 基于Arm Neoverse N2實現自動語音識別技術
基于Arm Neoverse N2實現自動語音識別技術
作者:安謀科技 (Arm China) 高級軟件產品經理 楊喜樂
自動語音識別 (Automatic Speech Recognition) 技術已經深入到現代生活的方方面面,廣泛應用于從語音助手、轉錄服務,到呼叫中心分析和語音轉文本翻譯等方面,為各行各業提供了創新解決方案,顯著提升了用戶體驗。
隨著機器學習 (ML) 和深度學習的最新進展,自動語音識別技術的精密性已經達到一個新的高度。現在,自動語音識別軟件可以非常準確地理解各種口音、方言和說話風格。FunASR 是阿里巴巴達摩院開發的一款先進的開源自動語音識別工具包。它為開發和部署自動語音識別系統提供了一套全面的工具和模型。
FunASR 兼容 CPU 和 GPU 計算。雖然 GPU 為訓練深度學習模型提供了出色的性能,但 CPU 在邊緣側和數據中心服務器中更為普遍,并且更適合模型推理。因此,FunASR 可以在 CPU 上進行高效的自動語音識別推理,并能在 GPU 加速不可用的情況下(如成本限制、功耗限制或缺乏可用性等),依然能夠順利部署。
Arm Neoverse N2 是一款專為云和邊緣計算設計的高性能 CPU 處理器。它可以支持包括人工智能 (AI) 和 ML 在內的多種云工作負載,并增加了 SVE2、Bfloat16 (BF16) 數據格式和 MMLA 等 AI 功能。
SVE2 使開發者能夠操作更大的數據向量,提升并行處理能力和執行效率,這對于 AI 模型訓練和推理階段涉及的大量數學計算尤為重要。
BF16 是一種較新的浮點格式,專為 AI 和 ML 應用而設計。它提供與 32 位浮點數相同的動態范圍,但僅占用 16 位存儲空間,有效縮小了模型尺寸,并顯著提升了計算效率。
MMLA 是 Armv8.6 中的一個架構特性。它為 GEMM 運算提供了顯著加速。GEMM 是 ML 中的一種基本算法,對兩個輸入矩陣進行復雜的乘法運算,得到一個輸出。
Arm 此前推出了 Arm Kleidi 技術,這是一套專為開發者設計的賦能技術,旨在增強 Arm Neoverse、Arm Cortex 等 Arm 平臺上的 AI 性能。Kleidi 技術廣泛涉及從框架到高度優化的算子庫,再到充滿活力的獨立軟件供應商 (ISV) 生態系統,全面覆蓋了 AI 開發的關鍵環節。
在本文中,我們將分享在基于 Neoverse N2 的阿里巴巴倚天 710 平臺上部署 FunASR 推理過程及基準測試方法。同時,我們將通過啟用 Arm Kleidi 技術進行對比分析,重點介紹與其他基于 CPU 和 GPU 的平臺相比,在倚天 710 CPU 上運行 FunASR 推理在性價比方面的主要優勢。
基準測試設置
軟件版本:
Ubuntu 22.04(64 位)
PyTorch v2.3.0
pip install funasr==0.8.8
pip install modelscope==1.10.0
模型:speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
請確保系統上安裝了 PyTorch 和相關的 python 庫[1],如果在 Arm 平臺上運行,可使用 Arm 在 docker 倉庫中提供的 PyTorch docker 鏡像[2],以便進行快速評估。
1對環境進行初始化并導入所需的依賴項
export OMP_NUM_THREADS=16
export DNNL_VERBOSE=1
import torch
import torch.autograd.profiler as profiler
import os
import random
import numpy as np
from funasr.tasks.asr import ASRTaskParaformer as ASRTask
from funasr.export.models import get_model
from modelscope.hub.snapshot_download import snapshot_download
<< 滑動查看 >>
2下載并配置模型
Paraformer 是阿里巴巴達摩院在 FunASR 開源項目中開發的一款高效自動語音識別模型,旨在提高端到端語音識別系統的魯棒性和效率。該模型基于 Transformer 架構,并融入了多項創新,以提升其在語音識別中的性能。為了進行基準測試,我們將使用魔搭社區中的 FunASR paraformer 模型[3]。
model_dir = snapshot_download('damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', cache_dir='./',revision=None)
#set the radom seed 0
random.seed(0)
np.random.seed(0)
torch.random.manual_seed(0)
model, asr_train_args = ASRTask.build_model_from_file(
'damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/config.yaml','damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pb' ,'damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/am.mvn' , 'cpu')
model = get_model(model, dict(feats_dim=560, onnx=False, model_name="model"))
<< 滑動查看 >>
3使用性能分析器運行以獲取模型推理結果
推理運行十次迭代以獲得平均結果。
batch = 64
seq_len = 93
dim = 560
speech = torch.randn((batch, seq_len, dim))
speech_lengths = torch.tensor([seq_len for _ in range(batch)], dtype=torch.int32)
with torch.no_grad():
with profiler.profile(with_stack=True, profile_memory=False, record_shapes=True) as prof:
for _ in range(10):
model(speech, speech_lengths)
print(prof.key_averages(group_by_input_shape=True).table(sort_by='self_cpu_time_total', row_limit=200))
<< 滑動查看 >>
使用 BF16 Fast Math 內核加速推理
作為 Arm Kleidi 技術的一部分,Arm Compute Library (ACL) 通過利用 BF16 MMLA 指令,提供了優化的 BF16 通用矩陣乘法 (GEMM) 內核。這些指令在 Neoverse N2 CPU 中得到支持,并且從 PyTorch 2.0 版本開始便通過 oneDNN 后端集成到了 PyTorch 中。ACL 中的 Fast Math GEMM 內核可以高度優化 CPU 上的推理性能。
要啟用 Fast Math GEMM 內核,請在運行推理之前設置以下環境變量:
$ export DNNL_DEFAULT_FPMATH_MODE=BF16
我們發現,在基于 Neoverse N2 的倚天 710 平臺上啟用 BF16 Fast Math 內核后,與默認的 FP32 內核相比,性能提高了約 2.3 倍。
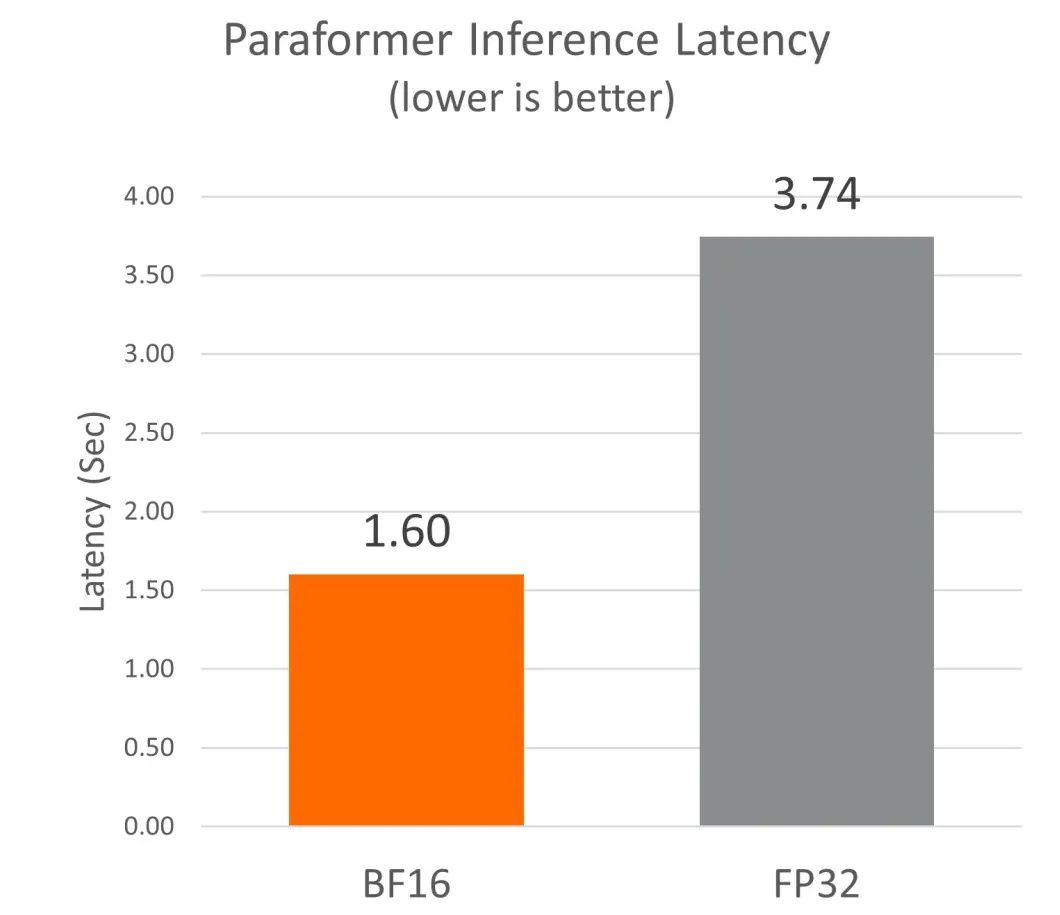
性能比較
我們還比較了 FunASR paraformer 模型在倚天 710 和阿里云其他同等級別云實例上的性能*。
Arm Neoverse N2(倚天 710):
ecs.c8y.4xlarge (16 vCPU + 32GB)
第 4 代英特爾至強“Sapphire Rapids”:
ecs.c8i.4xlarge (16 vCPU + 32GB)
第 4 代 AMD EPYC“Genoa”:
ecs.c8a.4xlarge (16 vCPU + 32GB)
*使用 armswdev/pytorch-arm-neoverse:r24.07-torch-2.3.0-onednn-acl docker 鏡像的倚天 710[2],適用于英特爾 Sapphire-Rapids 和 AMD Genoa 的官方 PyTorch v2.3.0
我們發現,基于 Neoverse N2 的倚天 710,搭配 BF16 Fast Math 內核,使得 paraformer 自動語音識別模型的推理性能較同等級別的 x86 云實例有高達 2.4 倍的優勢。
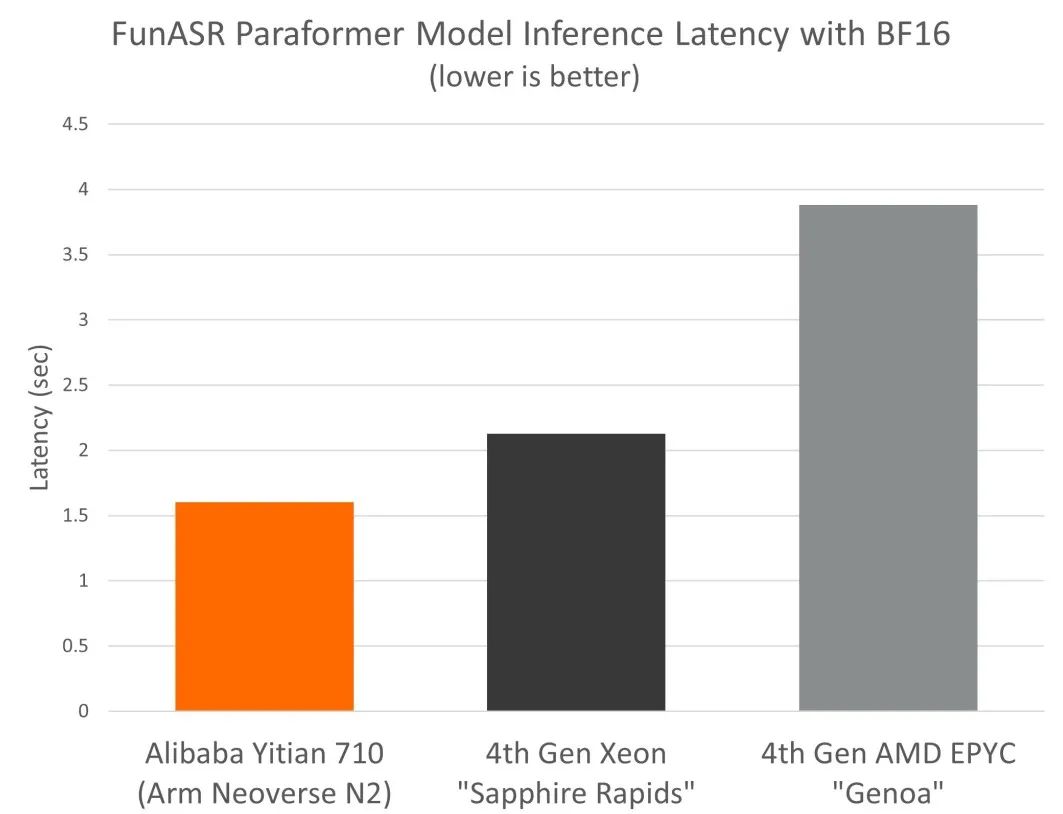
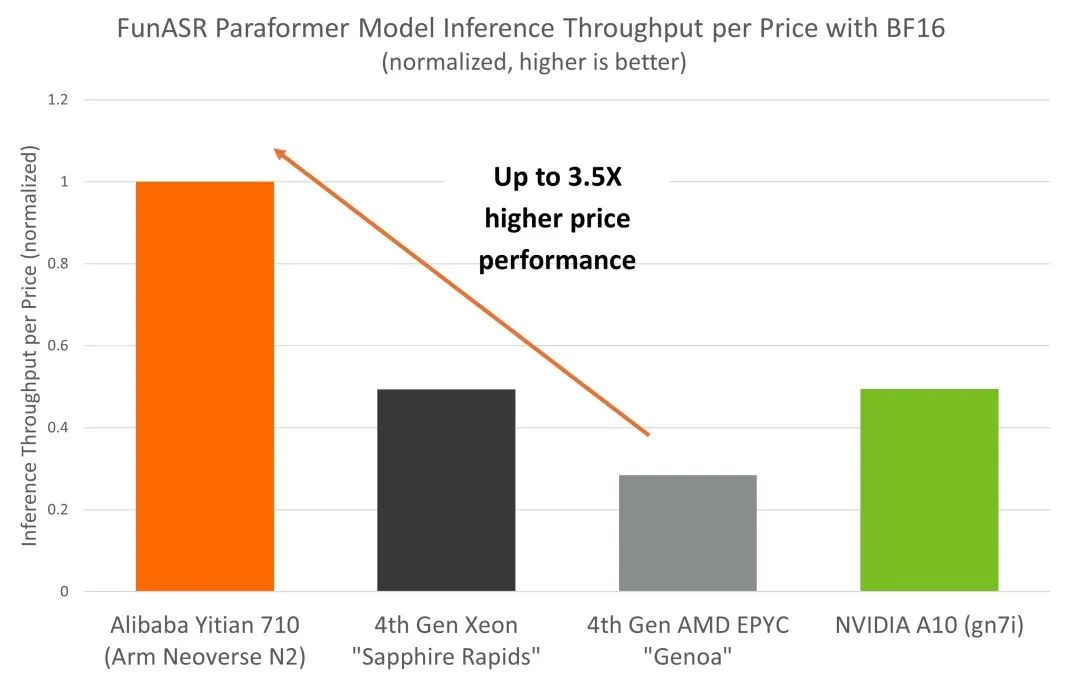
在實際推理部署中,成本是 AI 部署的主要考慮因素之一,對技術的實現和采用有很大的影響。為全面了解 CPU 和 GPU 平臺上自動語音識別推理部署的總體擁有成本 (TCO),我們將 NVIDIA A10 GPU 也納入對比分析中。得益于 Neoverse N2 出色的性能和能效,倚天 710 平臺相較于同等級別 x86 實例和 GPU 平臺,展現出更高的成本效益,這一點也體現在了阿里云倚天 710 實例更普惠的定價上。

從基準測試結果來看,倚天 710 在自動語音識別推理部署的 TCO 方面具有顯著優勢,其性價比較同等級別 x86 和 GPU 平臺高出 3.5 倍。
結論
基于 Arm Neoverse N2 的阿里巴巴倚天 710 具有 BF16 MMLA 擴展等特定 ML 功能,為采用 Arm Kleidi 技術的 FunASR paraformer 模型提供了出色的推理性能。開發者在倚天 710 上構建自動語音識別應用可實現更高性價比。
-
處理器
+關注
關注
68文章
19259瀏覽量
229651 -
ARM
+關注
關注
134文章
9084瀏覽量
367381 -
cpu
+關注
關注
68文章
10854瀏覽量
211574 -
語音識別
+關注
關注
38文章
1739瀏覽量
112633 -
機器學習
+關注
關注
66文章
8406瀏覽量
132558
原文標題:Arm Neoverse N2 平臺上利用 Arm Kleidi 技術實現自動語音識別卓越性價比
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Arm Neoverse家族新增V1和N2兩大平臺,突破高性能計算瓶頸
Arm Neoverse N2汽車硬件技術概述
ARM Neoverse?N2軟件優化指南
Arm Neoverse N1軟件優化指南
Arm Neoverse? N2核心加密擴展技術參考手冊
ARM Neoverse?N1核心技術參考手冊
ARM Neoverse?N2核心技術參考手冊
ARM Neoverse?N2參考設計技術概述
互聯網巨頭紛紛啟用Arm CPU架構,Arm最新Neoverse V1和N2平臺加速云服務器芯片自研
Arm推出新一代平臺 Neoverse V2 平臺
Arm 更新 Neoverse 產品路線圖,實現基于 Arm 平臺的人工智能基礎設施
Arm發布新一代Neoverse數據中心計算平臺,AI負載性能顯著提升
Arm新Arm Neoverse計算子系統(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3






 工商網監
工商網監
評論