 ETH-X超節點:開辟AI算力約束突破的新路徑
ETH-X超節點:開辟AI算力約束突破的新路徑
面對人工智能大模型的迅速發展及其對算力資源的急劇增長需求,單芯片性能提升遭遇瓶頸,同時通過Scale Out策略擴展多機集群以增加算力也遇到了局限性。在此背景下,中國信通院與騰訊攜手GPU、CPU、交換機芯片制造商、服務器供應商、網絡設備廠商及互聯網企業等多方力量,共同發起超大帶寬ETH-X(以太網)超節點計劃,旨在通過技術創新與行業合作,構建開放可擴展的HBD(高帶寬域)超節點系統樣機,探索AI算力提升新途徑,為構建ETH-X超節點互聯開放協作產業生態提供支撐。同時,將共同編制相關技術規范,為行業樹立標準,引導超節點技術高質發展。
AI大模型發展與算力需求
AI大模型的發展依賴于持續提升算力。根據Scaling Law(規模定理),增大模型規模與增加訓練數據量是直接提升AI大模型智能水平與性能的關鍵途徑。但對集群算力需求的將呈指數級增長。
長序列是AI大模型發展的另一個重要方向。長序列提高AI大模型回答問題的質量、處理復雜任務的能力以及更強的記憶力和個性化能力的同時,也會加大對訓練和推理算力資源的需求1,尤其是對顯存資源的需求。因此滿足AI大模型發展需求,算力能力的持續提升成為一個重要基礎。
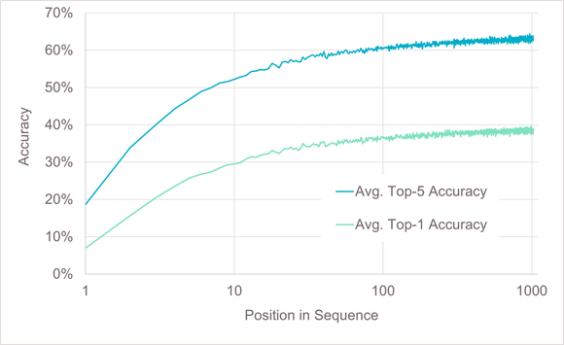
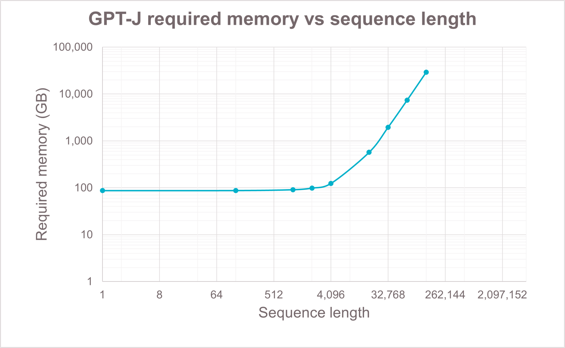
圖1 長序列帶來的準確率收益以及顯存需求
單芯片算力提升遇阻、
scale out集群算力提升受限
當前,提升集群算力已面臨一些明顯的制約因素。首先,單芯片性能提升受到HBM容量帶寬增長趕不上算力增長速度的限制,內存墻問題制約算法發揮。如在典型模型與并行方式下,Nvidia Hopper一代芯片的有效算力(HFU)明顯低于Ampere一代芯片,如圖2所示。另一種通過Scale out擴展集群規模提升整體算力的方式也受到GBS(Global Batch Size)不能無限增長的限制,導致在集群規模增大到一定程度后,HFU出現明顯下降。最后,模型參數量增大需要更大的模型并行規模,模型并行中Tensor并行或MOE類型的Expert并行都會在GPU之間產生大量的通信,并且這部分通信很難與計算進行overlap。而當前典型一機八卡服務器限制了Tensor并行的規模或Expert并行通過機間網絡,這都會導致HFU無法提高。
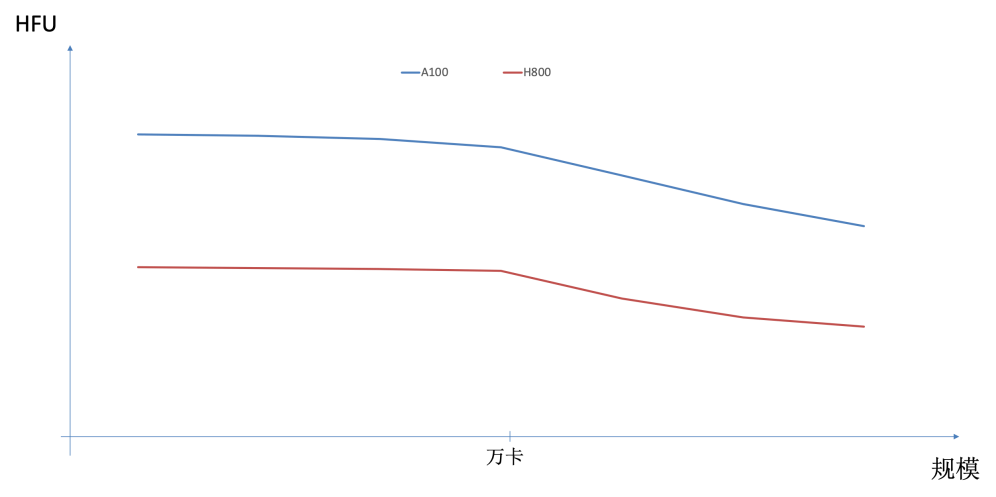
圖2 不同型號GPU以及不同規模集群對HFU的影響
通過scale up擴大HBD(超帶寬域)的超節點成為突破方向
HBD(High Bandwidth Domain)是一組以超帶寬(HB)互聯GPU-GPU的系統2。HBD內GPU-GPU通信帶寬是HBD之間GPU-GPU通信帶寬的數倍。如Nvidia H100 提供900GBps HB帶寬,HBD間GPU-GPU通信帶寬只有100GBps。因此在模型并行中將數據量大、無法overlap的部分限制在一個HBD內完成。
當前,HBD限制在一臺服務器內,典型1機8卡服務器是8張GPU卡之間通過某種HB連接技術實現互聯,構成一個HBD=8的系統。然而更大的參數規模、更長的序列長度、更多的MOE專家數量、更大的集群規模,都造成了更多的通信數據量。HBD=8的情況下,大量的數據通信均需經過HBD間的scale out網絡,因此通信占比提高、HFU下降的問題凸顯。
通過構建更大的HBD系統,以scale up方式提升系統算力是解決上述問題的有效途徑之一。如MIT與Meta的研究論文中,通過建模分析3,論證了擴大HBD對訓練性能的提升效果。另外,Nvidia也實現了不同規模HBD系統并進行了部署與驗證4。
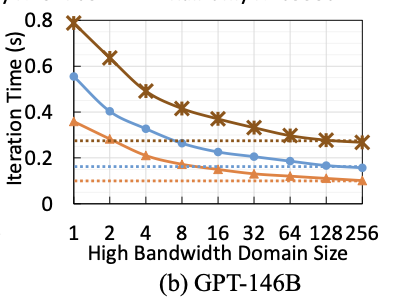
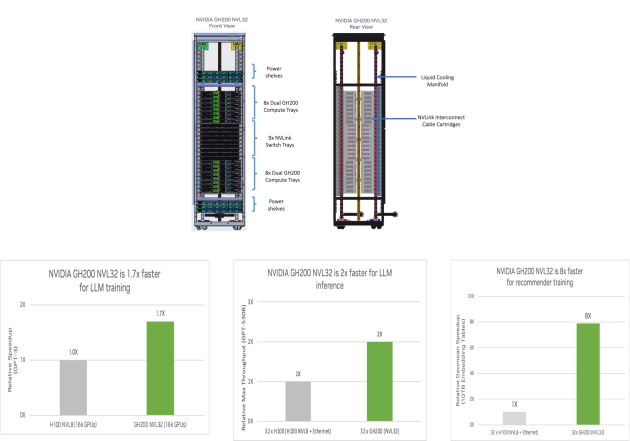
圖3 HBD超節點典型代表與業務收益舉例
Nvidia將HB互聯不僅用于GPU-GPU之間,而是將其應用到GPU-CPU/Memory的超大帶寬互聯,例如GH200、GB200產品。通過此方式為GPU提供一個超帶寬訪問CPU/Memory的能力。
Nvidia產品具備支持GPU-CPU/Memory的統一內存編制以及GPU通過內存語義接口read/write直接訪問CPU/Memory的能力,具有更高效、更直接的特點。但其同步操作的方式會對時延進行限制,制約可訪問CPU/Memory的距離與容量。另外,目前的軟件生態中,未有支持直接通過內存語義訪問CPU/Memory的系統。
相反若使用異步的memory offload方式將降低對時延的約束,并發利用多節點CPU/Memory,發揮HB互聯的帶寬優勢。另外,當前memory offload已具備一定軟件生態上的基礎,例如Zero offload5。
綜上所述,超節點是一個以超大帶寬(HB)互聯16卡以上GPU-GPU以及GPU-CPU/Memory的scale up系統,以HBD超節點為單位,通過傳統scale out擴展方式可形成更大規模、更高效的算力集群。超節點Scale Up的核心需求是超大帶寬(HB),但規模不需要很大。Scale Out的核心需求是超大規模。因此Scale Up網絡與Scale Out網絡更適合是相互獨立共存的兩張網絡。
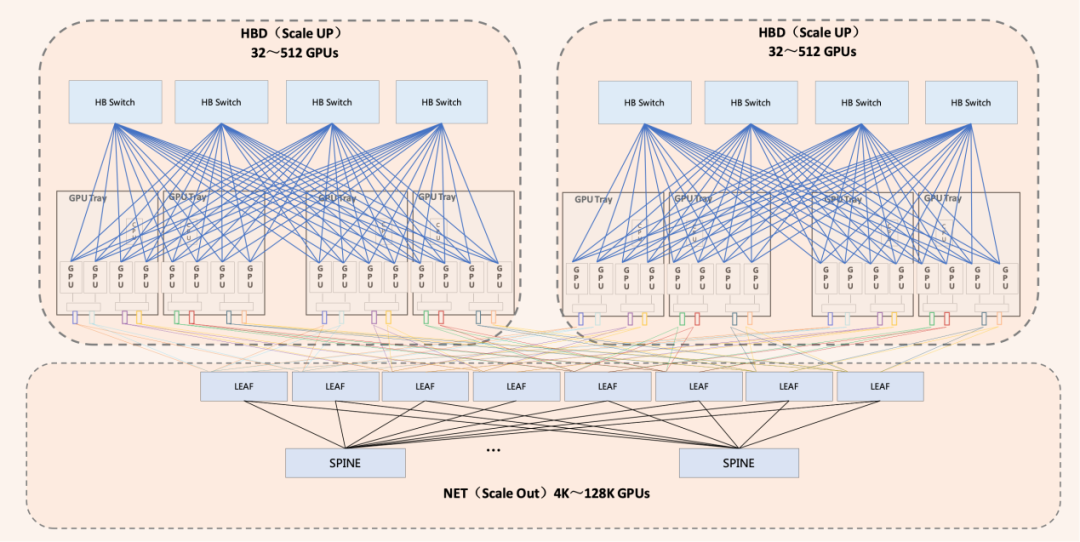
圖4 Scale Up超大帶寬與Scale Out超大規模共同構建高算力AI集群
ODCC ETH-X計劃構建開放超節點產業生態
超節點的核心是HB互聯技術,當前工業界已實現的超節點系統均是采用私有技術與協議實現HB互聯,例如Nvidia的NVLINK。但此類私有技術與協議由單一企業進行維護,無法保證技術長期、高效的發展。另外,從HBD超節點產品完善角度也無法保證系統的開放,導致無法形成良性、開放的產業生態。
以太網技術憑借開放的生態、多樣的產業鏈環境,為技術的長期演進發展提供支撐。當前以太網技術上從端口帶寬及交換容量方面已具有較強的競爭基礎。如以太網單端口800G MAC標準已成熟并產業化,以太網單芯片51.2T交換容量 ETH-switch也已在2023年產品化商用。
目前,以太網HB接口GPU產品的日益豐富,HBD超節點系統正逐步依托于以太網互聯技術,實現向更為模塊化、多元化的結構轉型,有效促進了多方廠商的積極參與,各廠商專精于系統內的不同組件或子系統開發,顯著提升了HBD超節點產品化的多樣性和方案的豐富度,為HBD超節點技術長期演進奠定穩固基石,確保其在應對未來挑戰時能夠持續進化,保持領先的技術競爭力與生態活力。
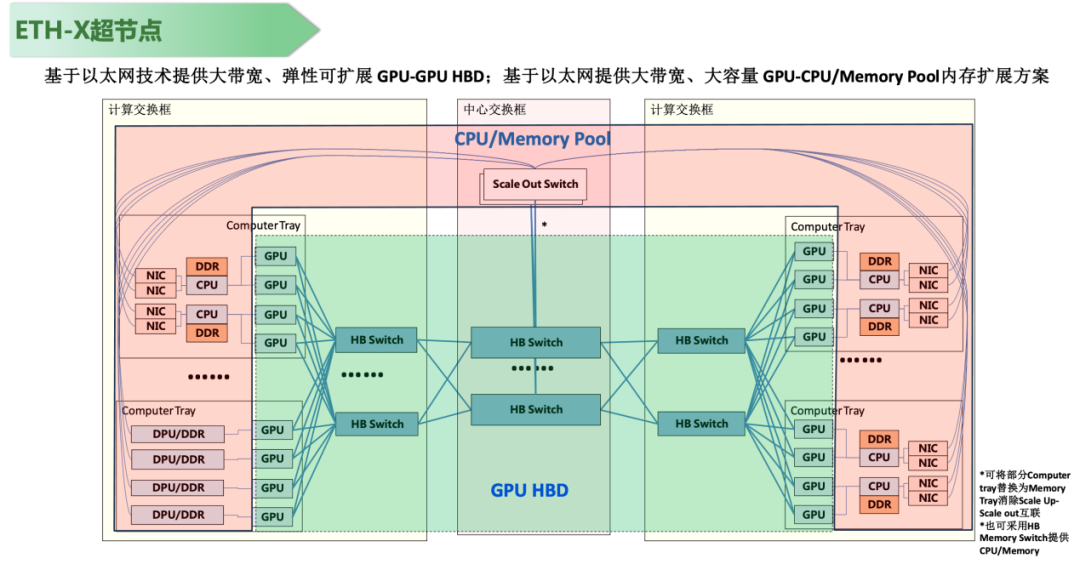
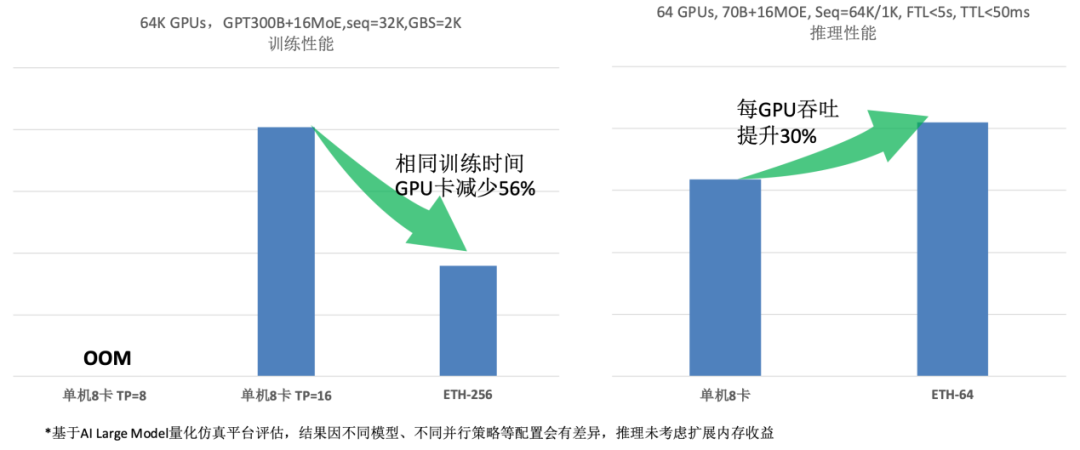
圖5 ETH-X超節點參考架構與預期收益評估
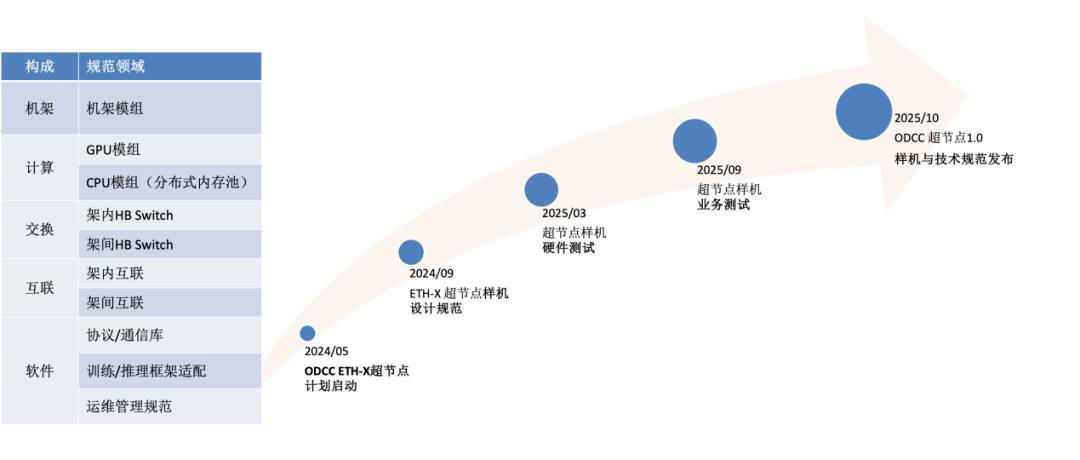
圖6 ETH-X技術規范構成與項目計劃
為推動算力產業的發展,ODCC網絡組啟動了ETH-X超節點系列項目。該項目由中國信通院、騰訊聯合快手科技、燧原科技、壁仞科技、華勤技術、銳捷網絡、新華三、云豹智能、云合智網、盛科通信、立訊精密、光迅科技等合作伙伴共同推動,以產品化樣機以及相關技術規范為目標,打造大型多GPU互聯算力集群系統。該項目計劃在2025年秋季前完成ETH-X超節點樣機軟硬件研發與相關業務系統驗證測試,同時發布ETH-X超節點技術規范1.0。
-
AI
+關注
關注
87文章
30728瀏覽量
268892 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238264 -
算力
+關注
關注
1文章
964瀏覽量
14794
原文標題:ETH-X超節點:探索突破AI算力約束的新途徑
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
奇異摩爾分享計算芯片Scale Up片間互聯新途徑

本源“量超融合先進計算平臺”入選2024算力中國·年度重大成果

哈爾濱即將迎來算力新紀元:中國移動智算中心節點盛大啟用
大模型時代的算力需求
光子計算芯片最新突破,峰值算力超1000tops,比電芯片更適合大模型

江蘇省算力基礎設施發展專項規劃:打造算力供給服務新高地
千億美元打造一個系統,成本越來越高的AI超算


立足算力,聚焦AI!順網科技全面走進AI智算時代

AI算力應用中的光模塊產品





 工商網監
工商網監
評論