 數據倉庫是什么_數據倉庫的特點_數據倉庫與數據庫區別
數據倉庫是什么_數據倉庫的特點_數據倉庫與數據庫區別
數據倉庫是什么
數據倉庫,英文名稱為DataWarehouse,可簡寫為DW或DWH。數據倉庫,是為企業所有級別的決策制定過程,提供所有類型數據支持的戰略集合。它是單個數據存儲,出于分析性報告和決策支持目的而創建。為需要業務智能的企業,提供指導業務流程改進、監視時間、成本、質量以及控制。
數據倉庫的特點
1.主題性
數據倉庫是一般從用戶實際需求出發,將不同平臺的數據源按設定主題進行劃分整合,與傳統的面向事務的操作型數據庫不同,具有較高的抽象性。面向主題的數據組織方式,就是在較高層次對分析對象數據的一個完整、統一并一致的描述,能完整及統一地刻畫各個分析對象所涉及的有關企業的各項數據,以及數據之間的聯系。
2.集成性
數據倉庫中存儲的數據大部分來源于傳統的數據庫,但并不是將原有數據簡單的直接導入,而是需要進行預處理。這是因為事務型數據中的數據一般都是有噪聲的、不完整的和數據形式不統一的。這些“臟數據”的直接導入將對在數據倉庫基礎上進行的數據挖掘造成混亂。“臟數據”在進入數據倉庫之前必須經過抽取、清洗、轉換才能生成從面向事務轉而面向主題的數據集合。數據集成是數據倉庫建設中最重要,也是最為復雜的一步。
3.穩定性
數據倉庫中的數據主要為決策者分析提供數據依據。決策依據的數據是不允許進行修改的。即數據保存到數據倉庫后,用戶僅能通過分析工具進行查詢和分析,而不能修改。數據的更新升級主要都在數據集成環節完成,過期的數據將在數據倉庫中直接篩除。
4.動態性
數據倉庫數據會隨時間變化而定期更新,不可更新是針對應用而言,即用戶分析處理時不更新數據。每隔一段固定的時間間隔后,抽取運行數據庫系統中產生的數據,轉換后集成到數據倉庫中。隨著時間的變化,數據以更高的綜合層次被不斷綜合,以適應趨勢分析的要求。當數據超過數據倉庫的存儲期限,或對分析無用時,從數據倉庫中刪除這些數據。關于數據倉庫的結構和維護信息保存在數據倉庫的元數據(Metadata)中,數據倉庫維護工作由系統根據其中的定義自動進行或由系統管理員定期維護。
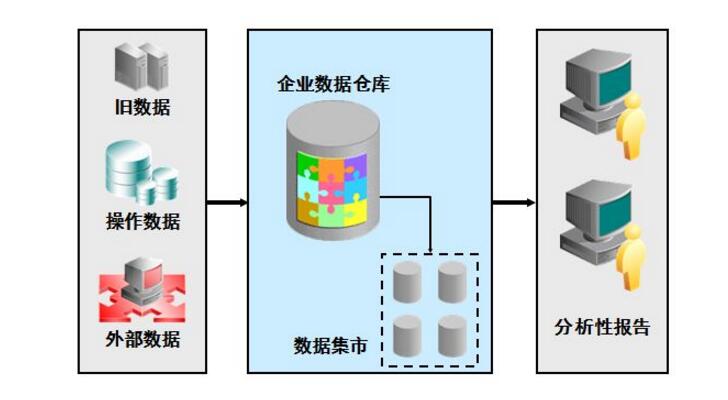
數據倉庫的基本架構
數據倉庫的目的是構建面向分析的集成化數據環境,為企業提供決策支持(DecisionSupport)。其實數據倉庫本身并不“生產”任何數據,同時自身也不需要“消費”任何的數據,數據來源于外部,并且開放給外部應用,這也是為什么叫“倉庫”,而不叫“工廠”的原因。因此數據倉庫的基本架構主要包含的是數據流入流出的過程,可以分為三層——源數據、數據倉庫、數據應用:
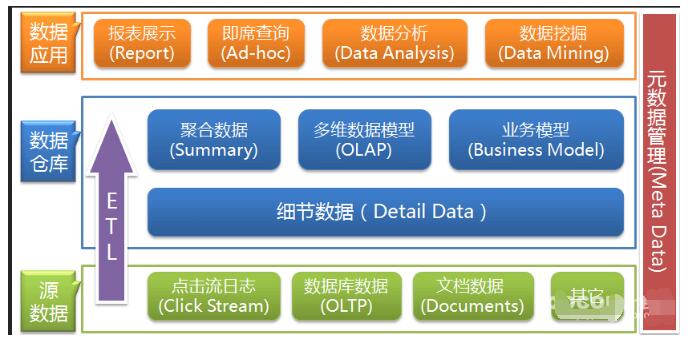
從圖中可以看出數據倉庫的數據來源于不同的源數據,并提供多樣的數據應用,數據自上而下流入數據倉庫后向上層開放應用,而數據倉庫只是中間集成化數據管理的一個平臺。
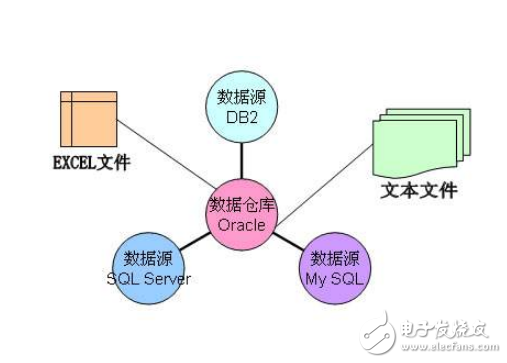
數據倉庫的數據來源
數據倉庫從各數據源獲取數據及在數據倉庫內的數據轉換和流動都可以認為是ETL(抽取Extra,轉化Transfer,裝載Load)的過程,ETL是數據倉庫的流水線,也可以認為是數據倉庫的血液,它維系著數據倉庫中數據的新陳代謝,而數據倉庫日常的管理和維護工作的大部分精力就是保持ETL的正常和穩定。
數據倉庫的數據存儲
數據倉庫并不需要儲存所有的原始數據,同時數據倉庫需要儲存部分細節數據。簡單地解釋下:
a.為什么不需要所有原始數據?數據倉庫面向分析處理,但是某些源數據對于分析而言沒有價值或者其可能產生的價值遠低于儲存這些數據所需要的數據倉庫的實現和性能上的成本。比如我們知道用戶的省份、城市足夠,至于用戶究竟住哪里可能只是物流商關心的事,或者用戶在博客的評論內容可能只是文本挖掘會有需要,但將這些冗長的評論文本存在數據倉庫就得不償失;
b.為什么要存細節數據?細節數據是必需的,數據倉庫的分析需求會時刻變化,而有了細節數據就可以做到以不變應萬變。如果我們只存儲根據某些需求搭建起來的數據模型,那么顯然對于頻繁變動的需求會手足無措;
數據倉庫基于維護細節數據的基礎上在對數據進行處理,使其真正地能夠應用于分析。主要包括三個方面:
1.數據的聚合
這里的聚合數據指的是基于特定需求的簡單聚合(基于多維數據的聚合體現在多維數據模型中),簡單聚合可以是網站的總Pageviews、Visits、UniqueVisitors等匯總數據,也可以是Avg.timeonpage、Avg.timeonsite等平均數據,這些數據可以直接地展示于報表上。
2.多維數據模型
多維數據模型提供了多角度多層次的分析應用,比如基于時間維、地域維等構建的銷售星形模型、雪花模型,可以實現在各時間維度和地域維度的交叉查詢,以及基于時間維和地域維的細分。所以數據倉庫面向特定群體的數據集市都是基于多維數據模型進行構建的。
3.業務模型
這里的業務模型指的是基于某些數據分析和決策支持而建立起來的數據模型,比如我之前介紹過的用戶評價模型、關聯推薦模型、RFM分析模型等,或者是決策支持的線性規劃模型、庫存模型等;同時,數據挖掘中前期數據的處理也可以在這里完成。
數據倉庫的數據應用
報表展示
報表幾乎是每個數據倉庫的必不可少的一類數據應用,將聚合數據和多維分析數據展示到報表,提供了最為簡單和直觀的數據。
即時查詢
理論上數據倉庫的所有數據(包括細節數據、聚合數據、多維數據和分析數據)都應該開放即時查詢,即時查詢提供了足夠靈活的數據獲取方式,用戶可以根據自己的需要查詢獲取數據。
數據分析
數據分析大部分基于構建的業務模型展開,當然也可以使用聚合的數據進行趨勢分析、比較分析、相關分析等,而多維數據模型提供了多維分析的數據基礎;同時從細節數據中獲取一些樣本數據進行特定的分析也是較為常見的一種途徑。
數據挖掘
數據挖掘用一些高級的算法可以讓數據展現出各種令人驚訝的結果。數據挖掘可以基于數據倉庫中已經構建起來的業務模型展開,但大多數時候數據挖掘會直接從細節數據上入手,而數據倉庫為挖掘工具諸如SAS、SPSS等提供數據接口。
元數據
數據倉庫環境中一個重要方面是元數據。元數據是關于數據的數據。只要有程序和數據,元數據就是信息處理環境的一部分。但是在數據倉庫中,元數據扮演一個新的重要角色。也正因為有了元數據,可以最有效地利用數據倉庫。元數據使得最終用戶/DSS分析員能夠探索各種可能性。
元數據在數據倉庫的上層,并且記錄數據倉庫中對象的位置。典型地,元數據記錄:
程序員所知的數據結構。
DSS分析員所知的數據結構。
數據倉庫的源數據。
數據加入數據倉庫時的轉換。
數據模型。
數據模型和數據倉庫的關系。
抽取數據的歷史記錄。
數據倉庫用途
信息技術與數據智能大環境下,數據倉庫在軟硬件領域、Internet和企業內部網解決方案以及數據庫方面提供了許多經濟高效的計算資源,可以保存極大量的數據供分析使用,且允許使用多種數據訪問技術。
開放系統技術使得分析大量數據的成本趨于合理,并且硬件解決方案也更為成熟。在數據倉庫應用中主要使用的技術如下:
并行
計算的硬件環境、操作系統環境、數據庫管理系統和所有相關的數據庫操作、查詢工具和技術、應用程序等各個領域都可以從并行的最新成就中獲益。
分區
分區功能使得支持大型表和索引更容易,同時也提高了數據管理和查詢性能。
數據壓縮
數據壓縮功能降低了數據倉庫環境中通常需要的用于存儲大量數據的磁盤系統的成本,新的數據壓縮技術也已經消除了壓縮數據對查詢性能造成的負面影響。
數據倉庫的五大好處
1、提供加強的商業智能(BI)
利用從各種數據源提供的數據,管理人員和高管們將不再需要憑著有限的數據或他們的直覺做出商業決策。此外,“數據倉庫及相關商業智能(BI)可直接用于包括市場細分、庫存管理、財務管理、銷售這樣的業務流程中。”
2、可節省時間
因為業務用戶可以在一個地方快速訪問許多數據源,他們就在關鍵方案上迅速做出知情的決策,而不會用浪費寶貴的時間從多種數據源中檢索數據。
不僅如此,業務主管們可以在很少或者根本沒有IT的支持下自己查詢數據—節約了更多的時間和資金。這意味著商業用戶不需要等待IT的出現就能生成報表,而那些在IT努力工作的人員可以做他們最好該做事情—維持業務的運行。
3、能提高數據的質量和一致性
一個數據倉庫的實施包括將數據從眾多的數據源系統中轉換成共同的格式。由于每個來自各個部門的數據被標準化了,每個部門將會產生與所有其它部門符合的結果。所以你可以對你數據的準確性更有信心。而準確的數據是強大的商業決策的基礎。
4、能提供歷史的智慧
一個數據倉庫儲存了大量的歷史數據,所以你可以通過分析不同的時期和趨勢來做出對未來的預測。這些數據通常不能被存儲在一個交易型的數據庫里或用來從一個交易系統中生成報表。
5、能創建高的投資回報率
最后,最值得一提的是投資回報率。已經安裝了數據倉庫和完善了商業智能(BI)系統的企業比沒有在商業智能(BI)系統和數據倉庫投資的企業能產生更多的利潤和節約更多的資金。而這應該成為高級管理層快速加入到數據倉庫這個潮流中的足夠理由。
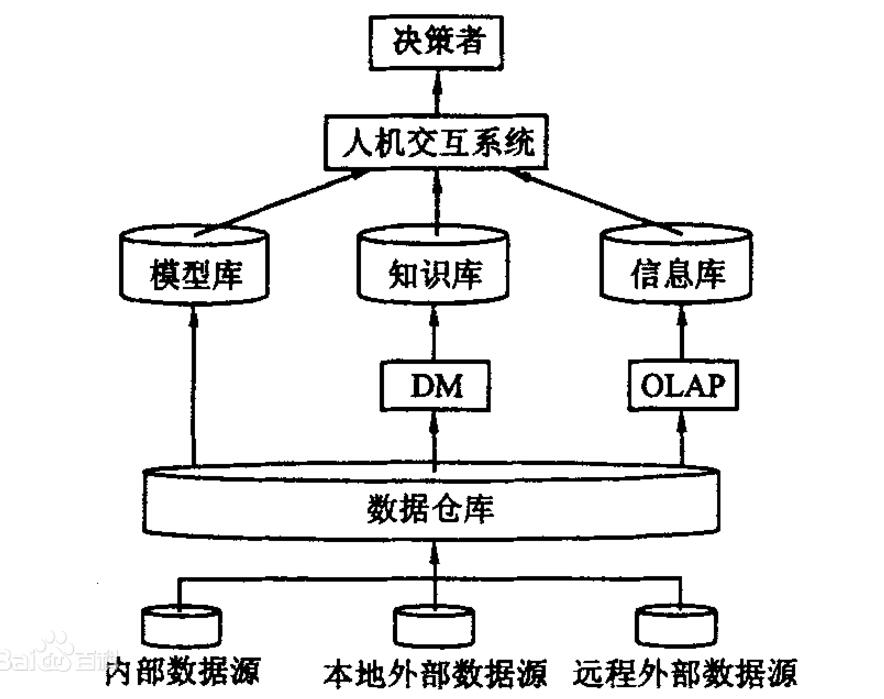
數據庫與數據倉庫的區別
簡而言之,數據庫是面向事務的設計,數據倉庫是面向主題設計的。
數據庫一般存儲在線交易數據,數據倉庫存儲的一般是歷史數據。
數據庫設計是盡量避免冗余,一般采用符合范式的規則來設計,數據倉庫在設計是有意引入冗余,采用反范式的方式來設計。
數據庫是為捕獲數據而設計,數據倉庫是為分析數據而設計,它的兩個基本的元素是維表和事實表。維是看問題的角度,比如時間,部門,維表放的就是這些東西的定義,事實表里放著要查詢的數據,同時有維的ID。
單從概念上講,有些晦澀。任何技術都是為應用服務的,結合應用可以很容易地理解。以銀行業務為例。數據庫是事務系統的數據平臺,客戶在銀行做的每筆交易都會寫入數據庫,被記錄下來,這里,可以簡單地理解為用數據庫記帳。數據倉庫是分析系統的數據平臺,它從事務系統獲取數據,并做匯總、加工,為決策者提供決策的依據。比如,某銀行某分行一個月發生多少交易,該分行當前存款余額是多少。如果存款又多,消費交易又多,那么該地區就有必要設立ATM了。
顯然,銀行的交易量是巨大的,通常以百萬甚至千萬次來計算。事務系統是實時的,這就要求時效性,客戶存一筆錢需要幾十秒是無法忍受的,這就要求數據庫只能存儲很短一段時間的數據。而分析系統是事后的,它要提供關注時間段內所有的有效數據。這些數據是海量的,匯總計算起來也要慢一些,但是,只要能夠提供有效的分析數據就達到目的了。
數據倉庫,是在數據庫已經大量存在的情況下,為了進一步挖掘數據資源、為了決策需要而產生的,它決不是所謂的“大型數據庫”。那么,數據倉庫與傳統數據庫比較,有哪些不同呢?讓我們先看看W.H.Inmon關于數據倉庫的定義:面向主題的、集成的、與時間相關且不可修改的數據集合。
“面向主題的”:傳統數據庫主要是為應用程序進行數據處理,未必按照同一主題存儲數據;數據倉庫側重于數據分析工作,是按照主題存儲的。這一點,類似于傳統農貿市場與超市的區別—市場里面,白菜、蘿卜、香菜會在一個攤位上,如果它們是一個小販賣的;而超市里,白菜、蘿卜、香菜則各自一塊。也就是說,市場里的菜(數據)是按照小販(應用程序)歸堆(存儲)的,超市里面則是按照菜的類型(同主題)歸堆的。
“與時間相關”:數據庫保存信息的時候,并不強調一定有時間信息。數據倉庫則不同,出于決策的需要,數據倉庫中的數據都要標明時間屬性。決策中,時間屬性很重要。同樣都是累計購買過九車產品的顧客,一位是最近三個月購買九車,一位是最近一年從未買過,這對于決策者意義是不同的。
“不可修改”:數據倉庫中的數據并不是最新的,而是來源于其它數據源。數據倉庫反映的是歷史信息,并不是很多數據庫處理的那種日常事務數據(有的數據庫例如電信計費數據庫甚至處理實時信息)。因此,數據倉庫中的數據是極少或根本不修改的;當然,向數據倉庫添加數據是允許的。
數據倉庫的出現,并不是要取代數據庫。目前,大部分數據倉庫還是用關系數據庫管理系統來管理的。可以說,數據庫、數據倉庫相輔相成、各有千秋。
所以主要區別在于:
(1)數據庫是面向事務的設計,數據倉庫是面向主題設計的。
(2)數據庫一般存儲在線交易數據,數據倉庫存儲的一般是歷史數據。
(3)數據庫設計是盡量避免冗余,數據倉庫在設計是有意引入冗余。
(4)數據庫是為捕獲數據而設計,數據倉庫是為分析數據而設計。
-
數據庫
+關注
關注
7文章
3794瀏覽量
64362
發布評論請先 登錄
相關推薦
數據倉庫的基本架構及架構圖介紹
什么是數據倉庫?數據倉庫的優勢分析
多版本數據倉庫模型設計
統計行業數據倉庫構建及應用
OLAP在電信數據倉庫中的設計
數據庫與數據倉庫的區別
保護MySQL數據倉庫的最佳實踐
數據倉庫是什么_數據倉庫有什么特點_數據庫和數據倉庫區別分析
如何建設企業級數據倉庫_多維數據庫模型的設計你知道多少





 工商網監
工商網監
評論