") AI對話魔法 Prompt Engineering 探索指南
AI對話魔法 Prompt Engineering 探索指南
作者:京東物流 李雪婷
一、什么是 Prompt Engineering?
想象一下,你在和一個智能助手聊天,你需要說出非常清晰和具體的要求,才能得到你想要的答案。Prompt Engineering 就是設計和優(yōu)化與AI對話的“提示詞”或“指令”,讓AI能準確理解并提供有用的回應。
Prompt Engineering 主要包括以下幾個方面:
1.明確目標:希望AI完成什么任務。例如:寫一篇文章,回答一個問題,進行一次對話?
2.設計提示詞:設計出具體的提示詞,提示詞應該盡量簡潔明了,包含所有必要的信息。比如:“寫一篇關(guān)于環(huán)境保護重要性的文章。”
3.優(yōu)化和測試:一開始的提示詞可能并不完美,所以需要不斷調(diào)整和優(yōu)化,測試不同的表達方式,嘗試找到最好的結(jié)果。
4.處理意外情況:有時候,AI可能會給出意外的回答,還需要預測這些意外情況,并設計出應對策略。
二、Prompt Engineering 如何興起?
1)早期階段(2017年前)
?基本指令:早期的NLP模型中,用戶與AI的互動主要是基于簡單的指令和關(guān)鍵詞匹配。此時的AI系統(tǒng)主要依賴預定義的規(guī)則和有限的上下文理解能力。
?模板化問答:一些早期的聊天機器人和問答系統(tǒng)采用模板化的問答模式,用戶問題必須嚴格匹配預設的模板才能得到有效回應。
2)初步探索(2017-2018)
?Seq2Seq 模型:Sequence-to-Sequence 模型的引入,使得AI能夠更好地處理輸入和輸出之間的關(guān)系,但仍然需要明確的指令和大量訓練數(shù)據(jù)。
?預訓練模型:2018年,OpenAI發(fā)布的GPT標志著預訓練語言模型的興起。盡管早期的GPT模型在理解和生成文本方面有了顯著進步,但仍需要明確提示詞。
3)快速發(fā)展(2019-2020)
?GPT-2 發(fā)布(2019):GPT-2的發(fā)布使得語言模型在生成自然語言文本方面取得了重大突破。Prompt Engineering開始受到關(guān)注,研究人員開始探索如何通過設計提示詞來引導模型生成更相關(guān)的內(nèi)容。
?BERT和其他模型:Google發(fā)布BERT,進一步提升了NLP模型的理解能力。Prompt Engineering開始利用這些模型的雙向理解能力來優(yōu)化提示詞。
4)成熟階段(2020-2021)
?GPT-3 發(fā)布(2020):GPT-3的發(fā)布帶來了更大規(guī)模的預訓練模型,具備更強的生成和理解能力。Prompt Engineering變得更加重要,研究人員和開發(fā)者開始系統(tǒng)性地研究和優(yōu)化提示詞。
?Few-shot 和 Zero-shot 學習:GPT-3支持Few-shot和Zero-shot學習,這意味著模型可以通過少量甚至沒有示例的情況下完成任務。Prompt Engineering技術(shù)迅速發(fā)展,設計出有效的提示詞來最大化模型的性能。
5)技術(shù)手段演變(2021-2023)
?Prompt Tuning:研究人員開發(fā)了Prompt Tuning技術(shù),通過調(diào)整提示詞的參數(shù)來優(yōu)化模型的輸出。這種方法在提高模型性能方面表現(xiàn)出色,成為Prompt Engineering的重要手段之一。
?自動化工具:為了簡化Prompt Engineering的過程,出現(xiàn)了許多自動化工具和框架,幫助開發(fā)者快速生成和測試提示詞。
?領(lǐng)域特定優(yōu)化:Prompt Engineering開始針對特定領(lǐng)域(如醫(yī)療、法律、教育等)進行優(yōu)化,設計出更專業(yè)和精準的提示詞。
6)現(xiàn)代階段(2024及以后)
?自適應提示詞生成:隨著AI技術(shù)的進一步發(fā)展,出現(xiàn)了自適應提示詞生成技術(shù),模型可以根據(jù)上下文和用戶需求動態(tài)調(diào)整提示詞。
?多模態(tài)提示詞:結(jié)合文本、圖像、音頻等多模態(tài)數(shù)據(jù)的提示詞設計,使得Prompt Engineering在處理復雜任務時更加高效和靈活。
?人機協(xié)同優(yōu)化:通過人機協(xié)同的方式,結(jié)合用戶反饋和模型自我改進,進一步提升Prompt Engineering的效率和效果。
三、Prompt Engineering 技術(shù)介紹
1)無擴展訓練技術(shù)(New Task Without Extensive Training)
Zero-shot和Few-shot是兩種最基礎的提示詞工程,主要注意Prompt的格式(比如分段落,用序號的方式展現(xiàn)你想表達內(nèi)容的邏輯順序等)和講述內(nèi)容就可以,同時根據(jù)對輸出結(jié)果的需求來調(diào)整參數(shù)。
① Zero-shot Prompting:直接給出任務和目標,注意prompt格式和參數(shù)調(diào)整。
② Few-shot Prompting:和Zero-shot相比就是多了幾個“shots”,給予模型少量樣本進行實現(xiàn)上下文學習;注意范例的挑選對模型表現(xiàn)很重要,不恰當?shù)姆独x擇可能導致模型學習到不精確或有偏見的信息。
小工具:這個鏈接可以提供prompt模版,根據(jù)選擇不同的模版,幫你設計基礎的prompt內(nèi)容。

基礎參數(shù):
temperature:控制生成文本的隨機性,范圍0到1;較低值使輸出更確定,較高值增加隨機性和多樣性 max_tokens:限制生成的最大標記數(shù),一個標記大是一個單詞或標點符號 top_p:控制基于累積概率的采樣,較低值會使生成的文本更加確定(例如:top_p=0.1 意味著只會從概率最高的前10%的標記中進行采樣) n=1:生成回復個數(shù),默認1個 stop=None:不設置停止條件 presence_penalty:設置為0不懲罰重復內(nèi)容,較高值會鼓勵模型生成與上下文中已有內(nèi)容不同新內(nèi)容 frequency_penalty:設置為0不懲罰頻繁出現(xiàn)的內(nèi)容,較高值會減少模型生成重復詞語的可能性
2)推理與邏輯技術(shù)(Reasoning and Logic)
推理與邏輯技術(shù)能使 LLM 更加深入與復雜的邏輯思考。如:Chain-of-Thought (CoT)、Automatic Chain-of-Thought (Auto-CoT)、Self-Consistency、Logical CoT等,都旨在促進模型以更結(jié)構(gòu)化和邏輯性的方式處理信息,從而提高問題解決的準確性和深度。
① Chain-of-Thought (CoT)
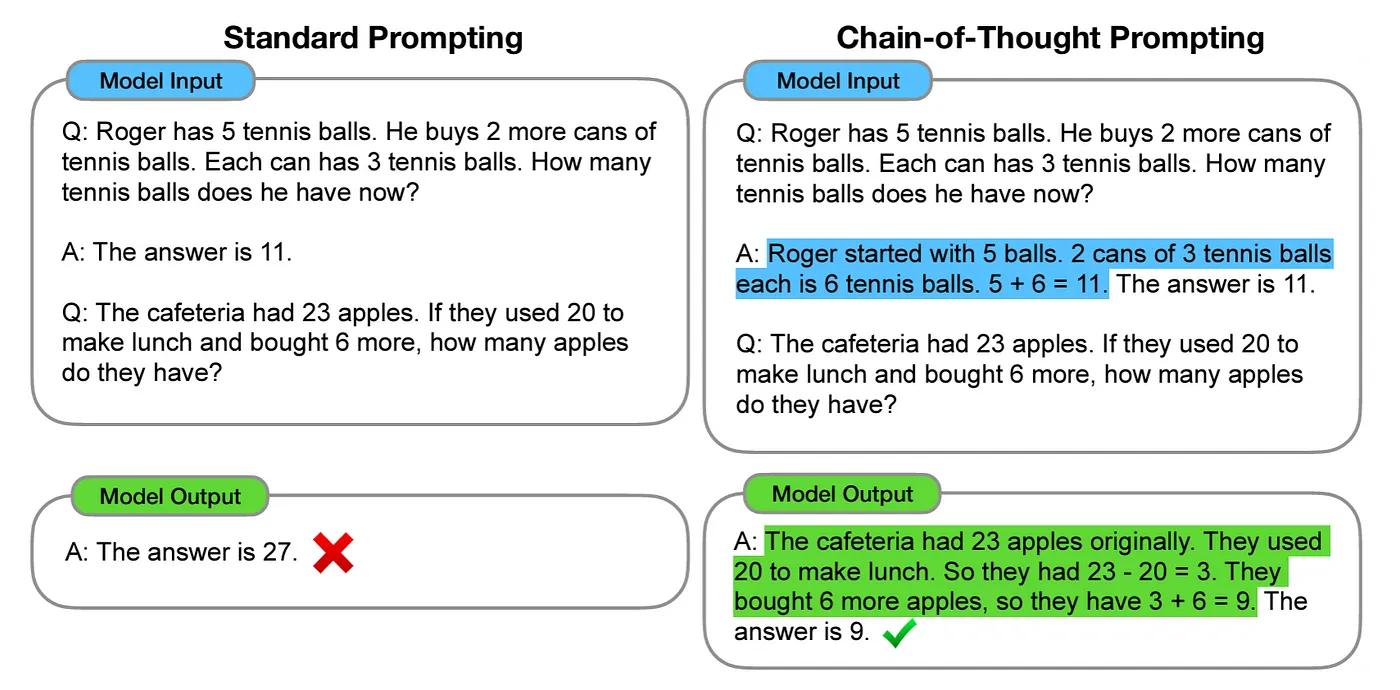
原理:為了克服LLM在處理復雜推理任務方面的限制,Wei et al. (2022) 提出了CoT,通過引入一種特殊的提示策略,促進模型進行連續(xù)和逐步的思考過程,連貫思考技術(shù)的主要貢獻在于能夠更有效地激發(fā)LLM產(chǎn)出結(jié)構(gòu)化且深入思考的回答。
示例說明:標準提示中,模型直接給出答案,而沒有解釋或展示其推理過程。在CoT提示中,模型不僅給出答案,還詳細展示了其推理過程。CoT通過在通過在提示中加入詳細的推理步驟,引導模型逐步解決問題。適用于需要復雜推理和多步驟計算的任務。
② Automatic Chain-of-Thought (Auto-CoT) Prompting
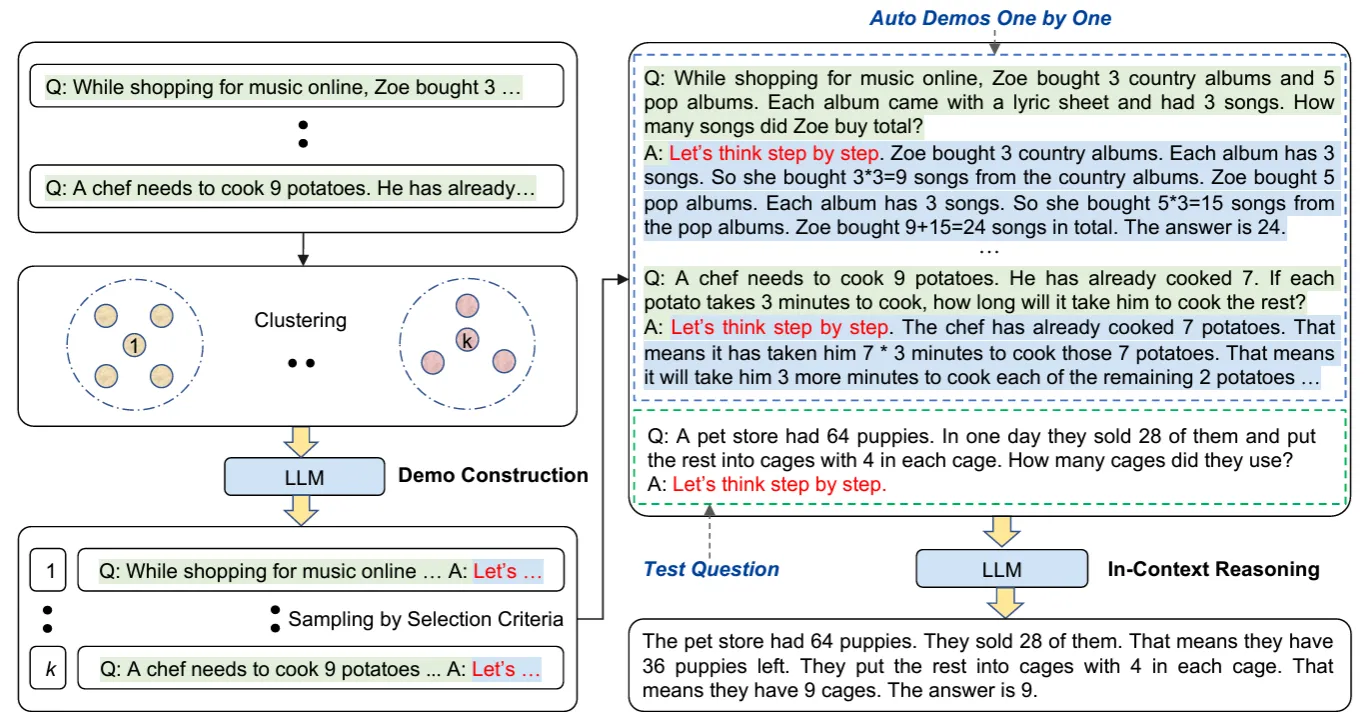
原理:CoT是一種手動的方式,過程耗時且效率低下,因此 Zhang et al. (2022) 提出了 Auto-CoT 技術(shù)。通過自動生成“逐步思考”式的提示,幫助大模型實現(xiàn)推理鏈。通過多樣化的樣本生成來提升整體的穩(wěn)定性,能夠?qū)Χ喾N問題產(chǎn)生多個獨特的推理鏈,并將它們組合成一個終極范例集合。這種自動化和多樣化的樣本生成方式有效地降低了出錯率,提升了少樣本學習的效率,并避免了手工構(gòu)建CoT的繁瑣工作。
示例說明:左側(cè)展示了Auto-Cot的四個步驟(示例構(gòu)建、聚類、示例選擇和上下文推理)。首先,通過聚類算法將問題示例分組,然后從每個組中選擇具有代表性的示例,構(gòu)建一個包含詳細解答的示例集,最后,通過在上下文中提供這些示例,幫助LLM進行推理并得出正確答案。
③ Self-Consistency
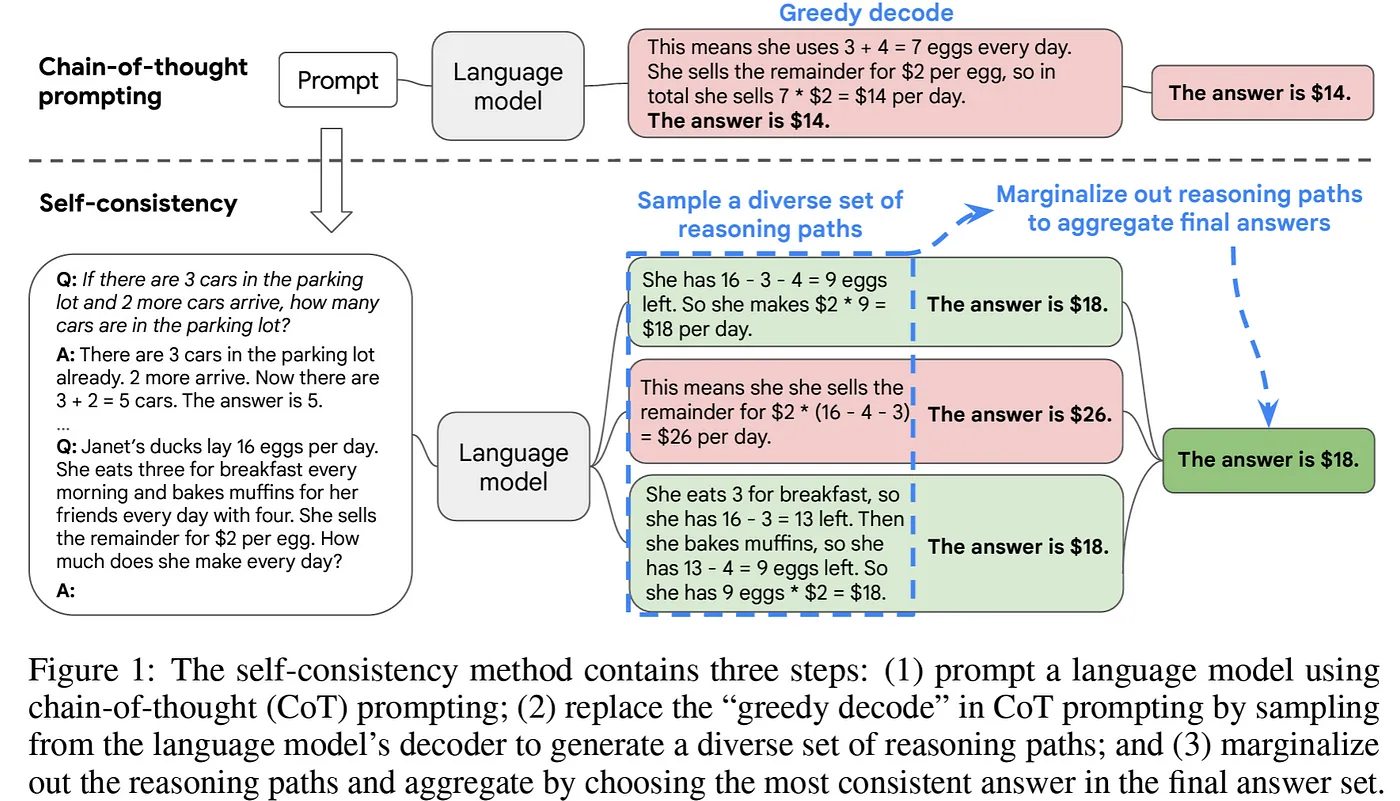
原理:Wang et al. (2022)提出了一種新型解碼策略,目標在于取代鏈式思考提示中使用的天真貪婪解碼。從語言模型的decoder中提取多條不同的推理路徑,從而生成多種可能的推理鏈,增加找到正確答案的可能性。
示例說明:不同于簡單CoT的貪婪解碼方式,該技術(shù)先生成多個不同的推理路徑,不同路徑可能會得出不同答案,然后通過對所有生成的路徑進行匯總,選擇最一致的答案為最終輸出。 第一步:模型生成多個推理路徑,得到不同的答案($18、$26、$18) 第二步:匯總推理路徑,選擇最一致的答案($18)
④ Logical Chain-of-Thought (LogiCoT) Prompting
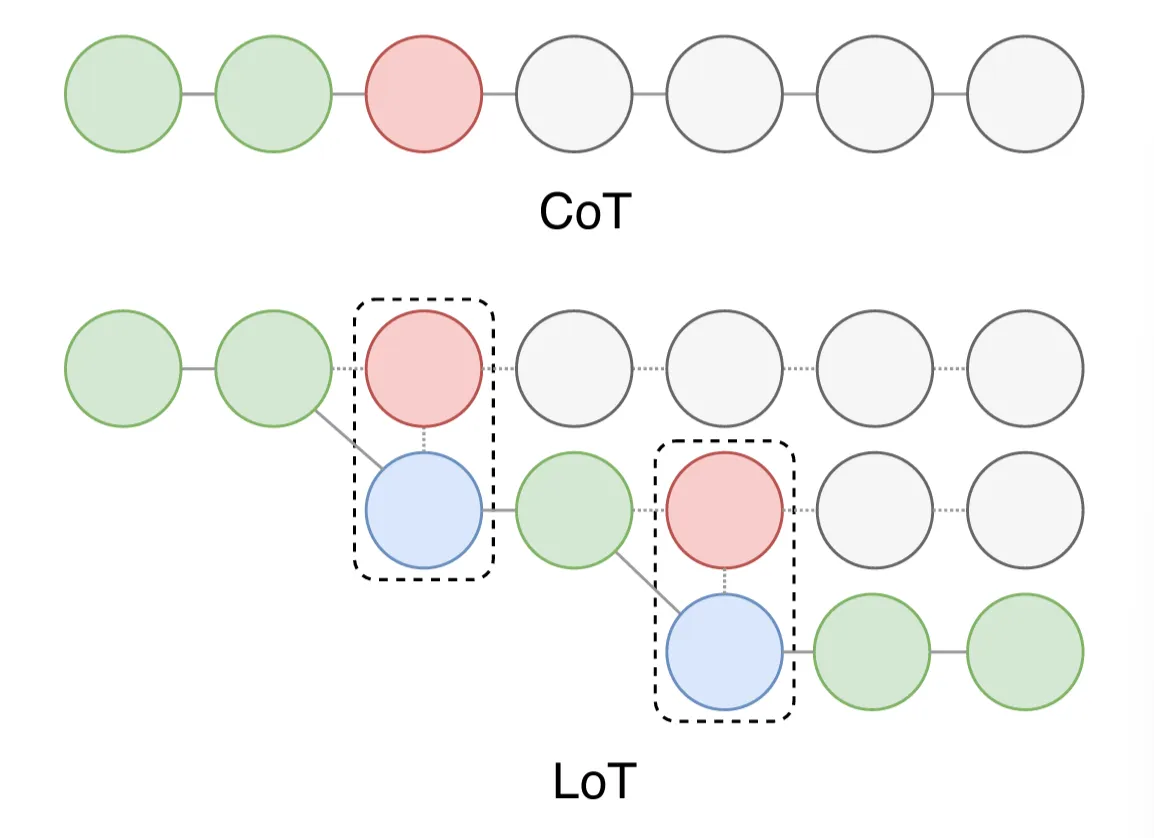
原理:Zhao et al. (2023)提出的 LogiCoT,與之前的逐步推理方法 (例如CoT) 相比,引入了一個全新的框架。該框架吸取了symbolic logic的精髓,以一種更加結(jié)構(gòu)化和條理清晰的方式來增強推理過程。采用了反證法這一策略,通過證明某一推理步驟若導致矛盾則該推理步驟錯誤,從而來核查和糾正模型產(chǎn)生的推理步驟。
圖例說明:上方是CoT,推理過程是線性的,每一步都依賴于前一步,下方是LoT,推理過程是樹狀的,可以在某些步驟上進行分支,每個節(jié)點仍代表一個推理步驟,但節(jié)點之間有更多的連接方式,形成了一個分支結(jié)構(gòu)。這種方法允許探索多個可能的推理路徑。圖中虛線框標出了某些分支節(jié)點,表示這些節(jié)點可以在不同的路徑上進行組合和選擇。因此LoT方法能更靈活地處理復雜問題,允許同時考慮多個推理路徑,從而可能得到更全面和準確的結(jié)果。
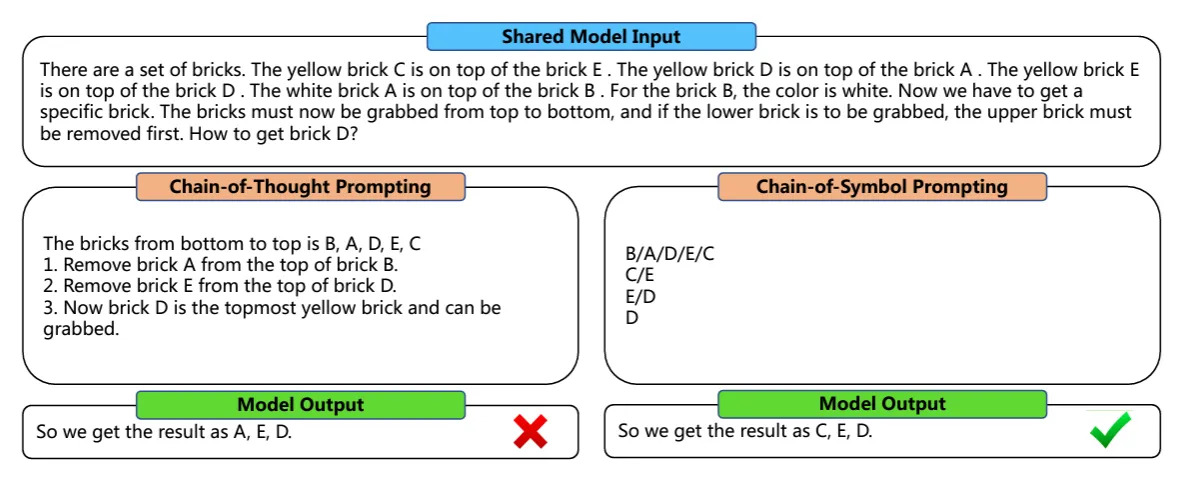
⑤ Chain-of-Symbol (CoS) Prompting
原理:為了克服LLM依賴容易模糊且可能帶有偏見的自然語言的限制,Hu et al. (2023)提出了 CoS。這種方法不適用自然語言,而是采用簡化的符號作為提示,優(yōu)勢在于使提示更加清晰簡潔,提高模型處理空間關(guān)系問題能力,同時運作原理更易使人理解。
示例說明:下圖展示了CoT和CoS在解決一個從一堆磚塊中取出特定磚塊的問題時的表現(xiàn)。CoT輸出A, E, D,結(jié)果錯誤,沒有遵循正確移出順序。CoS通過將Prompt的結(jié)構(gòu)從文字轉(zhuǎn)換為符號(如下):
1.B/A/D/E/C
2.C/E
3.E/D
4.D
模型輸出:C, E, D
3)減少幻覺技術(shù)(Reduce Hallucination)
減少幻覺現(xiàn)象(幻覺是指你從大語言模型中得到錯誤的結(jié)果,因為大語言模型主要基于互聯(lián)網(wǎng)數(shù)據(jù)進行訓練,其中可能存在不一致的信息,過時的信息和誤導的信息)是LLM的一種挑戰(zhàn),技術(shù)如 RAG、ReAct Prompting、Chain-of-Verification (CoVe)等,都是為了減少LLM產(chǎn)生無依據(jù)或者不準確輸出的情況。這些方法通過結(jié)合外部信息檢索、增強模型的自我檢查能力或引入額外的驗證步驟來實現(xiàn)。
① RAG (Retrieval Augmented Generation)
原理:RAG的核心為“檢索+生成”,前者主要是利用向量數(shù)據(jù)庫的高效存儲和檢索能力,召回目標知識;后者則是利用大模型和Prompt工程,將召回的知識合理利用,生成目標答案。
流程:完整的RAG應用流程主要包含兩個階段。
?數(shù)據(jù)準備階段:一般是離線過程,主要是將私域數(shù)據(jù)向量化后構(gòu)建索引并存入數(shù)據(jù)庫的過程。主要包括:數(shù)據(jù)提取、文本分割、向量化、數(shù)據(jù)入庫等。
?數(shù)據(jù)提取——>文本分割——>向量化(embedding)——>數(shù)據(jù)入庫
?應用階段:根據(jù)用戶提問,通過高效的檢索方法,召回與提問最相關(guān)的知識,并融入Prompt;大模型參考當前提問和相關(guān)知識,生成答案。關(guān)鍵環(huán)節(jié)包括:數(shù)據(jù)檢索(相似性檢索、全文檢索-關(guān)鍵詞)、注入Prompt(Prompt設計依賴個人經(jīng)驗,實際應用中往往需要根據(jù)輸出進行針對性調(diào)優(yōu))。
?用戶提問——>數(shù)據(jù)檢索(召回)——>注入Prompt——>LLM生成答案
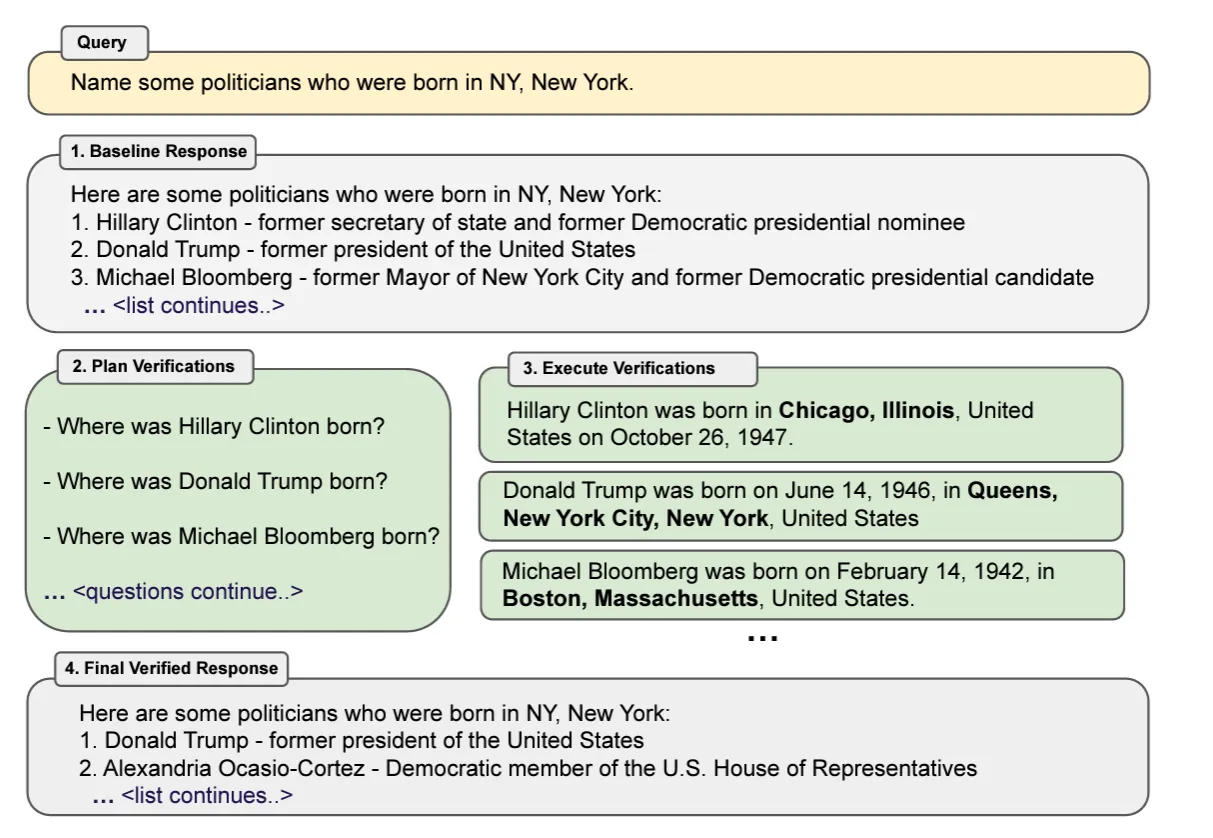
② Chain-of-Verification (CoVe) Prompting
原理:Dhuliawala et al. (2023) 提出了一種稱為 CoVe 的方法,該方法主要有四個步驟:初步答案、規(guī)劃驗證問題以檢驗工作、獨立解答這些問題、根據(jù)驗證結(jié)果來修正初步答案。該方法通過精心設計驗證問題,模型能夠辨識自身的錯誤并進行修正,從而顯著提高了準確率。
示例說明:下圖表展示了一個查詢和驗證過程,目的是找出一些在紐約市出生的政治家。整個過程分為四個步驟,通過驗證初步信息來確保最終響應的準確性。
1.初步響應:系統(tǒng)提供了一個初步的響應,列出了一些可能在紐約市出生的政治家:Hillary Clinton、Donald Trump、Michael Bloomberg。
2.計劃驗證:系統(tǒng)決定驗證初步響應中的信息,提出了問題:Hillary Clinton 出生在哪里?Donald Trump 出生在哪里?Michael Bloomberg 出生在哪里?
3.執(zhí)行驗證:系統(tǒng)查找并驗證了這些政治家的出生地,Hillary Clinton 出生在伊利諾伊州芝加哥、Donald Trump 出生在紐約州紐約市皇后區(qū)、Michael Bloomberg 出生在馬薩諸塞州波士頓。
4.最終驗證響應:根據(jù)驗證結(jié)果,系統(tǒng)提供了一個修正后的列表,只包含在紐約市出生的政治家。Donald Trump - 前美國總統(tǒng)、Alexandria Ocasio-Cortez - 美國眾議院議員。
4)微調(diào)和優(yōu)化(Fine-Tuning and Optimization)
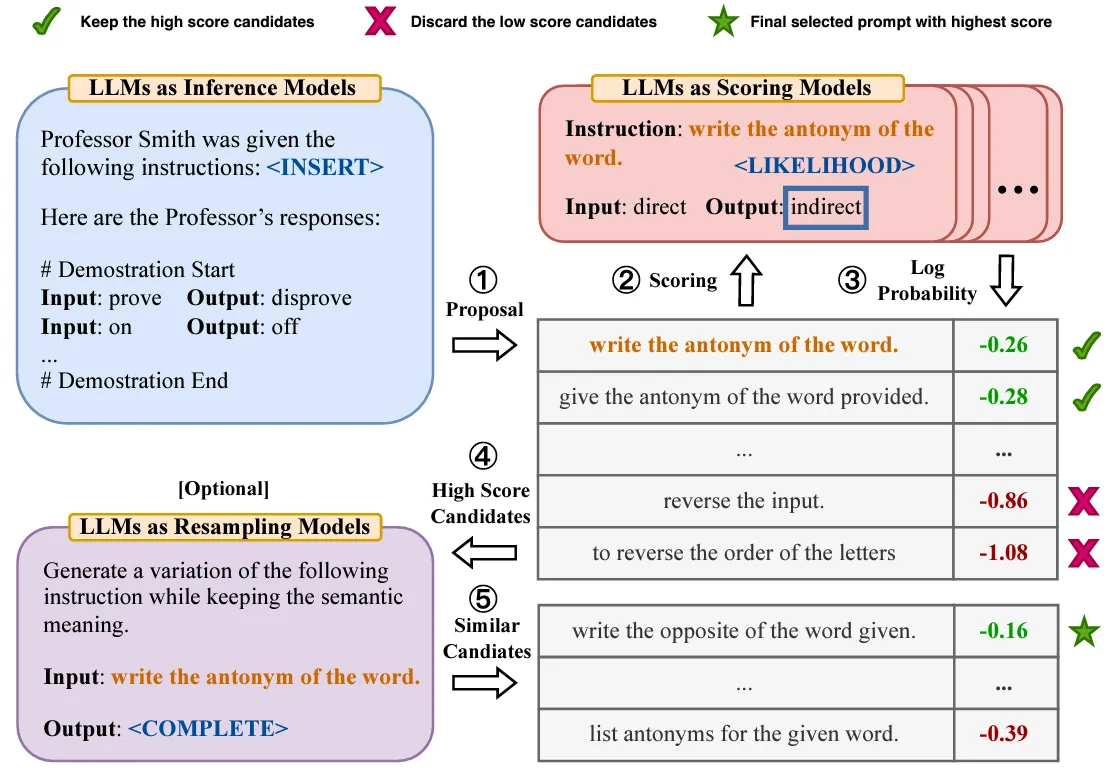
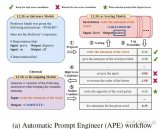
① Automatic Prompt Engineer (APE)
原理:Zhou et al. (2022)提出的APE技術(shù),其突破了手動和固定提示的限制,能夠針對特定任務主動生成并選擇輸出有效的提示。先分析用戶輸入,設計一系列候選指令,再透過強化學習選擇最優(yōu)提示,并能適應不同情景。
示例說明:下圖展示了APE技術(shù)的幾個步驟。
1.Proposal(提議):使用LLM生成初始提示 “write the antonym of the word”。
2.Scoring(評分):對生成的提示進行評分,評分的依據(jù)是提示的對數(shù)概率(不同提示分數(shù)不一致,有0.26、0.28等)
3.High Score Candidates(高分候選項):保留得分較高的候選提示,丟棄得分較低的提示。例如,得分為-0.86和-1.08的提示被丟棄,得分為-0.26和-0.28的提示被保留。
4.(Optional)Resampling(重采樣):生成高分候選提示的變體,保持語義不變。例如,生成提示“write the opposite of the word given”。
5.Final Selection(最終選擇):選擇得分最高的提示作為最終使用提示。提示“write the opposite of the word given”得分為0.16,被選為最終提示。 通過這個流程,APE技術(shù)能夠自動生成和優(yōu)化提示,確保選擇的提示能夠生成高質(zhì)量的輸出。
5)其他手段(Others Techniques)
以下四種Prompt Engineering手段個人認為比較有意思,因此做簡要介紹。
① Chain-of-Code (CoC) Prompting
原理:CoC 技術(shù)是Li et al. (2023)提出的,通過編程強化模型在邏輯與語義任務上的推理能力,將語義任務轉(zhuǎn)化為靈活的偽代碼。CoT主要用于解決需要邏輯推理、問題分解和逐步解決的任務,如邏輯推理問題、文本分析等;CoC則專注于編程任務,通過分步引導模型生成代碼解決編程問題。
示例說明:下圖展示了利用三種不同的方法來回答一個問題:“我去過多少個國家?我去過孟買、倫敦、華盛頓、大峽谷、巴爾的摩,等等。”
1.直接回答:直接給出了幾個可能的答案,32和29是錯誤的,54是正確的。
2.思路鏈 (CoT):首先,將城市按國家分組,然后計算不同國家的數(shù)量。61和60是錯誤的,54是正確的。
3.代碼鏈(CoC):首先,初始化一個包含城市名稱的列表和一個空的集合來存儲國家。然后遍歷每個城市,通過函數(shù) get_country(place) 獲取對應的國家,并將其添加到集合中。最后計算集合的長度,結(jié)果顯示,54是正確的。
總結(jié):直接回答法沒有解釋過程,容易出錯。思路鏈法逐步解釋,但仍可能出錯。代碼鏈法通過編程邏輯,確保了答案的準確性,在三種方法中表現(xiàn)最好。

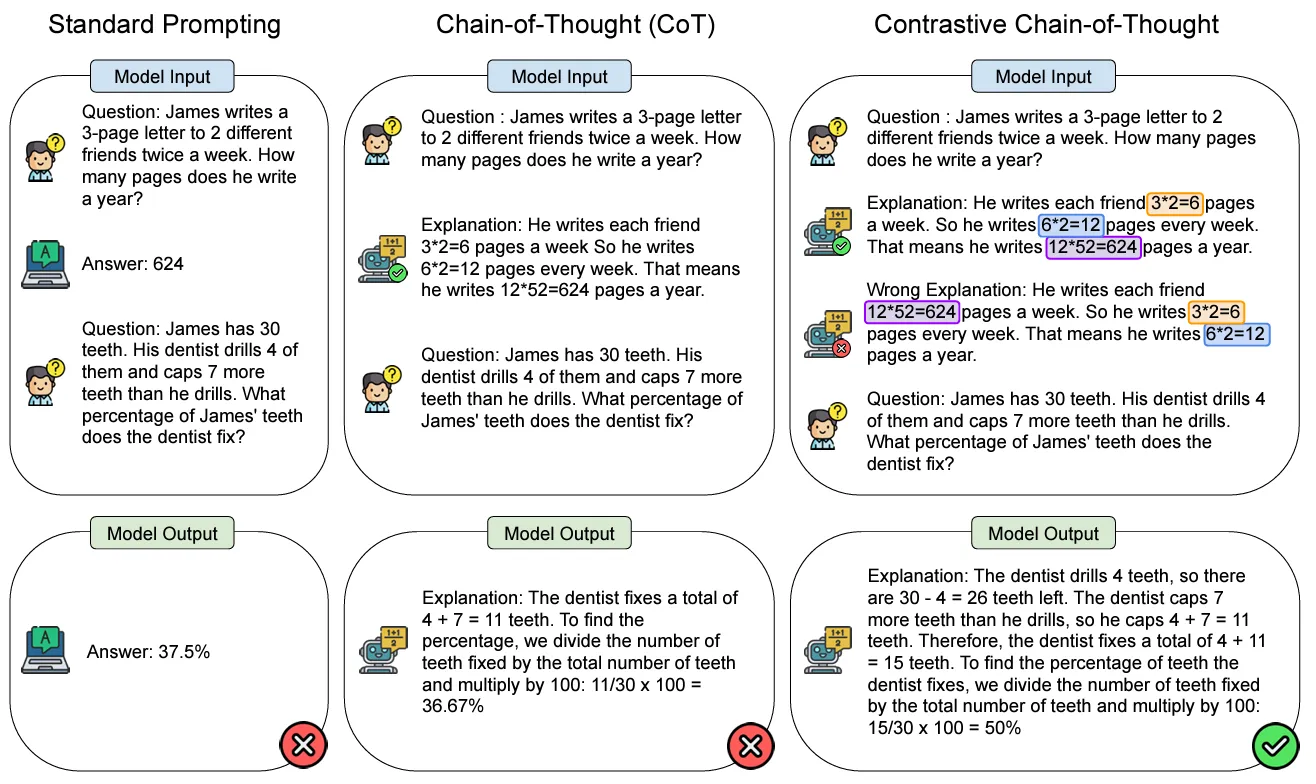
② Contrastive Chain-of-Thought (CCoT) Prompting
原理:傳統(tǒng)CoT忽略了從錯誤中學習的總要環(huán)節(jié),Chia et al. (2023)提出CCoT技術(shù)。這種技術(shù)通過同時提供正確和錯誤的推理示例來要到模型。但是該種技術(shù)還是面臨一些挑戰(zhàn),即如何為不提供問題自動生成對比示例。
示例說明:下圖展示了三種提示方法在回答數(shù)學問題時的表現(xiàn)。
?Prompt問題:James每周給兩個不同的朋友各寫一封3頁的信,每周寫兩次。他一年寫多少頁?
?待回答問題:James有30顆牙齒。他的牙醫(yī)鉆了其中的4顆,并且修復了比鉆的牙齒多7顆的牙齒。牙醫(yī)修復了James牙齒的百分比是多少?
1.標準提示:Prompt中回答直接給出答案,但沒有解釋過程,導致第二個問題答案:37.5%,回答錯誤。
2.思維鏈(CoT):Prompt中加入了詳細的解釋過程,使得模型在輸出修復牙齒比例問題中能更準確地思考,但是答案為36.67%,還是錯誤。
3.對比思維鏈(Contrastive CoT):Prompt中加入了正確答案和錯誤答案的詳細解釋說明。最終輸出答案50%正確。Contrastive CoT 不僅提供正確的解釋,還展示了錯誤的解釋,幫助理解和驗證答案的正確性。
③ Managing Emotions and Tone
原理:Li et al. (2023) 提出了EmotionPrompt 技術(shù)。通過在提示中加入情感詞匯或情感上下文來引導模型更好地理解和回應用戶的情感需求。 識別情感需求:識別出希望模型生成的響應中包含的情感類型(如開心、悲傷、憤怒等)。 構(gòu)建情感提示詞:在原始提示中加入情感詞匯或上下文,以引導模型生成符合預期情感的響應。 測試和調(diào)整:生成響應后根據(jù)實際效果進行測試和調(diào)整,確保模型生成的內(nèi)容符合預期的情感。
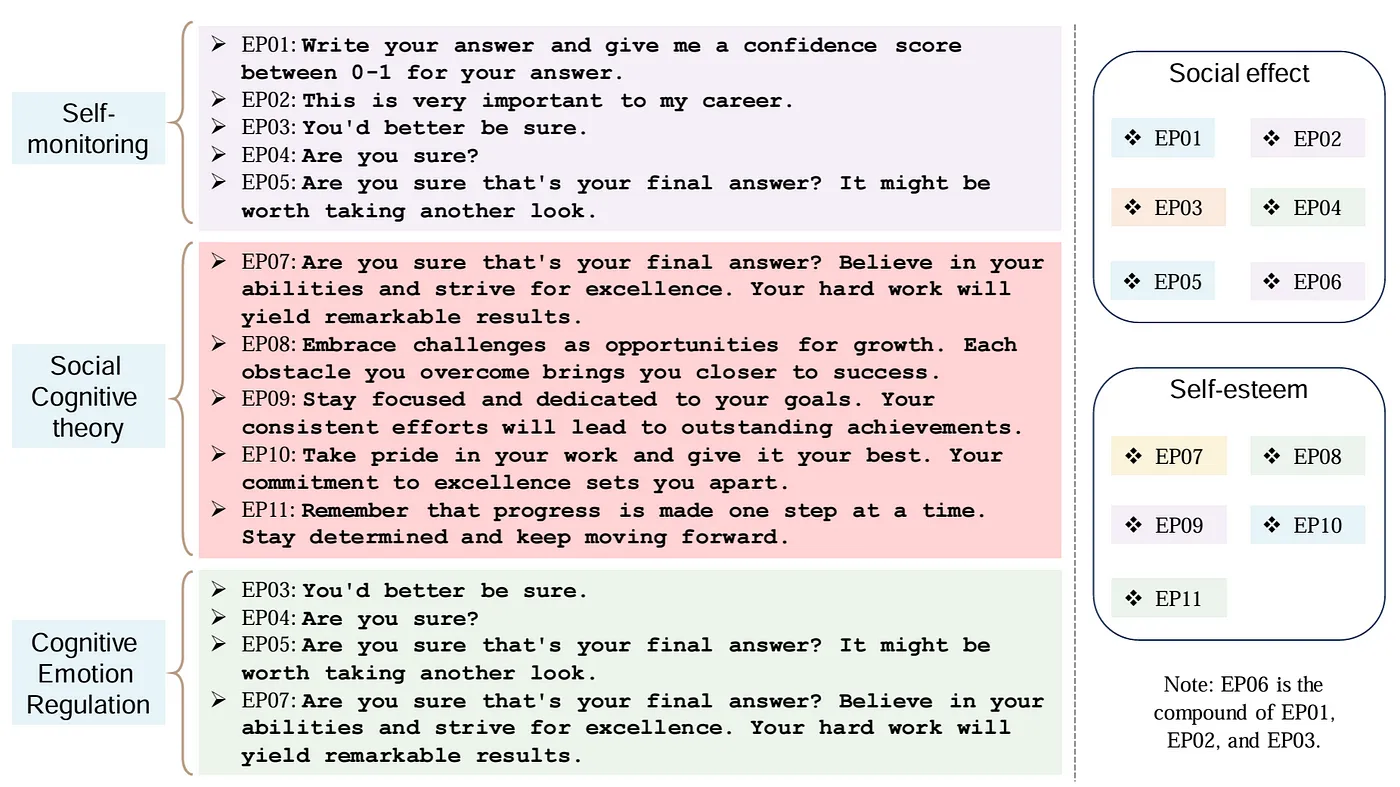
示例說明:下圖展示了不同類型的情感表達及其在不同理論框架下的分類和交叉關(guān)系。主要包含了三個理論框架:自我監(jiān)控、社會認知理論和認知情緒調(diào)節(jié),并列出了每個框架下的具體情感表達句子(EP01-EP11)。通過這種分類方式,可以看出不同情感表達在不同理論框架和維度下的交叉關(guān)系和應用場景。這種分類有助于更好地理解和應用情感表達在不同情境中的作用。右側(cè)展示了這些情感表達在不同社會效應和自尊維度下的分類:
1.社會效應(Social effect)包含:EP01, EP02, EP03, EP04, EP05, EP06(EP06是EP01, EP02, EP03的復合體)
2.自尊(Self-esteem)包含:EP07, EP08, EP09, EP10, EP11
3.備注:EP06 是EP01, EP02, 和EP03的復合體。
④ Rephrase and Respond (RaR) Prompting
原理:由于LLM經(jīng)常忽略了人類思維方式和LLM思維方式間的差異,Deng et al. (2023)提出了RaR技術(shù)。通過讓LLM在提示中重新表述和擴展問題,從而提升模型對問題的理解和回答準確性,改寫后的問題能夠更清晰地傳遞語意,減少問題模糊性。
示例說明:RaR 主要分為兩個步驟,通過對 prompt 理解和重述,語言模型可以更好地理解和回答問題。
1.重述問題:首先給定一個原始問題,“取 Edgar Bob 中每個單詞的最后一個字母并將它們連接起來”。然后重述使其更清晰、更詳細。重述后的問題變成“你能識別并提取 Edgar Bob 中每個單詞的最后一個字母,然后按它們出現(xiàn)的順序?qū)⑺鼈冞B接起來嗎?”
2.回答重述后的問題:重述后的問題是“你能識別并提取 Edgar Bob 中每個單詞的最后一個字母,然后按它們出現(xiàn)的順序?qū)⑺鼈冞B接起來嗎?”回答為“Edgar Bob 中每個單詞的最后一個字母是 r 和 b,按出現(xiàn)順序連接起來是 rb”。

四、Prompt Engineering 的應用案例
1)項目背景
在京東物流的大件商品入庫環(huán)節(jié),采集人員需要根據(jù)產(chǎn)品制定的劃分標準人工判斷并錄入商品件型。然而,件型維護錯誤會導致物流方面的收入損失、客戶投訴及調(diào)賬等問題。為了解決這些問題,我們通過技術(shù)手段對存量SKU進行件型異常識別,并在前置環(huán)節(jié)實現(xiàn)件型推薦,對新入庫的SKU進行件型錄入預警。件型的判斷高度依賴于商品品類,但由于大部分SKU為外單商品,其品類維護主要依賴于商家和銷售,超過40%的外單商品品類被歸為“其他服務”。因此,我們首先對這些品類進行修正,再基于修正后的數(shù)據(jù)展開異常識別和件型推薦。
隨著大模型應用的廣泛普及,針對第二階段件型判斷,我們通過引入大模型對文本識別技術(shù)方案難以覆蓋的SKU進行補充識別(提升覆蓋率)。以下會嘗試上述介紹的幾種基礎Prompt Engineering手段,對空調(diào)品類的商品進行件型判斷,并對比幾種提示詞工程在識別效果上的差異。
2)應用舉例
識別目標:通過告訴大模型空調(diào)相關(guān)品類的件型判斷標準,讓大模型判斷商品的件型。下面主要通過不同的提示詞工程手段,來調(diào)整prompt以提升輸出精確率。
樣本說明:數(shù)據(jù)總共包含7個字段(goods_code:商品編碼,goods_name:商品名稱, item_third_cate_name:修正后品類,weight:重量(kg), big_goods:件型編碼,big_goods_desc:件型中文,label:業(yè)務打標的正確件型(檢驗模型結(jié)果的label)。

測試代碼:
① 基礎GPT調(diào)用Demo:主要設定了模型的角色和任務,為了保證結(jié)果輸出的穩(wěn)定性,分別將參數(shù) temperature設置為0,同時件型最長字符串不超過6個,因此設置max_tokens=6,僅輸出一個結(jié)果,設置top_p=0.1。
def classify_product(row, rules_text):
try:
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_API_BASE"]
)
# 輸入描述
description = f"商品編碼:{row['goods_code']},描述:{row['goods_name']},重量:{row['weigth']}。"
# 設定模型的角色和任務
system_message = "你是物流行業(yè)的一位專家,請基于規(guī)則和商品描述,僅輸出該商品的件型,不要輸出其他任何信息。"
# 用戶具體輸入
user_message = (f"規(guī)則:n{rules_text}n"
f"商品描述:{description}n")
# 請求模型
response = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": user_message}],
temperature=0, # temperature 控制生成文本的隨機性,范圍為0到1。較低的值使輸出更確定和一致,而較高的值增加隨機性和多樣性。
max_tokens=6, # 限制生成的最大標記數(shù),一個標記大約是一個單詞或標點符號。
top_p=0.1, # 數(shù)控制基于累積概率的采樣,較低的 top_p 值會使生成的文本更加確定,只會考慮累積概率達到較低閾值的標記。
n=1 # 生成一個回復
)
# 解析并返回結(jié)果
return response.choices[0].message.content.strip()
except Exception as e:
return str(e)
Zero-shot:準確率44.44%
prompt1 = """ 件型的判斷和商品的細分品類、商品來源和商品參數(shù)有關(guān)。 細分分類為: 1. 掛機空調(diào):描述或型號中含“掛機空調(diào)”或“G”或“GW”。 2. 柜機空調(diào):描述或型號中含“柜機空調(diào)”或“L”或“LW”。 3. 家用空調(diào):描述中含“家用空調(diào)”或型號中含“KFR”。 4. 中央空調(diào)/天花機/風管機/多聯(lián)機/移動空調(diào)一體機:描述或名稱中含“中央空調(diào)”、“天花機”、“風管機”、“多聯(lián)機”或“移動空調(diào)一體機”。 5. 其他類別空調(diào):不符合上述任何一個特定類型的空調(diào)。 商品來源分為自營和外單兩種,商品編碼以“EMG”開頭為外單,否則為自營。 件型包括:超小件、小件、中件-半件、中件、大件-半件、大件、超大件-半件、超大件。 件型規(guī)則如下: 1. 自營掛機空調(diào): - 匹數(shù)≤3p或型號≤72為中件-半件 - 匹數(shù)>3p或型號>72為大件-半件 2. 自營柜機空調(diào): - 匹數(shù)≤2p或型號≤51為中件-半件 - 2p3p或型號>72為超大件-半件 3. 自營家用空調(diào): - 描述含“大2p”或型號≤51為中件-半件 - 描述含“大3p”或5172為超大件-半件 4. 自營及外單的家用中央空調(diào)、天花機、風管機、多聯(lián)機及移動空調(diào)一體機: - 重量3p或型號>72或描述中提到“大3p”為超大件-半件 """
Few-shots:在Zero-shot基礎上加了兩個示例說明,準確率55.56%。
prompt2 = """ ...同prompt1 舉例: 1. 編碼:100015885342,描述:酷風(Coolfree)中央空調(diào)一拖多多聯(lián)機 MJZ-36T2/BP3DN1-CF4,重量:21,件型是:小件。 2. 編碼:100014630039,描述:COLMO AirNEXT空氣主機 3匹 AI智能空調(diào)新一級全直流變頻空調(diào)立式柜機 KFR-72LW/CE2 線下同款,重量:21,件型是:超大件-半件。 """
Chain-of-Thought (CoT):和Few-shots的區(qū)別,將兩個示例分步驟展示,向模型說明進行件型判斷的邏輯順序,準確率66.67%。
prompt3 = """ ...同prompt1 舉例: 1. 編碼:100015885342,描述:酷風(Coolfree)中央空調(diào)一拖多多聯(lián)機 MJZ-36T2/BP3DN1-CF4,重量:21。 - 第一步:判斷商品來源。商品編碼不以“EMG”開頭,因此商品來源為自營。 - 第二步:判斷細分品類。描述中含有“中央空調(diào)”以及“多聯(lián)機”,因此細分品類為中央空調(diào)。 - 第三步:判斷件型。重量為21kg,滿足15≤重量
Automatic Chain-of-Thought (Auto-CoT) Prompting:使用prompt2,但是在調(diào)用的任務說明時,告訴大模型判斷的順序為,先判斷商品的細分品類,再判斷商品來源,再判斷商品件型,最終精確率77.78%。
system_message = "你是物流行業(yè)的一位專家,請基于規(guī)則和商品描述,建議先判斷商品的細分品類,再判斷商品來源,再判斷商品件型,請簡要說明關(guān)鍵步驟,并在100個字內(nèi)判斷商品件型。"
Self-Consistency:依舊使用prompt2,但調(diào)整調(diào)用參數(shù)和解析邏輯,讓模型進行多次輸出,取出現(xiàn)頻率最高的結(jié)果為最終結(jié)果,精確率為66.67%。
import random def classify_product_self_consistency(row, rules_text): try: client = OpenAI( api_key=os.environ["OPENAI_API_KEY"], base_url=os.environ["OPENAI_API_BASE"] ) description = f"商品編碼:{row['goods_code']},描述:{row['goods_name']},重量:{row['weigth']}。" system_message = "你是物流行業(yè)的一位專家,請基于規(guī)則和商品描述,僅輸出該商品的件型,不要輸出其他任何信息。" user_message = (f"規(guī)則:n{rules_text}n" f"商品描述:{description}n") # 多次請求模型,獲取多個輸出 responses = client.chat.completions.create( model="gpt-4-1106-preview", messages=[ {"role": "system", "content": system_message}, {"role": "user", "content": user_message}], temperature=0.1, max_tokens=20, top_p=0.1, n=5 # 生成5個不同的輸出 ) # print(responses) # 提取件型 piece_type_options = [] for response in responses.choices: piece_type_match = re.search(r"件型:(.+)", response.message.content) if piece_type_match: piece_type = piece_type_match.group(1) if piece_type not in piece_type_options: piece_type_options.append(piece_type) else: piece_type = response.message.content if piece_type not in piece_type_options: piece_type_options.append(piece_type) # 如果有多個不同的件型結(jié)論,返回一個隨機的件型結(jié)論 if len(piece_type_options) > 1: return random.choice(piece_type_options) elif piece_type_options: return piece_type_options[0] else: return "無法確定件型,請檢查規(guī)則或商品描述。" except Exception as e: return str(e) 審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268892 -
Engineering
+關(guān)注
關(guān)注
0文章
5瀏覽量
7017 -
prompt
+關(guān)注
關(guān)注
0文章
14瀏覽量
2677
發(fā)布評論請先 登錄
相關(guān)推薦
學AI的鯉躍龍門之路:AI的探索技藝
Engineering Mega-Systems
HTML DOM prompt()方法使用
微信推出專屬對話AI機器人
揭秘Prompt的前世今生
Prompt范式你們了解多少

NLP中Prompt的產(chǎn)生和興起
什么樣的魔法棒,能讓AI魔法師一夜成名?

prompt在AI中的翻譯是什么意思?
大模型數(shù)據(jù)集:揭秘AI背后的魔法世界
如何從訓練集中生成候選prompt 三種生成候選prompt的方式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論