") 如何構(gòu)建一個(gè)演示移動(dòng)端應(yīng)用
如何構(gòu)建一個(gè)演示移動(dòng)端應(yīng)用
作者:Arm 戰(zhàn)略與生態(tài)部工程師 Ayaan Masood
作為通訊工具,視頻會(huì)議幾乎隨處可見(jiàn),尤其適用于遠(yuǎn)程辦公和社交互動(dòng)。但其使用體驗(yàn)并非總是簡(jiǎn)單直接、即開(kāi)即用,可能需要進(jìn)行調(diào)整,確保音頻視頻設(shè)置良好。其中,照明便是一個(gè)難以把握的因素。在會(huì)議中,光線充足的視頻畫面會(huì)顯得得體大方,而糟糕的照明條件則會(huì)顯得不夠?qū)I(yè),還會(huì)分散其他與會(huì)者的注意力。有時(shí),改變光照情況并不可行,特別是在光線昏暗的冬季或照明不足的地點(diǎn)。
在本文中,我們將探討如何構(gòu)建一個(gè)演示移動(dòng)端應(yīng)用,以解決弱光條件下的視頻照明問(wèn)題。我們將介紹支持該應(yīng)用的神經(jīng)網(wǎng)絡(luò)模型及其機(jī)器學(xué)習(xí) (ML) 管線、性能優(yōu)化等。
找到合適的神經(jīng)網(wǎng)絡(luò)
我們采用基于神經(jīng)網(wǎng)絡(luò)的解決方案改善視頻照明。因此,這項(xiàng)工作的核心在于找到適合當(dāng)前任務(wù)的神經(jīng)網(wǎng)絡(luò)。目前,市面上有很多出色的開(kāi)源模型可供使用,而為本項(xiàng)目找到合適的候選模型至關(guān)重要。我們?cè)谠u(píng)估模型時(shí)主要關(guān)注以下三項(xiàng)要求:性能良好、照明質(zhì)量出色、視頻處理表現(xiàn)優(yōu)異。
我們的目標(biāo)是實(shí)現(xiàn)移動(dòng)端實(shí)時(shí)推理,這意味著,每幀處理時(shí)間只有嚴(yán)格控制在 33 毫秒內(nèi),才能實(shí)現(xiàn)每秒 30 幀的流暢播放。其中包括預(yù)處理/后處理步驟以及神經(jīng)網(wǎng)絡(luò)運(yùn)行所需的時(shí)間。視頻畫質(zhì)增強(qiáng)是另一項(xiàng)重要標(biāo)準(zhǔn)。該模型可智能化增強(qiáng)暗像、還原細(xì)節(jié),確保視頻幀之間暫時(shí)保持連貫,避免畫面閃爍。
模型架構(gòu)
所選模型來(lái)自 2021 年研究論文《用于弱光圖像/視頻增強(qiáng)的語(yǔ)義引導(dǎo)零樣本學(xué)習(xí)》[1]。在包含混合曝光和照明條件的復(fù)雜數(shù)據(jù)集上進(jìn)行測(cè)試時(shí),該模型的弱光增強(qiáng)質(zhì)量非常出色。暗像中不清晰的細(xì)節(jié)和結(jié)構(gòu)突然變得清晰起來(lái)。該模型的另一個(gè)優(yōu)點(diǎn)是尺寸極小,僅有一萬(wàn)個(gè)網(wǎng)絡(luò)參數(shù),因此推理速度很快。在模型架構(gòu)方面,輸入的圖像張量被縮小并傳遞到卷積層棧。這些層會(huì)預(yù)測(cè)逐像素增強(qiáng)因子,然后在模型后處理模塊中,將增強(qiáng)因子以乘法方式應(yīng)用到原始圖像像素上,從而生成增強(qiáng)的圖像。
值得一提的是,訓(xùn)練采用包含兩千張合成圖像的小型數(shù)據(jù)集,這就表明,如果數(shù)據(jù)集規(guī)模更大,模型就還有更大提升空間。我們?cè)鰪?qiáng)了真實(shí)參照?qǐng)D像,生成一系列統(tǒng)一曝光值,從而調(diào)整圖像明暗。該模型的訓(xùn)練不受監(jiān)督,無(wú)需標(biāo)簽,而是通過(guò)一個(gè)指導(dǎo)訓(xùn)練的損失函數(shù)來(lái)學(xué)習(xí)如何增強(qiáng)弱光圖像。這個(gè)損失函數(shù)是多個(gè)獨(dú)立損失的組合,它們分別負(fù)責(zé)圖像的各個(gè)方面,如顏色、亮度和語(yǔ)義信息。
ML 管線
該應(yīng)用的 ML 管線從輸入幀開(kāi)始,根據(jù)模型輸入張量要求加以處理,然后推理并向用戶顯示輸出。攔截相機(jī)幀進(jìn)行推理是 CameraX 庫(kù)的內(nèi)置功能,通過(guò)安卓的“圖像分析”API 實(shí)現(xiàn)。
我們采用了兩種不同的 ML 推理引擎:ONNX runtime和 TensorFlow Lite。將 Pytorch 模型導(dǎo)出為 ONNX 模型是 Pytorch 庫(kù)自帶的功能,而導(dǎo)出到 TensorFlow Lite 則困難得多。該模型的有效導(dǎo)出器為 Nobuco,其工作機(jī)制是先創(chuàng)建可轉(zhuǎn)換為 TFLite 的 Keras 模型。
模型推理產(chǎn)生的輸出格式取決于 ML 運(yùn)行時(shí)。如果采用 ONNX,則為 NCHW(即數(shù)量、通道、高度、寬度);如果采用 TFLite,則為 NHWC,其中通道排在末尾。這影響了后處理步驟的完成方式,即將整數(shù) RGB 值的輸出緩沖區(qū)解包,以創(chuàng)建終末位圖,并顯示在屏幕上。
結(jié)果呈現(xiàn)
性能優(yōu)化
在 Kotlin 中將 RGBA 位圖轉(zhuǎn)換為 RGB 的計(jì)算成本很高。當(dāng)性能預(yù)算限制在 33 毫秒以內(nèi)時(shí),僅轉(zhuǎn)換過(guò)程就需要花費(fèi)幾十毫秒。為了加快速度,我們使用了 C++ 語(yǔ)言,并對(duì)編譯器進(jìn)行了全面優(yōu)化。但是,要從 Kotlin 代碼調(diào)用 C++ 代碼,就得用到 Java 原生接口 (JNI)。通過(guò) JNI 傳遞一個(gè) 3x512x512 大小的浮點(diǎn)數(shù)緩沖區(qū)成本很高,因?yàn)楸仨殢?fù)制兩次,先從 Kotlin 復(fù)制到 C++,處理完后再?gòu)?fù)制回 Kotlin。為了解決這個(gè)問(wèn)題,我們使用了 Java 直接緩沖區(qū)。傳統(tǒng)緩沖區(qū)的內(nèi)存由安卓運(yùn)行時(shí)在堆上分配,C++ 不容易訪問(wèn)。而直接緩沖區(qū)必須按照系統(tǒng)的正確字節(jié)順序分配,而一旦分配好了,內(nèi)存就能以操作系統(tǒng)和 C++ 易于訪問(wèn)的方式分配。這樣,我們就省去了復(fù)制到 JNI 的時(shí)間,并能夠利用高度優(yōu)化的 C++ 代碼。
量化
該模型使用量化技術(shù)進(jìn)行優(yōu)化。量化就是使用較低精度表示神經(jīng)網(wǎng)絡(luò)的權(quán)重和激活值,從而在略微犧牲模型質(zhì)量的情況下提高推理速度。量化用的數(shù)據(jù)類型通常比較小,例如 INT8,它占用的空間只有原來(lái) 32 位浮點(diǎn)數(shù) (FP32) 的四分之一。模型量化有兩種:動(dòng)態(tài)量化和靜態(tài)量化。動(dòng)態(tài)量化僅量化模型權(quán)重,并在運(yùn)行時(shí),針對(duì)激活值確定量化參數(shù)。靜態(tài)量化則事先使用代表性數(shù)據(jù)集量化權(quán)重和激活值,所以在推理方面更快。對(duì)于這個(gè)模型,靜態(tài)量化提高了推理速度,而輸出照明增強(qiáng)效果則略暗一些,這樣的取舍是值得的。
模型推理時(shí)間
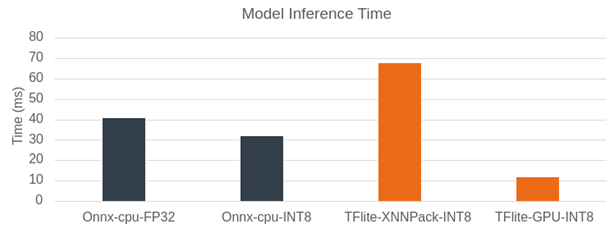
圖:模型推理時(shí)間 Pixel 7
上圖比較了使用 ONNX runtime 和 TensorFlow Lite 對(duì)弱光增強(qiáng)模型進(jìn)行模型推理的時(shí)間。在 Pixel 7 上的分辨率為 512x512。我們先將 ONNX runtime 作為推理引擎。在 CPU 上運(yùn)行時(shí),F(xiàn)P32 的模型推理時(shí)間為 40 毫秒。當(dāng)量化到 INT8 時(shí),這一時(shí)間縮短到 32 毫秒。性能原本有望獲得大幅提升,但使用可視化工具 Netron 分析模型文件后發(fā)現(xiàn),模型圖中增加了額外的量化/反量化算子,從而增加了計(jì)算開(kāi)銷。使用 XNNPack 和 INT8 模型的 TensorFlow Lite 在 CPU 上的表現(xiàn)稍慢于 ONNX runtime,推理時(shí)間接近 70 毫秒。不過(guò),TensorFlow Lite 在使用 GPU 處理時(shí),超越了之前所有推理引擎和模型類型的組合。對(duì)于 512x512 輸入圖像的推理,TensorFlow Lite 僅需 11 毫秒,因此我們選擇它作為運(yùn)行模型的后端,以實(shí)現(xiàn)實(shí)時(shí)照明增強(qiáng)。
安卓性能提示 API
想要重復(fù)對(duì)演示應(yīng)用進(jìn)行基準(zhǔn)測(cè)試,就必須要用 ADB 命令來(lái)開(kāi)啟安卓固定性能模式。這是因?yàn)槊看螠y(cè)試時(shí),CPU 的頻率可能會(huì)變來(lái)變?nèi)ィ珹DB 命令可以固定 CPU 頻率。我們發(fā)現(xiàn),在使用這種固定性能模式后,幀時(shí)間減少了。但這也讓應(yīng)用開(kāi)發(fā)者左右為難,因?yàn)樗麄儧](méi)法控制 CPU 頻率,但又不能指望終端用戶會(huì)使用 ADB。不過(guò),安卓性能提示 API 可以解決這個(gè)問(wèn)題。該 API 主要用于游戲,其工作原理是設(shè)定目標(biāo)幀時(shí)間并將該指標(biāo)報(bào)告回安卓系統(tǒng),由安卓系統(tǒng)調(diào)整時(shí)鐘頻率,嘗試達(dá)到該目標(biāo)。這使得幀時(shí)間得到了與固定性能模式相當(dāng)?shù)牧己酶纳啤?/p>
幀率
當(dāng)弱光增強(qiáng)功能打開(kāi)時(shí),應(yīng)用會(huì)顯示幀時(shí)序。盡管幀率約為 37 FPS,但攝像頭幀速率會(huì)根據(jù)硬件和照明情況受到限制(在極弱光條件下,安卓系統(tǒng)會(huì)降低相機(jī) FPS 以提高亮度)。在 Pixel 7 上,向用戶顯示的幀速率(默認(rèn)的安卓攝像頭 API)上限為 30 FPS。更快的推理并不會(huì)帶來(lái)更好的用戶體驗(yàn),因此保留了一個(gè) 7 FPS 的性能緩沖。
進(jìn)一步的模型訓(xùn)練
盡管原始模型在暗場(chǎng)景下的照明增強(qiáng)效果相當(dāng)不錯(cuò),但圖像有時(shí)會(huì)出現(xiàn)過(guò)度曝光的情況。為了解決這個(gè)問(wèn)題,我們采用了一個(gè)包含兩萬(wàn)張合成圖像的大型數(shù)據(jù)集進(jìn)行訓(xùn)練,此前的研究論文僅使用了兩千張圖像。
不過(guò),基于大型數(shù)據(jù)集的訓(xùn)練時(shí)間會(huì)變長(zhǎng)。經(jīng)過(guò)調(diào)查,性能下降的原因是每批量八張圖像超出了 GPU VRAM 容量,并溢出到系統(tǒng)內(nèi)存中。為了在不增加 VRAM 使用量的情況下提高有效批次大小,我們采用了梯度累積技術(shù),無(wú)需針對(duì)每個(gè)批量計(jì)算梯度,而是累積多個(gè)批量后再計(jì)算梯度。在我們的案例中,我們可以使用的批量上限是六張圖像,而采用梯度累積技術(shù)后,我們能夠使用的批量是 60 張圖像。
結(jié)論
我們?cè)诒疚闹姓故玖艘粋€(gè)可運(yùn)行的演示移動(dòng)端應(yīng)用,用于實(shí)時(shí)改善移動(dòng)端視頻的照明效果。基于 Arm 平臺(tái)優(yōu)化并運(yùn)行 ML 模型的過(guò)程非常順暢,得益于量化和各種推理引擎等技術(shù)的運(yùn)用,該模型能夠在 33 毫秒的嚴(yán)苛性能限制下順利運(yùn)行。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100713 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132561 -
移動(dòng)端
+關(guān)注
關(guān)注
0文章
41瀏覽量
4373
原文標(biāo)題:使用移動(dòng)端神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)實(shí)時(shí)弱光視頻增強(qiáng)
文章出處:【微信號(hào):Arm社區(qū),微信公眾號(hào):Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何構(gòu)建一個(gè)簡(jiǎn)單的對(duì)講電路
如何構(gòu)建一個(gè)具有同步復(fù)位端的CMOS四進(jìn)制計(jì)數(shù)器?
構(gòu)建一個(gè)基于LM13700的壓控放大器
什么是投影機(jī)無(wú)PC移動(dòng)演示
高通聯(lián)合中國(guó)移動(dòng)、中興通訊進(jìn)行端到端5G新空口系統(tǒng)的互通演示
如何快速構(gòu)建一個(gè)移動(dòng)跨平臺(tái)視頻通話應(yīng)用

pc端是什么意思_PC端與移動(dòng)端區(qū)別
中興聯(lián)手廣州移動(dòng)實(shí)現(xiàn)構(gòu)建端到端的5G地鐵切片
端到端的無(wú)人機(jī)導(dǎo)航模擬演示
如何構(gòu)建一個(gè)連接互聯(lián)網(wǎng)的流量計(jì)

如何使用ESP32構(gòu)建一個(gè)BLE iBeacon

構(gòu)建一個(gè)移動(dòng)RFID閱讀器

構(gòu)建一個(gè)移動(dòng)端友好的SAM方案MobileSAM
構(gòu)建一個(gè)移動(dòng)應(yīng)用程序
一個(gè)Artist RoboHelper的構(gòu)建





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論