡化量化工作的流程。我們很期待聽到來自 PyTorch 社區的反饋,以進一步改善開發者體驗,從而幫助大家更好地把用 PyTorch 打造的新穎體驗部署至更多樣的設備中。
模型覆蓋和性能
在此版本發布之前,許多開發者使用社區提供的轉換方法,如 ONNX2TF,在 TFLite 中運行 PyTorch 模型。我們開發 AI Edge Torch 的目標是減少開發過程中的阻力,提供出色的模型覆蓋率,并繼續完成我們的使命: 在 Android 設備上提供最佳的性能。
在覆蓋率方面,我們的測試表明,與現有工作流程 (尤其是 ONNX2TF) 相比,AI Edge Torch 在給定的模型集合上的覆蓋率有顯著的提高。
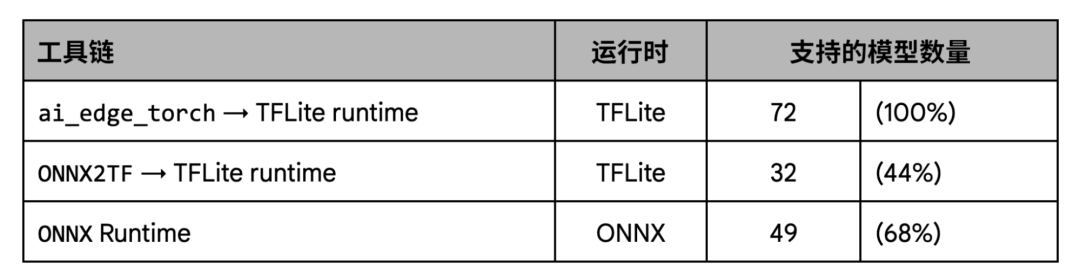
在性能方面,我們的測試顯示 AI Edge Torch 與 ONNX2TF 的基準性能表現相當,比 ONNX 運行時相比則有著更好的性能。
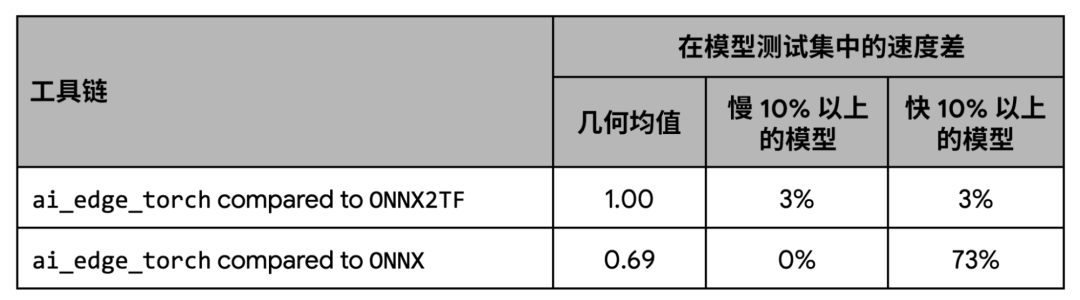
下圖顯示了在 ONNX 覆蓋的模型子集上的每個模型的詳細性能:
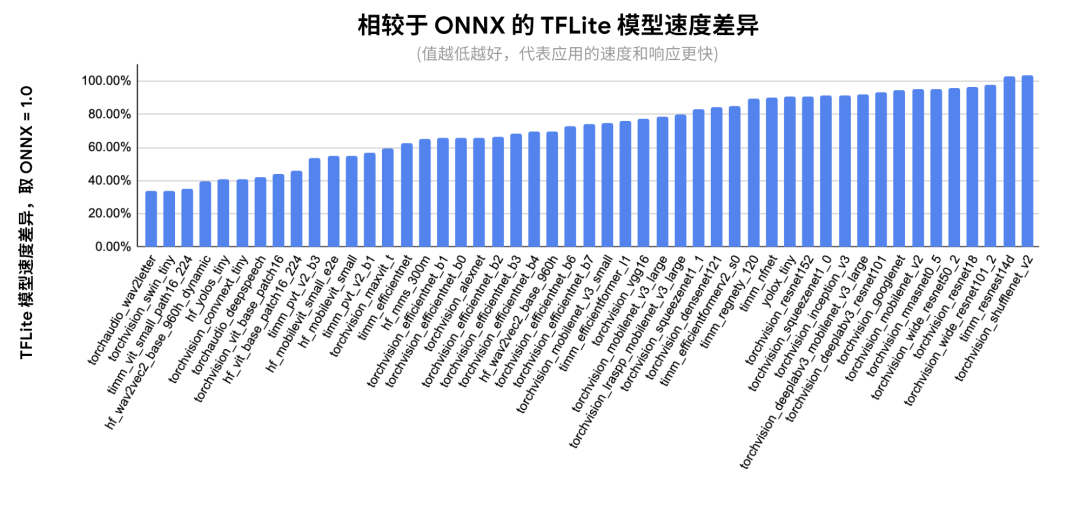
△ 相對于 ONNX 的每個網絡的推理延遲。以 Pixel 8 為測試設備,使用 fp32 精度。XNNPACK 固定為 4 個線程以確保復現性,經過 20 次迭代預熱后取 100 次運行的均值
早期體驗用戶和合作伙伴
在過去的幾個月中,我們與參與早期體驗的合作伙伴們密切合作,包括 Shopify、Adobe 和 Niantic,以改進我們的 PyTorch 支持。ai_edge_torch 已經被 Shopify 團隊用來在設備上去除產品圖像的背景,這個功能會出現在不久后發布的 Shopify 應用中。
芯片合作伙伴和代理
我們還和 Arm、Google Tensor G3、聯發科技、高通、三星 System LSI 這些合作伙伴們一起,提供跨 CPU、GPU 和加速器的硬件支持。我們通過這些合作提高了產品的性能和覆蓋率,并在加速器代理上驗證了由 PyTorch 生成的 TFLite 文件。
我們也很榮幸地和高通共同宣布新的 TensorFlow Lite 代理,現已開放供所有開發者使用。TFLite 代理是附加的軟件模塊,可提升在 GPU 和硬件加速器上的執行速度。這個新的 QNN 代理支持我們在 PyTorch Beta 測試集中用到的大多數模型,并提供對高通芯片的廣泛支持。通過使用高通的 DSP 和神經處理單元,相比僅使用 CPU 和 GPU 的場景,能明顯地提升運行速度 (相較 CPU 平均提升 20 倍,GPU 平均提升 5 倍)。為了方便測試,高通最近還發布了新的 AI Hub。高通 AI Hub 是一個云服務,可以讓開發者在一系列 Android 設備上對 TFLite 模型進行測試,并在使用 QNN 代理的設備上提供性能增益的可見性。
下一步
在接下來的幾個月中,我們將繼續在開放的環境中對產品進行迭代,朝著 1.0 版本努力,包括提升模型覆蓋率、改進 GPU 支持,提供新的量化模式。在本系列的第二篇文章中,我們將更深入地介紹 AI Edge Torch 生成式 API,這個 API 能讓開發者們在邊緣設備中運行自定義生成式 AI 模型,并且提供優秀的性能表現。
我們要感謝所有早期體驗用戶,正是他們提供的寶貴反饋讓我們得以及早發現錯誤,并確保開發者們獲得順暢的體驗。我們還要感謝硬件合作伙伴以及 XNNPACK 生態系統的貢獻者,是他們的幫助讓我們在如此多樣的設備上都能獲得優異的性能表現。同時,我們也要感謝廣大的 PyTorch 社區在這一路提供的指導和支持。
-
Google
+關注
關注
5文章
1791瀏覽量
59244 -
移動設備
+關注
關注
0文章
519瀏覽量
55309 -
AI
+關注
關注
88文章
35693瀏覽量
282214 -
模型
+關注
關注
1文章
3546瀏覽量
50710 -
機器學習
+關注
關注
66文章
8513瀏覽量
135059
原文標題:AI Edge Torch: 在移動設備上實現高性能的 PyTorch 模型推理
文章出處:【微信號:Google_Developers,微信公眾號:谷歌開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何使用torch 2.0或更高版本創建圖像?
EDGE技術詳解
一文看懂谷歌的AI芯片布局
Google之后 微軟宣布暫停Chromium Edge版本更新
Edge AI在深度學習應用中超越云計算
PyTorch中 torch.nn與torch.nn.functional的區別

Edge AI工控機的定義、挑選考量與常見應用
在設備上利用AI Edge Torch生成式API部署自定義大語言模型

面向AI與機器學習應用的開發平臺 AMD/Xilinx Versal? AI Edge VEK280





 工商網監
工商網監

評論