 從產業落地以及學術創新兩種視角出發,探索后深度學習時代的新挑戰
從產業落地以及學術創新兩種視角出發,探索后深度學習時代的新挑戰
編者按:在工業界大量資源的投入下,大數據、大規模GPU集群帶來了深度學習在計算機視覺領域的全面產業落地,在很多競賽中甚至取得遠超學術界的成績。在AI領域的各個頂級會議上,越來越多的優秀工作也來自于Google、Facebook、BAT等巨頭或者一些新銳創業公司。
值得注意的是,工業界目前的主要進展和應用落地,很大程度上依賴于高成本的有監督深度學習。而在很多實際場景中,存在數據獲取成本過高、甚至無法獲取的問題。因此,在數據不足的情況下,如何使用弱監督、乃至無監督的方式進行學習,這既是學術界中大家廣泛關注的問題,其實也是工業界面臨的新挑戰。
商湯科技研發總監、中山大學教授林倞,將從產業落地以及學術創新兩種視角出發,帶領大家一起探索“后深度學習時代”的新挑戰。
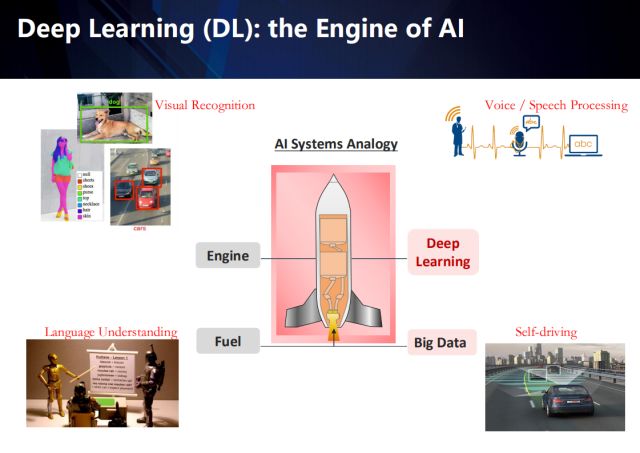
如果把AI系統比作為一架火箭,那么大數據就是它的燃料,深度學習則是它的引擎。隨著大數據以及GPU算力的加持,深度學習在很多領域都取得了突破性的進展,例如視覺圖像理解、屬性識別、物體檢測、自然語言處理、乃至自動駕駛。當然了,垂直化應用場景才是AI技術落地不可或缺的因素,這其實也是在工業界做研究的最大優勢——從真實的需求引導技術的發展,而學術界的科研往往基于一些不太實際的假設。
基于視覺的圖像理解,是從有標注的數據學習出AI算法,以實現相應的視覺識別任務,左上角展示了視覺圖像理解中的物體檢測以及屬性識別應用。

而值得注意的是,深度學習在計算機視覺領域的成功應用,很大程度上依賴于有監督的數據,這意味著大量的完全標注的干凈數據(例如人臉識別領域的數據)。然而,這樣的數據意味著非常高昂的成本。在真實的場景中,經常存在的是弱監督或者從互聯網上獲取的數據(例如網絡社交媒體的數據),以及無標注或者標注有噪聲的數據(例如智慧城市以及自動駕駛等應用中采集到的數據)。
LeCun教授曾用右圖的蛋糕,來形容有監督學習、無監督學習、以及強化學習之間的區別,這里借用來說明這三種數據的區別:完全標注的干凈數據就像蛋糕上的金箔櫻桃,甜美卻昂貴;而弱標注或互聯網爬取的數據,就像蛋糕上的奶油,還算甜但也可獲取;而無標注的或者標注有噪聲的數據,不太甜但成本較低。

在本次報告中,我將首先介紹深度學習如何應用于視覺理解,接下來會從三個方面介紹最新的深度學習范式:
以豐富多源的弱監督信息來輔助學習
算法自驅動、具有高性價比(性能/監督信息成本)的自主學習
無監督領域自適應學習
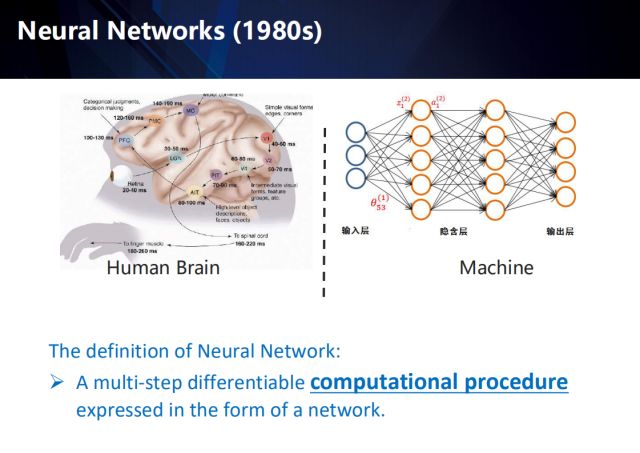
首先介紹一下深度學習的基本概念,深度學習被定義為最終以網絡形式呈現的、涵蓋了多個步驟的、可微分的計算過程。而說起深度學習,就要從上世紀80年代的神經網絡開始講起。神經網絡其命名的初衷,是向人腦中的神經網絡致敬。那么人腦中是如何處理視覺信號呢?
首先,視網膜輸入視覺信號,經過LGN外膝體,到達視覺皮層V1—V5,其中V1對邊緣和角點敏感,V2捕捉運動信息, V4對part物件敏感,例如人的眼睛、胳膊等,最后到達AIT,來處理高層信息:臉、物體等。送到PFC決策層,最后由MC發出指令。所以人腦處理視覺信號是一個從淺層到深層的過程,而在此過程中,并不是一個單一的處理,它還具備時序性,也就是說它在處理每個信號時,都是利用了之前的時序信息的。
深度神經網絡的形式和計算過程與人腦有很大的不同,不過它的發明的確是受到了神經信號處理的啟發,例如經典的感知機模型其實是對神經元最基本概念的模擬。右上展示了1980年發明的多層感知機。

從1980年代的多層感知機到2010年的卷積神經網絡,它經歷了一個層數由少至多、層級由淺至深的過程,通過解決網絡梯度消失以及泛化不好的問題,以及數據及GPU的加持,它終于實現了一個一站式的端到端的網絡。
自2010年起,深度學習方法取得了遠超傳統機器學習方法的成績,尤其隨著訓練數據集的不斷擴展,傳統方法迅速觸碰到精度天花板,相比之下,深度方法的預測精度則不斷提升。這里總結了這一波深度學習技術革新的幾個關鍵點,包括新的網絡優化方法,如ReLu,Batch Normally,Skip Connection等;從數學/知識驅動到數據驅動的研究思路的轉變;分治優化逐漸過渡到聯合端到端聯合優化;從避免過擬合學習到避免欠擬合學習;大量的開源代碼和初始化模型的涌現。
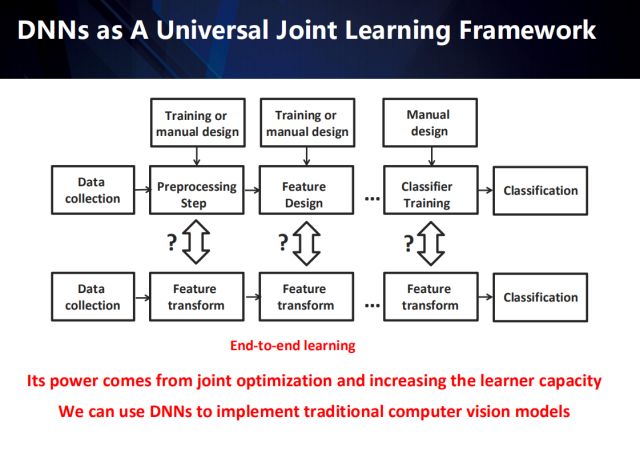
傳統的模式識別任務,大致可總結為幾個獨立的步驟:包括數據采集、數據預處理、特征提取、分類器訓練以及最終的分類。其中,數據預處理器和特征提取器的設計都是以經驗為驅動的。而深度學習通過將預處理、特征提取以及分類訓練任務融合,因此衍生出了一個,具有更強表示能力的端到端的特征轉換網絡。
在傳統模式識別方法到深度方法的演變過程中,我們越來越體會到學習的重要性,而特征學習也已進化成一個端到端的學習系統,傳統方法中的預處理已不是必須手段,而被融入端到端的系統中。似乎特征學習影響著一切模式識別任務的性能,然而,我們卻忽視了數據收集和評估的重要性。
接下來我們舉例說明傳統方法是如何演化為深度方法的。
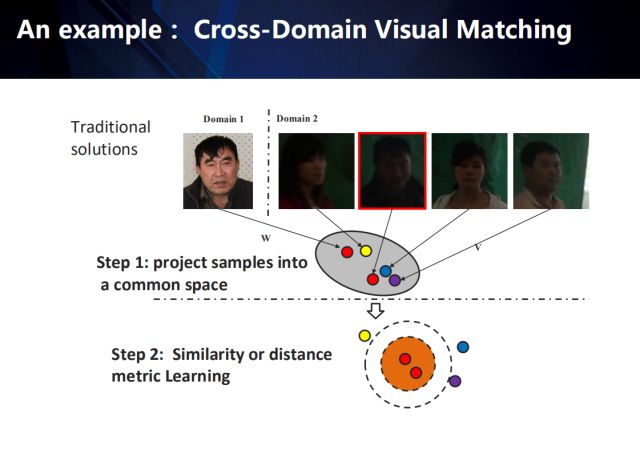
以跨領域視覺匹配任務(從領域2的數據中匹配到給定的領域1中的目標)為例,傳統的方法一般會包含以下兩個步驟:
首先,將來自于不同領域的樣本投影到一個公共的特征空間 (特征學習);
然后,采用相似性或距離度量學習的方式,學習到一種距離度量,來表征這個公共空間上特征之間的相似性 (相似性度量學習)。
那么如何將這種相似性的度量整合到深度神經網絡中,并進行端到端的學習呢?
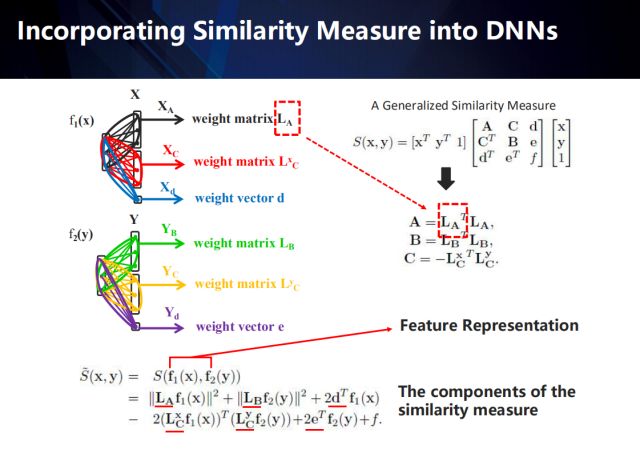
如何把相似性度量融合到特征提取中去?
以右上公式表示的相似性度量方法為例 (度量模型的提出和推導請參加相關論文),我們可以將該度量模型分解后融入到神經網絡中——將原來的全連接網絡表示成成若干個與度量模型相匹配的結構化網絡。再通過誤差反向傳導,可以將度量模型與卷積特征進行聯合學習、統一優化。詳細過程如下:
右上公式中, A矩陣為x樣本所在領域中樣本間的自相關矩陣,半正定; B矩陣表示y樣本所在領域中樣本間的自相關矩陣,半正定;C矩陣則是兩個領域樣本間的相關矩陣。
展開后我們可以發現,其組成成分除了網絡從不同域提取到的特征外,還包含6個不同的表達距離度量模型的變量(每個域包含2個矩陣和1個向量)。圖中左上部分顯示了我們將分解后的距離度量變量融入到神經網絡中的過程——結構化的網絡模型。
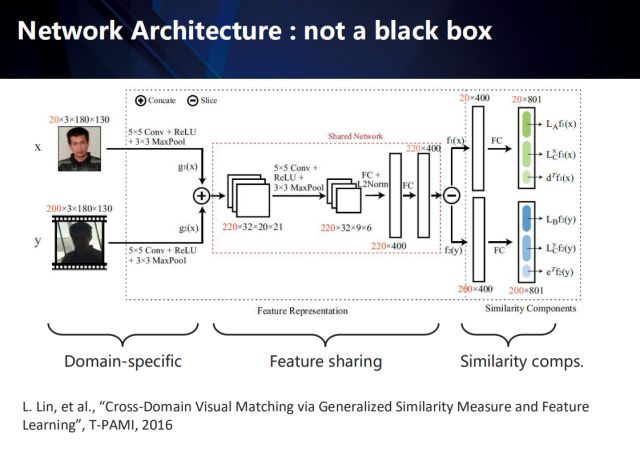
由此看來,深度網絡并不是完全的黑盒子,通過引入領域知識和結構化模型,是可以具備一定的宏觀解釋性的。
以跨域視覺匹配算法為例,其內部可歸納為三個部分:域獨有層、特征共享層、以及相似度量。
整個端到端的網絡如圖所示,其每個部分都具有可解釋性。
在域獨有層,該網絡為不同域的數據提取該域的獨有特征;
在特征共享層,我們首先將不同域的特征融合,再將融合后的特征投影到共有空間下,再反向拆解出各自域在該共有空間下的特征;
最終通過相似性度量得到不同域樣本間的匹配相似度。
相關的工作發表在T-PAMI 2016上,該模型在當時很多領域取得了state-of-the-arts的效果。

我們的驗證基準包括的幾個主要任務:年齡人臉驗證、跨攝像頭的行人再識別、素描畫與照片間的匹配、以及靜態圖片與靜態視頻間的匹配。
相比較之下,在公司做深度學習則充分發揮了海量計算資源和充足數據量的優勢,學術界精心設計的算法優勢很容易被工程化的能力抵消。
此外,區別于學術界只關注算法本身的模式,在工業界做產品,則涉及到大量的環節,不同的場景會衍生出不同的問題,此時通過應用場景形成數據閉環成為關鍵。商湯投入了大量資源建設基礎平臺、工程化團隊,通過深入各個垂直領域、積攢行業數據、建立行業壁壘,目前正在從AI平臺公司逐漸向AI產品公司過渡。

在工業界大量資源的投入下,大數據、大規模GPU集群帶來了深度學習在計算機視覺領域的全面產業落地,在很多競賽中甚至取得遠超學術界的成績。值得注意的是,工業界的這些進展的取得,是依賴于大量的全監督數據的,而在很多實際場景中,存在數據獲取成本過高、甚至無法獲取的問題。2012年以來,深度學習技術的高速發展并且在圖像、語音等各個領域的取得了大量的成功應用,如果把這5年看成是一個新的技術時代, 那么在“后深度學習”時代,我們更應該關注哪些方向呢?
我在這個報告中給出一些想法——介紹3個新的深度學習范式:
以豐富多源的弱監督信息來輔助學習
算法自驅動、成本效益較高的自主學習
無監督領域自適應學習
Learning with Weak and Rich Supervisions

首先來介紹如何以豐富多源的弱監督信息來輔助學習。

由于網頁形式的多樣化,從互聯網上獲取的數據時常具備多種類型的標簽,然而卻不能保證標簽的準確性, 往往存在標簽噪聲 。因此,這類數據可以看作具備豐富多源的弱監督信息。那么,我們考慮通過學習多個源的弱監督信息,來對標簽進行更正。
將大量的數據連同帶有小量噪聲的標簽,一起送入深度卷積神經網絡,檢測其中的標簽噪聲并進行更正。例如,右圖展示了,通過融合圖像數據以及對應的文本描述,來輔助對標簽進行更正。
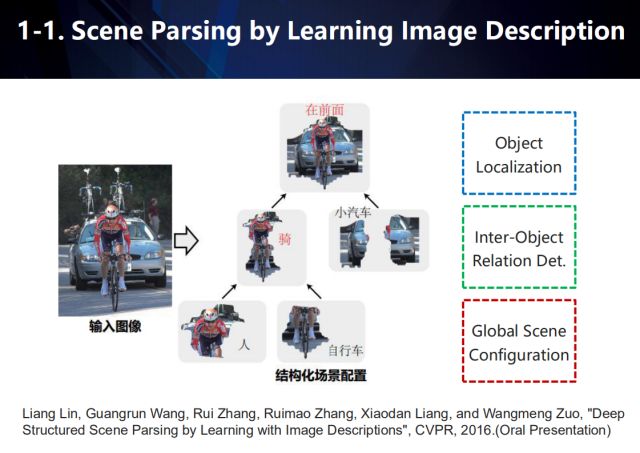
在場景解析任務中,我們通過學習圖像的描述來解析場景。如圖所示,利用物體定位來獲取場景中具有顯著性語義的物體,然后根據物體間的交互關系構建結構化場景配置。
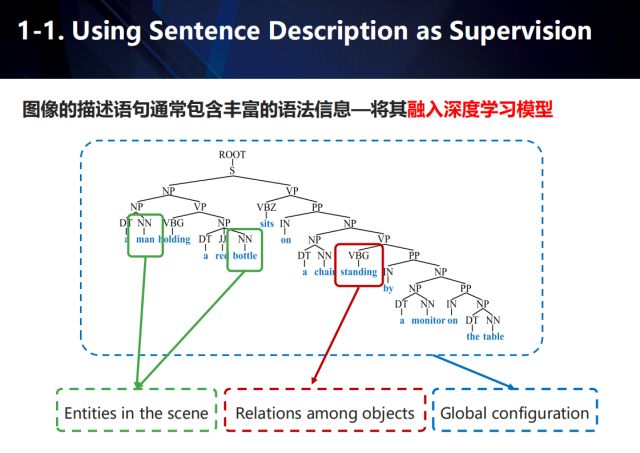
而圖像的描述語句通常包含豐富的語法信息,如果能將這些信息融入深度學習模型,那么可以將其看作一種輔助的監督手段。以對圖像描述這一應用為例,如圖所示,我們用綠色框表示場景中出現的實體,紅色框表示實體之間的關系,而藍色框表示場景的全局配置結構。
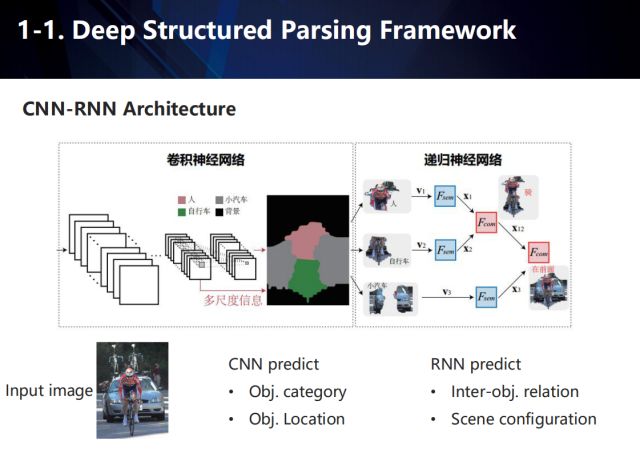
基于上述所說,我們提出了一個端到端的,結合卷積神經網絡和遞歸神經網絡的,深度結構化場景解析框架。輸入的圖片經過卷積神經網絡后,會為每個語義類別產生得分圖以及每個像素的特征表達,然后根據這些得分圖對每個像素進行分類,并將同類別的像素聚合到一起,最終獲取場景內v個目標的特征表達。然后將這v個目標的特征送入到遞歸神經網絡中,并映射到某個語義空間,提取語義以預測物體間的交互關系。其訓練過程如下:
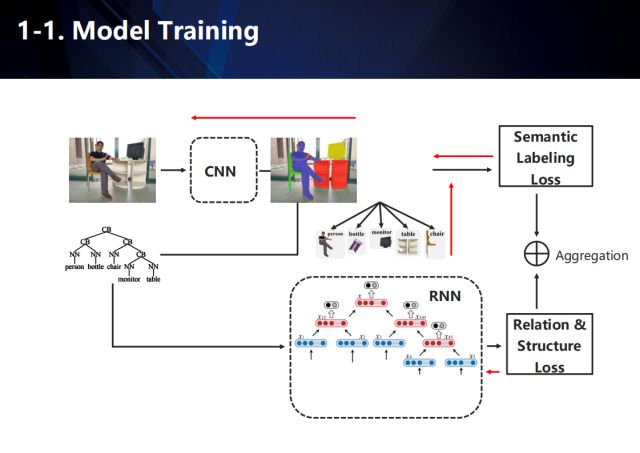
整個網絡學習的目標包含兩個,一個是卷積神經網絡部分中的場景語義標注信息,另一個則是遞歸神經網絡部分中的結構化解析結果。在訓練的過程中,由于圖像數據缺乏對應的場景結構化信息,我們需要對其進行估計,來訓練卷積神經網絡和遞歸循環神經網絡。
簡單來說,本工作的重點在于得到以下兩個目標:(1)語義標注信息,包括定位語義實體的位置和確定語義實體之間的互動關系,(2)得到語義實體中的繼承結構。
在本論文中采用的CNN-RNN聯合結構,與單一RNN方法不同之處在于模型預測了子節點和父節點之間的關系。其中,對于語義標注,我們采用CNN模型為每一個實體類生成特征表達,并將臨近的像素分組并對同類別使用同一標簽。利用CNN生成的特征,我們設計RNN模型來生成圖像理解樹來預測物體之間的關系和繼承結構,其中包括四個部分,語義映射(單層全連接層),融合(兩個子節點結合生成一個父節點),類別器(其中一個子網絡,用于確定兩個節點之間的關系,并利用父節點的特征作為輸入),打分器(另外一個子網絡,衡量兩個節點的置信度)。
本方法在學習過程中有兩個輸入,一個是圖像,另外一個圖像對應的解析句子,將圖像輸入CNN,得到圖像的實體類特征表達,同時利用語義解析生成樹方法將句子分解成語義樹,并將圖像得到的實體類與語義生成樹一同輸入到RNN網絡中,利用圖像的語義標注與關聯結構樹進行訓練,從而得到預期的結果。

語義分割和場景結構化解析在PSACALVOC 2012 和SYSU-Scene 評測集上的實驗結果展示如圖。
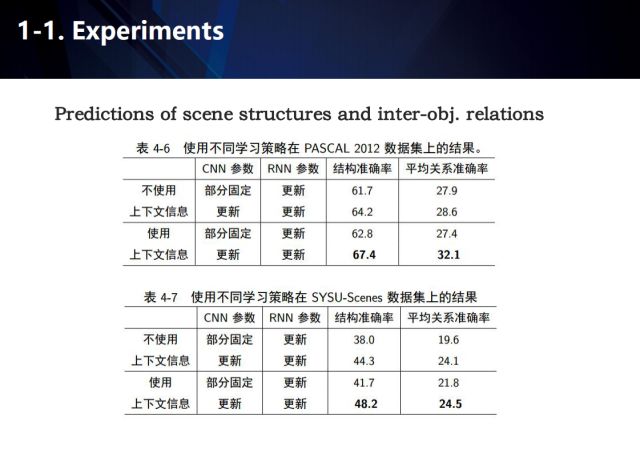
這里給出了使用不同的學習策略在PASCAL2012數據集上的結果,可以看出上下文信息被證明是一種有效的輔助手段。
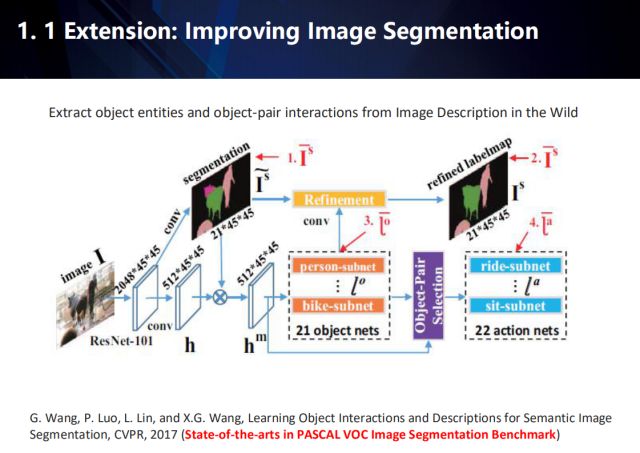
還可以擴展到圖像語義分割領域。這一工作發表在CVPR2017,目前在PASCAL VOC數據集上做到了state-of-the-arts。
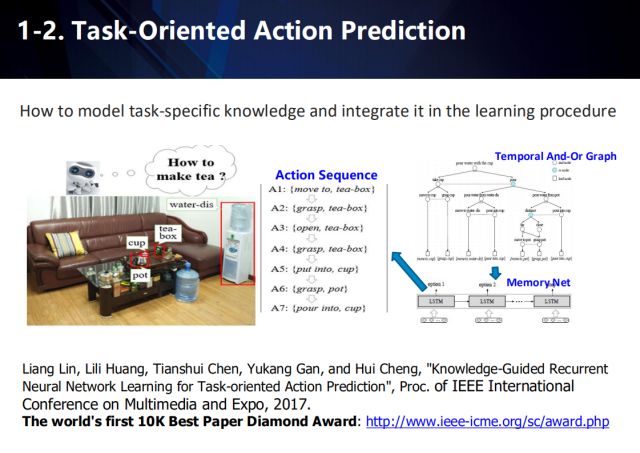
此外,在面向任務的動作預測中, 同樣可以采用弱監督學習的方式來解決需要大量標注信息的問題。這一工作獲得了The World’s First 10K Best Paper Diamond Award by ICME 2017.
這項工作首次提出了任務導向型的動作預測問題,即如何在特定場景下,自動地生成能完成指定任務的動作序列,并針對該問題進行了數據采集。在這篇論文中,作者提出使用長短期記憶神經網絡(LSTM)進行動作預測,并提出了多階段的訓練方法。為了解決學習過程中標注樣本不足的問題,該工作在第一階段采取時域與或圖模型(And-Or Graph, AOG)自動地生成動作序列集合進行數據增強,在下一階段利用增強后的數據訓練動作預測網絡。具體步驟如下。
1)為了對任務知識建模,該文引入時域與或圖(And-Or Graph, AOG)模型表達任務。AOG由四部分組成:表示任務的根節點,非終端節點集合,終端節點集合和權重分布集合。非終端節點包括與節點和或節點。其中,與節點表示將該節點的動作分解為有時序關系的子動作,或節點則表示可以完成該節點動作的不同方式,并根據概率分布P選擇其中一個子節點。終端節點包括跟該任務相關的原子動作。
2)由于AOG定義時存在的時序依賴關系,該論文利用深度優先遍歷的方法遍歷每個節點,同時利用與或圖長短期記憶模型(AOG-LSTM)預測該節點的支路選擇。
3)由于原子動作序列非常強的時序依賴關系,該論文同樣設計了一個LSTM(即Action-LSTM)時序地預測每個時刻的原子動作。具體地,原子動作Ai由一個原生動作以及一個相關物體組成,可表示為Ai=(ai, oi)。為了降低模型復雜性和預測空間的多變性,該論文假設原生動作和相關物體的預測是獨立的,并分別進行預測。
Progressive and Cost-effective Learning

接著介紹一下自驅動、成本效益較高的學習方式。
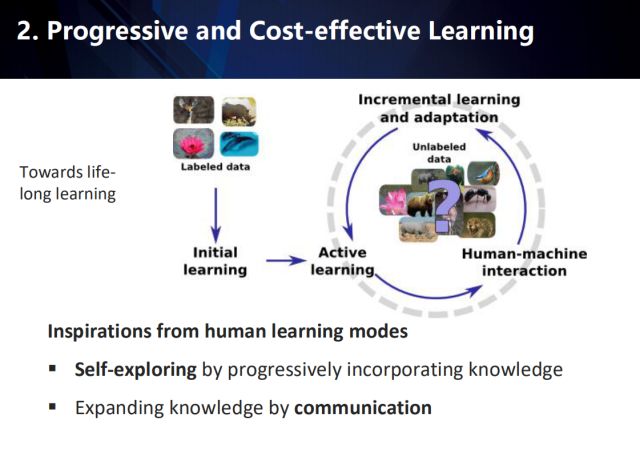
這類方法受到人類學習模式的一些啟發:一是在逐步整合學習到的知識中自我探索,二是在交流的過程中不斷擴充知識,以達到終生學習的目的。如上圖所示,在學習的初期,利用已有的標注數據進行初始化學習,然后在大量未標注的數據中不斷按照人機協同方式進行樣本挖掘,以增量地學習模型和適配未標注數據。

在自我驅動、低成本高效益的學習方式中,課程學習和自步學習是一種有效的思路。
課程學習的基本思想,是由深度學習的開創者之一,YoshuaBengio教授團隊于2009年的ICML會議上提出;而在2014年,由LuJiang等人提出了自步學習的公理化構造條件,并說明了針對不同的應用,可根據該公理化準則延伸出各種實用的課程學習方案。這些方法首先從任務中的簡單方面學習,來獲取簡單可靠的知識;然后逐漸地增加難度,來過渡到學習更復雜、更專業的知識,以完成對復雜事物的認知。

在目標檢測任務中,采用大量無標注、或者部分標注的數據進行訓練,盡管充滿挑戰,但仍然是實際視覺任務中成本效益較高的方式。對于這一挑戰,往往采用主動學習的方式來解決。而目前提出的主動學習方法,往往會利用最新的檢測器,根據一個信度閾值,來尋找檢測器難以區分的復雜樣例。通過對這些樣例進行主動標注,進而優化檢測器的性能。然而,這些主動學習的方法,卻忽視了余下大量的簡單樣例。
那么,如何既考慮到少量的復雜樣例,又充分利用到大量的簡單樣例呢?
我們提出了一種主動樣本挖掘(ASM)框架,如上圖所示。對于大量未標注的檢測數據,我們采用最新的檢測器進行檢測,并將檢測結果按照信度排序。對于信度高的檢測結果,我們直接將檢測結果作為其未標注信息;而對于少量的信度低的檢測結果,我們采用主動學習的方式來進行標注。最后,利用這些數據來優化檢測器性能。
具體來說,我們采用兩套不同的樣本挖掘方案策略函數:一個用于高置信度樣本的自動偽標注階段,另一組用于低置信度樣本的人工標注階段。我們進一步地引入了動態選擇函數,以無縫地確定上述哪個階段用于更新未標注樣本的標簽。在這種方式下,我們的自監督過程和主動學習過程可以相互協作和無縫切換,進行樣本挖掘。此外,自監督的過程還考慮了主動學習過程的指導和反饋,使其更適合大規模下物體檢測的需要。具體來說,我們引進兩個課程:自監督學習課程 (Self-Supervised learning Curriculum, SSC) 和主動學習課程 (Active Learning Curriculum, ALC)。SSC 用于表示一組具有高預測置信度,能控制對無標簽樣本的自動偽標注,而 ALC 用于表示很具有代表性,適合約束需要人工標注的樣本。值得注意的是,在訓練階段,SSC 以逐漸從簡單到復雜的方式,選擇偽標簽樣本進行網絡再訓練。相比之下,ALC 間歇地將人工標注的樣本,按照從復雜到簡單的方式,添加到訓練中。因此,我們認為 SSC 和 ALC 是對偶課程,彼此互補。通過主動學習過程來更新,這兩個對偶課程能夠有效地指導兩種完全不同的學習模式,來挖掘海量無標簽樣本。使得我們的模型在提高了分類器對噪聲樣本或離群點的魯棒性同時,也提高了檢測的精度。

Interpretation:上面優化公式由(W,Y,V,U)組成,其中W指代模型參數(物體檢測器的參數,我們的文章里面是Faster RCNN或者RFCN)。Y指代在自動標注下的物體檢測器產生的proposal的偽標注類別。V={v_i}^N_{i=1}指代自步學習過程(self-paced learning,在上式中為self-supervised process)下對每個proposal訓練實例的經驗損失權重,v_i取值為 [0,1)的一個連續值m維向量(m為類別數目)。U={u_i}^N_{i=1}指代主動學習下對每個訓練實例的經驗損失權重,u_i取值為一個{0,1}二值標量。
W是我們想要學習的參數,其余Y,V,U都可以看成是為了學習W而要推斷的隱變量。后兩個為權重隱變量,基于選擇函數(selector)作用于每個樣本訓練損失。具體來說,W的優化基于經驗損失的加權和。因此,在每次優化W之前,我們必須要知道Y (由于經驗損失為判別誤差,沒有自步學習過程下的給與的偽標注(Y),所有數據都只能利用AL的人工標注,整個方法退化為全監督學習) 。同時在優化W和Y之前,我們必須要知道U和V的值(知道每一個u_i和v_i的取值,才能決定哪些訓練實例的y值需要人工標注(自主學習AL),那些需要機器自動推斷 (自監督過程SS)。);同時,知道每一個u_i和v_i,才能基于選擇器(selector)推斷出經驗誤差的訓練權重)。給定樣本i基于u_i和v_i的值域以及選擇器可以看出,u_i=1>v_i^{j}對應樣本會被選擇為主動學習的人工標注對象,u_i=0<=v_i^{j}時對應樣本會得到自動標注。

于是,問題落在如何推斷U和V這兩個權重隱變量集合身上。容易看出U和V要聯合推斷,而如何選擇U和V則由每個訓練實例的經驗損失以及其對于各自的控制函數(f_SS, f_AL)決定。f_SS的具體解釋可以參考自步課程學習(self-paced curriculum learning),簡單的理解就是優先選擇訓練損失較小的樣本進行學習,這表現為訓練損失越小賦予的權重越大。隨著lambda變大(優化過程中,lambda和gamma都會逐漸變大),訓練會開始接納具有更大訓練誤差的樣本。f_AL相反,主動學習一開始會從訓練誤差較大的樣本(樣本誤差比較小的會被置零,從而被選擇為自監督過程并且得到自動標注)中選擇并進行人工標注。隨著gamma增大,主動學習會開始接納更小的誤差的樣本。
模型函數 f_SS代表了一種貪心的自監督的策略。它大大地節省了人工標注量,但是對于累計預測誤差造成的語義惡化無能為力。并且,f_SS極大依賴于初始參數 W。由于模型函數 f_AL存在,我們可以有效地克服這些缺點。f_AL選擇樣本給用戶進行后處理,通過f_AL獲得的人工標注被認為是可靠的,這種過程應該持續到訓練結束。值得一提的是,通過 f_SS進行的偽標注只有在訓練迭代中是可靠的,并且應該被適當的調整來引導每個階段更魯棒的網絡參數的學習。實際上,f_SS和f_AL是同時作用與每一個樣本的,這會等價于一個minimax的優化問題。
另一方面,U和V在推斷時需要考慮前一階段已經由主動學習中的人手工標記好的信息。我們利用之前的人手工標記好的信息,定義了兩個基于U和V的取值約束,稱為“對偶課程”(Dual Curricula)。該約束項將被自主學習選過的訓練樣本,如該樣本屬于m個類別之中的一類,我們將其為u和v值設定為1;如該樣本不在m個類別之中,我們將其u和v值設定為0。這意味著我們的訓練框架可以容納新類別的發掘,同時不會讓新類別影響檢測器的訓練。V^{lambda}_{i}和U^^{lambda}_{i}只基于之前AL選擇后的結果分別對u和v值進行約束。
形象來說,我們采用兩套不同的樣本挖掘方案策略函數:一個用于高置信度樣本的自動偽標注模式,另一組用于低置信度樣本的人工標注模式。我們進一步地引入了動態選擇函數,以無縫地確定上述哪個階段用于更新未標注樣本的標簽。在這種方式下,我們的自監督過程和主動學習過程可以相互協作和無縫切換,進行樣本挖掘。此外,自監督的過程還考慮了主動學習過程的指導和反饋,使其更適合大規模下物體檢測的需要。具體來說,我們引進兩個課程:自監督學習課程 (Self-Supervised learning Curriculum, SSC) 和主動學習課程 (Active Learning Curriculum, ALC)。SSC 用于表示一組具有高預測置信度,能控制對無標簽樣本的自動偽標注,而 ALC 用于表示很具有代表性,適合約束需要人工標注的樣本。值得注意的是,在訓練階段,SSC 以逐漸從簡單到復雜的方式,選擇偽標簽樣本進行網絡再訓練。相比之下,ALC 間歇地將人工標注的樣本,按照從復雜到簡單的方式,添加到訓練中。因此,我們認為 SSC 和 ALC 是對偶課程,彼此互補。通過主動學習過程來更新,這兩個對偶課程能夠有效地指導兩種完全不同的學習模式,來挖掘海量無標簽樣本。使得我們的模型在提高了分類器對噪聲樣本或離群點的魯棒性同時,也提高了檢測的精度。

基于u和v的聯合推斷構成了一個可基于訓練實例分解的minmax優化問題。對于每一個訓練實例u和v,我們證明了在滿足一定條件下,該推斷具有基于上式表達的閉式解 (具體考究這個有點復雜,可以參考我們的文章)。大概意思是,在考慮訓練實例i的類別經驗誤差和的時候,大于第一個閾值會u_i值會收斂為1 (大括號里面第一種情況)。由于v^{j}_i<1,我們知道該實例會被選作人工標注。另一方面,在類別經驗誤差和小于另一個閾值(大括號第二行第一個不等式)時,u_i值會收斂為0。由于v^{j}_i>=0,我們知道該實例會被選作機器自動標注,同時根據誤差大小,相應賦予不同的權重。當誤差越大,自動標注越有可能出錯,于是自動賦予權重越小。在大于某一值域(大括號第二行第二個不等式)下,v和u都會同時為零,這意味著該樣本不參與本輪訓練。
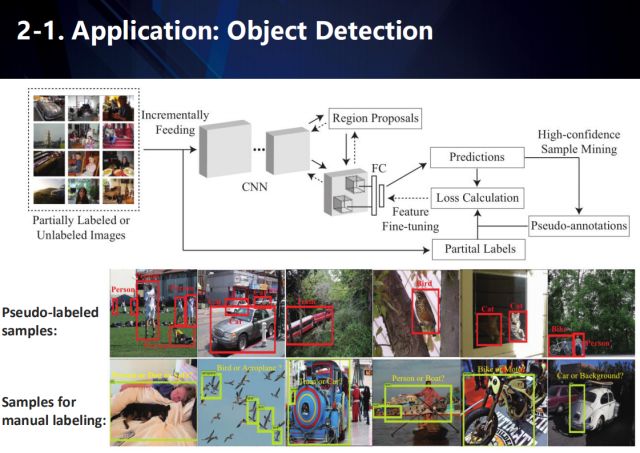
上圖展示了提出的框架(ASM)在目標檢測中的應用。

在PASCALVOC2007/2012結果中,我們的方法僅僅利用大約30~40%左右的標注數據,就能達到state-of-the-arts的檢測性能。

如何利用大量原始視頻學習
類似的策略可以應用在人體分割任務中,我們利用人體檢測器、和無監督的分割方法,從大量的原始視頻(來自YouTube)中生成人體掩膜。這些掩膜信息可以作為分割網絡的標注信息。同時,結合分割網絡輸出的信度圖,對人體檢測器提取的候選區域結果進行修正,以生成更好的人體掩膜。
Unsupervised Domain Adaptation

為了適配不同領域數據間的分布,解決目標任務缺乏數據標注的難題,我們將探索無監督領域自適應學習方法,包括單數據源領域自適應、以及多數據源領域自適應。
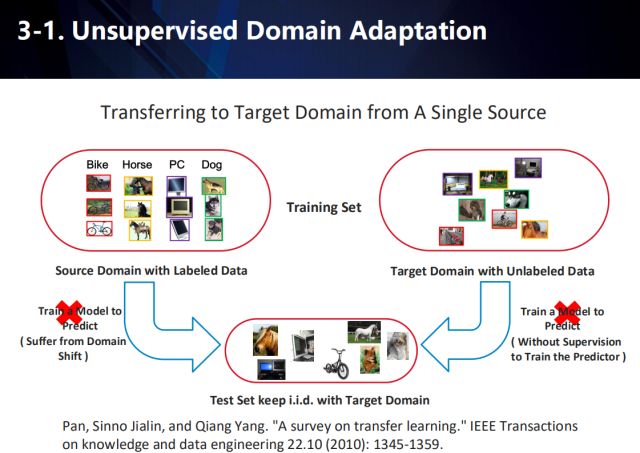
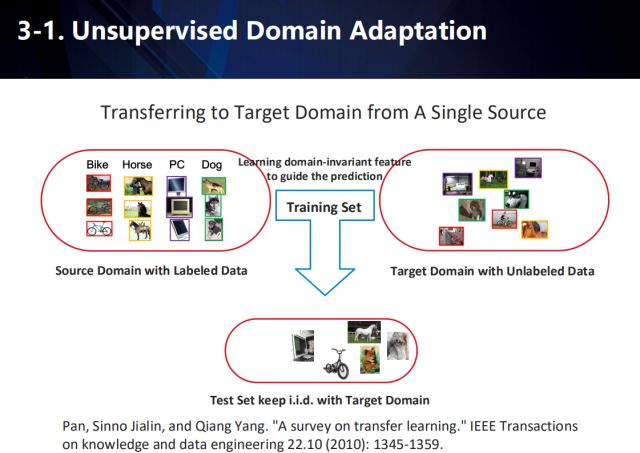
單數據源領域自適應
在應用場景中,往往存在某一領域的可用數據過少,而其他類似領域的可用數據充足,因此,衍生出了一系列遷移學習的方式,以做到跨領域的自適應。例如,在圖示的任務中,源域的數據一般是帶有標注信息的,而目標域的數據不僅與源域中的數據含有不同的分布,往往還沒有標注信息。因此,通過將學習到的知識從源域遷移到目標域,來提高算法在目標域數據上的性能。
因此,需要聯合有標注的源域數據和無標注的目標域數據,來學習一個與域無關的特征,來進行最終在目標域上的預測。
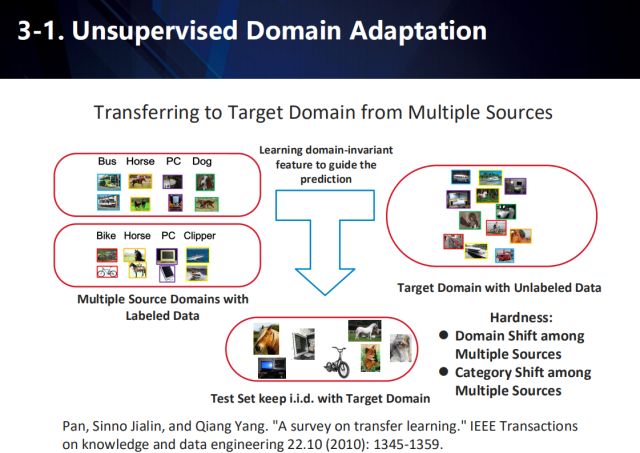
多數據源領域自適應
而對于從多數據源向目標域遷移學習的情況,將更加復雜,需要考慮:1.多種源域數據本身之間具有偏差 2.多種源域數據間類別存在偏差。
因此我們提出了一種名為“雞尾酒”的網絡,以解決將知識從多種源域的數據向目標域的數據中遷移的問題。
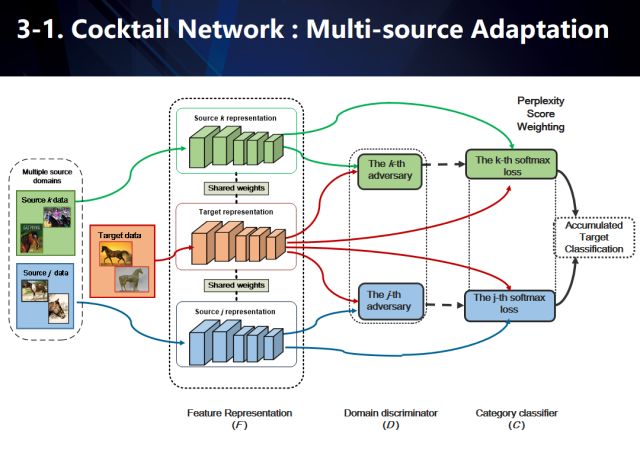
“雞尾酒”網絡
雞尾酒網絡用于學習基于多源域(我們的圖示僅簡化地展示了j,k兩個源域)下的域不變特征(domaininvariantfeature)。在具體數據流中,我們利用共享特征網絡對所有源域以及目標域進行特征建模,然后利用多路對抗域適應技術(基于單路對抗域適應(adversarial domainadaptation)下的擴展,對抗域適應的共享特征網絡對應于生成對抗學習(GAN)里面的生成器),每個源域分別與目標域進行兩兩組合對抗學習域不變特征。同時每個源域也分別進行監督學習,訓練基于不同源類別下的多個softmax分類器。注意到,基于對抗學習的建模,我們在得到共享特征網絡的同時,也可以得到多個源分別和目標域對抗的判別器。這些判別器在對于每一個目標域的數據,都可以給出該數據分別與每一個源域之間的混淆度(perplexityscore)。因此,對于每一個來自目標域的數據,我們首先利用不同源下的softmax分類器給出其多個分類結果。然后,基于每一個類別,我們找到包含該類別的所有源域softmax分類概率,再基于這些源域與目標域的混淆度,對分類概率取加權平均得到每個類別的分數。簡而言之就是,越跟目標域相識的源域混淆度會更高,意味著其分類結果更可信從而具有更高的加權權值。
需要注意的是,我們并沒有直接作用于所有softmax分類器上反而是基于每個類別分別進行加權平均處理。這是因為在我們的假設下,每個源的類別不一定共享,從而softmax結果不能簡單相加。當然,我們的方法也適用于所有源共享類別的情況,這樣我們的公式會等價于直接將softmax分類結果進行加權相加。
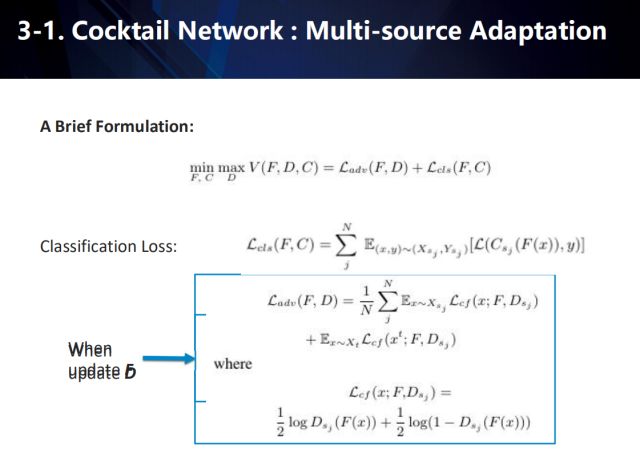
其中,L_adv 是對抗損失,當訓練判別器時用傳統的GAN loss,當訓練feature extractor時用confusion loss。L_cls是多源域(multiple source domains)分類損失,C為多源域softmax分類器。N是source的數目,s_j 代表第j個source,C_{s_j}代表第j個source的softmax 分類器 (用C來表示全部source的分類輸出),D_{s_j}代表第j個source跟target對抗的判別器 (用D來表示全部的對抗結果),F為feature extractor。

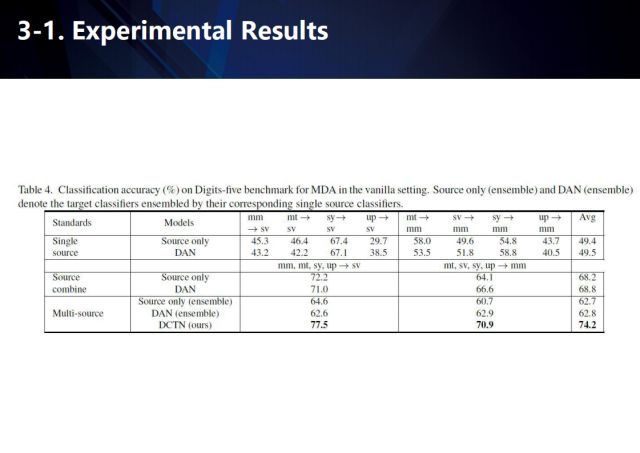
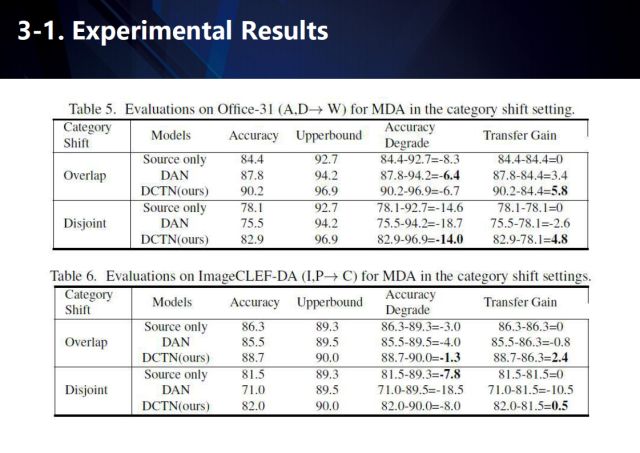
我們分別在Office-31、ImageCLEF-DA、Digit-five數據集上進行了測評,我們的方法取得了很好的結果。

-
AI
+關注
關注
87文章
31155瀏覽量
269488 -
大數據
+關注
關注
64文章
8897瀏覽量
137534 -
深度學習
+關注
關注
73文章
5507瀏覽量
121298
原文標題:后深度學習時代:弱監督學習、自主學習與自適應學習如何用于視覺理解
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
國產深度學習框架的挑戰和機會
兩種典型的電池供電電路的設計方案
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
2017全國深度學習技術應用大會
Nanopi深度學習之路(1)深度學習框架分析
labview深度學習檢測藥品兩類缺陷
從儲能、阻抗兩種不同視角解析電容去耦原理

深度學習的三種基本結構及原理詳解
深度學習時代的新主宰:可微編程






 工商網監
工商網監
評論