


連接視覺語言大模型與端到端自動駕駛
端到端自動駕駛在大規模駕駛數據上訓練,展現出很強的決策規劃能力,但是面對復雜罕見的駕駛場景,依然存在局限性,這是因為端到端模型缺乏常識知識和邏輯思維。而視覺語言多模態大模型(LargeVision-Language Models,LVLM),例如GPT-4O,已經展現出極強的視覺理解能力和分析能力,可以很好的與端到端模型互為補充,充當駕駛決策的“大腦”。
基于這個思路,我們提出了一種連接視覺語言多模態大模型和端到端模型的智駕系統 Senna,針對端到端模型魯棒性差,泛化性弱問題,行業首創“大模型高維駕駛決策-端到端低維軌跡規劃”的新駕駛范式,打造“大模型 +端到端”的下一代架構,實現安全,高效,擬人的智能駕駛。經多個數據集上的大量實驗證明Senna 具有業界最優的多模態+端到端規劃性能,展現出強大的跨場景泛化性和可遷移能力。
概述
端到端自動駕駛在大規模駕駛數據上訓練,展現出很強的決策規劃能力,但是面對復雜罕見的駕駛場景,依然存在局限性,這是因為端到端模型缺乏常識知識和邏輯思維。而視覺語言多模態大模型(Large Vision-Language Models,LVLM),例如GPT-4O,已經展現出極強的視覺理解能力和分析能力,可以很好的與端到端模型互為補充,充當駕駛決策的“大腦”。基于這個思路,我們提出了一種連接視覺語言多模態大模型和端到端模型的智駕系統Senna,針對端到端模型魯棒性差,泛化性弱問題,行業首創“大模型高維駕駛決策-端到端低維軌跡規劃”的新駕駛范式,打造“大模型+端到端”的下一代架構,實現安全,高效,擬人的智能駕駛。經多個數據集上的大量實驗證明,Senna具有業界最優的多模態+端到端規劃性能,展現出強大的跨場景泛化性和可遷移能力。
Senna解決的研究問題
此前基于大模型的自動駕駛方案,往往將大模型直接作為端到端模型,即直接用大模型預測規劃軌跡或者控制信號,但是大模型并不擅長預測精準的數值,因此這種方案并不一定是最優解。此前神經學的研究表明,人腦在做細致決策時,層次化的高維決策模塊和低維執行模塊組成的系統起到了關鍵的作用。例如,當想要左轉的駕駛員看到紅綠燈由紅變綠,大腦中首先會思考,現在紅綠燈變綠了,因此我可以加速啟動通過路口。然后再通過“打轉向燈”,“踩油門”等一系列動作完成通過路口這個目標。基于上述觀察,Senna主要嘗試探索和解決三個問題:
(1)如何有效地結合多模態大模型和端到端自動駕駛模型?

Senna采用解耦的行為決策-軌跡規劃思路,多模態大模型在大規模駕駛數據上微調,以提升其對駕駛場景的理解能力,并采用自然語言輸出高維決策指令,然后端到端模型基于大模型提供的決策指令,生成具體的規劃軌跡。一方面,使用大模型預測語言化的決策指令,可以最大利用其在語言任務上預訓練的知識和常識,生成合理的決策,并且避免預測精確數字效果欠佳的缺陷;另一方面,端到端模型更擅長精確的軌跡預測,將高維決策的任務解耦,可以降低端到端模型學習的難度,提升其軌跡規劃的精確度。
(2)如何設計一個面向駕駛任務的多模態大模型?
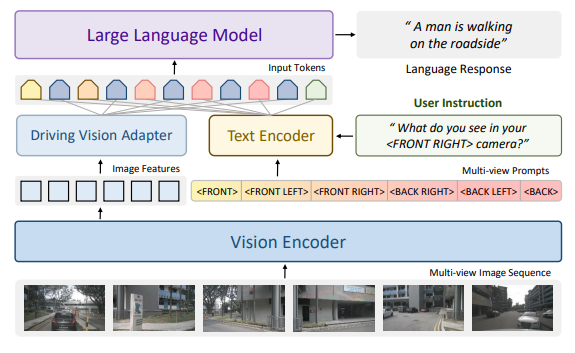
駕駛依賴于準確的空間感知,目前常見的多模態大模型沒有針對多圖輸入進行專門優化,此前針對駕駛任務的大模型或者僅支持前視輸入,缺乏完整的空間感知,存在安全隱患;或者支持多圖輸入,但是并沒有進行細致的設計,或針對其有效性進行驗證。
為了解決這些問題,我們提出了Senna,Senna包含兩個模塊,一個駕駛多模態大模型 (Senna-VLM) 和一個端到端模型(Senna-E2E),相比于通用的多模態大模型,Senna-VLM針對駕駛任務做出如下設計:首先,針對駕駛的大模型需要支持多圖從而可以輸入環視和多幀的信息,這對于準確的駕駛場景理解和安全非常重要。最初,我們嘗試簡單基于LLaVA-1.5模型加入環視多圖輸入,但是效果并不符合預期。在LLaVA中,一張圖像需要占用576個token,6張圖則需要占用3456個token,這幾乎要接近最大輸入長度,導致圖像信息占用的token數量過多。因此Senna-VLM對圖像編碼器輸出的圖像token做進一步特征壓縮,并設計了針對環視多圖的prompt,使得Senna可以區分不同視角的圖像特征并建立空間理解能力。
(3)如何有效地訓練面向駕駛任務的多模態大模型?
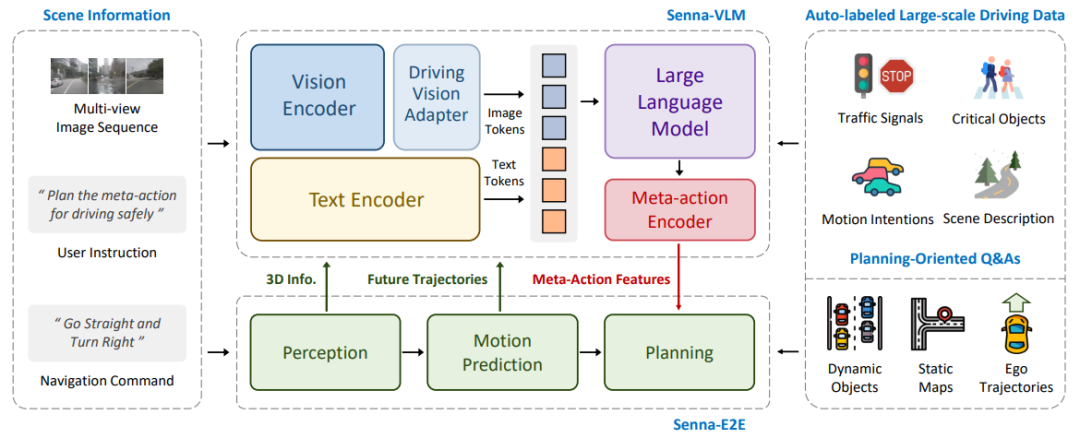
在有了適合駕駛任務的模型設計后,有效地訓練LVLM是最后一步。這部分包括兩方面的內容,數據和訓練策略。在數據方面,此前工作提出了一些策略,但是很多并不是針對規劃服務,例如檢測和grouding。另外,很多數據依賴于人工標注,這限制了數據的大規模生產。在本文中,我們首次驗證了不同類型的問答數據在駕駛規劃中的重要性。具體來說,我們引入了一系列面向規劃的問答數據,旨在增強Senna對駕駛場景中與規劃相關的線索的理解,最終實現更準確的規劃。這些問答數據包括駕駛場景描述、交通參與者的運動意圖預測、交通信號檢測、高維決策規劃等。我們的數據策略可以完全通過自動化流程實現大規模生產。至于訓練策略,大多數現有方法采用通用數據預訓練,然后針對駕駛任務微調。然而,我們的實驗結果表明,這可能不是最佳選擇。我們為 Senna-VLM 提出了一種三階段訓練策略,包括混合數據預訓練、駕駛通用微調和駕駛決策微調。實驗結果表明,我們提出的三階段訓練策略可以實現最佳的規劃性能。
Senna的關鍵創新
在模型層面,Senna提出層次化的規劃策略,可以充分利用大模型的常識知識和邏輯推理能力,生成準確的決策指令,并通過端到端模型生成具體的軌跡。另外,Senna設計了針對環視和多圖的策略,通過圖像token壓縮和精心設計的環視prompt,有效提高了多模態大模型對駕駛場景的理解。
在數據方面,我們設計了多種可以大規模自動標注的面向規劃的駕駛問答數據,包括場景描述、交通參與者行為預測、交通信號識別以及自車決策等。這些問答數據對于Senna生成準確的決策起到了關鍵作用。
在訓練層面,我們提出三階段的大模型訓練策略,不僅提升了Senna在駕駛場景的表現,且有效保留了其常識知識而不至于出現模式坍塌的問題。
Senna的實驗及應用效果
基于多個數據集上的大量實驗表明Senna 實現了state-of-the-art的規劃性能。實驗結果的亮點在于,通過使用在大規模數據集上預訓練的權重并進行微調,Senna 實現了顯著的性能提升,與沒有預訓練的模型相比,平均規劃誤差大幅降低了27.12% ,碰撞率降低了33.33%,這些結果驗證了 Senna 提出的結構化的決策規劃策略、模型結構設計和訓練策略的有效性。Senna強大的跨場景泛化性和可遷移能力,展現出成為下一代通用智駕大模型的潛力。
未來探索方向
Senna初步探索并驗證了基于語言化的決策將大模型和端到端模型結合的可行性。下一步,我們將利用更精細的語言決策,并基于決策信息以可控的方式實現個性化的軌跡規劃,并在可解釋性、閉環驗證等方面進一步探索優化。相信Senna將會激發行業在該領域的進一步研究和突破。
-
智能駕駛
+關注
關注
4文章
2823瀏覽量
50024 -
自動駕駛
+關注
關注
790文章
14344瀏覽量
170875 -
大模型
+關注
關注
2文章
3165瀏覽量
4115
原文標題:下一代“多模態大模型+端到端”架構Senna:開創智駕決策規劃全新范式
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中基于規則的決策和端到端大模型有何區別?
自動駕駛真的會來嗎?
端到端自動駕駛到底是什么?

理想汽車加速自動駕駛布局,成立“端到端”實體組織

Mobileye端到端自動駕駛解決方案的深度解析

Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統
端到端自動駕駛技術研究與分析
DiffusionDrive首次在端到端自動駕駛中引入擴散模型

端到端數據標注方案在自動駕駛領域的應用優勢
為什么自動駕駛端到端大模型有黑盒特性?

Nullmax端到端自動駕駛最新研究成果入選ICCV 2025





 工商網監
工商網監

評論