 如何設定機器人語義地圖的細粒度級別
如何設定機器人語義地圖的細粒度級別
0. 這篇文章干了啥?
機器人學中的一個基本問題是創建機器人觀察到的場景的有用地圖表示,其中有用性由機器人利用地圖完成感興趣的任務的能力來衡量。最近的研究,包括構建語義度量三維地圖,通過檢測對象和區域與封閉的語義標簽集對應的工作。然而,封閉集檢測在能夠表示的概念集方面存在固有的限制,并且不能很好地處理自然語言的內在歧義性和可變性。為了克服這些限制,一組新的方法開始利用視覺語言基礎模型進行開放集語義理解。這些方法使用一個無類別分割網絡(SegmentAnything或SAM)生成圖像的細粒度段,然后應用一個基礎模型得到描述每個段的開放集語義的嵌入向量。然后通過將段關聯起來構造對象,只要它們的嵌入向量在預定義的相似度閾值內。然而,這些方法把調整適當的閾值的困難任務留給了用戶,以控制從場景中提取的段的數量,以及用于決定是否必須將兩個段聚類在一起的閾值。更重要的是,這些方法沒有捕捉到地圖中語義概念的選擇不僅僅受語義相似性驅動,而且是內在于任務的。例如,考慮一個被指派移動鋼琴的機器人。機器人通過區分所有鍵和弦的位置幾乎不會增加價值,但可以通過將鋼琴視為一個大對象來完成任務。另一方面,被指派演奏鋼琴的機器人必須將鋼琴視為許多對象(即鍵)。被指派調音鋼琴的機器人必須將鋼琴視為更多的對象------考慮到弦、調音銷等。同樣,像一堆衣服應該表示為一個單獨的堆還是單獨的衣服,或者一片森林應該表示為一個單獨的地貌區域還是樹枝、葉子、樹干等,直到我們明確了表示必須支持的任務,這些問題仍然沒有得到解決。人類不僅在決定要表示哪些對象以及如何表示時考慮任務(有意識或無意識),而且還能相應地忽略與任務無關的場景部分。
下面一起來閱讀一下這項工作~
1. 論文信息
標題:Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
作者:Dominic Maggio, Yun Chang, Nathan Hughes, Matthew Trang, Dan Griffith, Carlyn Dougherty, Eric Cristofalo, Lukas Schmid, Luca Carlone
機構:MIT
原文鏈接:https://arxiv.org/abs/2404.13696
代碼鏈接:https://github.com/MIT-SPARK/Clio
2. 摘要
現代無關類別圖像分割工具(例如SegmentAnything)和開放集語義理解(例如CLIP)為機器人感知和地圖繪制提供了前所未有的機會。雖然傳統的封閉集度量語義地圖僅限于幾十個或幾百個語義類別,但現在我們可以建立包含大量對象和無數語義變體的地圖。這給我們留下了一個基本問題:機器人必須在其地圖表示中包含什么樣的對象(更一般地說,包含什么樣的語義概念)才是正確的粒度?雖然相關工作通過調整對象檢測的閾值來隱式選擇粒度級別,但我們認為這樣的選擇本質上取決于任務。本文的第一個貢獻是提出了一個任務驅動的3D場景理解問題,其中機器人被給定了一系列用自然語言描述的任務,必須選擇足以完成任務的粒度和對象子集以及場景結構并將其保留在其地圖中。我們表明,可以使用信息瓶頸(IB)這一已建立的信息論框架來自然地構建這個問題。第二個貢獻是一種基于聚合式信息瓶頸方法的任務驅動的3D場景理解算法,能夠將環境中的3D基元聚類成與任務相關的對象和區域,并逐步執行。第三個貢獻是將我們的任務驅動聚類算法集成到一個名為Clio的實時流水線中,該流水線僅使用板載計算,隨著機器人探索環境,在線構建環境的分層3D場景圖。我們的最終貢獻是進行了大量實驗,表明Clio不僅可以實時構建緊湊的開放集3D場景圖,而且通過將地圖限制在相關的語義概念上,還提高了任務執行的準確性。
3. 效果展示
我們提出了Clio,一種新穎的方法,用于在嵌入的開放集語義的情況下實時構建任務驅動的3D場景圖。我們從經典的信息瓶頸原理汲取靈感,根據一組自然語言任務------例如"閱讀棕色教科書"------形成與任務相關的對象基元的聚類,并通過將場景聚類為與任務相關的語義區域,如"小廚房"或"工作區"來進行聚類。
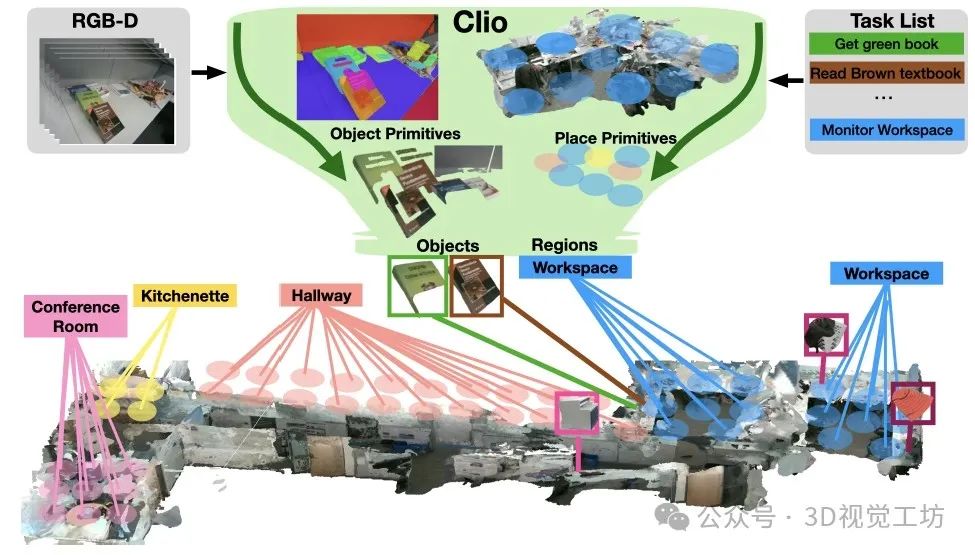
Clio使用Spot攜帶的筆記本電腦實時生成3D場景圖。我們展示了Spot能夠使用Clio的任務驅動3D場景圖執行用自然語言表達的抓取命令。

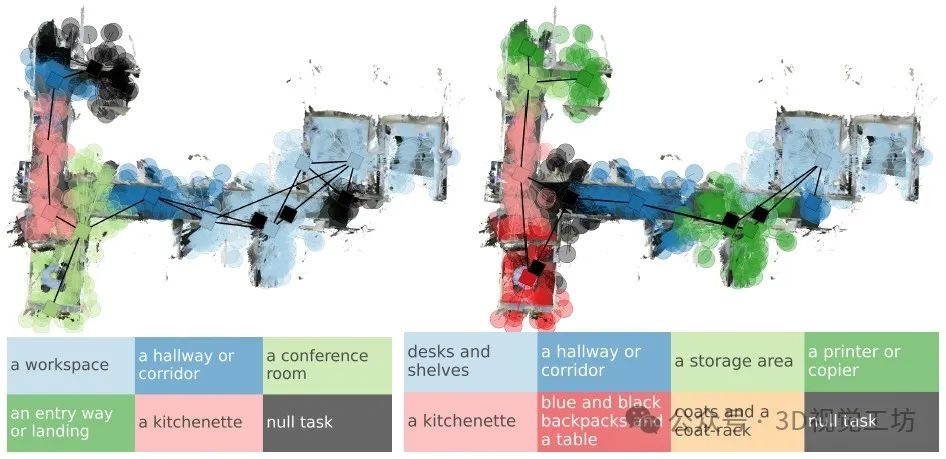
對地點聚類的定性示例。第一張圖顯示了通過類似房間類別標簽的任務提示進行聚類而產生的區域。第二張圖顯示了通過任務提示進行聚類而產生的區域,這些任務提示是潛在房間和物體的混合。
4. 主要貢獻
我們的第一個貢獻是闡述任務驅動的三維場景理解問題,其中機器人被給定一組在自然語言中指定的任務,并且需要構建一個足以完成給定任務的最小地圖表示。更具體地說,我們假設機器人能夠感知環境中的任務無關基元,以一組三維對象段和三維無障礙區域的形式,并且必須將它們聚類成一個僅包含相關對象和區域(例如,房間)的任務相關壓縮表示。這個問題可以自然地使用經典的信息瓶頸(IB)理論進行公式化,該理論還提供了用于任務驅動聚類的算法方法。
我們的第二個貢獻是將來自任務驅動三維場景理解問題的凝聚IB算法應用到問題中。具體而言,我們展示了如何使用CLIP嵌入獲取算法中所需的概率密度,并且表明由此產生的算法可以隨著機器人探索環境而逐步執行,其計算復雜度不隨環境大小增加。
我們的第三個貢獻是將提出的任務驅動聚類算法納入一個實時系統中,稱為Clio。Clio在操作開始時接收一組在自然語言中指定的任務列表:例如,這些可以是機器人在其生命周期內或當前部署期間被設想執行的任務。然后,隨著機器人的操作,Clio實時創建一個層次地圖,即環境的三維場景圖,其中表示僅保留相關對象和區域的任務。與當前用于開放集三維場景圖構建的方法相反,這些方法僅限于離線操作,當查詢大型視覺語言模型(VLMs)和大型語言模型(LLMs)時,并且Clio在實時和板載上運行,僅依賴于輕量級基礎模型,例如CLIP。我們在Replica數據集和四個真實環境中演示了Clio------一個公寓,一個辦公室,一個隔間和一個大型建筑場景。我們還展示了在一臺波士頓動力Spot四足機器人上使用Clio進行實時板載地圖制作。Clio不僅允許實時開放集三維場景圖構建,而且通過限制地圖僅包含相關對象和區域來提高任務執行的準確性。我們在https://github.com/MIT-SPARK/Clio上開源了Clio,并附帶了我們的自定義數據集。
5. 基本原理是啥?
Clio的前端接收RGB-D傳感器數據,并構建物體基元的圖形,地點圖形以及背景的度量-語義3D網格。Clio的后端執行增量聚合IB以根據用戶指定的任務列表對對象和區域進行聚類。
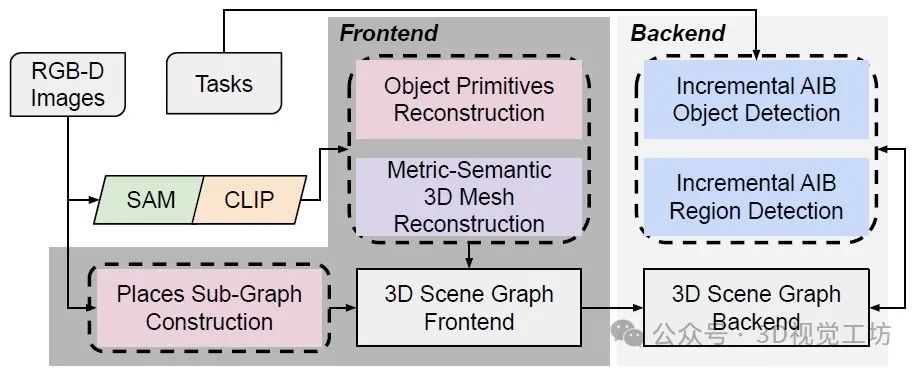
Cubicle數據集中需要任務提供對象定義糾正的部分示例。圖中展示了兩組任務的Clio聚類結果,分別列在(b)和(c)下;在聚類期間,任務列表中包含了14個額外的相同任務,但為了清晰起見未顯示出來。

6. 實驗結果
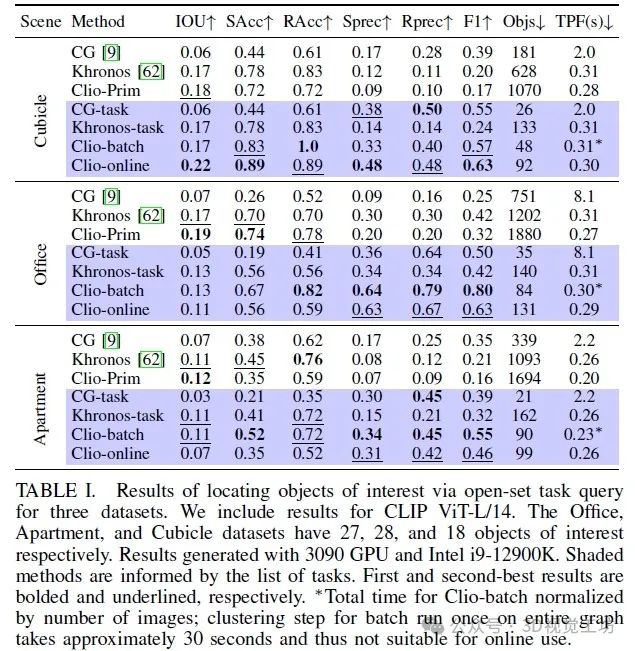
首先,我們觀察到任務驅動的方法(表I中藍色填充的行)通常會在保留較少對象的同時獲得更好的性能指標("Objs"列);這驗證了我們的論斷,即度量-語義映射需要以任務為驅動。具體來說,在某些情況下,與不考慮任務的基線相比,Clio 保留的對象數量要少一個數量級(與沒有信息瓶頸任務驅動聚類的 Clio-Prim 中的對象數量相比)。其次,我們觀察到 Clio 在各個數據集上的表現大多優于基線,在除了 Office 數據集的 IOU 和 SAcc 指標之外的所有情況下,Clio-batch 和 Clio-online 排名都位居前兩位。Office 數據集中的許多對象(例如訂書機、自行車頭盔)通常被檢測為孤立的基元,因此我們看到任務的知識對這個數據集的影響較小,但仍然能夠改善所有其他指標的性能。第三,我們觀察到 Clio 能夠在幾分之一秒內運行,比 ConceptGraphs 快約 6 倍;Khronos 和 Clio-Prim 也是實時運行的,但在其他指標方面性能不佳。最后,Clio-batch 和 Clio-online 在大多數情況下表現相似。它們性能上的差異是因為 Clio-online 是實時執行的,可能根據需要丟棄幀以跟上相機圖像流。這種差異有時有助于性能指標,有時則會妨礙性能指標的提升。
雖然 Clio 是為開放集檢測而設計的,但我們使用的評估方法在閉集 Replica 數據集上展示了我們的任務感知映射公式不會降低閉集映射任務的性能。在這里,我們的任務列表是每個 Replica 場景中存在的對象標簽集,其中每個標簽都被更改為"{類別}的圖像"。對于 Clio,在創建場景圖后,我們將每個檢測到的對象分配給與其余對象具有最高余弦相似度的標簽。為了提高 CLIP 在 Replica 數據集的低紋理區域的可靠性,我們通過將稠密 CLIP 特征合并到 Clio 中,包含了全局上下文的 CLIP 向量。我們報告準確率作為類平均召回(mAcc)和頻率加權的平均交并比(f-mIOU)。表II 顯示,Clio 達到了與領先的零樣本方法相當的性能,表明我們的任務感知聚類不會降低閉集任務的性能。
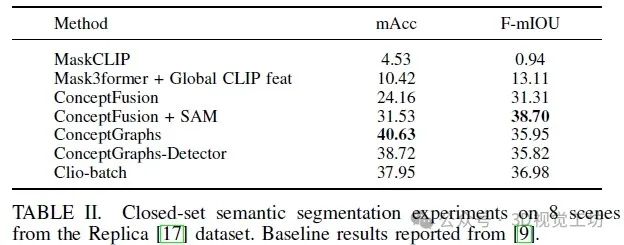
由于手動標記語義 3D 區域是一個高度主觀的任務,我們通過一個代理閉集任務評估了 Clio 區域的性能,其中 Clio 獲得了場景的可能房間標簽集作為任務。我們在三個數據集中標記了房間:Office、Apartment 和 Building。我們不分析 Cubicle 或 Replica 數據集,因為它們只包含單個房間。我們將 α 設為 0,以禁用對空任務的分配,因為每個地點都與至少一個房間標簽相關聯,并且我們在所有場景中保持所有參數不變。
我們使用精度和召回率指標來比較我們提出的 CLIP 嵌入向量關聯策略,Clio(平均),以及另一種更為樸素的策略,Clio(最近),后者使用從仍然可以從其中看到地點節點的最近圖像中獲取的嵌入向量。此外,我們使用 Hydra的純幾何房間分割方法作為閉集性能的比較點。這次比較的結果顯示在表III 中,該表還包括 F1 分數作為摘要統計量。表III 中的結果是在 5 次試驗中平均的,并報告了所有指標的標準偏差。我們注意到,我們選擇的關聯策略在 Office 和 Building 場景中優于 Hydra的純幾何方法和更為樸素的 Clio(最近),但在 Apartment 方面的 F1 分數方面表現相對較差。這是由于場景的性質;Office 和 Building 場景包含帶標簽的開放平面房間,需要語義知識來檢測(例如 Office 場景中的小廚房或 Building 場景中的樓梯間)。Apartment 主要包含幾何上不同的房間,這些房間可以用[7]中的幾何方法進行直接分割,而 Clio 則會過度分割,這可以從我們的方法的高精度但低召回中看出。另一方面,與 Office 中存在的連接的語義相似區域相比,導致了欠分割和較低的召回率。
7. 限制性
盡管實驗結果令人鼓舞,但我們的方法存在多個限制。首先,盡管我們的方法是zero-shot,并且不受任何特定基礎模型的限制,但在實施過程中確實繼承了一些基礎模型的限制,比如對提示調整的強烈敏感。例如,我們討論了不同CLIP模型對性能的影響。其次,我們目前在合并兩個基元時平均了CLIP向量,但考慮更具體的方法來結合它們的語義描述可能會更有趣。第三,如果兩個基元分別對同一任務具有相似的余弦相似度,但任務某種方式上需要將它們區分為單獨的對象時,Clio可能會過度聚類(例如,我們可能希望在擺放餐具時將叉子與刀子區分開來,盡管它們可能對任務有相似的相關性)。最后,我們目前考慮的是相對簡單的單步任務。然而,將所提出的框架擴展到與一組高級復雜任務一起工作將是可取的。
8. 總結
我們提出了一種面向任務的三維度量語義映射的形式化方法,其中機器人被提供了一系列自然語言任務,并且必須創建一個足以支持這些任務的地圖,其粒度和結構是足夠的。我們已經表明,這個問題可以用經典的信息瓶頸來表達,并且已經開發了聚合信息瓶頸算法的增量版本作為解決策略。我們已將所得算法集成到實時系統Clio中,該系統在機器人探索環境時構建一個三維場景圖,包括任務相關的對象和區域。我們還通過展示它可以在Spot機器人上實時執行并支持拾取和放置移動操作任務,證明了Clio對機器人學的相關性。
-
傳感器
+關注
關注
2550文章
51041瀏覽量
753098 -
機器人
+關注
關注
211文章
28389瀏覽量
206924
原文標題:MIT最新開源!Clio:如何確定機器人語義地圖的細粒度?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《人形機器人產業地圖(2024)》重磅發布!

機器人沒有度量信息如何導航
Perforce Helix Core通過ISO 26262認證!為汽車軟件開發團隊提供無限可擴展性、細粒度安全性、文件快速訪問等

機器人語言系統包括三個基本狀態
圖像語義分割的實用性是什么
Al大模型機器人
微信大模型擴容并開源,推出首個中英雙語文生圖模型,參數規模達15億
一微半導體“基于地圖輪廓的區域分界線搜索方法”專利公布
華為云攜手樂聚機器人,探索人形機器人大模型開發
數倉中搭建細粒度容災應用的主要步驟
助力移動機器人下游任務!Mobile-Seed用于聯合語義分割和邊界檢測

ICLR 2024 清華/新國大/澳門大學提出一模通吃的多粒度圖文組合檢索MUG:通過不確定性建模,兩行代碼完成部署






 工商網監
工商網監
評論