 eda分析中的數據清洗步驟
eda分析中的數據清洗步驟
在數據分析的早期階段,探索性數據分析(EDA)是一種重要的方法,它幫助我們理解數據集的特征和結構。然而,原始數據往往包含錯誤、缺失值、異常值和不一致性,這些都可能影響分析結果。因此,在進行EDA之前,進行徹底的數據清洗是必不可少的。
1. 數據預處理
數據預處理是數據清洗的第一步,它包括數據導入、數據類型轉換和數據結構調整。
- 數據導入 :將數據從各種來源(如CSV、Excel、數據庫等)導入到分析工具中。
- 數據類型轉換 :確保數據集中的每個變量都有正確的數據類型。例如,將日期字符串轉換為日期類型,將數字字符串轉換為數值類型。
- 數據結構調整 :根據分析需求調整數據結構,如將寬格式數據轉換為長格式數據,或者合并多個數據表。
2. 數據轉換
數據轉換是將數據轉換成適合分析的形式,包括規范化、標準化、編碼類別變量和特征工程。
- 規范化 :將數據縮放到一個特定的范圍,如0到1之間,以消除不同量綱的影響。
- 標準化 :將數據轉換為均值為0,標準差為1的分布,以消除不同量綱的影響。
- 編碼類別變量 :將類別變量轉換為數值變量,如使用獨熱編碼(One-Hot Encoding)或標簽編碼(Label Encoding)。
- 特征工程 :創建新的特征或修改現有特征以提高模型的性能,如從日期中提取年、月、日等。
3. 異常值檢測和處理
異常值是那些與數據集中的其余值顯著不同的值,它們可能是由于錯誤或自然變異造成的。
- 異常值檢測 :使用統計方法(如IQR方法、Z分數、箱線圖等)來識別異常值。
- 異常值處理 :根據異常值的性質和分析目標,選擇適當的處理方法,如刪除、替換或保留。
4. 缺失值處理
缺失值是數據分析中的常見問題,它們會影響模型的性能和結果的準確性。
- 缺失值識別 :識別數據集中的缺失值,包括完全缺失和部分缺失。
- 缺失值處理 :根據數據的重要性和缺失的模式,選擇適當的處理方法,如刪除、填充(如均值、中位數、眾數填充)或使用模型預測缺失值。
5. 數據一致性檢查
數據一致性檢查是確保數據集中的值符合預期的格式和邏輯。
- 格式一致性 :檢查數據是否符合預定的格式,如電話號碼、電子郵件地址等。
- 邏輯一致性 :檢查數據是否符合邏輯規則,如年齡不能為負數,日期不能在未來等。
- 數據完整性 :檢查數據是否完整,如關鍵字段是否缺失,記錄是否重復等。
6. 數據質量評估
在數據清洗后,進行數據質量評估是必要的,以確保數據清洗的效果。
- 統計摘要 :生成數據的描述性統計,如均值、中位數、最大值和最小值等。
- 可視化檢查 :使用圖表(如直方圖、箱線圖、散點圖等)來直觀地檢查數據的分布和關系。
- 一致性測試 :進行邏輯測試和驗證,以確保數據的一致性和完整性。
7. 數據清洗的自動化
隨著數據量的增加,手動進行數據清洗變得越來越不切實際。因此,自動化數據清洗變得越來越重要。
- 編寫腳本 :使用編程語言(如Python、R等)編寫數據清洗腳本,以自動化數據預處理、轉換和清洗過程。
- 使用數據清洗工具 :利用現有的數據清洗工具和庫(如Pandas、OpenRefine等)來簡化數據清洗工作。
- 持續監控 :建立數據監控系統,以持續跟蹤數據質量,并在數據進入分析流程之前進行清洗。
結論
數據清洗是探索性數據分析中的關鍵步驟,它直接影響到分析結果的準確性和可靠性。通過遵循上述步驟,我們可以有效地清洗數據,為后續的分析打下堅實的基礎。隨著技術的發展,自動化和智能化的數據清洗工具將進一步提高數據清洗的效率和效果。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據
+關注
關注
8文章
7010瀏覽量
88976 -
eda
+關注
關注
71文章
2757瀏覽量
173226 -
自動化
+關注
關注
29文章
5565瀏覽量
79255
發布評論請先 登錄
相關推薦
數據可視化與數據分析的關系
的含義。 數據分析的定義與作用 數據分析是一種使用統計和邏輯方法來分析數據集的過程,目的是發現模式、趨勢和關聯性。它包括數據
eda與傳統數據分析的區別
進行初步的探索和理解,發現數據中潛在的模式、關系、異常值等,為后續的分析和建模提供線索和基礎。 方法論 :EDA強調數據的真實分布和可視化,
數據分析有哪些分析方法
數據分析是一種重要的技能,它可以幫助我們從大量的數據中提取有價值的信息,從而做出更明智的決策。在這篇文章中,我們將介紹數據分析的各種方法,包括描述性
硅晶片清洗:半導體制造過程中的一個基本和關鍵步驟
和電子設備中存在的集成電路的工藝。在半導體器件制造中,各種處理步驟分為四大類,例如沉積、去除、圖案化和電特性的改變。 最后,通過在半導體材料中摻雜雜質來改變電特性。晶片清洗過程的目的是
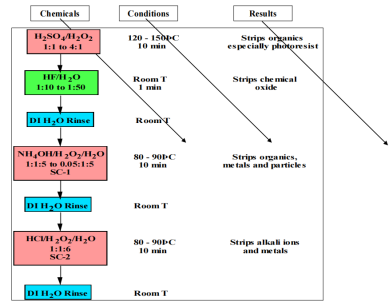
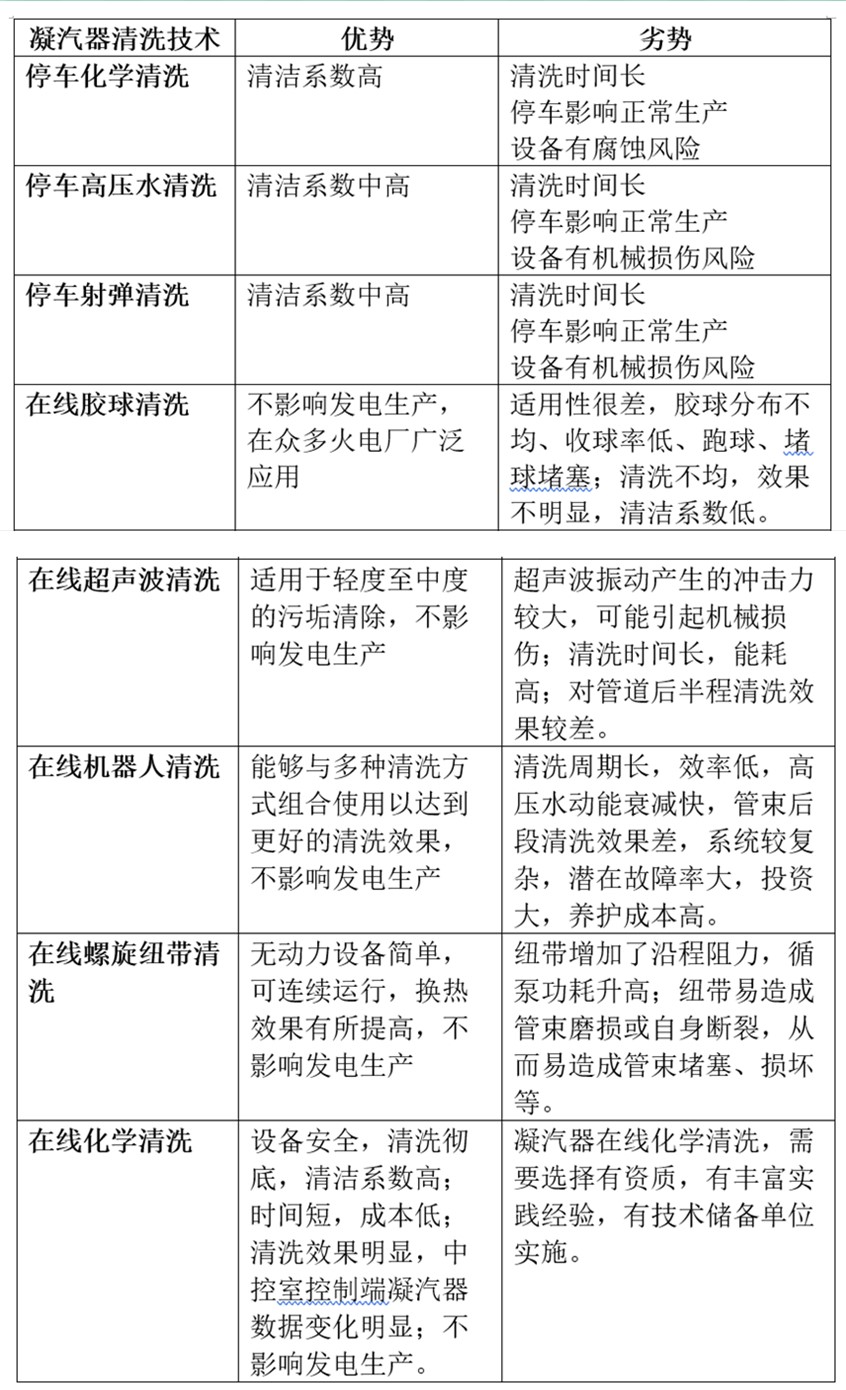
火電廠凝汽器不停車在線清洗與凝汽器停車清洗八種技術對比分析
通過凝汽器結垢對發電機組運行安全性和經濟性的影響分析,以及對火電行業現有凝汽器清洗技術的優劣對比介紹,并通過火電廠凝汽器在線化學清洗技術案例,對清洗前后凝汽器運行性能
超聲波清洗機的4大清洗特點與清洗原理
效率和更好的清洗效果。
2. 環保性:超聲波清洗機在清洗過程中無需使用化學清洗劑,只需使用清水或少量專用清洗劑即可。這大大降低了

eda工具軟件有哪些 EDA工具有什么優勢
EDA (Exploratory Data Analysis)是指通過可視化和統計方法來探索和分析數據的過程。它是數據分析的重要步驟,能夠幫
超聲波清洗機原理及作用 超聲波清洗機使用步驟
發生器、換能器、清洗槽、控制系統和電源等組成。 超聲波發生器產生高頻電信號,然后通過連接線傳遞到換能器上。換能器將電信號轉換成機械振動,產生超聲波,然后通過耦合裝置輸入到清洗槽內的清洗液中
eda是什么軟件如何用
科學領域被廣泛應用,既可以用于初步數據探索,也可用于驗證假設和發現潛在的模式。無論是對于小型數據集還是大型數據集,EDA都是數據科學家們進行





 工商網監
工商網監
評論