") redis應(yīng)用場(chǎng)景及實(shí)例
redis應(yīng)用場(chǎng)景及實(shí)例
前言
Redis是一個(gè)開(kāi)源的使用ANSI C語(yǔ)言編寫(xiě)、支持網(wǎng)絡(luò)、可基于內(nèi)存亦可持久化的日志型、Key-Value數(shù)據(jù)庫(kù),并提供多種語(yǔ)言的API。在這篇文章中,我們將闡述 Redis 最常用的使用場(chǎng)景,以及那些影響我們選擇的不同特性。
Redis 的 5 個(gè)常見(jiàn)使用場(chǎng)景
1、會(huì)話緩存(Session Cache)
最常用的一種使用Redis的情景是會(huì)話緩存(session cache)。用Redis緩存會(huì)話比其他存儲(chǔ)(如Memcached)的優(yōu)勢(shì)在于:Redis提供持久化。當(dāng)維護(hù)一個(gè)不是嚴(yán)格要求一致性的緩存時(shí),如果用戶的購(gòu)物車(chē)信息全部丟失,大部分人都會(huì)不高興的,現(xiàn)在,他們還會(huì)這樣嗎?
幸運(yùn)的是,隨著 Redis 這些年的改進(jìn),很容易找到怎么恰當(dāng)?shù)氖褂肦edis來(lái)緩存會(huì)話的文檔。甚至廣為人知的商業(yè)平臺(tái)Magento也提供Redis的插件。
2、全頁(yè)緩存(FPC)
除基本的會(huì)話token之外,Redis還提供很簡(jiǎn)便的FPC平臺(tái)。回到一致性問(wèn)題,即使重啟了Redis實(shí)例,因?yàn)橛写疟P(pán)的持久化,用戶也不會(huì)看到頁(yè)面加載速度的下降,這是一個(gè)極大改進(jìn),類(lèi)似PHP本地FPC。
再次以Magento為例,Magento提供一個(gè)插件來(lái)使用Redis作為全頁(yè)緩存后端。
此外,對(duì)WordPress的用戶來(lái)說(shuō),Pantheon有一個(gè)非常好的插件 wp-redis,這個(gè)插件能幫助你以最快速度加載你曾瀏覽過(guò)的頁(yè)面。
3、隊(duì)列
Reids在內(nèi)存存儲(chǔ)引擎領(lǐng)域的一大優(yōu)點(diǎn)是提供 list 和 set 操作,這使得Redis能作為一個(gè)很好的消息隊(duì)列平臺(tái)來(lái)使用。Redis作為隊(duì)列使用的操作,就類(lèi)似于本地程序語(yǔ)言(如Python)對(duì) list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你馬上就能找到大量的開(kāi)源項(xiàng)目,這些項(xiàng)目的目的就是利用Redis創(chuàng)建非常好的后端工具,以滿足各種隊(duì)列需求。例如,Celery有一個(gè)后臺(tái)就是使用Redis作為broker,你可以從這里去查看。
4、排行榜/計(jì)數(shù)器
Redis在內(nèi)存中對(duì)數(shù)字進(jìn)行遞增或遞減的操作實(shí)現(xiàn)的非常好。集合(Set)和有序集合(Sorted Set)也使得我們?cè)趫?zhí)行這些操作的時(shí)候變的非常簡(jiǎn)單,Redis只是正好提供了這兩種數(shù)據(jù)結(jié)構(gòu)。所以,我們要從排序集合中獲取到排名最靠前的10個(gè)用戶–我們稱之為“user_scores”,我們只需要像下面一樣執(zhí)行即可:
當(dāng)然,這是假定你是根據(jù)你用戶的分?jǐn)?shù)做遞增的排序。如果你想返回用戶及用戶的分?jǐn)?shù),你需要這樣執(zhí)行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一個(gè)很好的例子,用Ruby實(shí)現(xiàn)的,它的排行榜就是使用Redis來(lái)存儲(chǔ)數(shù)據(jù)的,你可以在這里看到。
5、發(fā)布/訂閱
最后(但肯定不是最不重要的)是Redis的發(fā)布/訂閱功能。發(fā)布/訂閱的使用場(chǎng)景確實(shí)非常多。我已看見(jiàn)人們?cè)谏缃痪W(wǎng)絡(luò)連接中使用,還可作為基于發(fā)布/訂閱的腳本觸發(fā)器,甚至用Redis的發(fā)布/訂閱功能來(lái)建立聊天系統(tǒng)!(不,這是真的,你可以去核實(shí))。
Redis提供的所有特性中,我感覺(jué)這個(gè)是喜歡的人最少的一個(gè),雖然它為用戶提供如果此多功能。
詳解 Redis 應(yīng)用場(chǎng)景及應(yīng)用實(shí)例
1. MySql+Memcached架構(gòu)的問(wèn)題
實(shí)際MySQL是適合進(jìn)行海量數(shù)據(jù)存儲(chǔ)的,通過(guò)Memcached將熱點(diǎn)數(shù)據(jù)加載到cache,加速訪問(wèn),很多公司都曾經(jīng)使用過(guò)這樣的架構(gòu),但隨著業(yè)務(wù)數(shù)據(jù)量的不斷增加,和訪問(wèn)量的持續(xù)增長(zhǎng),我們遇到了很多問(wèn)題:
1.MySQL需要不斷進(jìn)行拆庫(kù)拆表,Memcached也需不斷跟著擴(kuò)容,擴(kuò)容和維護(hù)工作占據(jù)大量開(kāi)發(fā)時(shí)間。
2.Memcached與MySQL數(shù)據(jù)庫(kù)數(shù)據(jù)一致性問(wèn)題。
3.Memcached數(shù)據(jù)命中率低或down機(jī),大量訪問(wèn)直接穿透到DB,MySQL無(wú)法支撐。
4.跨機(jī)房cache同步問(wèn)題。
眾多NoSQL百花齊放,如何選擇
最近幾年,業(yè)界不斷涌現(xiàn)出很多各種各樣的NoSQL產(chǎn)品,那么如何才能正確地使用好這些產(chǎn)品,最大化地發(fā)揮其長(zhǎng)處,是我們需要深入研究和思考的問(wèn)題,實(shí)際歸根結(jié)底最重要的是了解這些產(chǎn)品的定位,并且了解到每款產(chǎn)品的tradeoffs,在實(shí)際應(yīng)用中做到揚(yáng)長(zhǎng)避短,總體上這些NoSQL主要用于解決以下幾種問(wèn)題
1.少量數(shù)據(jù)存儲(chǔ),高速讀寫(xiě)訪問(wèn)。此類(lèi)產(chǎn)品通過(guò)數(shù)據(jù)全部in-momery 的方式來(lái)保證高速訪問(wèn),同時(shí)提供數(shù)據(jù)落地的功能,實(shí)際這正是Redis最主要的適用場(chǎng)景。
2.海量數(shù)據(jù)存儲(chǔ),分布式系統(tǒng)支持,數(shù)據(jù)一致性保證,方便的集群節(jié)點(diǎn)添加/刪除。
3.這方面最具代表性的是dynamo和bigtable 2篇論文所闡述的思路。前者是一個(gè)完全無(wú)中心的設(shè)計(jì),節(jié)點(diǎn)之間通過(guò)gossip方式傳遞集群信息,數(shù)據(jù)保證最終一致性,后者是一個(gè)中心化的方案設(shè)計(jì),通過(guò)類(lèi)似一個(gè)分布式鎖服務(wù)來(lái)保證強(qiáng)一致性,數(shù)據(jù)寫(xiě)入先寫(xiě)內(nèi)存和redo log,然后定期compat歸并到磁盤(pán)上,將隨機(jī)寫(xiě)優(yōu)化為順序?qū)懀岣邔?xiě)入性能。
4.Schema free,auto-sharding等。比如目前常見(jiàn)的一些文檔數(shù)據(jù)庫(kù)都是支持schema-free的,直接存儲(chǔ)json格式數(shù)據(jù),并且支持auto-sharding等功能,比如mongodb。
面對(duì)這些不同類(lèi)型的NoSQL產(chǎn)品,我們需要根據(jù)我們的業(yè)務(wù)場(chǎng)景選擇最合適的產(chǎn)品。
Redis最適合所有數(shù)據(jù)in-momory的場(chǎng)景,雖然Redis也提供持久化功能,但實(shí)際更多的是一個(gè)disk-backed的功能,跟傳統(tǒng)意義上的持久化有比較大的差別,那么可能大家就會(huì)有疑問(wèn),似乎Redis更像一個(gè)加強(qiáng)版的Memcached,那么何時(shí)使用Memcached,何時(shí)使用 Redis呢?
如果簡(jiǎn)單地比較Redis與Memcached的區(qū)別,大多數(shù)都會(huì)得到以下觀點(diǎn):
1 、Redis不僅僅支持簡(jiǎn)單的k/v類(lèi)型的數(shù)據(jù),同時(shí)還提供list,set,zset,hash等數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ)。
2 、Redis支持?jǐn)?shù)據(jù)的備份,即master-slave模式的數(shù)據(jù)備份。
3 、Redis支持?jǐn)?shù)據(jù)的持久化,可以將內(nèi)存中的數(shù)據(jù)保持在磁盤(pán)中,重啟的時(shí)候可以再次加載進(jìn)行使用。
2. Redis常用數(shù)據(jù)類(lèi)型
Redis最為常用的數(shù)據(jù)類(lèi)型主要有以下:
String
Hash
List
Set
Sorted set
pub/sub
Transactions
在具體描述這幾種數(shù)據(jù)類(lèi)型之前,我們先通過(guò)一張圖了解下Redis內(nèi)部?jī)?nèi)存管理中是如何描述這些不同數(shù)據(jù)類(lèi)型的:
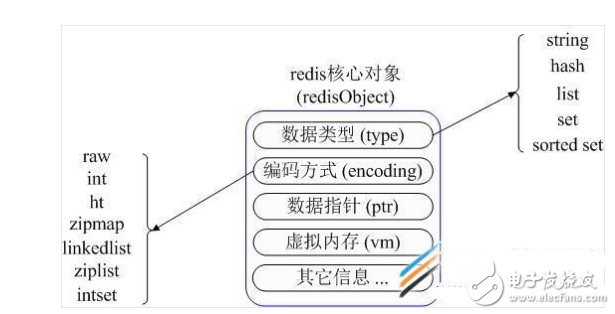
首先Redis內(nèi)部使用一個(gè)redisObject對(duì)象來(lái)表示所有的key和value,redisObject最主要的信息如上圖所示:
type代表一個(gè)value對(duì)象具體是何種數(shù)據(jù)類(lèi)型,
encoding是不同數(shù)據(jù)類(lèi)型在redis內(nèi)部的存儲(chǔ)方式,
比如:type=string代表value存儲(chǔ)的是一個(gè)普通字符串,那么對(duì)應(yīng)的encoding可以是raw或者是int,如果是int則代表實(shí)際 redis內(nèi)部是按數(shù)值型類(lèi)存儲(chǔ)和表示這個(gè)字符串的,當(dāng)然前提是這個(gè)字符串本身可以用數(shù)值表示,比如:”123″ “456″這樣的字符串。
這里需要特殊說(shuō)明一下vm字段,只有打開(kāi)了Redis的虛擬內(nèi)存功能,此字段才會(huì)真正的分配內(nèi)存,該功能默認(rèn)是關(guān)閉狀態(tài)的,該功能會(huì)在后面具體描述。通過(guò)上圖我們可以發(fā)現(xiàn)Redis使用redisObject來(lái)表示所有的key/value數(shù)據(jù)是比較浪費(fèi)內(nèi)存的,當(dāng)然這些內(nèi)存管理成本的付出主要也是為了給 Redis不同數(shù)據(jù)類(lèi)型提供一個(gè)統(tǒng)一的管理接口,實(shí)際作者也提供了多種方法幫助我們盡量節(jié)省內(nèi)存使用,我們隨后會(huì)具體討論。
3. 各種數(shù)據(jù)類(lèi)型應(yīng)用和實(shí)現(xiàn)方式
下面我們先來(lái)逐一的分析下這7種數(shù)據(jù)類(lèi)型的使用和內(nèi)部實(shí)現(xiàn)方式:
String:
Strings 數(shù)據(jù)結(jié)構(gòu)是簡(jiǎn)單的key-value類(lèi)型,value其實(shí)不僅是String,也可以是數(shù)字。
常用命令: set,get,decr,incr,mget 等。
應(yīng)用場(chǎng)景:String是最常用的一種數(shù)據(jù)類(lèi)型,普通的key/ value 存儲(chǔ)都可以歸為此類(lèi)。即可以完全實(shí)現(xiàn)目前 Memcached 的功能,并且效率更高。還可以享受Redis的定時(shí)持久化,操作日志及 Replication等功能。除了提供與 Memcached 一樣的get、set、incr、decr 等操作外,Redis還提供了下面一些操作:
獲取字符串長(zhǎng)度
往字符串a(chǎn)ppend內(nèi)容
設(shè)置和獲取字符串的某一段內(nèi)容
設(shè)置及獲取字符串的某一位(bit)
批量設(shè)置一系列字符串的內(nèi)容
實(shí)現(xiàn)方式:String在redis內(nèi)部存儲(chǔ)默認(rèn)就是一個(gè)字符串,被redisObject所引用,當(dāng)遇到incr,decr等操作時(shí)會(huì)轉(zhuǎn)成數(shù)值型進(jìn)行計(jì)算,此時(shí)redisObject的encoding字段為int。
Hash
常用命令:hget,hset,hgetall 等。
應(yīng)用場(chǎng)景:在Memcached中,我們經(jīng)常將一些結(jié)構(gòu)化的信息打包成HashMap,在客戶端序列化后存儲(chǔ)為一個(gè)字符串的值,比如用戶的昵稱、年齡、性別、積分等,這時(shí)候在需要修改其中某一項(xiàng)時(shí),通常需要將所有值取出反序列化后,修改某一項(xiàng)的值,再序列化存儲(chǔ)回去。這樣不僅增大了開(kāi)銷(xiāo),也不適用于一些可能并發(fā)操作的場(chǎng)合(比如兩個(gè)并發(fā)的操作都需要修改積分)。而Redis的Hash結(jié)構(gòu)可以使你像在數(shù)據(jù)庫(kù)中Update一個(gè)屬性一樣只修改某一項(xiàng)屬性值。
我們簡(jiǎn)單舉個(gè)實(shí)例來(lái)描述下Hash的應(yīng)用場(chǎng)景,比如我們要存儲(chǔ)一個(gè)用戶信息對(duì)象數(shù)據(jù),包含以下信息:
用戶ID為查找的key,存儲(chǔ)的value用戶對(duì)象包含姓名,年齡,生日等信息,如果用普通的key/value結(jié)構(gòu)來(lái)存儲(chǔ),主要有 2種存儲(chǔ)方式。
第一種方式將用戶ID作為查找key,把其他信息封裝成一個(gè)對(duì)象以序列化的方式存儲(chǔ),這種方式的缺點(diǎn)是,增加了序列化/反序列化的開(kāi)銷(xiāo),并且在需要修改其中一項(xiàng)信息時(shí),需要把整個(gè)對(duì)象取回,并且修改操作需要對(duì)并發(fā)進(jìn)行保護(hù),引入CAS等復(fù)雜問(wèn)題。
第二種方法是這個(gè)用戶信息對(duì)象有多少成員就存成多少個(gè)key-value對(duì)兒,用用戶ID+對(duì)應(yīng)屬性的名稱作為唯一標(biāo)識(shí)來(lái)取得對(duì)應(yīng)屬性的值,雖然省去了序列化開(kāi)銷(xiāo)和并發(fā)問(wèn)題,但是用戶ID為重復(fù)存儲(chǔ),如果存在大量這樣的數(shù)據(jù),內(nèi)存浪費(fèi)還是非常可觀的。
那么Redis提供的Hash很好的解決了這個(gè)問(wèn)題,Redis的Hash實(shí)際是內(nèi)部存儲(chǔ)的Value為一個(gè)HashMap,并提供了直接存取這個(gè)Map成員的接口。
也就是說(shuō),Key仍然是用戶ID, value是一個(gè)Map,這個(gè)Map的key是成員的屬性名,value是屬性值,這樣對(duì)數(shù)據(jù)的修改和存取都可以直接通過(guò)其內(nèi)部Map的 Key(Redis里稱內(nèi)部Map的key為field), 也就是通過(guò) key(用戶ID) + field(屬性標(biāo)簽) 就可以操作對(duì)應(yīng)屬性數(shù)據(jù)了,既不需要重復(fù)存儲(chǔ)數(shù)據(jù),也不會(huì)帶來(lái)序列化和并發(fā)修改控制的問(wèn)題。很好的解決了問(wèn)題。
這里同時(shí)需要注意,Redis提供了接口(hgetall)可以直接取到全部的屬性數(shù)據(jù),但是如果內(nèi)部Map的成員很多,那么涉及到遍歷整個(gè)內(nèi)部 Map的操作,由于Redis單線程模型的緣故,這個(gè)遍歷操作可能會(huì)比較耗時(shí),而另其它客戶端的請(qǐng)求完全不響應(yīng),這點(diǎn)需要格外注意。
實(shí)現(xiàn)方式:
上面已經(jīng)說(shuō)到Redis Hash對(duì)應(yīng)Value內(nèi)部實(shí)際就是一個(gè)HashMap,實(shí)際這里會(huì)有2種不同實(shí)現(xiàn),這個(gè)Hash的成員比較少時(shí)Redis為了節(jié)省內(nèi)存會(huì)采用類(lèi)似一維數(shù)組的方式來(lái)緊湊存儲(chǔ),而不會(huì)采用真正的HashMap結(jié)構(gòu),對(duì)應(yīng)的value redisObject的encoding為zipmap,當(dāng)成員數(shù)量增大時(shí)會(huì)自動(dòng)轉(zhuǎn)成真正的HashMap,此時(shí)encoding為ht。
List
常用命令:lpush,rpush,lpop,rpop,lrange等。
應(yīng)用場(chǎng)景:
Redis list的應(yīng)用場(chǎng)景非常多,也是Redis最重要的數(shù)據(jù)結(jié)構(gòu)之一,比如twitter的關(guān)注列表,粉絲列表等都可以用Redis的list結(jié)構(gòu)來(lái)實(shí)現(xiàn)。
Lists 就是鏈表,相信略有數(shù)據(jù)結(jié)構(gòu)知識(shí)的人都應(yīng)該能理解其結(jié)構(gòu)。使用Lists結(jié)構(gòu),我們可以輕松地實(shí)現(xiàn)最新消息排行等功能。Lists的另一個(gè)應(yīng)用就是消息隊(duì)列,
可以利用Lists的PUSH操作,將任務(wù)存在Lists中,然后工作線程再用POP操作將任務(wù)取出進(jìn)行執(zhí)行。Redis還提供了操作Lists中某一段的api,你可以直接查詢,刪除Lists中某一段的元素。
實(shí)現(xiàn)方式:
Redis list的實(shí)現(xiàn)為一個(gè)雙向鏈表,即可以支持反向查找和遍歷,更方便操作,不過(guò)帶來(lái)了部分額外的內(nèi)存開(kāi)銷(xiāo),Redis內(nèi)部的很多實(shí)現(xiàn),包括發(fā)送緩沖隊(duì)列等也都是用的這個(gè)數(shù)據(jù)結(jié)構(gòu)。
Set
常用命令:
sadd,spop,smembers,sunion 等。
應(yīng)用場(chǎng)景:
Redis set對(duì)外提供的功能與list類(lèi)似是一個(gè)列表的功能,特殊之處在于set是可以自動(dòng)排重的,當(dāng)你需要存儲(chǔ)一個(gè)列表數(shù)據(jù),又不希望出現(xiàn)重復(fù)數(shù)據(jù)時(shí),set 是一個(gè)很好的選擇,并且set提供了判斷某個(gè)成員是否在一個(gè)set集合內(nèi)的重要接口,這個(gè)也是list所不能提供的。
Sets 集合的概念就是一堆不重復(fù)值的組合。利用Redis提供的Sets數(shù)據(jù)結(jié)構(gòu),可以存儲(chǔ)一些集合性的數(shù)據(jù),比如在微博應(yīng)用中,可以將一個(gè)用戶所有的關(guān)注人存在一個(gè)集合中,將其所有粉絲存在一個(gè)集合。Redis還為集合提供了求交集、并集、差集等操作,可以非常方便的實(shí)現(xiàn)如共同關(guān)注、共同喜好、二度好友等功能,對(duì)上面的所有集合操作,你還可以使用不同的命令選擇將結(jié)果返回給客戶端還是存集到一個(gè)新的集合中。
實(shí)現(xiàn)方式:
set 的內(nèi)部實(shí)現(xiàn)是一個(gè) value永遠(yuǎn)為null的HashMap,實(shí)際就是通過(guò)計(jì)算hash的方式來(lái)快速排重的,這也是set能提供判斷一個(gè)成員是否在集合內(nèi)的原因。
Sorted Set
常用命令:
zadd,zrange,zrem,zcard等
使用場(chǎng)景:
Redis sorted set的使用場(chǎng)景與set類(lèi)似,區(qū)別是set不是自動(dòng)有序的,而sorted set可以通過(guò)用戶額外提供一個(gè)優(yōu)先級(jí)(score)的參數(shù)來(lái)為成員排序,并且是插入有序的,即自動(dòng)排序。當(dāng)你需要一個(gè)有序的并且不重復(fù)的集合列表,那么可以選擇sorted set數(shù)據(jù)結(jié)構(gòu),比如twitter 的public timeline可以以發(fā)表時(shí)間作為score來(lái)存儲(chǔ),這樣獲取時(shí)就是自動(dòng)按時(shí)間排好序的。
另外還可以用Sorted Sets來(lái)做帶權(quán)重的隊(duì)列,比如普通消息的score為1,重要消息的score為2,然后工作線程可以選擇按score的倒序來(lái)獲取工作任務(wù)。讓重要的任務(wù)優(yōu)先執(zhí)行。
實(shí)現(xiàn)方式:
Redis sorted set的內(nèi)部使用HashMap和跳躍表(SkipList)來(lái)保證數(shù)據(jù)的存儲(chǔ)和有序,HashMap里放的是成員到score的映射,而跳躍表里存放的是所有的成員,排序依據(jù)是HashMap里存的score,使用跳躍表的結(jié)構(gòu)可以獲得比較高的查找效率,并且在實(shí)現(xiàn)上比較簡(jiǎn)單。
Pub/Sub
Pub/Sub 從字面上理解就是發(fā)布(Publish)與訂閱(Subscribe),在Redis中,你可以設(shè)定對(duì)某一個(gè)key值進(jìn)行消息發(fā)布及消息訂閱,當(dāng)一個(gè) key值上進(jìn)行了消息發(fā)布后,所有訂閱它的客戶端都會(huì)收到相應(yīng)的消息。這一功能最明顯的用法就是用作實(shí)時(shí)消息系統(tǒng),比如普通的即時(shí)聊天,群聊等功能。
Transactions
誰(shuí)說(shuō)NoSQL都不支持事務(wù),雖然Redis的Transactions提供的并不是嚴(yán)格的ACID的事務(wù)(比如一串用EXEC提交執(zhí)行的命令,在執(zhí)行中服務(wù)器宕機(jī),那么會(huì)有一部分命令執(zhí)行了,剩下的沒(méi)執(zhí)行),但是這個(gè)Transactions還是提供了基本的命令打包執(zhí)行的功能(在服務(wù)器不出問(wèn)題的情況下,可以保證一連串的命令是順序在一起執(zhí)行的,中間有會(huì)有其它客戶端命令插進(jìn)來(lái)執(zhí)行)。Redis還提供了一個(gè)Watch功能,你可以對(duì)一個(gè)key進(jìn)行 Watch,然后再執(zhí)行Transactions,在這過(guò)程中,如果這個(gè)Watched的值進(jìn)行了修改,那么這個(gè)Transactions會(huì)發(fā)現(xiàn)并拒絕執(zhí)行。
4. Redis實(shí)際應(yīng)用場(chǎng)景
Redis在很多方面與其他數(shù)據(jù)庫(kù)解決方案不同:它使用內(nèi)存提供主存儲(chǔ)支持,而僅使用硬盤(pán)做持久性的存儲(chǔ);它的數(shù)據(jù)模型非常獨(dú)特,用的是單線程。另一個(gè)大區(qū)別在于,你可以在開(kāi)發(fā)環(huán)境中使用Redis的功能,但卻不需要轉(zhuǎn)到Redis。
轉(zhuǎn)向Redis當(dāng)然也是可取的,許多開(kāi)發(fā)者從一開(kāi)始就把Redis作為首選數(shù)據(jù)庫(kù);但設(shè)想如果你的開(kāi)發(fā)環(huán)境已經(jīng)搭建好,應(yīng)用已經(jīng)在上面運(yùn)行了,那么更換數(shù)據(jù)庫(kù)框架顯然不那么容易。另外在一些需要大容量數(shù)據(jù)集的應(yīng)用,Redis也并不適合,因?yàn)樗臄?shù)據(jù)集不會(huì)超過(guò)系統(tǒng)可用的內(nèi)存。所以如果你有大數(shù)據(jù)應(yīng)用,而且主要是讀取訪問(wèn)模式,那么Redis并不是正確的選擇。
然而我喜歡Redis的一點(diǎn)就是你可以把它融入到你的系統(tǒng)中來(lái),這就能夠解決很多問(wèn)題,比如那些你現(xiàn)有的數(shù)據(jù)庫(kù)處理起來(lái)感到緩慢的任務(wù)。這些你就可以通過(guò) Redis來(lái)進(jìn)行優(yōu)化,或者為應(yīng)用創(chuàng)建些新的功能。在本文中,我就想探討一些怎樣將Redis加入到現(xiàn)有的環(huán)境中,并利用它的原語(yǔ)命令等功能來(lái)解決 傳統(tǒng)環(huán)境中碰到的一些常見(jiàn)問(wèn)題。在這些例子中,Redis都不是作為首選數(shù)據(jù)庫(kù)。
1、顯示最新的項(xiàng)目列表
下面這個(gè)語(yǔ)句常用來(lái)顯示最新項(xiàng)目,隨著數(shù)據(jù)多了,查詢毫無(wú)疑問(wèn)會(huì)越來(lái)越慢。
SELECT * FROM foo WHERE … ORDER BY time DESC LIMIT 10
在Web應(yīng)用中,“列出最新的回復(fù)”之類(lèi)的查詢非常普遍,這通常會(huì)帶來(lái)可擴(kuò)展性問(wèn)題。這令人沮喪,因?yàn)轫?xiàng)目本來(lái)就是按這個(gè)順序被創(chuàng)建的,但要輸出這個(gè)順序卻不得不進(jìn)行排序操作。
類(lèi)似的問(wèn)題就可以用Redis來(lái)解決。比如說(shuō),我們的一個(gè)Web應(yīng)用想要列出用戶貼出的最新20條評(píng)論。在最新的評(píng)論邊上我們有一個(gè)“顯示全部”的鏈接,點(diǎn)擊后就可以獲得更多的評(píng)論。
我們假設(shè)數(shù)據(jù)庫(kù)中的每條評(píng)論都有一個(gè)唯一的遞增的ID字段。
我們可以使用分頁(yè)來(lái)制作主頁(yè)和評(píng)論頁(yè),使用Redis的模板,每次新評(píng)論發(fā)表時(shí),我們會(huì)將它的ID添加到一個(gè)Redis列表:
LPUSH latest.comments
我們將列表裁剪為指定長(zhǎng)度,因此Redis只需要保存最新的5000條評(píng)論:
LTRIM latest.comments 0 5000
每次我們需要獲取最新評(píng)論的項(xiàng)目范圍時(shí),我們調(diào)用一個(gè)函數(shù)來(lái)完成(使用偽代碼):
FUNCTION get_latest_comments(start, num_items):
id_list = redis.lrange(“l(fā)atest.comments”,start,start+num_items – 1)
IF id_list.length < num_items?
id_list = SQL_DB(“SELECT … ORDER BY time LIMIT …”)
END
RETURN id_list
END
這里我們做的很簡(jiǎn)單。在Redis中我們的最新ID使用了常駐緩存,這是一直更新的。但是我們做了限制不能超過(guò)5000個(gè)ID,因此我們的獲取ID函數(shù)會(huì)一直詢問(wèn)Redis。只有在start/count參數(shù)超出了這個(gè)范圍的時(shí)候,才需要去訪問(wèn)數(shù)據(jù)庫(kù)。
我們的系統(tǒng)不會(huì)像傳統(tǒng)方式那樣“刷新”緩存,Redis實(shí)例中的信息永遠(yuǎn)是一致的。SQL數(shù)據(jù)庫(kù)(或是硬盤(pán)上的其他類(lèi)型數(shù)據(jù)庫(kù))只是在用戶需要獲取“很遠(yuǎn)”的數(shù)據(jù)時(shí)才會(huì)被觸發(fā),而主頁(yè)或第一個(gè)評(píng)論頁(yè)是不會(huì)麻煩到硬盤(pán)上的數(shù)據(jù)庫(kù)了。
2、刪除與過(guò)濾
我們可以使用LREM來(lái)刪除評(píng)論。如果刪除操作非常少,另一個(gè)選擇是直接跳過(guò)評(píng)論條目的入口,報(bào)告說(shuō)該評(píng)論已經(jīng)不存在。
有些時(shí)候你想要給不同的列表附加上不同的過(guò)濾器。如果過(guò)濾器的數(shù)量受到限制,你可以簡(jiǎn)單的為每個(gè)不同的過(guò)濾器使用不同的Redis列表。畢竟每個(gè)列表只有5000條項(xiàng)目,但Redis卻能夠使用非常少的內(nèi)存來(lái)處理幾百萬(wàn)條項(xiàng)目。
3、排行榜相關(guān)
另一個(gè)很普遍的需求是各種數(shù)據(jù)庫(kù)的數(shù)據(jù)并非存儲(chǔ)在內(nèi)存中,因此在按得分排序以及實(shí)時(shí)更新這些幾乎每秒鐘都需要更新的功能上數(shù)據(jù)庫(kù)的性能不夠理想。
典型的比如那些在線游戲的排行榜,比如一個(gè)Facebook的游戲,根據(jù)得分你通常想要:
– 列出前100名高分選手
– 列出某用戶當(dāng)前的全球排名
這些操作對(duì)于Redis來(lái)說(shuō)小菜一碟,即使你有幾百萬(wàn)個(gè)用戶,每分鐘都會(huì)有幾百萬(wàn)個(gè)新的得分。
模式是這樣的,每次獲得新得分時(shí),我們用這樣的代碼:
ZADD leaderboard
你可能用userID來(lái)取代username,這取決于你是怎么設(shè)計(jì)的。
得到前100名高分用戶很簡(jiǎn)單:ZREVRANGE leaderboard 0 99。
用戶的全球排名也相似,只需要:ZRANK leaderboard 。
4、按照用戶投票和時(shí)間排序
排行榜的一種常見(jiàn)變體模式就像Reddit或Hacker News用的那樣,新聞按照類(lèi)似下面的公式根據(jù)得分來(lái)排序:
score = points / time^alpha
因此用戶的投票會(huì)相應(yīng)的把新聞挖出來(lái),但時(shí)間會(huì)按照一定的指數(shù)將新聞埋下去。下面是我們的模式,當(dāng)然算法由你決定。
模式是這樣的,開(kāi)始時(shí)先觀察那些可能是最新的項(xiàng)目,例如首頁(yè)上的1000條新聞都是候選者,因此我們先忽視掉其他的,這實(shí)現(xiàn)起來(lái)很簡(jiǎn)單。
每次新的新聞貼上來(lái)后,我們將ID添加到列表中,使用LPUSH + LTRIM,確保只取出最新的1000條項(xiàng)目。
有一項(xiàng)后臺(tái)任務(wù)獲取這個(gè)列表,并且持續(xù)的計(jì)算這1000條新聞中每條新聞的最終得分。計(jì)算結(jié)果由ZADD命令按照新的順序填充生成列表,老新聞則被清除。這里的關(guān)鍵思路是排序工作是由后臺(tái)任務(wù)來(lái)完成的。
5、處理過(guò)期項(xiàng)目
另一種常用的項(xiàng)目排序是按照時(shí)間排序。我們使用unix時(shí)間作為得分即可。
模式如下:
– 每次有新項(xiàng)目添加到我們的非Redis數(shù)據(jù)庫(kù)時(shí),我們把它加入到排序集合中。這時(shí)我們用的是時(shí)間屬性,current_time和time_to_live。
– 另一項(xiàng)后臺(tái)任務(wù)使用ZRANGE…SCORES查詢排序集合,取出最新的10個(gè)項(xiàng)目。如果發(fā)現(xiàn)unix時(shí)間已經(jīng)過(guò)期,則在數(shù)據(jù)庫(kù)中刪除條目。
6、計(jì)數(shù)
Redis是一個(gè)很好的計(jì)數(shù)器,這要感謝INCRBY和其他相似命令。
我相信你曾許多次想要給數(shù)據(jù)庫(kù)加上新的計(jì)數(shù)器,用來(lái)獲取統(tǒng)計(jì)或顯示新信息,但是最后卻由于寫(xiě)入敏感而不得不放棄它們。
好了,現(xiàn)在使用Redis就不需要再擔(dān)心了。有了原子遞增(atomic increment),你可以放心的加上各種計(jì)數(shù),用GETSET重置,或者是讓它們過(guò)期。
例如這樣操作:
INCR user: EXPIRE
user: 60
你可以計(jì)算出最近用戶在頁(yè)面間停頓不超過(guò)60秒的頁(yè)面瀏覽量,當(dāng)計(jì)數(shù)達(dá)到比如20時(shí),就可以顯示出某些條幅提示,或是其它你想顯示的東西。
7、特定時(shí)間內(nèi)的特定項(xiàng)目
另一項(xiàng)對(duì)于其他數(shù)據(jù)庫(kù)很難,但Redis做起來(lái)卻輕而易舉的事就是統(tǒng)計(jì)在某段特點(diǎn)時(shí)間里有多少特定用戶訪問(wèn)了某個(gè)特定資源。比如我想要知道某些特定的注冊(cè)用戶或IP地址,他們到底有多少訪問(wèn)了某篇文章。
每次我獲得一次新的頁(yè)面瀏覽時(shí)我只需要這樣做:
SADD page:day1:
當(dāng)然你可能想用unix時(shí)間替換day1,比如time()-(time()%3600*24)等等。
想知道特定用戶的數(shù)量嗎?只需要使用SCARD page:day1: 。
需要測(cè)試某個(gè)特定用戶是否訪問(wèn)了這個(gè)頁(yè)面?SISMEMBER page:day1: 。
8、實(shí)時(shí)分析正在發(fā)生的情況,用于數(shù)據(jù)統(tǒng)計(jì)與防止垃圾郵件等
我們只做了幾個(gè)例子,但如果你研究Redis的命令集,并且組合一下,就能獲得大量的實(shí)時(shí)分析方法,有效而且非常省力。使用Redis原語(yǔ)命令,更容易實(shí)施垃圾郵件過(guò)濾系統(tǒng)或其他實(shí)時(shí)跟蹤系統(tǒng)。
9、Pub/Sub
Redis的Pub/Sub非常非常簡(jiǎn)單,運(yùn)行穩(wěn)定并且快速。支持模式匹配,能夠?qū)崟r(shí)訂閱與取消頻道。
10、隊(duì)列
你應(yīng)該已經(jīng)注意到像list push和list pop這樣的Redis命令能夠很方便的執(zhí)行隊(duì)列操作了,但能做的可不止這些:比如Redis還有l(wèi)ist pop的變體命令,能夠在列表為空時(shí)阻塞隊(duì)列。
現(xiàn)代的互聯(lián)網(wǎng)應(yīng)用大量地使用了消息隊(duì)列(Messaging)。消息隊(duì)列不僅被用于系統(tǒng)內(nèi)部組件之間的通信,同時(shí)也被用于系統(tǒng)跟其它服務(wù)之間的交互。消息隊(duì)列的使用可以增加系統(tǒng)的可擴(kuò)展性、靈活性和用戶體驗(yàn)。非基于消息隊(duì)列的系統(tǒng),其運(yùn)行速度取決于系統(tǒng)中最慢的組件的速度(注:短板效應(yīng))。而基于消息隊(duì)列可以將系統(tǒng)中各組件解除耦合,這樣系統(tǒng)就不再受最慢組件的束縛,各組件可以異步運(yùn)行從而得以更快的速度完成各自的工作。
此外,當(dāng)服務(wù)器處在高并發(fā)操作的時(shí)候,比如頻繁地寫(xiě)入日志文件。可以利用消息隊(duì)列實(shí)現(xiàn)異步處理。從而實(shí)現(xiàn)高性能的并發(fā)操作。
11、緩存
Redis的緩存部分值得寫(xiě)一篇新文章,我這里只是簡(jiǎn)單的說(shuō)一下。Redis能夠替代memcached,讓你的緩存從只能存儲(chǔ)數(shù)據(jù)變得能夠更新數(shù)據(jù),因此你不再需要每次都重新生成數(shù)據(jù)了。
此部分內(nèi)容的原文地址:http://antirez.com/post/take-advantage-of-redis-adding-it-to-your-stack.html
5. 國(guó)內(nèi)外三個(gè)不同領(lǐng)域巨頭分享的Redis實(shí)戰(zhàn)經(jīng)驗(yàn)及使用場(chǎng)景
隨著應(yīng)用對(duì)高性能需求的增加,NoSQL逐漸在各大名企的系統(tǒng)架構(gòu)中生根發(fā)芽。這里我們將為大家分享社交巨頭新浪微博、傳媒巨頭Viacom及圖片分享領(lǐng)域佼佼者Pinterest帶來(lái)的Redis實(shí)踐,首先我們看新浪微博 @啟盼cobain的Redis實(shí)戰(zhàn)經(jīng)驗(yàn)分享:
一、新浪微博:史上最大的Redis集群
Tape is Dead,Disk is Tape,F(xiàn)lash is Disk,RAM Locality is King. — Jim Gray
Redis不是比較成熟的memcache或者M(jìn)ysql的替代品,是對(duì)于大型互聯(lián)網(wǎng)類(lèi)應(yīng)用在架構(gòu)上很好的補(bǔ)充。現(xiàn)在有越來(lái)越多的應(yīng)用也在紛紛基于Redis做架構(gòu)的改造。首先簡(jiǎn)單公布一下Redis平臺(tái)實(shí)際情況:
2200+億 commands/day 5000億Read/day 500億Write/day
18TB+ Memory
500+ Servers in 6 IDC 2000+instances
應(yīng)該是國(guó)內(nèi)外比較大的Redis使用平臺(tái),今天主要從應(yīng)用角度談?wù)凴edis服務(wù)平臺(tái)。
Redis使用場(chǎng)景
1.Counting(計(jì)數(shù))
計(jì)數(shù)的應(yīng)用在另外一篇文章里較詳細(xì)的描述,計(jì)數(shù)場(chǎng)景的優(yōu)化 http://www.xdata.me/?p=262這里就不多加描述了。
可以預(yù)見(jiàn)的是,有很多同學(xué)認(rèn)為把計(jì)數(shù)全部存在內(nèi)存中成本非常高,我在這里用個(gè)圖表來(lái)表達(dá)下我的觀點(diǎn):
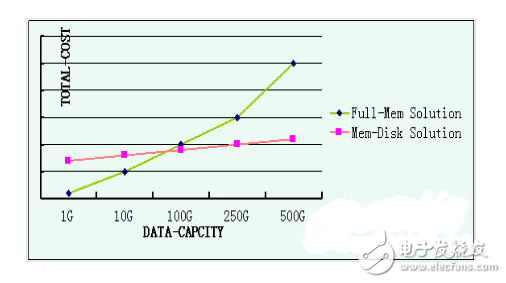
很多情況大家都會(huì)設(shè)想純使用內(nèi)存的方案會(huì)很有很高成本,但實(shí)際情況往往會(huì)有一些不一樣:
COST,對(duì)于有一定吞吐需求的應(yīng)用來(lái)說(shuō),肯定會(huì)單獨(dú)申請(qǐng)DB、Cache資源,很多擔(dān)心DB寫(xiě)入性能的同學(xué)還會(huì)主動(dòng)將DB更新記入異步隊(duì)列,而這三塊的資源的利用率一般都不會(huì)太高。資源算下來(lái),你驚異的發(fā)現(xiàn):反而純內(nèi)存的方案會(huì)更精簡(jiǎn)!
KISS原則,這對(duì)于開(kāi)發(fā)是非常友好的,我只需要建立一套連接池,不用擔(dān)心數(shù)據(jù)一致性的維護(hù),不用維護(hù)異步隊(duì)列。
Cache穿透風(fēng)險(xiǎn),如果后端使用DB,肯定不會(huì)提供很高的吞吐能力,cache宕機(jī)如果沒(méi)有妥善處理,那就悲劇了。
大多數(shù)的起始存儲(chǔ)需求,容量較小。
2.Reverse cache(反向cache)
面對(duì)微博常常出現(xiàn)的熱點(diǎn),如最近出現(xiàn)了較為火爆的短鏈,短時(shí)間有數(shù)以萬(wàn)計(jì)的人點(diǎn)擊、跳轉(zhuǎn),而這里會(huì)常常涌現(xiàn)一些需求,比如我們向快速在跳轉(zhuǎn)時(shí)判定用戶等級(jí),是否有一些賬號(hào)綁定,性別愛(ài)好什么的,已給其展示不同的內(nèi)容或者信息。
普通采用memcache+Mysql的解決方案,當(dāng)調(diào)用id合法的情況下,可支撐較大的吞吐。但當(dāng)調(diào)用id不可控,有較多垃圾用戶調(diào)用時(shí),由于memcache未有命中,會(huì)大量的穿透至Mysql服務(wù)器,瞬間造成連接數(shù)瘋長(zhǎng),整體吞吐量降低,響應(yīng)時(shí)間變慢。
這里我們可以用redis記錄全量的用戶判定信息,如string key:uid int:type,做一次反向的cache,當(dāng)用戶在redis快速獲取自己等級(jí)等信息后,再去Mc+Mysql層去獲取全量信息。如圖:
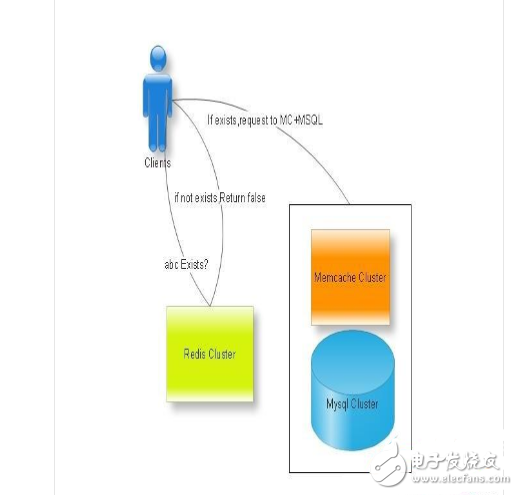
當(dāng)然這也不是最優(yōu)化的場(chǎng)景,如用Redis做bloomfilter,可能更加省用內(nèi)存。
3.Top 10 list
產(chǎn)品運(yùn)營(yíng)總會(huì)讓你展示最近、最熱、點(diǎn)擊率最高、活躍度最高等等條件的top list。很多更新較頻繁的列表如果使用MC+MySQL維護(hù)的話緩存失效的可能性會(huì)比較大,鑒于占用內(nèi)存較小的情況,使用Redis做存儲(chǔ)也是相當(dāng)不錯(cuò)的。
4.Last Index
用戶最近訪問(wèn)記錄也是redis list的很好應(yīng)用場(chǎng)景,lpush lpop自動(dòng)過(guò)期老的登陸記錄,對(duì)于開(kāi)發(fā)來(lái)說(shuō)還是非常友好的。
5.Relation List/Message Queue
這里把兩個(gè)功能放在最后,因?yàn)檫@兩個(gè)功能在現(xiàn)實(shí)問(wèn)題當(dāng)中遇到了一些困難,但在一定階段也確實(shí)解決了我們很多的問(wèn)題,故在這里只做說(shuō)明。
Message Queue就是通過(guò)list的lpop及l(fā)push接口進(jìn)行隊(duì)列的寫(xiě)入和消費(fèi),由于本身性能較好也能解決大部分問(wèn)題。
6.Fast transaction with Lua
Redis 的Lua的功能擴(kuò)展實(shí)際給Redis帶來(lái)了更多的應(yīng)用場(chǎng)景,你可以編寫(xiě)若干command組合作為一個(gè)小型的非阻塞事務(wù)或者更新邏輯,如:在收到 message推送時(shí),同時(shí)1.給自己的增加一個(gè)未讀的對(duì)話 2.給自己的私信增加一個(gè)未讀消息 3.最后給發(fā)送人回執(zhí)一個(gè)完成推送消息,這一層邏輯完全可以在Redis Server端實(shí)現(xiàn)。
但是,需要注意的是Redis會(huì)將lua script的全部?jī)?nèi)容記錄在aof和傳送給slave,這也將是對(duì)磁盤(pán),網(wǎng)卡一個(gè)不小的開(kāi)銷(xiāo)。
7.Instead of Memcache
很多測(cè)試和應(yīng)用均已證明,
在性能方面Redis并沒(méi)有落后memcache多少,而單線程的模型給Redis反而帶來(lái)了很強(qiáng)的擴(kuò)展性。
在很多場(chǎng)景下,Redis對(duì)同一份數(shù)據(jù)的內(nèi)存開(kāi)銷(xiāo)是小于memcache的slab分配的。
Redis提供的數(shù)據(jù)同步功能,其實(shí)是對(duì)cache的一個(gè)強(qiáng)有力功能擴(kuò)展。
Redis使用的重要點(diǎn)
1.rdb/aof Backup!
我們線上的Redis 95%以上是承擔(dān)后端存儲(chǔ)功能的,我們不僅用作cache,而更為一種k-v存儲(chǔ),他完全替代了后端的存儲(chǔ)服務(wù)(MySQL),故其數(shù)據(jù)是非常重要的,如果出現(xiàn)數(shù)據(jù)污染和丟失,誤操作等情況,將是難以恢復(fù)的。所以備份是非常必要的!為此,我們有共享的hdfs資源作為我們的備份池,希望能隨時(shí)可以還原業(yè)務(wù)所需數(shù)據(jù)。
2.Small item & Small instance!
由于Redis單線程(嚴(yán)格意義上不是單線程,但認(rèn)為對(duì)request的處理是單線程的)的模型,大的數(shù)據(jù)結(jié)構(gòu)list,sorted set,hash set的批量處理就意味著其他請(qǐng)求的等待,故使用Redis的復(fù)雜數(shù)據(jù)結(jié)構(gòu)一定要控制其單key-struct的大小。
另外,Redis單實(shí)例的內(nèi)存容量也應(yīng)該有嚴(yán)格的限制。單實(shí)例內(nèi)存容量較大后,直接帶來(lái)的問(wèn)題就是故障恢復(fù)或者Rebuild從庫(kù)的時(shí)候時(shí)間較長(zhǎng),而更糟糕的是,Redis rewrite aof和save rdb時(shí),將會(huì)帶來(lái)非常大且長(zhǎng)的系統(tǒng)壓力,并占用額外內(nèi)存,很可能導(dǎo)致系統(tǒng)內(nèi)存不足等嚴(yán)重影響性能的線上故障。我們線上96G/128G內(nèi)存服務(wù)器不建議單實(shí)例容量大于20/30G。
3.Been Available!
業(yè)界資料和使用比較多的是Redis sentinel(哨兵)
http://www.huangz.me/en/latest/storage/redis_code_analysis/sentinel.html
http://qiita.com/wellflat/items/8935016fdee25d4866d9
2000行C實(shí)現(xiàn)了服務(wù)器狀態(tài)檢測(cè),自動(dòng)故障轉(zhuǎn)移等功能。
但由于自身實(shí)際架構(gòu)往往會(huì)復(fù)雜,或者考慮的角度比較多,為此 @許琦eryk和我一同做了hypnos項(xiàng)目。
hypnos是神話中的睡神,字面意思也是希望我們工程師無(wú)需在休息時(shí)間處理任何故障。:-)
其工作原理示意如下:
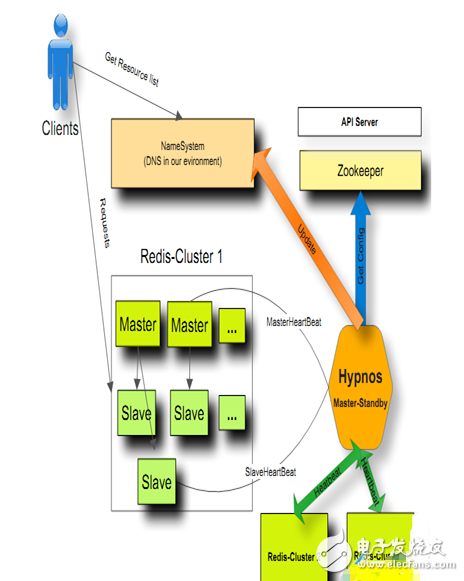
Talk is cheap, show me your code! 稍后將單獨(dú)寫(xiě)篇博客細(xì)致講下Hypnos的實(shí)現(xiàn)。
4.In Memory or not?
發(fā)現(xiàn)一種情況,開(kāi)發(fā)在溝通后端資源設(shè)計(jì)的時(shí)候,常常因?yàn)榱?xí)慣使用和錯(cuò)誤了解產(chǎn)品定位等原因,而忽視了對(duì)真實(shí)使用用戶的評(píng)估。也許這是一份歷史數(shù)據(jù),只有最近一天的數(shù)據(jù)才有人進(jìn)行訪問(wèn),而把歷史數(shù)據(jù)的容量和最近一天請(qǐng)求量都拋給內(nèi)存類(lèi)的存儲(chǔ)現(xiàn)實(shí)是非常不合理的。
所以當(dāng)你在究竟使用什么樣的數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)的時(shí)候,請(qǐng)務(wù)必先進(jìn)行成本衡量,有多少數(shù)據(jù)是需要存儲(chǔ)在內(nèi)存中的?有多少數(shù)據(jù)是對(duì)用戶真正有意義的。因?yàn)檫@其實(shí)對(duì)后端資源的設(shè)計(jì)是至關(guān)重要的,1G的數(shù)據(jù)容量和1T的數(shù)據(jù)容量對(duì)于設(shè)計(jì)思路是完全不一樣的
Plans in future?
1.slave sync改造
全部改造線上master-slave數(shù)據(jù)同步機(jī)制,這一點(diǎn)我們借鑒了MySQL Replication的思路,使用rdb+aof+pos作為數(shù)據(jù)同步的依據(jù),這里簡(jiǎn)要說(shuō)明為什么官方提供的psync沒(méi)有很好的滿足我們的需求:
假設(shè)A有兩個(gè)從庫(kù)B及C,及 A `— B&C,這時(shí)我們發(fā)現(xiàn)master A服務(wù)器有宕機(jī)隱患需要重啟或者A節(jié)點(diǎn)直接宕機(jī),需要切換B為新的主庫(kù),如果A、B、C不共享rdb及aof信息,C在作為B的從庫(kù)時(shí),仍會(huì)清除自身數(shù)據(jù),因?yàn)镃節(jié)點(diǎn)只記錄了和A節(jié)點(diǎn)的同步狀況。
故我們需要有一種將A`–B&C 結(jié)構(gòu)切換切換為A`–B`–C結(jié)構(gòu)的同步機(jī)制,psync雖然支持?jǐn)帱c(diǎn)續(xù)傳,但仍無(wú)法支持master故障的平滑切換。
實(shí)際上我們已經(jīng)在我們定制的Redis計(jì)數(shù)服務(wù)上使用了如上功能的同步,效果非常好,解決了運(yùn)維負(fù)擔(dān),但仍需向所有Redis服務(wù)推廣,如果可能我們也會(huì)向官方Redis提出相關(guān)sync slave的改進(jìn)。
2.更適合redis的name-system Or proxy
細(xì)心的同學(xué)發(fā)現(xiàn)我們除了使用DNS作為命名系統(tǒng),也在zookeeper中有一份記錄,為什么不讓用戶直接訪問(wèn)一個(gè)系統(tǒng),zk或者DNS選擇其一呢?
其實(shí)還是很簡(jiǎn)單,命名系統(tǒng)是個(gè)非常重要的組件,而dns是一套比較完善的命名系統(tǒng),我們?yōu)榇俗隽撕芏喔倪M(jìn)和試錯(cuò),zk的實(shí)現(xiàn)還是相對(duì)復(fù)雜,我們還沒(méi)有較強(qiáng)的把控粒度。我們也在思考用什么做命名系統(tǒng)更符合我們需求。
3.后端數(shù)據(jù)存儲(chǔ)
大內(nèi)存的使用肯定是一個(gè)重要的成本優(yōu)化方向,flash盤(pán)及分布式的存儲(chǔ)也在我們未來(lái)計(jì)劃之中。(原文鏈接: Largest Redis Clusters Ever)
二、Pinterest:Reids維護(hù)上百億的相關(guān)性
Pinterest已經(jīng)成為硅谷最瘋故事之一,在2012年,他們基于PC的業(yè)務(wù)增加1047%,移動(dòng)端采用增加1698%, 該年3月其獨(dú)立訪問(wèn)數(shù)量更飆升至533億。在Pinterest,人們關(guān)注的事物以百億記——每個(gè)用戶界面都會(huì)查詢某個(gè)board或者是用戶是否關(guān)注的行為促成了異常復(fù)雜的工程問(wèn)題。這也讓Redis獲得了用武之地。經(jīng)過(guò)數(shù)年的發(fā)展,Pinterest已經(jīng)成為媒體、社交等多個(gè)領(lǐng)域的佼佼者,其輝煌戰(zhàn)績(jī)?nèi)缦拢?/p>
獲得的推薦流量高于Google+、YouTube及LinkedIn三者的總和
與Facebook及Twitter一起成為最流行的三大社交網(wǎng)絡(luò)
參考Pinterest進(jìn)行購(gòu)買(mǎi)的用戶比其它網(wǎng)站更高( 更多詳情)
如您所想,基于其獨(dú)立訪問(wèn)數(shù),Pinterest的高規(guī)模促成了一個(gè)非常高的IT基礎(chǔ)設(shè)施需求。
通過(guò)緩存來(lái)優(yōu)化用戶體驗(yàn)
近日,Pinterest工程經(jīng)理Abhi Khune對(duì)其公司的用戶體驗(yàn)需求及Redis的使用經(jīng)驗(yàn) 進(jìn)行了分享。即使是滋生的應(yīng)用程序打造者,在分析網(wǎng)站的細(xì)節(jié)之前也不會(huì)理解這些特性,因此先大致的理解一下使用場(chǎng)景:首先,為每個(gè)粉絲進(jìn)行提及到的預(yù)檢查;其次,UI將準(zhǔn)確的顯示用戶的粉絲及關(guān)注列表分頁(yè)。高效的執(zhí)行這些操作,每次點(diǎn)擊都需要非常高的性能架構(gòu)。
不能免俗,Pinterest的軟件工程師及架構(gòu)師已經(jīng)使用了MySQL及memcache,但是緩存解決方案仍然達(dá)到了他們的瓶頸;因此為了擁有更好的用戶體驗(yàn),緩存必須被擴(kuò)充。而在實(shí)際操作過(guò)程中,工程團(tuán)隊(duì)已然發(fā)現(xiàn)緩存只有當(dāng)用戶sub-graph已經(jīng)在緩存中時(shí)才會(huì)起到作用。因此。任何使用這個(gè)系統(tǒng)的人都需要被緩存,這就導(dǎo)致了整個(gè)圖的緩存。同時(shí),最常見(jiàn)的查詢“用戶A是否關(guān)注了用戶B”的答案經(jīng)常是否定的,然而這卻被作為了緩存丟失,從而促成一個(gè)數(shù)據(jù)庫(kù)查詢,因此他們需要一個(gè)新的方法來(lái)擴(kuò)展緩存。最終,他們團(tuán)隊(duì)決定使用Redis來(lái)存儲(chǔ)整個(gè)圖,用以服務(wù)眾多的列表。
使用Redis存儲(chǔ)大量的Pinterest列表
Pinterest使用了Redis作為解決方案,并將性能推至了內(nèi)存數(shù)據(jù)庫(kù)等級(jí),為用戶保存多種類(lèi)型列表:
關(guān)注者列表
你所關(guān)注的board列表
粉絲列表
關(guān)注你board的用戶列表
某個(gè)用戶中board中你沒(méi)有關(guān)注的列表
每個(gè)board的關(guān)注者及非關(guān)注者
Redis 為其7000萬(wàn)用戶存儲(chǔ)了以上的所有列表,本質(zhì)上講可以說(shuō)是儲(chǔ)存了所有粉絲圖,通過(guò)用戶ID分片。鑒于你可以通過(guò)類(lèi)型來(lái)查看以上列表的數(shù)據(jù),分析概要信息被用看起來(lái)更像事務(wù)的系統(tǒng)儲(chǔ)存及訪問(wèn)。Pinterest當(dāng)下的用戶like被限制為10萬(wàn),初略進(jìn)行統(tǒng)計(jì):如果每個(gè)用戶關(guān)注25個(gè)board,將會(huì)在用戶及board間產(chǎn)生17.5億的關(guān)系。同時(shí)更加重要的是,這些關(guān)系隨著系統(tǒng)的使用每天都會(huì)增加。
Pinterest的Reids架構(gòu)及運(yùn)營(yíng)
通過(guò)Pinterest的一個(gè)創(chuàng)始人了解到,Pinterest開(kāi)始使用Python及訂制的Django編寫(xiě)應(yīng)用程序,并一直持續(xù)到其擁有1800萬(wàn)用戶級(jí)日410TB用戶數(shù)據(jù)的時(shí)候。雖然使用了多個(gè)存儲(chǔ)對(duì)數(shù)據(jù)進(jìn)行儲(chǔ)存,工程師根據(jù)用戶id使用了8192個(gè)虛擬分片,每個(gè)分片都運(yùn)行在一個(gè)Redis DB之上,同時(shí)1個(gè)Redis實(shí)例將運(yùn)行多個(gè)Redis DB。為了對(duì)CPU核心的充分使用,同一臺(tái)主機(jī)上同時(shí)使用多線程和單線程Redis實(shí)例。
鑒于整個(gè)數(shù)據(jù)集運(yùn)行在內(nèi)存當(dāng)中,Redis在Amazon EBS上對(duì)每秒傳輸進(jìn)來(lái)的寫(xiě)入都會(huì)進(jìn)行持久化。擴(kuò)展主要通過(guò)兩個(gè)方面進(jìn)行:第一,保持50%的利用率,通過(guò)主從轉(zhuǎn)換,機(jī)器上運(yùn)行的Redis實(shí)例一半會(huì)轉(zhuǎn)譯到一個(gè)新機(jī)器上;第二,擴(kuò)展節(jié)點(diǎn)和分片。整個(gè)Redis集群都會(huì)使用一個(gè)主從配置,從部分將被當(dāng)做一個(gè)熱備份。一旦主節(jié)點(diǎn)失敗,從部分會(huì)立刻完成主的轉(zhuǎn)換,同時(shí)一個(gè)新的從部分將會(huì)被添加,ZooKeeper將完成整個(gè)過(guò)程。同時(shí)他們每個(gè)小時(shí)都會(huì)在Amazon S3上運(yùn)行BGsave做更持久的儲(chǔ)存——這項(xiàng)Reids操作會(huì)在后端進(jìn)行,之后Pinterest會(huì)使用這些數(shù)據(jù)做MapReduce和分析作業(yè) 。
三、Viacom:Redis在系統(tǒng)中的用例盤(pán)點(diǎn)
Viacom是全球最大的傳媒集體之一,同時(shí)也遭遇了當(dāng)下最大的數(shù)據(jù)難題之一:如何處理日益劇增的動(dòng)態(tài)視頻內(nèi)容。
著眼這一挑戰(zhàn)的上升趨勢(shì),我們會(huì)發(fā)現(xiàn):2010年世界上所有數(shù)據(jù)體積達(dá)到ZB級(jí),而單單2012這一年,互聯(lián)網(wǎng)產(chǎn)生的數(shù)據(jù)就增加了2.8個(gè)ZB,其中大部分的數(shù)據(jù)都是非結(jié)構(gòu)化的,包括了視頻和圖片。
覆蓋MVN(以前稱為MTV Networks、Paramount及BET),Viacom是個(gè)名副其實(shí)的傳媒巨頭,支持眾多人氣站點(diǎn),其中包括The Daily Show、osh.0、South Park Studios、GameTrailers.com等。作為媒體公司,這些網(wǎng)站上的文檔、圖片、視頻短片都在無(wú)時(shí)無(wú)刻的更新。長(zhǎng)話短說(shuō),下面就進(jìn)入 Viacom高級(jí)架構(gòu)師Michael Venezia 分享的Redis實(shí)踐:
Viacom的網(wǎng)站架構(gòu)背景
對(duì)于Viacom,橫跨多個(gè)站點(diǎn)傳播內(nèi)容讓必須專(zhuān)注于規(guī)模的需求,同時(shí)為了將內(nèi)容竟可能快的傳播到相應(yīng)用戶,他們還必須聚焦內(nèi)容之間的關(guān)系。然而即使The Daily Show、Nickelodeon、Spike或者是VH1 這些單獨(dú)的網(wǎng)站上,日平均PV都可以達(dá)到千萬(wàn),峰值時(shí)流量更會(huì)達(dá)到平均值的20-30倍。同時(shí)基于對(duì)實(shí)時(shí)的需求,動(dòng)態(tài)的規(guī)模及速度已成為架構(gòu)的基礎(chǔ)之一。
除去動(dòng)態(tài)規(guī)模之外,服務(wù)還必須基于用戶正在瀏覽的視頻或者是地理位置來(lái)推測(cè)用戶的喜好。比如說(shuō),某個(gè)頁(yè)面可能會(huì)將一個(gè)獨(dú)立的視頻片段與本地的促銷(xiāo),視頻系列的額外部分,甚至是相關(guān)視頻聯(lián)系起來(lái)。為了能讓用戶能在網(wǎng)站上停留更長(zhǎng)的時(shí)間,他們建立了一個(gè)能基于詳細(xì)元數(shù)據(jù)自動(dòng)建立頁(yè)面的軟件引擎,這個(gè)引擎可以根據(jù)用戶當(dāng)下興趣推薦額外的內(nèi)容。鑒于用于興趣的隨時(shí)改變,數(shù)據(jù)的類(lèi)型非常廣泛——類(lèi)似graph-like,實(shí)際上做的是大量的join。
這樣做有利于減少類(lèi)似視頻的大體積文件副本數(shù),比如數(shù)據(jù)存儲(chǔ)中一個(gè)獨(dú)立的記錄是Southpark片段“Cartman gets an Anal Probe”,這個(gè)片段可能也會(huì)出現(xiàn)在德語(yǔ)的網(wǎng)站上。雖然視頻是一樣的,但是英語(yǔ)用戶搜索的可能就是另一個(gè)不同的詞語(yǔ)。元數(shù)據(jù)的副本轉(zhuǎn)換成搜索結(jié)果,并指向相同的視頻。因此在美國(guó)用戶搜索真實(shí)標(biāo)題的情況下,德國(guó)瀏覽者可能會(huì)使用轉(zhuǎn)譯的標(biāo)題——德國(guó)網(wǎng)站上的“Cartman und die Analsonde”。
這些元數(shù)據(jù)覆蓋了其它記錄或者是對(duì)象,同時(shí)還可以根據(jù)使用環(huán)境來(lái)改變內(nèi)容,通過(guò)不同的規(guī)則集來(lái)限制不同地理位置或者是設(shè)備請(qǐng)求的內(nèi)容。
Viacom的實(shí)現(xiàn)方法
盡管許多機(jī)構(gòu)通過(guò)使用ORM及傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)來(lái)解決這個(gè)問(wèn)題,Viacom卻使用了一個(gè)迥然不同的方法。
本質(zhì)上,他們完全承擔(dān)不了對(duì)數(shù)據(jù)庫(kù)的直接訪問(wèn)。首先,他們處理的大部分都是流數(shù)據(jù),他們偏向于使用Akamai從地理上來(lái)分配內(nèi)容。其次,基于頁(yè)面的復(fù)雜性可能會(huì)取上萬(wàn)個(gè)對(duì)象。取如此多的數(shù)據(jù)顯然會(huì)影響到性能,因此JSON在1個(gè)數(shù)據(jù)服務(wù)中投入了使用。當(dāng)然,這些JSON對(duì)象的緩存將直接影響到網(wǎng)站性能。同時(shí),當(dāng)內(nèi)容或者是內(nèi)容之間的關(guān)系發(fā)生改變時(shí),緩存還需要?jiǎng)討B(tài)的進(jìn)行更新。
Viacom 依靠對(duì)象基元和超類(lèi)解決這個(gè)問(wèn)題,繼續(xù)以South Park為例:一個(gè)私有的“episode”類(lèi)包含了所有該片段相關(guān)信息,一個(gè)“super object”將有助于發(fā)現(xiàn)實(shí)際的視頻對(duì)象。超類(lèi)這個(gè)思想確實(shí)非常有益于建設(shè)低延遲頁(yè)面的自動(dòng)建設(shè),這些超類(lèi)可以幫助到基元對(duì)象到緩存的映射及保存。
Viacom為什么要使用Redis
每當(dāng)Viacom上傳一個(gè)視頻片段,系統(tǒng)將建立一個(gè)私有的對(duì)象,并于1個(gè)超類(lèi)關(guān)聯(lián)。每一次修改,他們都需要重估私有對(duì)象的每個(gè)改變,并更新所有復(fù)合對(duì)象。同時(shí),系統(tǒng)還需要無(wú)效Akamail中的URL請(qǐng)求。系統(tǒng)現(xiàn)有架構(gòu)的組合及更敏捷的管理方法需求將Viacom推向了Redis。
基于Viacom主要基于PHP,所以這個(gè)解決方案必須支持PHP。他們首先選擇了memcached做對(duì)象存儲(chǔ),但是它并不能很好的支持hashmap;同時(shí)他們還需要一個(gè)更有效的進(jìn)行無(wú)效步驟的重估,即更好的理解內(nèi)容的依賴性。本質(zhì)上說(shuō),他們需要時(shí)刻跟進(jìn)無(wú)效步驟中的依賴性改變。因此他們選擇了 Redis及Predis的組合來(lái)解決這個(gè)問(wèn)題。
他們團(tuán)隊(duì)使用Redis給southparkstudios.com和thedailyshow.com兩個(gè)網(wǎng)站建設(shè)依賴性圖,在取得了很大的成功后他們開(kāi)始著眼Redis其它適合場(chǎng)景。
Redis的其它使用場(chǎng)景
顯而易見(jiàn),如果有人使用Redis來(lái)建設(shè)依賴性圖,那么使用它來(lái)做對(duì)象處理也是說(shuō)得通的。同樣,這也成了架構(gòu)團(tuán)隊(duì)為Redis選擇的第二使用場(chǎng)景。 Redis的復(fù)制及持久化特性同時(shí)也征服了Viacom的運(yùn)營(yíng)團(tuán)隊(duì),因此在幾個(gè)開(kāi)發(fā)周期后,Redis成為他們網(wǎng)站的主要數(shù)據(jù)及依賴性儲(chǔ)存。
后兩個(gè)用例則是行為追蹤及瀏覽計(jì)數(shù)的緩沖,改變后的架構(gòu)是Redis每幾分鐘向MySQL中儲(chǔ)存一次,而瀏覽計(jì)數(shù)則通過(guò)Redis進(jìn)行存儲(chǔ)及計(jì)數(shù)。同時(shí) Redis還被用來(lái)做人氣的計(jì)算,一個(gè)基于訪問(wèn)數(shù)及訪問(wèn)時(shí)間的得分系統(tǒng)——如果某個(gè)視頻最近被訪問(wèn)的次數(shù)越多,它的人氣就越高。在如此多內(nèi)容上每隔 10-15分鐘做一次計(jì)算絕對(duì)不是類(lèi)似MySQL這樣傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)的強(qiáng)項(xiàng),Viacom使用Redis的理由也非常簡(jiǎn)單——在1個(gè)存儲(chǔ)瀏覽信息的 Redis實(shí)例上運(yùn)行Lua批處理作業(yè),計(jì)算出所有的得分表。信息被拷貝到另一個(gè)Redis實(shí)例上,用以支持相關(guān)的產(chǎn)品查詢。同時(shí)還在MySQL上做了另一個(gè)備份,用以以后的分析,這種組合會(huì)將這個(gè)過(guò)程耗費(fèi)的時(shí)間降低60倍。
Viacom還使用Redis存儲(chǔ)一步作業(yè)信息,這些信息被插入一個(gè)列表中,工作人員則使用BLPOP命令行在隊(duì)列中抓取頂端的任務(wù)。同時(shí)zsets被用于從眾多社交網(wǎng)絡(luò)(比如Twitter及Tumblr)上綜合內(nèi)容,Viacom通過(guò)Brightcove視頻播放器來(lái)同步多個(gè)內(nèi)容管理系統(tǒng)。
橫跨這些用例,幾乎所有的Redis命令都被使用——sets、lists、zlists、hashmaps、scripts、counters等。同時(shí),Redis也成為Viacom可擴(kuò)展架構(gòu)中不可或缺的一環(huán)。
-
Redis
+關(guān)注
關(guān)注
0文章
374瀏覽量
10871
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論