 高效大模型的推理綜述
高效大模型的推理綜述
大模型由于其在各種任務中的出色表現而引起了廣泛的關注。然而,大模型推理的大量計算和內存需求對其在資源受限場景的部署提出了挑戰。業內一直在努力開發旨在提高大模型推理效率的技術。本文對現有的關于高效大模型推理的文獻進行了全面的綜述總結。首先分析了大模型推理效率低下的主要原因,即大模型參數規模、注意力計算操的二次復雜度作和自回歸解碼方法。然后,引入了一個全面的分類法,將現有優化工作劃分為數據級別、模型級別和系統級別的優化。此外,本文還對關鍵子領域的代表性方法進行了對比實驗,以及分析并給出一定的見解。最后,對相關工作進行總結,并對未來的研究方向進行了討論。
1 Introduction
近年來,大模型受到了學術界和工業界的廣泛關注。
LLM領域經歷了顯著的增長和顯著的成就。許多開源llm已經出現,包括gpt-系列(GPT-1, GPT-2和GPT-3), OPT, lama系列(LLaMA , LLaMA 2,BaiChuan 2 ,Vicuna, LongChat), BLOOM, FALCON, GLM和Mtaistral[12],他們用于學術研究和商業落地。大模型的成功源于其處理各種任務的強大能力,如神經語言理解(NLU)、神經語言生成(NLG)、推理和代碼生成[15],從而實現了ChatGPT、Copilot和Bing等有影響力的應用程序。越來越多的人認為[16]LMM士的崛起和取得的成就標志著人類向通用人工智能(AGI)邁進了一大步。
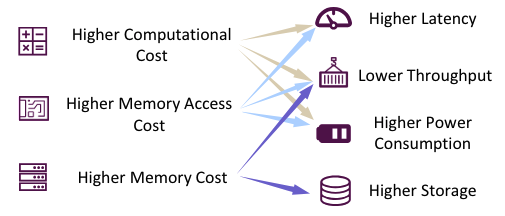
圖1:大模型部署挑戰
然而,LLM的部署并不總是很順利。如圖1所示,在推理過程中,使用LLM通常需要更高的計算成本,內存訪問成本和內存占用。(根本原因分析見Sec. 2.3)在資源受限的場景中,推理效率也會降低(如,延遲,吞吐量,功耗和存儲)。這對LLM在終端以及云場景這兩方面的應用帶來了挑戰。例如,巨大的存儲需求使得在個人筆記本電腦上部署70B參數量的模型來用于輔助開發是不切實際的。此外,如果將LLM用于每一個搜索引擎請求,那么低吞吐量將帶來巨大的成本,從而導致搜索引擎利潤的大幅減少。
幸運的是,大量的技術已經被提出來,以實現LLM的有效推理。為了獲得對現有研究的全面了解,并激發進一步的研究,文章對當前現有的LLM高效推理工作采用了分級分類和系統總結。具體來說,將現有工作劃分組織為數據級別、模型級別和系統級別的優化。此外,文章對關鍵子領域內的代表性方法進行了實驗分析,以鞏固知識,提供實際性建議并為未來的研究努力提供指導。
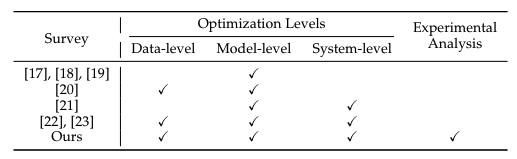
表1:綜述對比
目前,綜述[17],[18],[19],[20],[21],[22]均涉及LLM領域。這些綜述主要集中在LLM效率的不同方面,但提供了進一步改進的機會。Zhu等[17],Park等[18]和Wang等。[19]將綜述的重心放在,模型壓縮技術上,是模型級別的優化。Ding等[20]將數據和模型架構作為研究重心。Miao等[21]從機器學習系統(MLSys)研究的角度研究LLM的有效推理。相比之下,本文提供了一個更全面的研究范圍,在三個層次上解決優化:數據級別、模型級別和系統級別,同時也囊括了最近的研究工作。而Wan等[22]和Xu等[23]也對高效LLM研究進行了全面綜述。基于在幾個關鍵的子領域如模型量化和模型server端中進行的實驗分析,本文通過整合對比實驗,提供實際的見解和建議。如表1所示,展示了各種綜述之間的比較。
本文行文結構劃分如下:第二章介紹了LLMs的基本概念和知識,并對LLMs推理過程中效率瓶頸進行了詳細的分析。第三章展示了本文提出的分類法。第四章到第六章從三個不同優化級別分別對相關工作進行展示討論。第七章針對幾個關鍵的應用場景進行更廣泛的討論。第八章總結本綜述的關鍵貢獻。
2 Preliminaries
2.1 transformer架構的LLM
語言建模作為語言模型的基本功能,包括對單詞序列概率進行建模并預測后續單詞的概率分布。近年來研究人員發現增加語言模型規模不僅提高了語言建模能力,除了傳統的NLP任務之外,還產生了處理更復雜任務的能力[24],這些規模更大的語言模型是被稱為大模型(LLMs)。
主流大模型是基于Transformer架構[25]設計的。典型的transformer架構的模型由數個堆疊的transformer block組成。通常,一個transformer block由一個多頭自注意力(MHSA)模塊,一個前饋神經網絡(FFN)和一個LayerNorm(LN)層組成。每個transformer block接收前一個transformer block的輸出特征,并將其作為輸入,并將特征串行送進每個子模塊中,最后輸出。特別的是,在第一個transformer block前,需要用一個tokenizer將傳統的輸入語句轉化為token序列,并緊接著使用一個embedding層將token序列轉化為輸入特征。且一個額外的位置embedding被加入到輸入特征中,來對輸入token序列的token順序進行編碼。
Transformer架構的核心是自注意力機制,其在多頭自注意力(MHSA)模塊被使用。MHSA模塊對輸入進行線性變換,得到了Q,K,V向量,如公式(1)所示:
其中為輸入特征,為第個注意力頭的變換矩陣。接著自注意力操作被應用于每個()元組并得到第個注意力頭的特征,如公式(2)所示:
其中是query(key)的維度。自注意力計算包含矩陣乘法,其計算復雜度是輸入長度的二次方。最后,MHSA模塊將所有注意力頭的特征進行拼接,并對他們做映射矩陣變換,如公式(3)所示:
其中是映射矩陣。自注意力機制可以讓模型識別不同輸入部分的重要性,而不用去考慮距離,也已就此可以獲得輸入語句的長距離依賴以及復雜的關系。
FFN作為transformer block的另一個重要模塊,被設置在多頭自注意力(MHSA)模塊之后,且包含兩個使用非線性激活函數的。其接收MHSA模塊的輸出特征如公式(4)所示,進行計算:
其中,和為兩個線性層的權重矩陣,為激活函數。
2.2 大模型推理過程
最受歡迎的大模型,如,decoder-only架構的大模型通常采用自回歸的方式生成輸出語句,自回歸的方式是逐token的進行輸出。在每一次生成步中,大模型將過去的全部token序列作為輸入,包括輸入token以及剛剛生成的token,并生成下一個token。隨著序列長度的增加,生過文本這一過程的時間成本也顯著藏家。為了解決這個問題,一個關鍵技術,key-value(KV)緩存被提出來,用于加速文本生成。
KV緩存技術,包括在多頭自注意(MHSA)塊內,存儲和復用前面的token對應的key 向量(K)和value向量(V)。此項技術在大模型推理以中得到了廣泛的應用,因為其對文本生成延遲實現了巨大的優化。基于此項技術,大模型的推理過程可以劃分為兩個階段:
①prefilling階段:大模型計算并存儲原始輸入token的KV緩存,并生成第一個輸出token,如圖2(a)所示
②decoding階段:大模型利用KV 緩存逐個輸出token,并用新生成的token的K,V(鍵-值)對進行KV緩存更新。
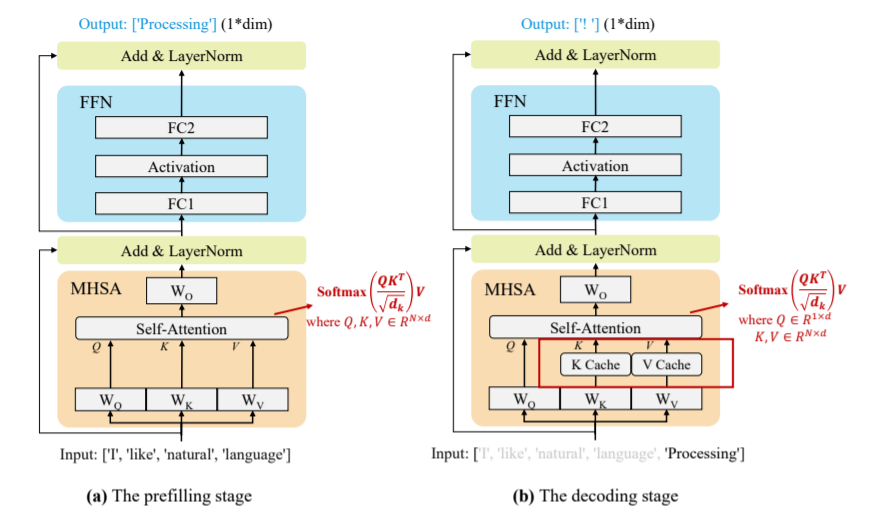
圖2:KV緩存技術在大模型推理中應用原理示意圖
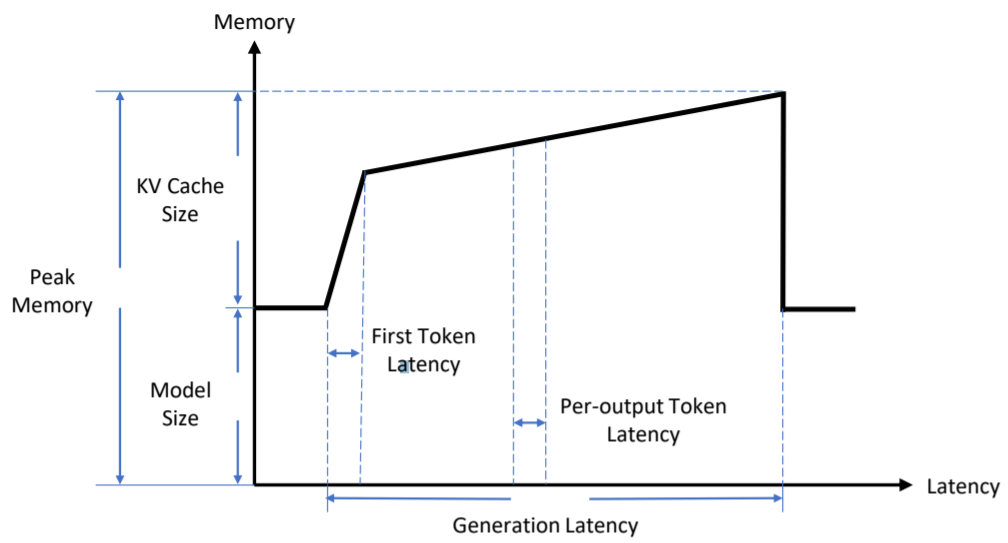
如圖3所示,展示了提升推理效率的關鍵指標。對于橫軸Latency(延遲,在預填充(prefilling)階段,將first token latency記作生成第一個token的時間;在decoding階段,將per-output token latency記作生成一個token的平均時間。此外,generation latency表示輸出整個token序列的時間。對于縱軸Memory(內存),model size被用來表示存儲模型權重所需要的內存大小以及KV cache size代表存儲存儲KV緩存的內存大小。此外,peak memory代表在生成工程中需要占用的最大內存。其大約為model size與KV cache size之和。對模型權重和KV緩存的內存和。除去延遲和內存中,吞吐量(throughput)也是大模型推理服務系統中的一個廣泛使用的指標。token throughput表示每秒生成的token數量,request throughput表示每秒完成的請求數。
2.3 推理效率分析
在資源受限的場景中,部署大模型并保持其推理效率以及性能對于工業界和科研及都是巨大的挑戰。例如,對有700億參數量的LLaMA-2-70B進行部署,以FP16數據格式對其權重進行加載需要140GB顯存(VRAM),進行推理需要至少6張 RTX 3090Ti GPU(單卡顯存24GB)或者2張NVIDIA的A100 GPU(單卡顯存80GB)。在推理延遲方面,2張NVIDIA的A100 GPU上生成一個token需要100毫秒。因此,生成一個具有數百個token的序列需要超過10秒。除去內存占用和推理延遲,吞吐量以及能源電量的消耗都需要被考慮。大模型推理過程中,三個重要因素將很大程度上影響上述指標。計算成本(computational cost),內存訪問成本(memory access cost)和內存使用(memory usage)。大模型推理低效率的根本原因需要關注三個關鍵因素:
①Model Size:主流大模型通常包含數十億甚至萬億的參數。例如,LLaMA-70B模型包括700億參數,而GPT-3為1750億參數。在推理過程中,模型大小對計算成本、內存訪問成本和內存使用產生了顯著影響。
②Attention Operation:如2.1和2.2中所述,prefilling階段中,自注意操作的計算復雜度為輸入長度的2次方,因此輸入長度的增加,計算成本、內存訪問成本和內存使用都會顯著增加。
③Decoding Approach:自回歸解碼是逐token的進行生成。在每個decoding step,所有模型權重都來自于GPU芯片的片下HBM,導致內存訪問成本巨大。此外,KV緩存隨著輸入長度的增長而增長,可能導致內存分散和不規則內存訪問。
3 TAXONOMY
上述部分講述了影響大模型推理性能的關鍵因素,如計算成本、內存訪問成本和內存使用,并進一步分析了根本原因:Model Size、Attention Operation和Decoding Approach。許多研究從不同的角度對優化推理效率進行了努力。通過回顧和總結這些研究,文章將它們分為三個級別的優化,即:數據級別優化、模型級別優化和系統級別優化(如圖4所示):
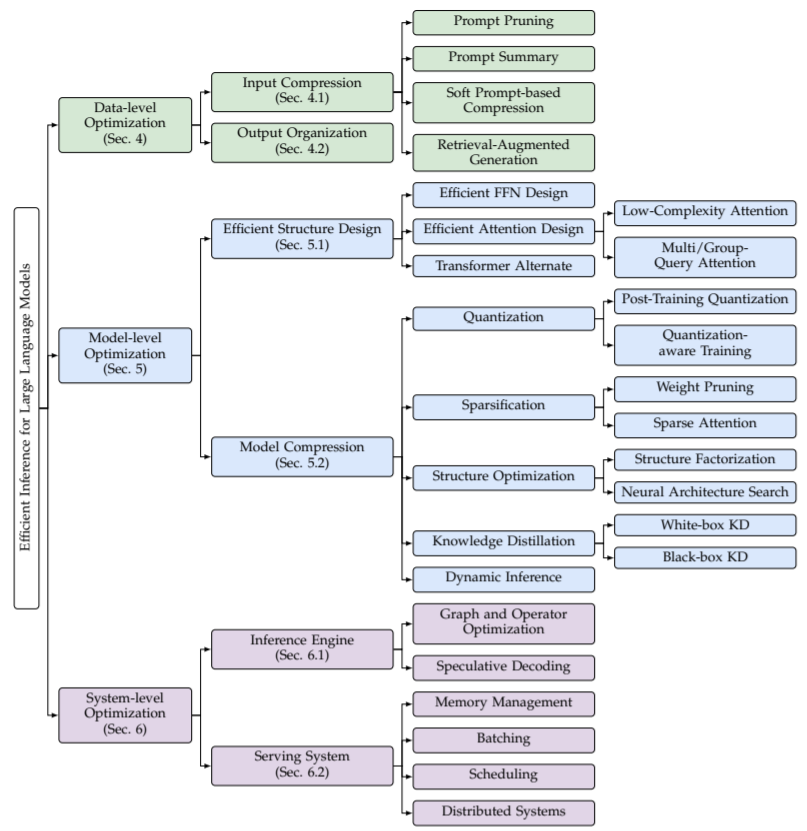
圖4:大模型推理性能優化分類
數據級別優化:即通過優化輸入prompt(例如,輸入壓縮)或者更好的組織輸出內容(例如,輸出組織)。這類優化通常不會改變原來的模型,因此沒有高昂的模型訓練成本(其中,可能需要對少量的輔助模型進行訓練,但與訓練大模型的成本相比,這個成本可以被忽略)。
模型級別優化:即在模型推理時,通過設計一個有效的模型結構(如有效的結構設計)或者壓縮預訓練模型(如模型壓縮)來優化推理效率。優化第一種優化通常需要昂貴的預訓練或少量的微調來保留或者恢復模型能力的成本,而第二種典型的會給模型性能帶來損失。
系統級別優化:即優化推理引擎或者服務系統。推理引擎的優化不需要進行模型訓練,服務系統的優化對于模型性能而言更是無損的。此外,文章還在章節6.3中隊硬件加速設計進行了簡單的介紹。
4.數據級別優化
數據級別的優化今年來的工作可以劃分為兩類,如優輸入壓縮或者輸出組織。輸入壓縮技術直接縮短了模型的輸入長度來減少推理損失。同時輸出組織技術通過組織輸出內容的結構來實現批量(并行)推理,此方法可以提升硬件利用率和降低模型的生成延遲。
4.1輸入壓縮
在大模型的實際應用中,提示詞prompt至關重要,許多工作都提出了設計提示詞的新方法,它們在實踐中均展示出精心設計的提示可以釋放大模型的性能。例如,上下文學習(In-Context Learning)建議在prompt中包含多個相關示例,這種方法能夠鼓勵大模型去進行類比學習。思維鏈(Chain-of-Thought, COT)技術則是在上下文的示例中加入一系列中間的推理步驟,用于幫助大模型進行復雜的推理。然而,這些提示詞上的相關技巧不可避免地會導致提示詞更長,這是一個挑戰,因為計算成本和內存使用在prefilling期間會二次增長(如2.3節所示)。
為了解決這個問腿輸入prompt壓縮技術被提出來用于縮短提示詞長度且不對大模型的回答質量構成顯著性影響。在這一技術方面,相關研究可分為四個方面,如圖5所示:提示詞裁剪(prompt pruning),提示詞總結(prompt summary),基于提示詞的軟壓縮(soft prompt-based compression)和檢索增強生成(retrieval augmented generation, RAG)。
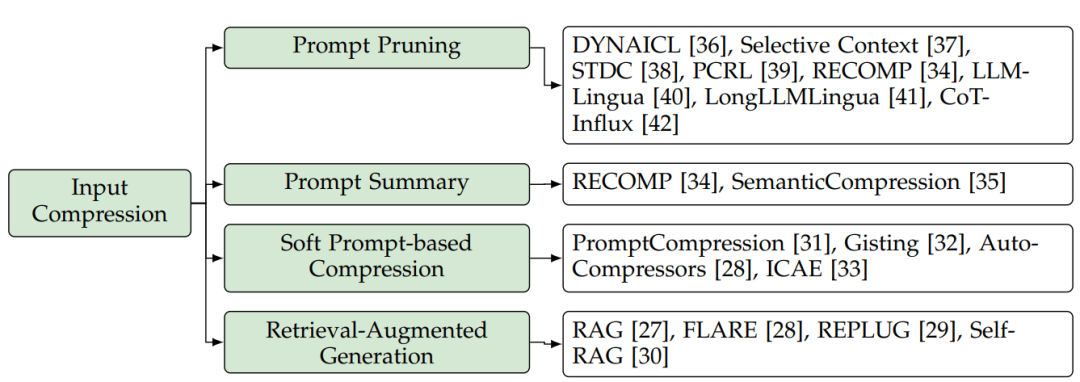
圖5:大模型輸入壓縮方法分類
4.1.1 提示詞裁剪(prompt pruning)
提示詞裁剪的核心思想是從輸入prompt中基于預定義或者學習到的關鍵性指標中去在線去除不重要的token,語句或者文檔。DYNAICL提出對給定輸入,動態地確定上下文示例的最優數量,通過一個訓練好的基于大模型的controller。Selective Context這篇論文提出將token合并為數個單元,接著使用一個基于self-information指標(如,negative log likelihood)的單元級別地prompt裁剪。STDC論文基于解析樹進行提示詞裁剪,其迭代地刪除在裁剪后導致最小性能下降的短語node。PCRL論文引入了一種基于強化學習的token級別的裁剪方案。PCRL背后的核心思想是通過將忠實度和壓縮比組合到獎勵函數中來訓練一個策略大模型。忠實度是通過計算經過裁剪后的輸出提示符和原始提示詞之間的相似度來衡量的。RECOMP方法實現了一種句子級別裁剪策略來壓縮用于檢索增強語言模型(Retrieval-Augmented Language Models, RALMs)的提示。該方法包括使用預訓練的encoder將輸入問題和文檔編碼為latent embedding。然后,它根據文檔embedding與問題embedding的相似度決定要去除哪些文檔。LLMLingua引入了一種粗到細的剪枝方案,用于prompt壓縮。最初,它執行示范級別的裁剪,然后根據困惑度執行token級別的裁剪。為了提高性能,LLMLingua提出了一個預算控制器,在提示詞的不同部分之間動態分配裁剪預算。此外,它利用迭代式的token級的壓縮算法來解決由條件獨立性假設引入的不準確性。LLMLingua還采用了一種分布對齊策略,將目標大模型的輸出分布與用于困惑度計算的較小大模型進行對齊。LongLLMLingua[41]在LLMLingua的基礎上進行了一些加強:(1)它利用以輸入問題為條件的困惑度作為提示詞裁剪的指標。(2)它為不同的演示分配不同的修剪比例,并根據其指標值在最終提示詞內重新排序。(3)基于響應恢復原始內容。CoT-Influx引入了一種使用強化學習對思維鏈(CoT)提示詞進行粗到細粒度裁剪的方法。具體來說,它會先裁剪去除不重要的示例,然后在剩下的示例中繼續刪除不重要的token。
4.1.2 提示詞總結(prompt summary)
提示詞總結的核心思想是在保持相似的語義信息的前提下,將原有提示詞濃縮為更短的總結。這些技術還可以作為提示詞的在線壓縮方法。與前面提到的保留未裁剪標記的提示詞裁剪技術不同,這一行方法將整個提示符轉換為總結。RECOMP[34]引入了一個抽象壓縮器(Abstractive Compressor),其將輸入問題和檢索到的文檔作為輸入,生成一個簡潔的摘要。具體來說,它從大規模的大模型中提取輕量級壓縮器來進行總結工作。SemanticCompression提出了一種語義壓縮方法。它首先將文本分解成句子。然后,它根據主題將句子分組,然后總結每組中的句子。
4.1.3 基于提示詞的軟壓縮(Soft Prompt-based Compression)
這種壓縮技術的核心思想是設計一個比原始提示詞短得多的軟提示詞,作為大模型的輸入。軟提示詞被定義為一系列可學習的連續token。有些技術對固定前綴的提示詞(如系統提示詞、特定任務提示詞)采用脫機壓縮。例如,PromptCompression訓練軟提示來模擬預定的系統提示詞。該方法包括在輸入token之前添加幾個軟token,并允許在反向傳播期間對這些軟token進行調整。在對提示數據集進行微調之后,軟token序列充當軟提示詞。Gisting引入了一種方法,使用前綴詞調優將特定任務的提示詞壓縮為一組簡潔的gist token。鑒于特定任務的提示會因任務而異,前綴詞調優將針對每個任務單獨使用。為了提高效率,Gisting進一步引入了一種元學習方法,用于預測新的未見過的gist token基于先前任務中的的gist token。
其他技術對每個新的輸入提示詞進行在線壓縮。例如,AutoCompressors訓練一個預訓練的語言模型,通過無監督學習將提示詞壓縮成總結向量。ICAE訓練了一個自動編碼器將原始上下文壓縮到短記憶槽中。具體來說,ICAE采用適應LoRA的大模型作為編碼器,并使用目標大模型作為解碼器。在輸入token之前添加一組記憶token并將其編碼到記憶槽中。
4.1.4 檢索增強生成(retrieval augmented generation, RAG)
檢索增強生成(Retrieval-Augmented Generation, RAG)旨在通過整合外部知識來源來提高大模型回答的質量。RAG也可以看作是在處理大量數據時提高推理效率的一種技術。RAG沒有將所有信息合并到一個過長的prompt中,而是將檢索到的相關信息添加到原始提示符中,從而確保模型在顯著減少提示詞長度的同時接收到必要的信息。FLARE使用對即將到來的句子的預測來主動決定何時以及檢索什么信息。REPLUG將大模型視為一個黑盒,并使用可調檢索模型對其進行擴充。它將檢索到的文檔添加到凍結的黑盒大模型的輸入中,并進一步利用大模型來監督檢索模型。Self-RAG通過檢索和自我反思來提高大模型的質量和真實性。它引入了反饋token,使大模型在推理階段可控。
4.2 輸出組織(Output Organization)
傳統的大模型的推理過程是完全順序生成的,這會導致大量的時間消耗。輸出組織技術旨在通過組織輸出內容的結構來(部分地)實現并行化生成。
思維骨架(Skeleton-of-Thought, SoT)是這個方向的先驅。SoT背后的核心思想是利用大模型的新興能力來對輸出內容的結構進行規劃。具體來說,SoT包括兩個主要階段。在第一階段(即框架階段),SoT指導大模型使用預定義的“框架提示詞”生成答案的簡明框架。例如,給定一個問題,如“中國菜的典型類型是什么?”,這個階段的輸出將是一個菜的列表(例如,面條,火鍋,米飯),沒有詳細的描述。然后,在第二階段(即點擴展階段),SoT指導大模型使用“點擴展提示符”來同時擴展骨架中的每個點,然后將這些拓展連接起來最終形成最后答案。當應用于開源模型時,可以通過批推理執行點擴展,這可以提升硬件利用率,并在使用相同的計算資源的前提下減少總體生成延遲,以減少額外的計算。SoT的推理流程展示如圖6所示:
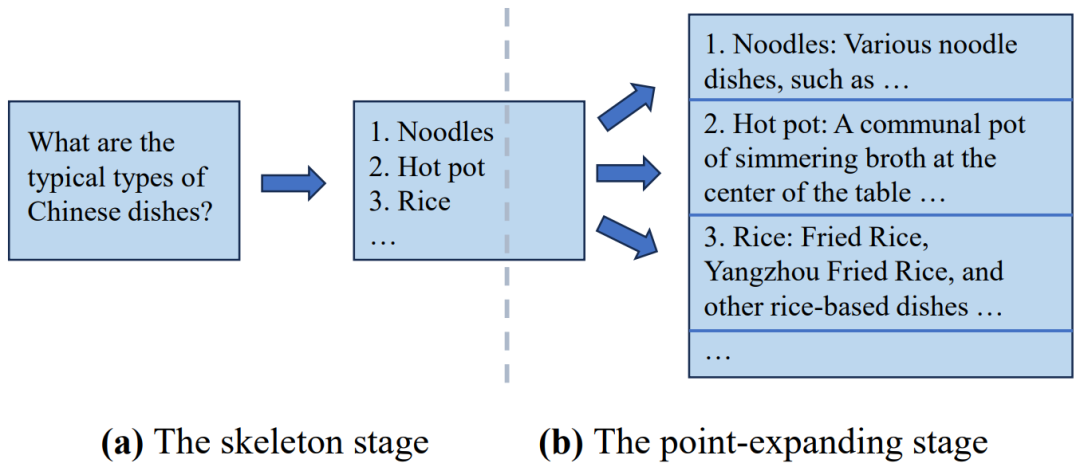
由于額外的提示詞(如骨架提示詞和點擴展提示詞)帶來的開銷,SoT討論了在點擴展階段跨多個點來共享公共提示詞前綴的KV緩存的可能性。此外,SoT使用路由模型來決定SoT是否適合應用于特定的問題,目的是將其限制在合適的情況下使用。結果,SoT在最近發布的12個大模型上 實現了高達2.39倍的推理加速,并通過提高答案的多樣性和相關性來提高答案質量。
SGD進一步擴展了SoT的思想,其將子問題點組織成一個有向無環圖(DAG),并在一個回合內并行地回答邏輯獨立的子問題。與SoT類似,SGD還利用大模型的新興能力,通過提供自己制作的提示詞和幾個示例來生成輸出結構。SGD放寬了不同點之間嚴格的獨立性假設,以提高答案的質量,特別是對于數學和編碼問題。與SoT相比,SGD優先考慮答案質量而不是速度。此外,SGD引入了一個自適應的模型選擇方法,來根據其估計的復雜性為每個子問題分配最優模型大小,從而進一步提高效率。
APAR采用了與SoT類似的思想,利用大模型輸出特殊的控制token(如 ,[fork])來自動動態的觸發并行解碼。為了有效地利用輸出內容中固有的可并行化結構并準確地生成控制token,APAR對大模型進行了微調,這些大模型是精心設計的數據上進行的,這些數據是在特定樹結構中形成的。因此,APAR在基準測試中實現1.4到2.0倍的平均加速,且對答案質量的影響可以忽略不計。此外,APAR將他們的解碼方法與推測解碼技術(如Medusa)和推理框架(如vLLM)結合,來進一步改進推理延遲和系統吞吐量。
SGLang在Python 特征原語中引入了一種領域特定語言(DSL),其能夠靈活地促進大模型編程。SGLang的核心思想是自動分析各種生成調用之間的依賴關系,并在此基礎上進行批量推理和KV緩存共享。使用該語言,用戶可以輕松實現各種提示詞策略,并從SGLang的自動效率優化(如SoT,ToT)中收益。此外,SGLang 還介紹并結合了幾種系統級別的編譯技術,如代碼移動和預取注釋。
4.3 認識,建議和未來方向
大模型處理更長的輸入、生成更長的輸出的需求日益增長,這凸顯了數據級別的優化技術的重要性。在這些技術中,輸入壓縮方法的主要目標是通過減少由attention操作引起的計算和內存成本來提升prefilling階段的效率。此外,對于基于API的大模型,這些方法可以減少與輸入token相關的API成本。相比之下,輸出組織方法側重于通過降低與自回歸解碼方法相關的大量內存訪問成本來優化解碼階段。
隨著大模型的功能越來越強大,是有可能能利用它們來壓縮輸入提示詞或構建輸出內容的。輸出組織方法的最新進展也證明了利用大模型將輸出內容組織成獨立點或依賴圖的有效性,從而便于批量推理以改善生成延遲。這些方法利用了輸出內容中固有的可并行結構,使大模型能夠執行并行解碼,從而提高硬件利用率,從而減少端到端的生成延遲。
最近,各種提示詞pipeline(如,ToT ,GoT)和Agent框架正在出現。雖然這些創新提高了大模型的能力,但它們也增加了輸入prompt的長度,導致計算成本增加。為了解決這個問題,采用輸入壓縮技術來減少輸入長度是一種很有希望的解決方案。同時,這些pipeline和框架自然地為輸出結構引入了更多的并行性,增加了并行解碼和跨不同解碼線程來共享KV cache的可能性。SGLang支持靈活的大模型編程,并為前端和后端協同優化提供了機會,為該領域的進一步擴展和改進奠定了基礎。總之,數據級別優化,包括輸入壓縮和輸出組織技術,在可預見的將來,為了提高大模型推理效率,將變得越來越必要。
除了優化現有框架的推理效率外,一些研究還側重于直接設計更高效的智能體框架。例如,FrugalGPT提出了一個由不同大小的大模型組成的模型級聯,如果模型對答案達到足夠的確定性水平,那么推理過程就會提前停止。該方法通過利用分層的模型體系結構和基于模型置信度估計的智能推理終止來提高效率。與模型級別的動態推理技術(第5.2.5節)相比,FrugalGPT在pipeline級別執行動態推理。
5 模型級別優化
大模型高效推理的模型級別優化主要集中在模型結構或數據表示的優化上。模型結構優化包括直接設計有效的模型結構、修改原模型和調整推理時間結構。在數據表示優化方面,通常采用模型量化技術。
在本節中,文章將根據所需的額外訓練開銷對模型級別的優化技術進行分類。第一類包含設計更有效的模型結構(又叫有效結構設計)。使用這種方法開發的模型通常需要從頭開始訓練。第二類側重于壓縮預訓練模型(稱為模型壓縮)。此類別中的壓縮模型通常只需要最小的微調即可恢復其性能。
5.1 有效結構設計
目前,SOTA大模型通常使用Transformer架構,如2.1節所述。然而,基于transformer的大模型的關鍵組件,包括前饋網絡(FFN)和attention操作,在推理過程中存在效率問題。文章認為原因如下:
FFN在基于transformer的大模型中貢獻了很大一部分模型參數,這導致顯著的內存訪問成本和內存使用,特別是在解碼階段。例如,FFN模塊在LLaMA-7B模型中占63.01%,在LLaMA-70B模型中占71.69%。
attention操作在的復雜度是輸入長度的二次方,這導致大量的計算成本和內存使用,特別是在處理較長的輸入上下文時。
為了解決這些計算效率問題,一些研究集中在開發更有效的模型結構上。文章將相關研究分為三組(如圖7所示):高效FFN設計、高效注意力設計和Transformer替代。
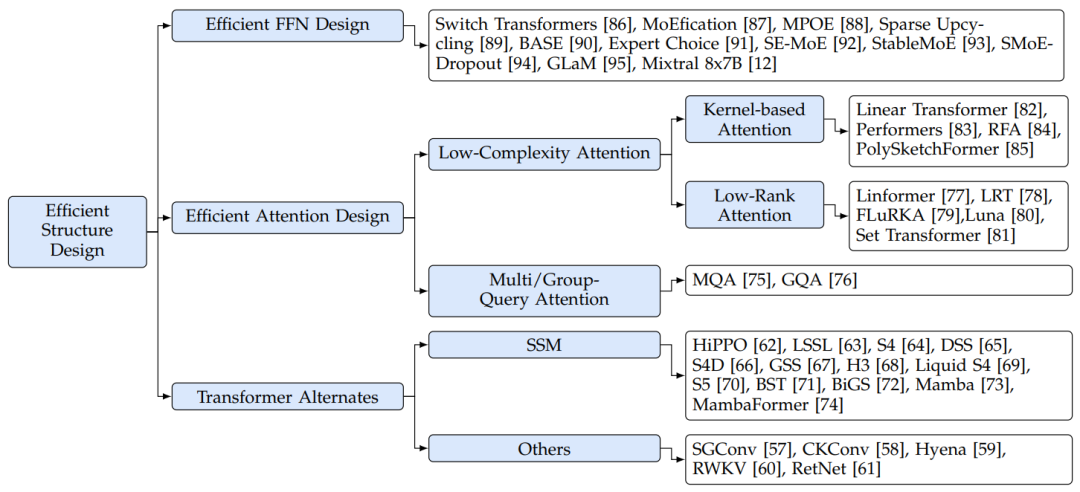
圖7:大模型有效結構設計分類
5.1.1 高效FFN設計
在這一方面,許多研究都集中在將混合專家(mixture-of-experts, MoE)技術集成到大模型中,以提高大模型的性能,同時保持計算成本。MoE的核心思想是動態地分配各種預算,在面對不同的輸入token時。在基于MoE的Transformers中,多個并行的前饋審計網絡(FFN),即專家,與可訓練的路由模塊一起使用。在推理過程中,模型選擇性地為路由模塊控制的每個token激活特定的專家。
一些研究集中研究FFN專家的工作,主要是在優化專家權值的獲取過程或使專家更輕量化以提高效率。例如,MoEfication設計了一種方法,使用預訓練的權重將非MoE大模型轉換為MoE版本。這種方法免去了對MoE模型進行昂貴的預訓練的需要。為了實現這個技術,MoEfication首先將預訓練大模型的FFN神經元分成多組。在每一組中,神經元通常同時被激活函數激活。然后,它以專家的身份重組每組神經元。Sparse Upcycling引入了一種方法,直接從密集模型的checkpoint中初始化基于MoE的LLM的權重。在這種方法中,基于MoE的LLM中的專家是密集模型中FFN的精確復制品。通過使用這種簡單的初始化,Sparse Upcycling可以有效地訓練MoE模型以達到高性能。MPOE提出通過矩陣乘積算子(Matrix Product Operators, MPO)分解來減少基于MoE的大模型的參數。該方法將FFN的每個權重矩陣分解為一個包含公共信息的全局共享張量和一組捕獲特定特征的局部輔助張量。
另一項研究側重于改進MoE模型中路由模塊(或策略)的設計。在以前的MoE模型中,路由模塊容易導致負載不平衡問題,這意味著一些專家被分配了大量token,而另一些專家只處理少量token。這種不平衡不僅浪費了未充分利用的專家的能力,降低了模型的性能,還降低了推斷推理質量。當前的MoE實現經常使用批矩陣乘法來同時計算所有FFN專家。這就要求每個專家的輸入矩陣必須具有相同的形狀。然而,由于存在負載不平衡問題,需要向那些未充分利用的專家中填充輸入token集以滿足形狀約束,這會造成計算浪費。因此,路由模塊設計的主要目標是在MoE專家的token分配中實現更好的平衡。Switch Transformers在最終loss函數中引入了一個額外的loss,即負載平衡loss,以懲罰路由模塊的不平衡分配。這種loss被表述為token分配分數向量和均勻分布向量之間的縮放點積。因此,只有在所有專家之間平衡token分配時,損失才會最小化。這種方法鼓勵路由模塊在專家之間均勻地分發token,促進負載平衡并最終提高模型性能和效率。BASE用端到端的方式學習了每個專家的embedding,然后根據embedding的相似性將專家分配給令token。為了保證負載均衡,BASE制定了一個線性分配問題,并利用拍賣算法有效地解決了這個問題。Expert Choice引入了一種簡單而有效的策略來確保基于MoE的模型的完美負載平衡。與以前將專家分配給token的方法不同,Expert Choice允許每個專家根據embedding的相似度獨立選擇top-k個token。這種方法確保每個專家處理固定數量的token,即使每個token可能分配給不同數量的專家。
除了上述關注模型架構本身的研究外,也有對基于MoE的模型的訓練方法改進的相關工作。SE-MoE引入了一種新的輔助loss,稱為router z-loss,其目的是在不影響性能的情況下提高模型訓練的穩定性。SE-MoE發現在路由模塊中,softmax操作所引入的指數函數會加劇舍入誤差,導致訓練不穩定。為了解決這個問題,router z-loss會懲罰輸入到指數函數中的大概率,從而最小化訓練期間的舍入誤差。StableMoE指出基于MoE的大模型存在路由波動問題,即在訓練和推理階段專家分配不一致。對于相同的輸入token,在訓練時其被分配給了不同的專家,但在推理時卻只激活一個專家。為了解決這個問題,StableMoE建議采用更一致的訓練方法。它首先學習路由策略,然后在模型主干訓練和推理階段保持固定的路由策略。SMoE-Dropout為基于MoE的大模型設計了一種訓練方法,其提出在訓練過程中逐步增加激活專家的數量。這種方法提升了基于MoE的模型的推理和下游微調的可擴展性。GLaM預訓練并發布了一系列具有不同參數大小的模型,這證明了它們在few-shot任務上與密集大模型的性能相當。這個系列模型中,最大的模型的參數高達1.2萬億。Mixtral 8x7B是最近發布的一個引人注目的開源模型。在推理過程中,它只利用了130億個活動參數,在不同的基準測試中取得了比LLaMA-2-70B模型更好的性能。Mixtral 8x7B每層由8個前饋網絡(FFN)專家組成,每個token在推理過程中分配給兩個專家。
5.1.2 高效attention設計
attention操作是Transformer體系結構中的一個關鍵部分。然而,它的計算復雜度是與輸入長度相關的二次方,這導致了大量的計算成本、內存訪問成本和內存使用,特別是在處理長上下文時。為了解決這個問題,研究人員正在探索更有效的方法來近似原始attention操作的功能。這些研究大致可以分為兩個主要分支:multi-query attention和low complexity attention。
①Multi-Query Attention。Multi-Query Attention(MQA)通過共享橫跨不同注意力頭的KV緩存來優化attention 操作。這項策略有效的減少了推理時的內存訪問成本和內存使用,對改善Transformer模型的性能帶來了幫助。如第2.2節所述,transformer類型的大模型通常采用多頭注意力(MHA)操作。該操作需要在解碼階段為每個注意力頭存儲和檢索KV對,導致內存訪問成本和內存使用大幅增加。而MQA通過在不同的頭上使用相同的KV對,同時保持不同的Q值來解決這一問題。通過廣泛的測試,MQA已經被證明可以顯著降低內存需求,且對模型性能的影響很小,這使它成為一個提高推理效率的關鍵技術。Grouped-query attention(GQA)進一步擴展了MQA的概念,它可以看作是MHA和MQA的混合。具體來說,GQA將注意力頭分成不同的組,然后為每個組存儲一組KV值。這種方法不僅保持了MQA在減少內存開銷方面的優勢,還強化了推理速度和輸出質量之間的平衡。
②Low-Complexity Attention。Low-Complexity Attention方法旨在設計新的機制來降低每個注意力頭的計算復雜度。為了簡化討論,這里假設Q(查詢)、K(鍵)和V(值)矩陣的維度是相同的,即。由于下面的工作不涉及像MQA那樣改變注意頭的數量,此處的討論集中在每個頭內的注意力機制。如2.2節所述,傳統注意力機制的計算復雜度為,相當于隨著輸入長度增長,呈二次增長。為了解決低效率問題,Kernel-based Attention和Low-Rank Attention方法被提出,此方法將復雜度降低到。
Kernel-based Attention。基于核的注意力設計了一個核,通過變換特征映射之間的線性點積如,,來近似的非線性softmax操作。它通過優先計算,然后將其與相乘,從而避免了與相關的傳統二次計算。具體來說,輸入Q和K矩陣首先通過核函數映射到核空間,但是保持其原始維度。接著利用矩陣乘法的關聯特性,允許K和V在與Q交互之前相乘。因此注意力機制被重新表述為:
其中,。此方法有效的將計算復雜度降低至,使其與輸入長度成線性關系。Linear Transformer是第一個提出基于核的注意力的工作。它采用作為核函數,其中表示指數線性單元激活函數。Performers和RFA提出使用隨機特征映射來更好地近似softmax函數。PolySketchFormer采用多項式函數和素描技術近似softmax函數。
Low-Rank Attention。 Low-Rank Attention技術在執行注意計算之前,將K和V矩陣的token維度(如)壓縮到較小的固定長度(即如)。該方法基于對注意力矩陣通常表現出低秩特性的認識,使得在token維度上壓縮它是可行的。這條研究路線的主要重點是設計有效的壓縮方法,其中可以是上下文矩陣,也可以是K和V矩陣:
有一種工作是使用線性投影來壓縮token維度。它通過將K和V矩陣與映射矩陣相乘來完成的。這樣,注意力計算的計算復雜度降至,與輸入長度成線性關系。Linformer首先觀察并分析了注意力的低秩性,提出了低秩注意力框架。LRT提出將低秩變換同時應用于attention模塊和FFN,來進一步提高計算效率。FLuRKA將低秩變換和核化結合到注意力矩陣中,進一步提高了效率。具體的說,它首先降低K和V矩陣的token的維度,然后對Q和低秩K矩陣應用核函數。
除了線性映射外,其他的token維度壓縮方法也被提出出來。Luna和Set Transformer利用額外的注意力計算和較小的query來有效地壓縮K和V矩陣。Luna則是使用了一個額外的固定長度為的query矩陣。小的query使用原始的上下文矩陣執行注意力計算,稱為pack attention,來將上下文矩陣壓縮到大小為。隨后,常規的注意力計算,稱為unpack attention,將注意力計算應用于原始Q矩陣和壓縮的K和V矩陣。額外的query矩陣可以是可學習的參數或從前一層中獲取。Set Transformer通過引入固定長度的矢量,設計了類似的技術。FunnelTransformer不同于以往壓縮K和V的工作,它使用池化操作來逐步壓縮Q矩陣的序列長度。
5.1.3 Transformer替代
除了聚焦于優化注意力操作之外,最近的研究還創新地設計了高效而有效的序列建模體系結構。表2比較了一些代表性的非transformer架構模型的性能。在訓練和推理過程中,這些架構的模型在序列長度方面表現出小于二次方的計算復雜度,使大模型能夠顯著增加其上下文長度。
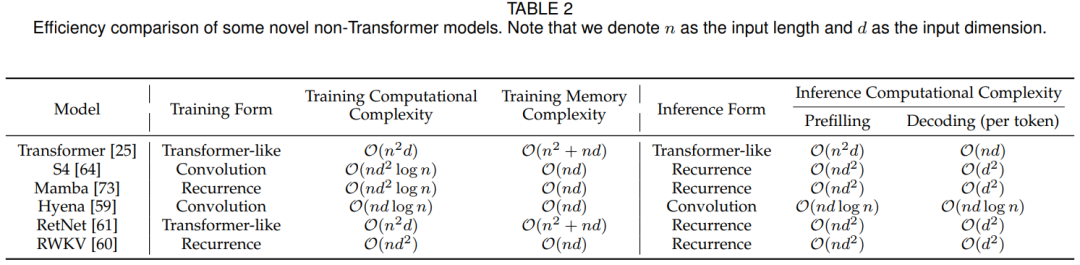
典型非Transformer架構模型性能比較
在這些研究中,有兩個突出的研究方向引起了極大的關注。其中一條研究集中在狀態空間模型(State Space Model, SSM)上,該模型將序列建模視作一種基于HiPPO理論的遞歸變換。此外,其他研究主要集中在使用長卷積或設計類似注意力的公式來建模序列。
State Space Model:狀態空間模型(SSM)在某些NLP和CV任務中的建模能力極具競爭力。與基于注意力的Transformer相比,SSM在輸入序列長度方面表現出線性的計算和存儲復雜度,這提高了其處理長上下文序列的能力。本篇綜述中,SSM是指一系列滿足以下兩個屬性的模型架構:
(1)它們基于HiPPO和LSSL提出的以下公式對序列進行建模:
其中,表示轉移矩陣。為中間狀態,為輸入序列。
(2)他們基于HiPPO理論設計了轉移矩陣A。具體來說,HiPPO提出通過將輸入序列映射到一組多項式基上,將其壓縮為系數序列(即)。
在上述框架的基礎上,一些研究主要集中在改進轉移矩陣A的參數化或初始化。這包括在SSM中重新定義矩陣的公式或初始化方式,以增強其在序列建模任務中的有效性和性能。LSSL首先提出用HiPPO設計的最優轉移矩陣初始化A。此外,LSSL還通過展開公式(7),以卷積的方式訓練SSM。具體地說,通過定義一個卷積核為,可以將公式(7)改寫為,也可以通過快速傅里葉變換(FFT)高效地計算。然而,計算這個卷積核的代價是昂貴的,因為它需要多次乘以A。為此,S4、DSS和S4D提出對矩陣A進行對角化,從而加快計算速度。這可以看作是轉換矩陣A的參數化技術。過去的SSM獨立處理每個輸入維度,從而會產生大量可訓練的參數。為了提高效率,S5提出使用一組參數同時處理所有輸入維度。在此結構的基礎上,S5介紹了基于標準HiPPO矩陣的A的參數化和初始化方法。Liquid S4和Mamba以輸入依賴的方式對轉移矩陣進行參數化,這進一步增強了SSM的建模能力。此外,S5和Mamba均采用并行掃描技術,無需卷積操作即可進行有效的模型訓練。這種技術在現代GPU硬件上的實現和部署方面具有優勢。
另一類研究方向是基于SSM設計更好的模型架構。GSS和BiGS結合了門控注意力單元(GAU)和SSM。它們將GAU中的注意力操作替換為SSM操作。BST將SSM模型與提出的使用強局部感應偏置的Block Transformer相結合。H3觀察到SSM在召回較早的token和跨序列比較token方面很弱。為此,它建議在標準SSM操作之前增加一個移位SSM操作,用于直接將輸入令牌移位進入狀態。MambaFormer結合了標準Transformer和SSM模型,將Transformer中的FFN層替換為SSM層。Jamba引入了另一種方法,通過在SSM模型中添加四個Transformer層來組合Transformer和SSM模型。DenseMamba探討了傳統SSM中隱藏狀態退化的問題,并在SSM體系結構中引入了稠密連接,以在模型的更深層中保存細粒度信息。BlackMamba和MoE- mamba提出用混合專家(Mixture-of-Experts, MoE)技術增強SSM模型,在保持模型性能的同時優化訓練和推理效率。
其他代替:除了SSM之外,還有其他幾種高效的替代方案也引起了極大的關注,包括長卷積和類attention的遞歸運算。一些研究在長序列建模中采用了長卷積。這些工作主要是關于卷積參數的參數化的。例如,Hyena采用了一種數據相關的參數化方法,用于使用淺前饋神經網絡(FFN)的長卷積。其他設計類注意力操作,但可以納入循環方式的研究,從而實現高效的訓練和高效的推理。例如,RWKV是在AFT的基礎上建立的,AFT提出將Transformer模型中的注意力操作代入如下公式:
其中,和Transformer一樣 ,分別為quey,key,vakue,為一個可學習的成對位置偏差和為一個非線性函數。具體來說,它進一步將位置偏差進行重參數化,,因此可以將公式(8)重寫為遞歸形式。這樣,RWKV可以將Transformer的有效并行化訓練特性和RNN的高效推理能力結合起來。
效果分析:文章在表2中分析和比較了幾種創新的和具有代表性的非Transformer架構的模型的計算和內存復雜性。在訓練時間方面,許多模型(如S4, Hyena, RetNet)這些通過使用卷積或注意力等訓練形式來保持訓練并行性。值得注意的是,Mamba用并行掃描技術處理輸入序列,從而也使用了訓練并行性。
另一方面,在推理過程中,大多數研究選擇循環架構來保持prefilling階段的線性計算復雜度并在decoding階段保持上下文長度不可知。而且,在decoding階段,這些新穎的體系結構消除了緩存和加載歷史token的特性的需要(類似于基于Transformer的語言模型中的KV緩存),從而顯著節省了內存訪問成本。
5.2 模型壓縮
模型壓縮包括一系列旨在通過修改預訓練模型的數據表示(例如,量化)或改變其模型架構(例如,稀疏化、結構優化和動態推理)來提高其推理效率的技術,如圖8所示。
圖8:大模型的模型壓縮方法分類
5.2.1 量化
量化是一種廣泛使用的技術,通過將模型的權重和激活從高位寬表示轉換為低位寬表示來減少大模型的計算和內存成本。具體來說,許多方法都涉及到將FP16張量量化為低位整型張量,可以表示為如下公式:
其中表示16位浮點(FP16)值,表示低精度整數值,表示位數,和表示縮放因子和零點。
在下面,本文從效率分析開始,說明量化技術如何減少大模型的端到端推理延遲。隨后,再分別詳細介紹兩種不同的量化工作流程:Post-Training Quantization (PTQ)和Quantization-Aware Training (QAT)。
效率分析:如2.2節所述,大模型的推理過程包括兩個階段:prefilling階段和decoding階段。在prefilling階段,大模型通常處理長token序列,主要操作是通用矩陣乘法(GEMM)。Prefilling階段的延遲主要受到高精度CUDA內核執行的計算操作的限制。為了解決這個問題,現有的研究方法對權重和激活量化,以使用低精度Tensor核來加速計算。如圖9 (b)所示,在每次GEMM操作之前會在線執行激活量化,從而允許使用低精度Tensor核(例如INT8)進行計算。這種量化方法被稱為權重激活量化。
相比之下,在解碼階段,大模型在每個生成步中只處理一個token,其使用通用矩陣向量乘法(GEMV)作為核心操作。解碼階段的延遲主要受到加載大權重張量的影響。為了解決這個問題,現有的方法只關注量化權重來加速內存訪問。這種方法稱為,首先對權重進行離線量化,然后將低精度權重去量化為FP16格式進行計算,如圖9 (a)所示。
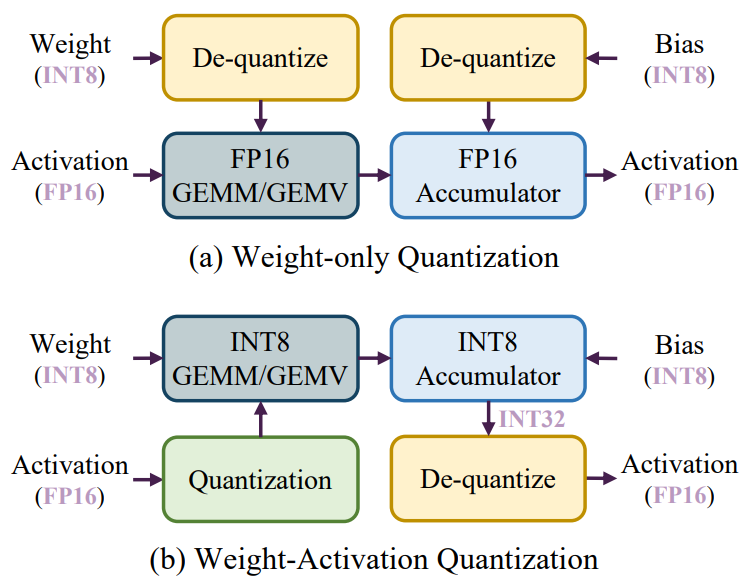
圖9:(a)純權重量化推理流程。(b)權重激活量化推理流程。
Post-Training Quantization: PTQ涉及對預訓練模型進行量化,而不需要再訓練,這可能是一個昂貴的過程。盡管PTQ方法已經在較小的模型中得到了很好的探索,但是將現有的量化技術直接應用于大模型存在困難。這主要是因為與較小的模型相比,大模型的權重和激活通常表現出更多的異常值,并且具有更寬的分布范圍,這使得它們的量化更具挑戰性。總之,大模型的復雜特性,以其規模和復雜性為特征,需要用專門的方法來有效地處理量化過程。大模型中異常值和更寬的分布范圍的存在需要開發量身定制的量化技術,以便在不影響模型性能或效率的情況下處理這些獨特的特征。
大量的研究致力于開發有效的量化算法來壓縮大模型。本文在表3中提供了跨四個維度分類的代表性算法的綜合。對于量化張量的種類,某些研究專注于weight-only quantization,而其他許多研究則專注于權重和激活的量化。值得注意的是,在大模型中,KV緩存代表了影響內存和內存訪問的獨特組件。因此,一些研究提出對KV緩存進行量化。在量化格式方面,為了便于硬件實現,大多數算法采用統一的格式。關于量化參數(如縮放因子、零點)的確定,大多數研究依賴于由權重或激活值得出的統計數據。然而,也有一些研究主張基于重構loss來尋找最優參數。此外,一些研究也建議在量化之前或量化過程中更新未量化的權重(稱為)以提高性能。
在weight-only quantization方法中,GPTQ代表了大模型量化的早期較好的工作,它建立在傳統算法OBQ的基礎上。OBQ通過相對于未量化權重的Hessian矩陣的重建誤差的方法,來實現每行權重矩陣的最優量化順序。在每個量化步驟之后,OBQ迭代調整未量化的權重以減輕重建誤差。然而,量化過程中頻繁更新Hessian矩陣增加了計算復雜度。GPTQ通過采用統一的從左到右的順序來量化每一行,從而簡化了這個過程,從而避免了大量更新Hessian矩陣的需要。該策略通過在量化一行時僅計算Hessian矩陣,然后將計算結果用于后續行,從而大大減少了計算需求,從而加快了整個量化過程。LUT- GEMM提出了一種新的利用查找表(Look-Up Table, LUT)的去量化方法,旨在通過減少去量化開銷來加速量化大模型的推理過程。此外,它采用了一種稱為二進制編碼量化(BCQ)的非均勻量化方法,該方法包含了可學習的量化區間。AWQ觀察到權重通道對性能的重要性各不相同,特別強調那些與激活異常值的輸入通道對齊的通道。為了增強關鍵權重通道的保存,AWQ采用了一種重參數化的方法。該方法通過網格搜索選擇重參數化系數,有效地減小了重構誤差。OWQ觀察到量化與激活異常值相關的權重的困難。為了解決這個問題,OWQ采用了混合精度量化策略。該方法識別權重矩陣中的弱列,并為這些特定權重分配更高的精度,同時以較低的精度級別量化其余權重。SpQR引入了一種方法,在量化過程中識別和分配更高精度的權重異常值,而其余權重被量化為3位。SqueezeLLM提出將離群值存儲在全精度稀疏矩陣中,并對剩余權重應用非均勻量化。根據量化靈敏度確定非均勻量化的值,能夠提高量化模型的性能。QuIP引入了LDLQ,一種二次代理目標的最優自適應方法。研究表明,保證權值與Hessian矩陣之間的不相干性可以提高LDLQ的有效性。QuIP利用LDLQ,通過隨機正交矩陣乘法實現非相干性。FineQuant采用了一種啟發式方法。為了確定每列量化的粒度,結合從實驗中獲得的經驗見解來設計量化方案。QuantEase的工作建立在GPTQ之上。在對每一層進行量化時,其提出了一種基于坐標下降的方法來更精確地補償未量化的權重。此外,QuantEase可以利用來自GPTQ的量化權重作為初始化,并進一步完善補償過程。LLM-MQ采用FP16格式保護權重異常值,并將其存儲在壓縮稀疏行(CSR)格式中,以提高計算效率。此外,LLM-MQ將每個層的位寬分配,建模為整數規劃問題,并采用高效的求解器在幾秒內求解。LLM-MQ還設計了一個高效的CUDA內核來集成去量化運算符,從而降低了計算過程中的內存訪問成本。
對于weight-activation quantization,ZeroQuant采用細粒度量化權值和激活,利用核融合來最小化量化過程中的內存訪問成本,并逐層進行知識蒸餾以恢復性能。FlexGen將權重和KV緩存直接量化到INT4中,以減少大批量推理期間的內存占用。LLM.int8() 發現激活中的異常值集中在一小部分通道中。基于這一點,LLM.int8() 根據輸入通道內的離群值分布將激活和權重分成兩個不同的部分,以最小化激活中的量化誤差。包含激活值和權重的異常數據的通道以FP16格式存儲,其他通道則以INT8格式存儲。SmoothQuant采用了一種重新參數化技術來解決量化激活值的挑戰。該方法引入比例因子,擴大了權重通道的數據范圍,縮小了相應激活通道的數據范圍。ZeroQuant引入了權重的組級別的量化策略和激活的token級別的量化方法。在此方法的基礎上,ZeroQuantV2提出了LoRC(低秩補償)技術,采用低秩矩陣來減輕量化不準確性。RPTQ發現不同激活通道的分布,實質上是變化的,這給量化帶來了挑戰。為了緩解這個問題,RPTQ將具有相似激活分布的通道重新組織到集群中,并在每個集群中獨立地應用量化。OliVe觀察到離群值附近的正態值不那么關鍵。因此,它將每個離群值與一個正態值配對,犧牲正態值,以獲得更大的離群值表示范圍。OS+觀察到異常值的分布是集中且不對稱的,這對大模型的量化提出了挑戰。為了解決這個問題,OS+引入了一種通道級別的移動和縮放技術。在搜索過程去確定移動和縮放參數,能有效地處理集中和不對稱的離群值分布。ZeroQuant-FP研究了將權重和激活值量化為FP4和FP8格式的可行性。研究表明,與整數類型相比,將激活量化為浮點類型(FP4和FP8)會產生更好的結果。Omniquant與先前依賴量化參數的經驗設計的方法不同。相反,它優化了權值裁剪的邊界和等效變換的縮放因子,以最小化量化誤差。QLLM通過實現通道重組來解決異常值對量化的影響。此外,QLLM還設計了可學習的低秩參數,來減小post-quantized模型的量化誤差。Atom采用了混合精度和動態量化激活的策略。值得注意的是,它擴展了這種方法,將KV緩存量化為INT4,以提高吞吐量性能。LLM-FP4努力將整個模型量化為FP4格式,并引入了預移位指數偏置技術。該方法將激活值的比例因子與權重相結合,以解決異常值帶來的量化問題。BiLLM代表了迄今為止最低位PTQ的工作之一。BiLLM識別了權值的鐘形分布和權值Hessian矩陣的異常長尾分布。在此基礎上,提出了將基于Hessian矩陣的權重結構分類為顯著值和非顯著值,并分別進行二值化。因此,BiLLM可以將大模型廣泛量化到1.08位,且不會顯著降低困惑度。KVQuant通過在校準集上離線導出最優數據類型,提出了KV緩存量化的非均勻量化方案。KIVI提出了一種無需調優的2bit KV緩存量化算法,該算法利用單通道量化用于key cache,利用單token量化進行value cache。Li等進行了全面的評估,評估了量化對不同張量類型(包括KV Cache)、各種任務、11種不同的大模型和SOTA量化方法的影響。
Quantization-Aware Training:QAT在模型訓練過程中考慮了量化的影響。通過集成復制量化效果的層,QAT有助于權重適應量化引起的錯誤,從而提高任務性能。然而,訓練大模型通常需要大量的訓練數據和計算資源,這對QAT的實施構成了潛在的瓶頸。因此,目前的研究工作集中在減少訓練數據需求或減輕與QAT實施相關的計算負擔的策略上。為了減少數據需求,LLM-QAT引入了一種無數據的方法,利用原始FP16的大模型生成訓練數據。具體來說,LLM-QAT使用詞表中的每個token作為生成句子的起始標記。基于生成的訓練數據,LLM- QAT應用了基于蒸餾的工作流來訓練量化的LLM,以匹配原始FP16大模型的輸出分布。Norm Tweaking只針對那些在語言類別中占最高比例的語言,做了起始標記的限制選擇。這一策略可以有效地提高量化模型在不同任務上的生成性能。
為了減少計算量,許多方法采用高效參數微調(parameter-efficient tuning,PEFT)策略來加速QAT。QLoRA將大模型的權重量化為4位,隨后在BF16中對每個4位權重矩陣使用LoRA來對量化模型進行微調。QLoRA允許在一個只有30GB內存的GPU上對65B參數的大模型進行有效的微調。QALoRA則提出在QLoRA中加入分組量化。作者觀察到QLoRA中量化參數的數量明顯小于LoRA參數的數量,這會導致量化與低秩自適應之間的不平衡。他們建議,組級別的操作可以通過增加專用于量化的參數數量來解決這個問題。此外,QA-LoRA可以將LoRA項合并到相應的量化權矩陣中。LoftQ指出,在QLoRA中用零初始化LoRA矩陣對于下游任務是低效的。作為一種替代方案,LoftQ建議使用原始FP16權重與量化權重之間差距的奇異值分解(Singular Value Decomposition,SVD)來初始化LoRA矩陣。LoftQ迭代地應用量化和奇異值分解來獲得更精確的原始權重近似值。Norm Tweaking提出在量化后訓練LayerNorm層,并使用知識蒸餾將量化模型的輸出分布與FP16模型的輸出分布進行匹配,達到類似LLM-QAT的效果,同時避免了較高的訓練成本。
對比實驗與分析:本綜述的作者對不同場景下的weight-only quantization技術所產生的加速效果。作者使用了LLaMA-2-7B和LLaMA-2-13B,并使用AWQ將它們的權重量化至4-bit。作者使用NVIDIA A100進行實驗,并使用TensorRT-LLM和LMDeploy這兩個推理框架部署量化后的大模型。然后,作者評估了這些推理框架在不同的輸入序列上實現的加速,這些序列是批大小和上下文長度不同的。prefilling延遲、decoding延遲端到端延遲的加速效果,如表4所示。
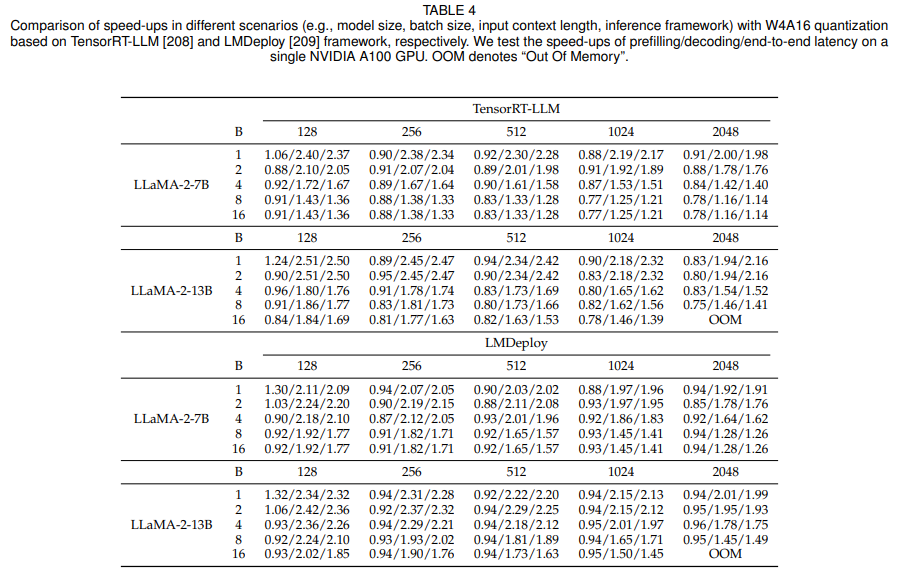
表4:大模型加速效果對比
實驗結果表明:(1)Weight-only quantization可以在decoding階段加速,進而實現端到端的加速。這種提升主要源于從高帶寬內存( High Bandwidth Memory,HBM)更快地加載具有低精度權重張量的量化模型,這種方法顯著減少了內存訪問開銷。(2)對于prefilling階段,weight-only quantization可能會增加延遲。這是因為prefilling階段的瓶頸是計算成本,而不是內存訪問開銷。因此,只量化沒有激活的權重對延遲的影響最小。此外,如圖9所示,weight-only quantization需要將低精度權重去量化到FP16,這會導致額外的計算開銷,從而減慢prefilling。(3)隨著批量大小和輸入長度的增加,weight-only quantization的加速程度逐漸減小。這主要是因為,對于更大的批處理大小和輸入長度,計算成本構成了更大比例的延遲。雖然weight-only quantization主要降低了內存訪問成本,但隨著批量大小和輸入長度增大,計算需求變得更加突出,它對延遲的影響變得不那么顯著。(4)由于內存訪問開銷與模型的參數量規模相關,weight-only quantization為參數規模較大的模型提供了更大的好處。隨著模型的復雜度與尺寸的增長,存儲和訪問權重所需的內存量也會成比例地增加。通過量化模型權重,weight-only quantization可以有效地減少內存占用和內存訪問開銷。
5.2.2 稀疏化(Sparsification)
稀疏化是一種壓縮技術,可以增加數據結構(如模型參數或激活)中零值元素的比例。該方法通過在計算過程中有效地忽略零元素來降低計算復雜度和內存占用。在應用到大模型中時,稀疏化通常應用于權重參數和注意力激活。這導致了權值修剪策略和稀疏注意力機制的發展。
權重修剪(Weight Pruning):權值修剪系統地從模型中去除不太關鍵的權值和結構,旨在減少預填充階段和解碼階段的計算和內存成本,而不會顯著影響性能。這種稀疏化方法分為兩種主要類型:非結構化修剪和結構化修剪。它們的分類基于修剪過程的粒度,如圖10所示。
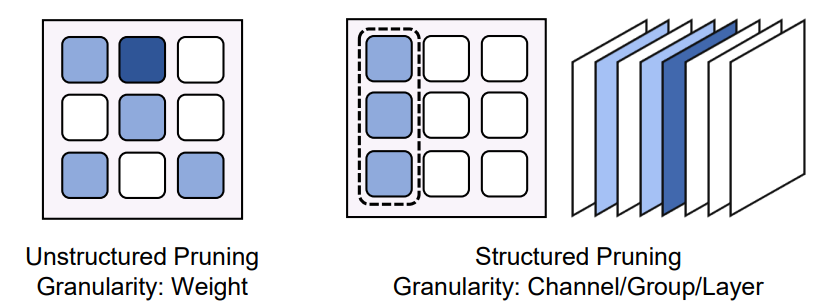
圖10:非結構化修剪和結構化修剪
非結構化修剪以細粒度修剪單個權重值。與結構化修剪相比,它通常在對模型預測影響最小的情況下實現更高的稀疏度。然而,通過非結構化剪枝實現的稀疏模式缺乏高層次的規律性,導致不規則的內存訪問和計算模式。這種不規律會嚴重阻礙硬件加速的潛力,因為現代計算架構針對密集、規則的數據進行了優化。因此,盡管實現了更高的稀疏度級別,但非結構化剪枝在硬件效率和計算加速方面的實際好處可能是有限的。
權值修剪的焦點是修剪標準,包括權重重要性和修剪比例。考慮到大模型的參數規模巨大,提高剪枝效率也至關重要。一個修剪準則是最小化模型的重建損失。SparseGPT是該領域的代表性方法。它遵循OBS的思想,考慮去除每個權值對網絡重構損失的影響。OBS迭代地確定一個剪枝掩模對權值進行剪枝,并重建未剪枝的權值以補償剪枝損失。SparseGPT通過最優部分更新技術克服了OBS的效率瓶頸,設計了一種基于OBS重構誤差的自適應掩碼選擇技術。Prune and Tune通過在修剪過程中使用最少的訓練步驟微調大模型來改進SparseGPT。ISC結合OBS和OBD中的顯著性標準設計了一種新的修剪標準。該算法進一步根據Hessian信息為每一層分配非均勻剪枝比例。BESA通過重構損失的梯度下降學習一個可微的二值掩碼。每一層的剪枝比依次通過最小化重建誤差來確定。另一種流行的修剪標準是基于大小缺定。Wanda提出使用權值與輸入激活范數之間的元素積作為修剪準則。RIA通過使用相對重要性和激活度的度量來聯合考慮權重和激活度,該度量基于其所有連接的權重來評估每個權重元素的重要性。此外,RIA將非結構化稀疏范式轉換為結構化N:M稀疏范式,可以在NVIDIA GPU上獲得實際的加速。OWL側重于確定各層的剪枝比例。它根據激活異常值比率為每一層分配剪枝比率。
與非結構化修剪相比,結構化修剪以更粗的粒度操作,修剪模型中較大的結構單元,例如整個通道或層。這些方法直接促進了在傳統硬件平臺上的推理加速,因為它們與這些系統優化處理的密集、規則的數據范式保持一致。然而,結構化修剪的粗粒度通常會對模型性能產生更明顯的影響。這類修剪標準還強制執行結構化修剪模式。LLM-Prune提出了一種任務不可知的結構化修剪算法。具體來說,它首先根據神經元之間的連接依賴關系識別出大模型中的偶聯結構。然后,它根據設計良好的組級別的修剪度量來決定要刪除哪些結構組。修剪后,進一步提出通過一個高校參數訓練技術,如LoRA來恢復模型性能。 Sheared LLaMA提出將原始大模型修剪為現有預訓練大模型的特定目標架構。此外,它設計了動態批數據加載技術來提升post-training 性能。
ZipLM迭代地識別和修剪結構組件,在損失和運行時間之間進行最壞的權衡。LoRAPrune為帶有LoRA模塊的預訓練大模型提出了結構化修剪框架,以實現基于LoRA的模型的快速推理。它設計了基于LoRA的權值和梯度的由LoRA引導的剪枝準則,并設計了基于該準則去除不重要權值的迭代剪枝方案。LoRAShear還為基于LoRA的大模型設計了一種修剪方法,該方法采用(1)圖算法來識別最小的去除結構,(2)漸進式結構化剪接算法LHSPG,(3)動態知識恢復機制來恢復模型性能。SliceGPT[174]基于RMSNorm操作的計算不變性思想。它提出在每個權值矩陣中對稀疏性進行結構化排列,并對整個行或列進行切片。PLATON[提出通過考慮權重的重要性和不確定性來修剪權重。它使用重要性分數的指數移動平均(Exponential Moving Average,EMA)來估計重要性,對不確定性采用上置信度界(UCB)。SIMPLE提出通過學習相應的稀疏掩碼來修剪注意頭、FFN神經元和隱藏維度。在進行剪枝后,進一步采用知識精餾對剪枝后的模型進行微調,實現性能恢復。
稀疏注意力(Sparse Attention):Transformer多頭自注意力(MHSA)組件中的稀疏注意技術可以策略性地省略某些注意運算,以提高注意運算的計算效率,主要是在預填充階段。這些機制根據對特定輸入數據的依賴程度分為靜態和動態兩類。
靜態稀疏注意力去除了獨立于特定輸入的激活值。這些方法預先確定了稀疏的注意力掩碼,并在推理過程中將其強加于注意力矩陣。過去的研究工作結合了不同的稀疏模式來保留每個注意力矩陣中最基本的元素。如圖11(a)所示,最常見的稀疏注意力模式是局部和全局注意模式。本地注意力范式捕獲每個token的本地上下文,并在每個token周圍設置固定大小的窗口注意。全局注意力范式通過計算和關注整個序列中的所有token來捕獲特定token與所有其他token之間的相關性。利用全局模式可以消除存儲未使用的token的KV對的需要,從而減少了解碼階段的內存訪問成本和內存使用。Sparse Transformer將這些模式結合起來,用本地模式捕獲本地上下文,然后每隔幾個單詞就用全局模式聚合信息。StreamingLLM只對前幾個token應用本地模式和全局模式。結果表明,這種全局模式作為注意力漕,保持了對初始標記的強注意得分。它有助于大模型推廣到無限輸入序列長度。Bigbird也使用隨機模式,其中所有token都參加一組隨機token。證明了局部模式、全局模式和隨機模式的組合可以封裝所有連續序列到序列的函數,并證實了其圖靈完備性。如圖11(b)所示,Longformer還引入了膨脹的滑動窗口模式。它類似于擴張的CNN,使滑動窗口“擴張”以增加接受野。為了使模型適應稀疏設置,Structured sparse Attention提倡一種熵感知的訓練方法,將高概率的注意力值聚集到更密集的區域中。與以往手工設計稀疏模式的研究不同,SemSA使用基于梯度的分析來識別重要的注意模式,并自動優化注意密度分布,進一步提高模型效率。
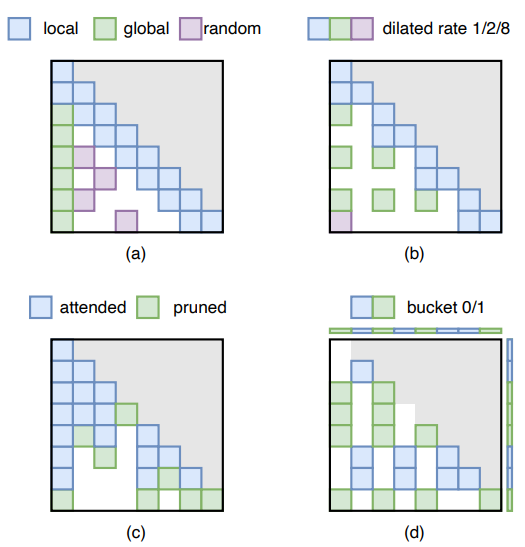
圖11:不同的稀疏注意力掩碼舉例
相比之下,動態稀疏注意力根據不同的輸入自適應地消除激活值,通過實時監測神經元的激活值來繞過對神經元的影響可以忽略的計算,從而實現修剪。大多數動態稀疏注意方法采用動態token修剪方法,如圖11(c)所示。Spatten、SeqBoat和Adaptive Sparse Attention利用語言結構的固有冗余提出動態標記級修剪策略。Spatten通過匯總注意力矩陣列來評估每個單詞的累積重要性,并在后面的層中從輸入中對具有最小累積重要性的token進行修剪。SeqBoat訓練了一個線性狀態空間模型(State Space Model, SSM),該模型帶有一個稀疏的sigmoid函數,以確定每個注意力頭需要修剪哪個token。Spatten和SeqBoat都對整個輸入的無信息的token進行了修剪。自適應稀疏注意力在生成過程中逐漸修剪token。它去除了上下文中,在未來生成不再需要的部分。
除了動態token修剪,動態注意力修剪技術也被應用。如圖11(d)所示,這些方法不是修剪某些token的所有注意力值,而是根據輸入動態地修剪注意力的選擇部分。在相關工作中,一個較為不錯的方法是動態地將輸入token分成組,稱為桶,并策略性地省略駐留在單獨桶中的token的注意力計算。這些方法的重點在于如何將相關的token聚類在一起,來促進它們之間的注意力計算,從而提高效率。Reformer利用位置敏感的哈希來將共享相同哈希碼的key和query聚集到同一個桶中。在此之后,Sparse Flash Attention引入了專門針對這種基于哈希的稀疏注意力機制進行優化的GPU內核,進一步提高了計算效率。同時,Routing Transformer采用球形k-means聚類算法將token聚合到桶中,優化了注意力計算的選擇過程。Sparse Sinkhorn Attention采用學習排序網絡將key與其相關的query桶對齊,確保僅在相應的query和key對之間計算注意力。與桶級操作不同,H2O引入了token級動態注意力修剪機制。它將靜態本地注意力與當前query和一組動態標識的key token之間的動態計算結合起來,稱作heavy-hitters(H2)。這些 heavy-hitters通過移除策略進行動態調整,該策略旨在在每個生成步驟中刪除最不重要的key,從而有效地管理heavy-hitter集的大小和相關性。
此外,將每個token視為圖節點,將token之間的注意力視為邊,可以擴展靜態稀疏注意力的視角。原始的全注意力機制等同于一個均勻最短路徑距離為1的完整圖。稀疏注意力通過其隨機掩碼引入隨機邊,有效地將任意兩個節點之間的最短路徑距離減小到,從而保持類似于完全注意的高效信息流。Diffuser利用圖論的視角,通過多跳token關聯來擴展稀疏注意的接受場。它還從擴展圖屬性中獲得靈感,以設計更好的稀疏模式,以近似全注意力的信息流。
除了注意力級和token級的稀疏性之外,注意力修剪的范圍擴展到各種粒度。Spatten還將修剪從token粒度擴展到注意力頭粒度,消除了不必要的注意力頭的計算,以進一步減少計算和內存需求。
5.2.3 架構優化(Structure Optimization)
架構優化的目標是重新定義模型的體系結構或者架構,以提高模型效率和性能之間的平衡。相關工作中有兩種突出的技術:神經結構搜索(Neural Architecture Search, NAS)和低秩分解(Low Rank Factorization, LRF)。
神經結構搜索(Neural Architecture Search):神經架構搜索(Neural Architecture Search, NAS)旨在自動搜索在效率和性能之間達到最佳平衡的最優神經架構。AutoTinyBERT利用one-shot神經架構搜索(NAS)來發現Transformer架構的超參數。值得注意的是,它引入了一種引人注目的批處理訓練方法來訓練超級預訓練語言模型(SuperPLM),隨后使用進化算法來識別最優子模型。NAS-BERT使用一些創新技術,如塊級別搜索、搜索空間修剪和性能逼近,在傳統的自監督預訓練任務上訓練大型超級網絡。這種方法允許NAS-BERT有效地應用于各種下游任務,而不需要大量的重新訓練。通過NAS進行結構剪枝將結構剪枝作為一個多目標NAS問題,通過一次性的NAS方法進行解決。LiteTransformerSearch提出使用不需要訓練的指標,例如參數的數量作為代理指標來指導搜索。這種方法可以有效地探索和選擇最優的體系結構,而不需要在搜索階段進行實際的訓練。AutoDistil提出了一種完全與任務無關的few-shot NAS算法,該算法具有三種主要技術:搜索空間劃分、與任務無關的SuperLM訓練和與任務無關的搜索。這種方法的目的是促進跨各種任務的高效體系結構發現,并減少特定于任務的調整。通常,NAS算法需要評估每個采樣架構的性能,這可能會產生大量的訓練成本。因此,這些技術在應用于大模型時具有挑戰性。
低秩分解(Low Rank Factorization):低秩分解(LRF)或低秩分解(Low Rank Decomposition)的目的是用兩個低秩矩陣和近似一個矩陣:
其中比和小得多。這樣,LRF可以減少內存使用,提高計算效率。此外,在大模型推理的解碼階段,內存訪問成本是解碼速度的瓶頸。因此,LRF可以減少需要加載的參數數量,從而加快解碼速度。LoRD顯示了壓縮大模型的潛力,而不會通過LRF大幅降低性能。具體來說,采用奇異值分解(SVD)對權重矩陣進行因式分解,成功地將一個包含16B個參數的大模型壓縮為12.3B,性能小幅度下降。TensorGPT引入了一種使用Tensor-Train Decomposition來壓縮embedding層的方法。每個token embedding都被視為矩陣乘積狀態(Matrix Product State, MPS),并以分布式方式高效計算。LoSparse結合了LRF和權值剪枝在LLM壓縮中的優點。通過利用低秩近似,LoSparse降低了直接進行模型修剪通常會丟失太多表達神經元的風險。LPLR和ZeroQuant-V2都提出了對權矩陣進行LRF和量化同時壓縮的方法。DSFormer提出將權重矩陣分解為半結構化稀疏矩陣與一個小型密集型矩陣的乘積。ASVD設計了一個激活感知的奇異值分解方法。該方法包括在應用奇異值分解進行矩陣分解之前,根據激活分布縮放權重矩陣。ASVD還包括通過一個搜索進程確定每個層的合適的截斷秩。
5.2.4 知識蒸餾(Knowledge Distillation)
知識蒸餾(Knowledge Distillation, KD)是一種成熟的模型壓縮技術,其中來自大型模型(稱為teacher模型)的知識被轉移到較小的模型(稱為student模型)。在大模型的背景下,KD使用原始的大模型作為teacher模型來提煉較小的大模型。目前許多研究都集中在如何有效地將大模型的各種能力轉移到更小的模型上。在這個領域,方法可以分為兩種主要類型:白盒KD和黑盒KD(如圖12所示)。
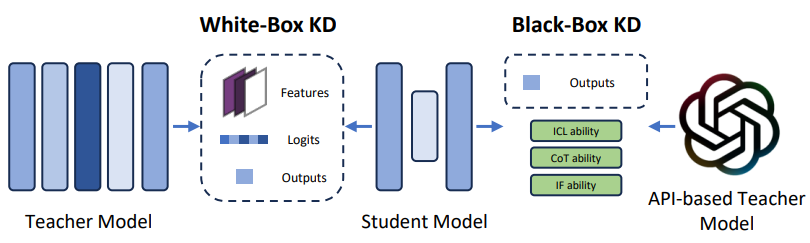
圖12:白盒KD(左)與黑盒KD(右)示意圖
白盒KD(White-box KD):白盒KD指的是利用對teacher模型的結構和參數的訪問的蒸餾方法。這些方法使KD能夠有效地利用teacher模型的中間特征和輸出概率來增強student模型的性能。MiniLLM采用標準白盒KD方法,但將正向Kullback-Leibler divergence(KLD)替換為反向KLD。GKD引入了對 on-policy數據的使用,其中包括由student模型本身生成的輸出序列,以進一步蒸餾學生模型。該方法側重于使用這些策略數據來對齊teacher和student模型之間的輸出概率。TED提出了一種任務感知的層級別的方法,包括結合額外的檢索分層KD方法。這種方法包括在teacher和student模型的每一層之后添加過濾器,訓練這些特定任務的過濾器,然后凍結teacher模型的過濾器,在訓練student過濾器以使其輸出特征與相應的teacher過濾器對齊時。MiniMoE通過使用混合專家(MoE)模型作為student模型來緩解能力差距。對于新出現的實體,預訓練語言模型可能缺乏最新的信息。為了解決這個問題,一種解決方案是將額外的檢索文本合并到提示中,盡管這會增加推理成本。另外,KPTD通過知識蒸餾將知識從實體定義轉移到大模型參數。該方法生成一個基于實體定義的傳輸集,并提取student模型,以便將輸出分布與基于這些定義的teacher模型相匹配。
黑盒KD(Black-box KD):黑盒KD是指teacher模型的結構和參數不可獲取的知識蒸餾方法。通常,黑箱KD只使用teacher模型得到的最終結果來蒸餾student模型。在大模型領域,黑箱KD主要引導student模型學習大模型的泛化能力和涌現能力,包括InContext Learning (ICL)能力、 思維鏈(Chain-of-Thought, CoT)推理能力和Instruction Following (IF)能力。在ICL能力方面,Multitask-ICT引入了上下文學習蒸餾(in-context learning distillation)來轉移大模型的多任務few-shot能力,同時利用上下文學習和語言建模能力。MCKD觀察到,從通過語境學習得到的teacher模型中提煉出來的student模型,在看不見的輸入prompt上往往表現優異。基于這一觀察,MCKD設計了一個多階段蒸餾范式,其中使用前階段的student模型為后續階段生成蒸餾數據,從而提高了蒸餾方法的有效性。為了提煉思維鏈(CoT)推理能力,諸如 Distilling Step-by-Step、SCoTD、CoT prompt、MCC-KD和Fine-tune-CoT等幾種技術提出了提煉方法,將從大模型中提取的反應和基本原理結合起來訓練student模型。 Socratic CoT也將推理能力轉移到較小的模型。具體來說,它對一對student模型進行了微調,即問題生成(QG)模型和問題回答(QA)模型。QG模型被訓練成基于輸入問題生成中間問題,指導QA模型生成最終的回答。PaD觀察到錯誤的推理(即正確的最終答案但錯誤的推理步驟)可能對student模型有害。為了解決這個問題,PaD建議生成合成程序用于推理問題,然后由附加的解釋器自動檢查。這種方法有助于去除帶有錯誤推理的蒸餾數據,提高student模型訓練數據的質量。
5.2.5 動態推理
動態推理涉及在推理過程中自適應選擇模型子結構,其以輸入數據為條件。此小節重點介紹early exiting的技術,這些技術使大模型能夠根據特定的樣本或token在不同的模型層停止其推理。值得注意的是,雖然MoE技術(在第5.1.1節中討論)也會在推理過程中調整模型結構,但它們通常涉及昂貴的預訓練成本。相比之下,這些技術只需要訓練一個小模塊來確定何時結束推理。本文將此類研究分為兩大類:樣本級別的early exiting和token級別的early exiting(如圖13所示)。
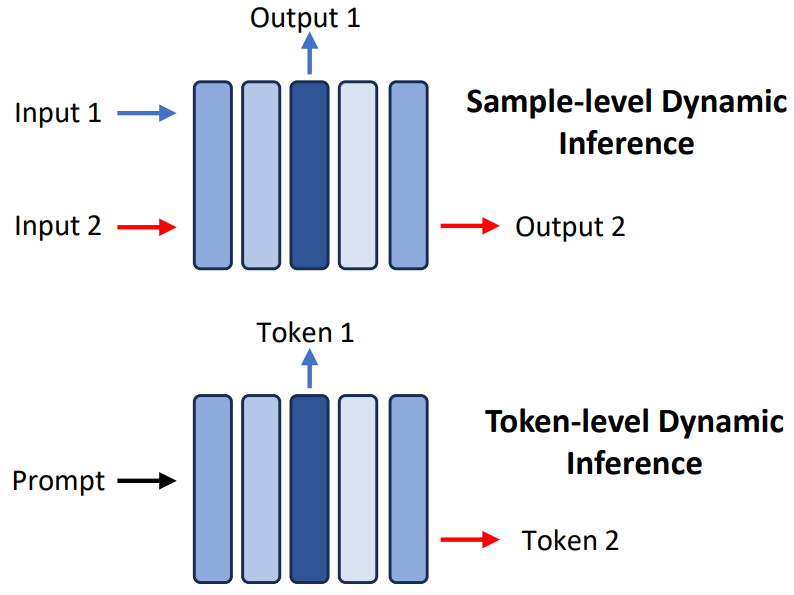
圖13:token級別和樣本級別的動態推理示意圖
樣本級別:樣本級別的early exiting技術側重于確定用于單個輸入樣本的大模型的最佳大小和結構。一種常見的方法是在每一層之后使用額外的模塊來擴展大模型,利用這些模塊來決定是否在特定層終止推理。FastBERT, DeeBERT, MP和MPEE直接訓練這些模塊來根據當前層的特征做出決策(例如,輸出0繼續或輸出1停止)。Global Past-Future Early Exit提出了一種方法,利用來自前一層和后一層的語言信息豐富這些模塊的輸入。考慮到在推理過程中不能直接訪問未來層的特征,論文訓練了一個簡單的前饋層來估計這些未來特征。PABEE訓練模塊來作為直接預測的輸出頭,建議在預測保持一致時終止推理。HASHEE采用了一種非參數決策方法,該方法基于相似樣本應在同一層退出推理的假設。
Token級別:在大模型推理的decodig階段,依次生成token,token級別的early exiting技術旨在優化用于每個輸出token的大模型的大小和結構。CALM在每個Transformer層之后引入early exit分類器,訓練它們輸出置信度分數,以確定是否在特定層停止推理。值得注意的是,在self-attention模塊中,計算每層當前token的特征依賴于同一層中所有先前token的特征(即KV cache)。為了解決由于先前token early exit而導致KV cache丟失的問題,CALM建議直接將該特征從現有層復制到后續層,實驗結果顯示只有輕微的性能下降。SkipDecode解決了先前早期存在的方法的局限性,這些方法阻礙了它們對批處理推理和KV cache的適用性,從而限制了實際的加速增益。對于批處理推理,SkipDecode為批處理中的所有token提出了一個統一的退出點。對于KV cache,SkipDecode確保了exit point的單調減少,以防止KV緩存的重新計算,從而促進了推理過程中的效率提高。
5.3 認識,建議和未來方向
在高效結構設計方面,尋找替代Transformer的結構是一個新興的研究領域。例如,Mamba、RWKV及其各自的變種在各種任務中表現出了競爭力,近年來引起了越來越多的關注。然而,調查這些非Transformer模型與Transformer模型相比是否會表現出某些缺點仍然是相關的。同時,探索非transformer架構與注意力操作的集成是未來另一個有希望的研究方向。
在模型壓縮領域,量化作為在大模型部署中使用的主要方法脫穎而出,主要是由于兩個關鍵因素。首先,量化提供了一種方便的壓縮大模型的方法。例如,使用Post-Training Quantization(PTQ)方法可以在幾分鐘內將具有70億個參數的大模型的參數數分鐘內減少到壓縮形式。其次,量化具有實現內存消耗和推理速度大幅降低的潛力,同時只引入了很小的性能折損。對于許多實際應用,這種折損通常被認為是可以接受的。然而,值得注意的是,量化仍然可能會損害大模型的某些突發能力,例如自校準或多步推理。此外,在處理長上下文等特定場景中,量化可能導致顯著的性能下降。因此,在這些特殊情況下,需要仔細選擇適當的量化方法來減輕這種退化的風險。大量文獻研究了稀疏注意力技術在長上下文處理中的應用。例如,最近的一項代表性工作StreamingLLM僅通過恢復幾個注意力匯token就可以處理400萬個token。盡管如此,這些方法往往會犧牲關鍵信息,從而導致性能下降。因此,在有效管理長上下文的同時保留基本信息的挑戰仍然是未來探索的一個重要領域。至于權值修剪技術,LLM-KICK指出,即使在相對較低的稀疏度比下,當前最先進的(SOTA)方法也會出現相當大的性能下降。因此,開發有效的權值修剪方法來保持大模型性能仍然是一個新興和關鍵的研究方向。
模型結構的優化通常涉及使用神經結構搜索(NAS),這通常需要大量的計算資源,這對其在壓縮大模型中的實際應用構成了潛在的障礙。因此,相關研究采用自動結構優化進行大模型壓縮的可行性值得進一步探索。此外,像低秩分解(LRF)這樣的技術在壓縮比和任務性能之間實現最佳平衡仍然是一個挑戰。例如,ASVD在不影響大模型推理能力的情況下,只能實現適度的10%到20%的壓縮比。
除了采用單獨的模型壓縮技術外,一些研究還探索了不同方法的組合來壓縮大模型,利用各自的優勢來提高效率。例如,MPOE將權重矩陣分解專門應用于基于MoE的大模型中的專家前饋網絡(FFNs),目的是進一步降低內存需求。LLM-MQ利用權值稀疏性技術在模型量化過程中保護權值異常值,從而最大限度地減少量化誤差。LPLR側重于量化低秩分解權重矩陣,以進一步降低大模型推理過程中的內存占用和內存訪問成本。此外,LoSparse將低秩分解與權值剪枝相結合,利用剪枝增強低秩近似的多樣性,同時利用低秩分解保留重要權值,防止關鍵信息丟失。這些方法強調了集成多種壓縮技術以更好地優化大模型的潛力。
6 系統級別優化
大模型推理的系統級優化主要涉及增強模型前向傳遞。考慮到大模型的計算圖,存在多個算子,其中注意力算子和線性算子占據了大部分的運行時間。如2.3節所述,系統級優化主要考慮大模型中注意算子和解碼方法的獨特特征。特別是,為了解決大模型解碼方法的具體問題,線性算子需要特殊的平鋪設計,推測解碼方法也被提出以提高利用率。此外,在在線服務的上下文中,請求通常來自多個用戶。因此,除了前面討論的優化之外,在線服務還面臨著與異步請求引起的內存、批處理和調度相關的挑戰。
6.1 推理引擎
目前對推理引擎的優化主要在于加速模型向前推理過程。對大模型推理中的主要算子和計算圖進行了高度優化。此外,為了在不降低性能的前提下提高推理速度,推測解碼技術也被提出。
6.1.1 圖和計算優化
運行時間分析:通過HuggingFace,作者用不同的模型和上下文長度來分析推理運行時間。圖15的分析結果表明,注意力計算和線性計算占據了運行時間的絕大部分,它們通常超過推理持續時間的75%。因此,大部分優化工作都致力于提高兩個操作的性能。此外,有多個操作符占用了一小部分運行時間,這使得操作符的執行時間支離破碎,增加了CPU端的內核啟動成本。為了解決這個問題,在圖計算級別,當前優化的推理引擎實現了高度融合的算子。
注意力計算優化:標準的注意力計算(例如,使用Pytorch)包含矩陣Q與矩陣(K)的乘法,這導致時間和空間復雜度與輸入序列長度呈現二次增長。如圖15所示,注意力計算操作的時間占比隨著上下文長度的增加而增加。這意味著對內存大小和計算能力的要求很高,特別是在處理長序列時。為了解決GPU上標準注意力計算的計算和內存開銷,定制化注意力計算是必不可少的。FlashAttention將整個注意力操作融合為一個單一的、內存高效的操作,以減輕內存訪問開銷。輸入矩陣(Q, K, V)和注意力矩陣被平鋪成多個塊,從而消除了完整數據加載的需要。FlashDecoding建立在Flash Attention的基礎上,旨在最大限度地提高解碼的計算并行性。由于譯碼方法的應用,Q矩陣在decoding過程中會退化為一批向量,如果并行度僅限于batch大小維度,則很難填充計算單元。FlashDecoding通過在序列維度上引入并行計算來解決這個問題。雖然這會給softmax計算帶來一些同步開銷,但它會顯著提高并行性,特別是對于小批量大小和長序列。隨后的工作FlashDecoding++觀察到,在之前的工作中,softmax內的最大值僅作為防止數據溢出的比例因子。然而,動態最大值會導致顯著的同步開銷。此外,大量實驗表明,在典型的大模型(如Llama2, ChatGLM)中,超過99.99%的softmax輸入在一定范圍內。因此,FlashDecoding++提出基于統計數據提前確定比例因子。這消除了softmax計算中的同步開銷,使后續操作能夠在softmax計算的同時并行執行。
線性計算優化:線性算子在大模型推理、特征投影和前饋神經網絡(FFN)中發揮著關鍵作用。在傳統神經網絡中,線性算子可以抽象為通用矩陣-矩陣乘法(General Matrix-Matrix Multiplication, GEMM)運算。然而,對于大模型,decoding方法的應用導致維度的明顯降低,與傳統的GEMM工作負載不同。傳統GEMM的底層實現得到了高度優化,主流大模型推理框架(例如,DeepSpeed , vLLM, OpenPPL等)主要調用cuBLAS為線性算子提供的GEMM API接口。
如果沒有針對降低維數的GEMM明確定制的實現,decoding過程中的線性計算將會效率低下。在最新版本的TensorRT-LLM中可以觀察到解決該問題的issue。它引入了專用的通用矩陣向量乘法(General Matrix-Vector Multiplication, GEMV)實現,潛在地提高了decoding步驟的效率。最近的研究FlashDecoding++做了進一步的改進,在解碼步驟中處理小批量數據時,解決了cuBLAS和CUTLASS庫的低效率問題。該研究的作者首先引入了FlatGEMM操作的概念,以高度降低的維度(FlashDecoding++中的維數< 8)來表示GEMM的工作負載。由于FlatGEMM具有新的計算特性,傳統GEMM的平鋪策略需要進行修改。作者觀察到,隨著工作負載的變化,存在兩個問題:低并行性和內存訪問瓶頸。
為了解決這些問題,FlashDecoding++采用了細粒度平鋪策略來提高并行性,并利用雙緩沖技術來隱藏內存訪問延遲。此外,當前經典大模型(例如,Llama2, ChatGLM)中的線性操作通常具有固定的形狀,FlashDecoding++建立了啟發式選擇機制。這個機制根據輸入大小在不同的線性運算符之間進行動態地選擇轉換。這些選項包括FastGEMV、FlatGEMM和由cuBLAS庫提供的GEMM。這種方法確保為給定的線性工作負載選擇最有效的計算操作,從而可能導致更好的端到端性能。
近年來,應用MoE FFN來增強模型能力已成為大模型研究的一種趨勢。這種模型結構也對算子優化提出了新的要求。如圖15所示,在具有MoE FFN的Mixtral模型中,由于HuggingFace實現中未優化FFN計算,線性算子在運行時占主導地位。此外,Mixtral采用了GQA注意結構,其降低了注意力算子的運行時間比例,進一步指出了對優化FFN層迫切需要。MegaBlocks是第一個針對MoE FFN層優化計算的算法。該工作將MoE FFN計算制定為塊稀疏操作,并提出了用于加速的定制GPU內核。MegaBlocks專注于MoE模型的有效訓練,因此忽略了推理的特征(例如,解碼方法)。現有框架正在努力優化MoE FFN推理階段的計算。vLLM的官方在Triton中集成了MoE FFN的融合內核,無縫地消除了索引開銷。
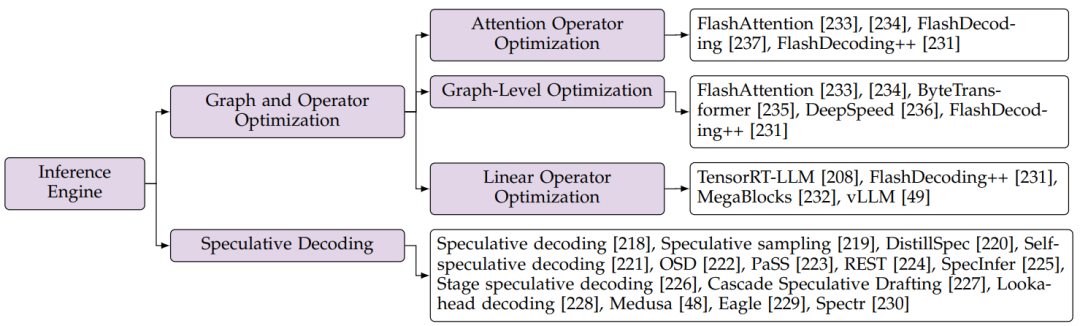
圖14:大模型推理引擎優化分類
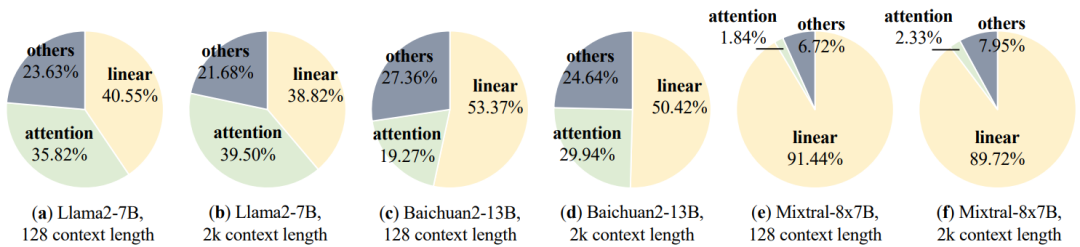
圖15:多個大模型的推理運行時間分析
圖級別的優化:核融合作為一種流行的圖級優化脫穎而出,因為它能夠減少運行時間。應用核融合有三個主要優點:(1)減少內存訪問。融合內核從本質上消除了中間結果的內存訪問,減輕了計算操作的內存瓶頸。(2)減輕內核啟動開銷。對于一些輕量級操作(如殘差add),內核啟動時間占據了大部分延遲,內核融合減少了單個內核的啟動。(3)增強并行性。對于那些沒有數據依賴的運算符,當單個內核執行無法填充硬件容量時,通過融合實現內核并行是有益的。
核融合技術被證明對大模型推理是有效的,具有上述所有優點。FlashAttention將注意力運算符表述成一個單一的內核,消除了訪問注意力結果的開銷。基于注意力算子是內存有限的這一事實,內存訪問的減少能有效地轉化為運行時加速。ByteTransformer和DeepSpeed提出將包括殘差加法、層模和激活函數在內的輕量級算子融合到前線性算子中,以減少內核啟動開銷。
和DeepSpeed[236]提出將包括殘差add、layernorm和激活函數在內的輕量級算子融合到前面的線性算子中,以減少內核啟動開銷。因此,這些輕量級操作符在時間軸上消失,幾乎沒有額外的延遲。此外,還采用核融合來提高大模型推理的利用率。Q、K和V矩陣的投影變換原本是三個單獨的線性運算,并融合成一個線性運算符部署在現代GPU上。目前,核融合技術已經應用于大模型推理實踐中,高度優化的推理引擎在運行時只使用少數融合核。例如,在FlashDecoding++實現中,一個transformer塊僅集成了七個融合的內核。利用上述運算符和內核融合優化,FlashDecoding++實現了在HuggingFace高達4.86倍的加速。
6.1.2 推測解碼
推測解碼(如投機采樣)是一種用于自回歸大模型的創新解碼技術,旨在提高解碼效率,同時不影響輸出的質量。這種方法的核心思想包括使用一個較小的模型(稱為草稿模型)來有效地預測幾個后續token,然后使用目標大模型并行驗證這些預測。該方法旨在使大模型能夠在單個推理通常所需的時間范圍內生成多個token。圖16顯示了傳統自回歸解碼方法與推測解碼方法的比較。理論上,推測解碼方法包括兩個步驟:
1)草稿構建:采用草稿模型,以并行或自回歸的方式生成多個后續token,即Draft token。2)草案驗證:利用目標模型在單個大模型推理步驟中計算所有草稿token的條件概率,隨后依次確定每個草稿token的接受程度。接受率表示每個推理步驟接受的草稿token的平均數量,是評估推測解碼算法性能的關鍵指標。
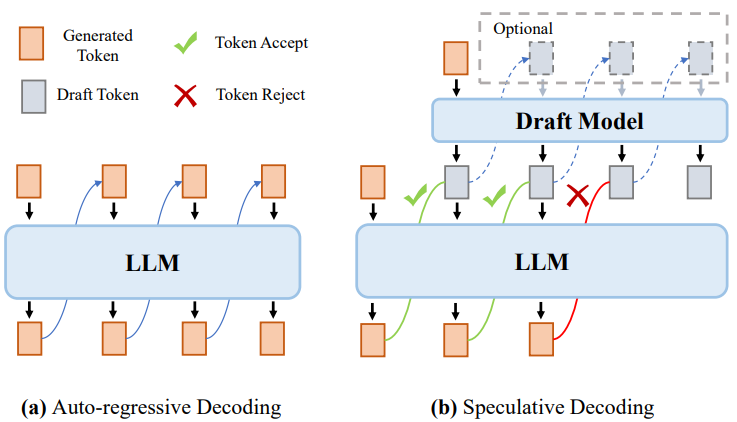
圖16:自回歸解碼(a)和推測解碼(b)對比
推測解碼確保了輸出與自回歸解碼方法的質量對等。傳統解碼技術主要使用兩個采樣方法:greedy sampling和 nucleus sampling。greedy sampling涉及在每個解碼步驟中選擇概率最高的令牌來生成特定的輸出序列。推測解碼的最初工作,被稱為Blockwise Parallel Decoding,旨在確保草草稿token與通過greedy sampling的token實現精確匹配,從而保持輸出令牌等價。相比之下,nucleus sampling涉及從概率分布中抽樣token,每次運行都會產生不同的token序列。這種多樣性使得nucleus sampling很受歡迎。為了在推測解碼框架內容納nucleus sampling,已經提出了投機采樣技術。投機采樣保持輸出分布不變,與nucleus sampling的概率性質一致,以產生不同的標記序列。形式上,給定一個token序列和一個草稿token序列,投機采樣策略以以下概率接受第i個草稿token:
其中和分別代表來自目標大模型和草稿模型的概率分布。如果第個token被接受,它設定為。另外,它退出草稿token的驗證,并從下面的分布中進行的重采樣:
基于投機采樣,出現了幾種變體,旨在驗證多個草稿token序列。值得注意的是,在這種情況下,token tree verfier已成為一種廣泛采用的驗證策略。這種方法利用草稿token集的樹狀結構表示,并采用樹注意力機制來有效地執行驗證過程。
在推測解碼方法中,草稿token的接受率受到草稿模型的輸出分布與原始大模型的輸出分布的一致程度的顯著影響。因此,大量的研究工作都是為了改進草稿模型。DistillSpec直接從目標大模型中提取較小的草稿模型。SSD包括從目標大模型中自動識別子模型(模型層的子集)作為草稿模型,從而消除了對草稿模型進行單獨訓練的需要。OSD動態調整草稿模型的輸出分布,以匹配在線大模型服務中的用戶查詢分布。它通過監視來自大模型的被拒絕的草稿token,并使用該數據通過蒸餾來改進草稿模型來實現這一點。PaSS提出利用目標大模型本身作為草稿模型,將可訓練的token(look -ahead token)作為輸入序列,以同時生成后續token。REST引入了一種基于檢索的推測解碼方法,采用非參數檢索數據存儲作為草稿模型。SpecInfer引入了一種集體提升調優技術來對齊一組草稿模型的輸出分布通過目標大模型。Lookahead decoding 包含大模型生成并行的生成n-grams來生成草稿token。Medusa對大模型的幾個頭進行微調,專門用于生成后續的草稿token。Eagle采用一種稱為自回歸頭的輕量級Transformer層,以自回歸的方式生成草稿token,將目標大模型的豐富上下文特征集成到草稿模型的輸入中。
另一項研究側重于設計更有效的草稿構建策略。傳統的方法通常產生單一的草稿token序列,這對通過驗證提出了挑戰。對此,Spectr主張生成多個草稿token序列,并采用k-sequential草稿選擇技術并發驗證k個序列。該方法利用推測抽樣,確保輸出分布的一致性。類似地,SpecInfer采用了類似的方法。然而,與Spectr不同的是,SpecInfer將草稿token序列合并到一個“token tree”中,并引入了一個用于驗證的樹形注意力機制。這種策略被稱為“token tree verifier”。由于其有效性,token tree verifier在眾多推測解碼算法中被廣泛采用。除了這些努力之外,Stage Speculative Decoding和Cascade Speculative Drafting(CS Drafting)建議通過將投機解碼直接集成到token生成過程中來加速草稿構建。
對比實驗與分析:論文作者通過實驗來評估推測解碼方法的加速性能。具體來說,作者對該領域的研究進行了全面的回顧,并選擇了其中6個已經開源的代碼進行研究,分別是:Speculative Decoding (SpD)、Lookahead Decoding (LADE)、REST、Self-speculative Decoding (SSD)、Medusa和Eagle。對于評估數據集,使用Vicuna-80對上述方法進行評估,該數據集包含80個問題,分為10類。這80個問題的平均結果作為輸出。對于目標大模型,作者采用了五個主流的開源大模型,分別是Vicuna-7B-V1.3、Vicuna-13B-V1.3、Vicuna-33B-V1.3、LLaMA-2-7B和LLaMA-2-13B。作者展示了這5個大模型的評估指標范圍。對于草稿模型,作者對SpD采用了兩個個訓練好的草稿模型,即LLaMA-68M和LLaMA-160M。對于其他推測解碼方法,作者遵循它們提出的草稿構建方法和使用他們提供的權重。在評價指標方面,作者使用接受率和加速率,接受率是指接受token數與生成步數之比,加速比是指在確定輸出總長度時,原始自回歸解碼的延遲與推測解碼的延遲之比。
表5提供了各種推測解碼方法的比較,突出了幾個關鍵觀察結果:(1) Eagle表現出優異的性能,在多個大模型上實現了3.47~3.72倍的端到端加速。為了理解它的成功,作者對Eagle的深入分析揭示了兩個關鍵因素。首先,Eagle采用自回歸方法來解碼草稿token,直接利用先前生成的token的信息。其次,Eagle集成了原始大模型和草案模型的先前token的豐富特征,以提高下一個草稿token生成的準確性。(2) token tree verifier被證明在提升投機采樣方法的性能中是有效的。(3)這些方法實現的端到端加速往往低于接受率。這種差異是由于與草稿模型相關的生成成本不可忽視的實際考慮而產生的。
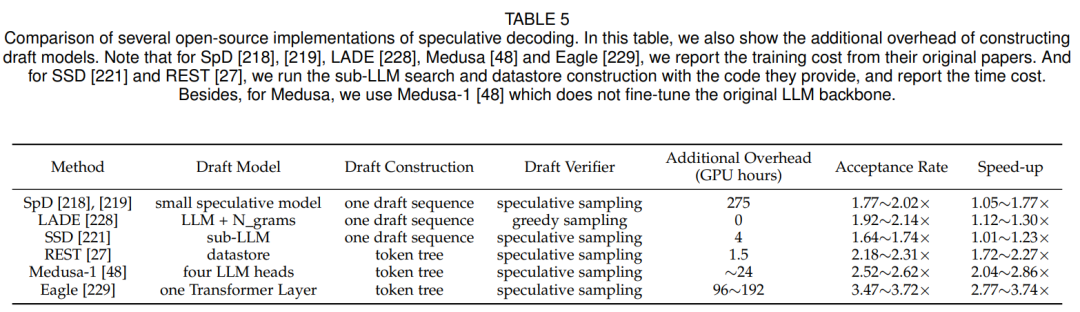
表5:實驗結果
6.2 推理服務系統
推理服務系統的優化主要在于提高處理異步請求的效率。優化了內存管理以容納更多的請求,并集成了高效的批處理和調度策略以提高系統吞吐量。此外,提出了針對分布式系統的優化方法,以充分利用分布式計算資源。
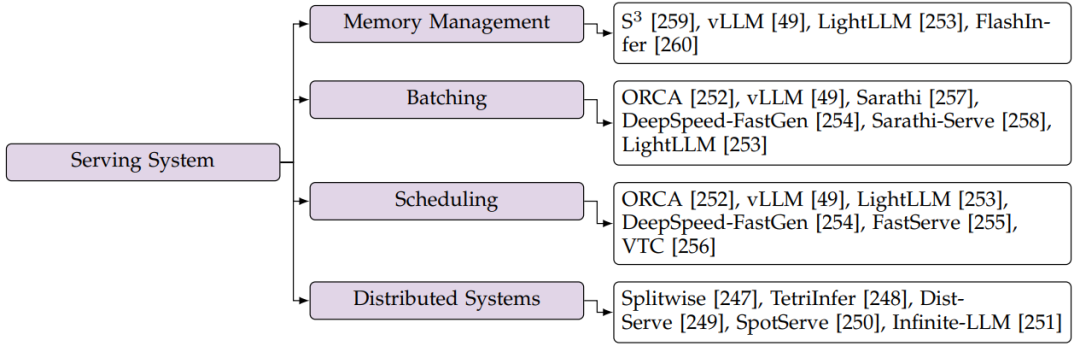
圖17:推理服務系統分類圖
6.2.1內存管理
在大模型服務中,KV緩存的存儲決定了內存的使用,特別是當上下文長度很長時(參見第2.3節)。由于生成長度不確定,提前分配KV cache存儲空間很難。早期的實現通常根據每個請求的預設最大長度預先分配存儲空間。但是,在終止請求生成的時,這種方法會導致存儲資源的大量浪費。為了解決這個問題,為了減少預分配空間的浪費,提出了為每個請求預測生成長度的上界。
但是,當不存在如此大的連續空間時,靜態的KV緩存分配方式仍然是失敗的。為了應對碎片化存儲,vLLM提出以操作系統的樣式,以分頁的方式存儲KV緩存。vLLM首先分配盡可能大的內存空間,并將其平均劃分為多個物理塊。當請求來臨時,vLLM以不連續的方式動態地將生成的KV緩存映射到預分配的物理塊。通過這種方式,vLLM顯著減少了存儲碎片,并在大模型服務中實現了更高的吞吐量。在vLLM的基礎上,LightLLM使用了更細粒度的KV緩存存儲,減少了不規則邊界產生的浪費。LightLLM將token的KV緩存作為一個單元來處理,而不是一個塊,因此生成的KV緩存總是使預分配的空間飽和。
當前優化的推理服務系統通常采用這種分頁方式來管理KV緩存存儲,從而減少冗余KV緩存的浪費。然而,分頁存儲導致注意力操作中的內存訪問不規則。對于使用分頁KV緩存的注意力算子,這就需要考慮KV緩存的虛擬地址空間與其對應的物理地址空間之間的映射關系。為了提高注意力算子的計算效率,必須對KV緩存的加載模式進行調整,以方便連續存儲器訪問。例如,在vLLM的PagedAttention中,對于K cache,head大小維度的存儲結構為16字節的連續向量,而FlashInfer為KV緩存編排了各種數據布局,并伴隨著適當設計的內存訪問方案。注意力算子的優化與頁面KV緩存存儲的結合仍然是推理服務系統發展中的一個前沿挑戰。
6.2.2 連續批處理
批處理中的請求長度可能不同,當較短的請求完成而較長的請求仍在運行時,會導致利用率較低。由于服務場景中的請求具有異步特性,因此緩解這種低利用率的時間段是有可能的。基于此,連續批處理技術被提出,以便在一些舊請求完成后對新請求進行批處理。ORCA是在大模型服務端第一個這樣做的工作。
每個請求的計算包含多個迭代,每個迭代表示預填充步驟或解碼步驟。作者建議可以在迭代級別對不同的請求進行批處理。此工作在線性操作符中實現迭代級批處理,在序列維度中將不同的請求連接在一起。因此,與完成的請求相對應的備用存儲和計算資源被及時釋放。繼ORCA之后,vLLM將該技術擴展到注意力計算,使不同KV緩存長度的請求能夠批處理在一起。Sarathi、DeepSpeed-FastGen和SarathiServe進一步引入了一種split-and-fuse方法,將預填充請求和解碼請求批處理在一起。具體來說,此方法首先在序列維度上拆分長預填充請求,然后將其與多個短解碼請求批處理在一起。該方法平衡了不同迭代之間的工作負載,并通過消除新請求的延遲顯著減少了尾部延遲。LightLLM也采用了split-and-fuse方法。
6.2.3 Scheduling技術
在大模型服務中,每個請求的作業長度具有可變性,因此執行請求的順序會顯著影響服務系統的吞吐量。head-of-line blocking發生在長請求被賦予優先級時。具體來說,對于長請求,內存使用會迅速增長,當系統內存容量耗盡時,會導致后續請求受阻。ORCA和開源框架,包括vLLM和LightLLM,采用簡單的先到先服務(FCFS)原則來調度請求。DeepSpeed-FastGen則優先考慮解碼請求以提高性能。FastServe提出了一種搶占式調度策略來優化排隊阻塞問題,實現大模型服務的低作業完成時間(JCT)。FastServe采用多級反饋隊列(MLFQ)來優先處理剩余時間最短的請求。由于自動回歸解碼方法會產生未知的請求長度,FastServe首先預測長度,并利用跳過連接方式為每個請求找到適當的優先級。與以往的工作不同,VTC討論了大模型推理服務中的公平性。VTC引入了一個基于token數的成本函數來衡量客戶端之間的公平性,并進一步提出了一個公平調度程序來確保公平性。
6.2.4 分布式系統
為了實現高吞吐量,大模型服務通常部署在分布式平臺上。最近的工作還側重于通過利用分布式特征來優化此類推理服務的性能。值得注意的是,預填充是計算密集型的,解碼是內存密集型的,splitwise, TetriInfer和DistServe證明了分解請求的預填充和解碼步驟的效率。這樣,兩個不同的階段就可以根據各自的特點進行獨立的處理。SpotServe設計用于在具有可搶占GPU實例的云上提供大模型服務。SpotServe有效地處理包括動態并行控制和實例遷移在內的挑戰,并且還利用大模型的自回歸特性來實現token級別的狀態恢復。此外,Infinite-LLM將vLLM中的分頁KV緩存方法擴展到分布式云環境。
6.3 硬件加速器設計
過去的研究工作集中在優化Transformer架構,特別是優化注意力算子,通常采用稀疏方法來促進FPGA部署。與NVIDIA V100 GPU相比,FACT加速器通過線性運算的混合精度量化和算法-硬件協同設計實現了卓越的能效,而且這些方法不是為生成式大模型量身定制的。
近期的工作,如ALLO突出了FPGA在管理內存密集型解碼階段方面的優勢。強調了模型壓縮技術對大模型高效FPGA部署的重要性。相反,DFX側重于解碼階段優化,但缺少模型壓縮方法,限制了可擴展性在更大的模型和更長的輸入(最多1.5B模型和256個token)。ALLO建立在這些見解的基礎上,進一步提供了一個可組合和可重用的高級合成(High-level Synthesis, HLS)內核庫。與DFX相比,ALLO的實現在預填充階段展示了卓越的生成加速,在解碼期間實現了比NVIDIA A100 GPU更高的能效和加速。
FlightLLM也利用了這些見解,引入了一個可配置的稀疏數字信號處理器(DSP)鏈,用于各種具有高計算效率的稀疏模式。為了提高存儲帶寬利用率,提出了一種支持混合精度的片上譯碼方案。FlightLLM在Llama2-7B型號上實現了比NVIDIA V100S GPU高6.0倍的能效和1.8倍的成本效益,解碼時的吞吐量比NVIDIA A100 GPU高1.2倍。
6.4 大模型推理框架對比
作者對比了多個推理框架的性能,如表6所示。使用Llama2-7B(batch size=1,輸入長度=1k,輸出長度=128)測量推理吞吐量。推理服務性能是在ShareGPT數據集上測量的最大吞吐量。兩者都基于單個NVIDIA A100 80GB GPU。在上述框架中,DeepSpeed、vLLM、LightLLM和TensorRT-LLM集成了推理服務功能,為來自多個用戶的異步請求提供服務。作者還在表格中列出了每個框架的優化。作者還在表中列出了針對每個框架的優化。除了HuggingFace外,所有框架都實現了operator級別或圖優化級別的優化以提高性能,其中一些框架還支持推測解碼技術。請注意,作者測量所有框架的推理性能時,沒有使用推測解碼技術。推理吞吐量的結果表明,FlashDecoding++和TensorRT-LLM在覆蓋主要算子和計算圖的優化方面優于其他算法。在推理服務方面,各框架均采用細粒度、不連續存儲方式進行KV緩存,并采用連續批處理技術提高系統利用率。與vLLM和LightLLM不同,DeepSpeed在調度中優先考慮解碼請求,這意味著如果批處理中有足夠的現有解碼請求,則不會合并新請求。

表6:開源推理框架性能對比
6.5 認識,建議和未來方向
系統級優化在不降低精度的同時提高了效率,因此在大模型推理實踐中越來越普遍。對推理的優化也適用于服務。最近,operator優化已經與實際服務場景緊密結合,例如,專門為前綴緩存設計的RadixAttention和加速推測解碼驗證的tree attention。應用和場景的迭代將不斷對operator的發展提出新的要求。
考慮到實際推理服務系統中固有的多方面目標,例如JCT、系統吞吐量和公平性,調度策略的設計相應地變得復雜。在請求長度不確定的大模型服務領域,現有文獻通常依賴于預測機制來促進調度策略的設計。然而,目前的預測器的有效性達不到理想的標準,這表明在服務調度策略開發中存在改進和優化的潛力。
7 關鍵應用場景討論
目前的研究在探索跨各種優化級別的高效大模型推理的邊界方面取得了重大進展。然而,需要進一步的研究來提高大模型在實際場景中的效率。作者為數據級(第4.3節)、模型級(第5.3節)和系統級(第6.5節)的優化技術分析了有希望的未來方向。在本節中,作者總結了四個關鍵場景:Agent and Multi-Model Framework、Long-Context LLMs、Edge Scenario Deployment和安Security-Efficiency Synergy,并對它們進行了更廣泛的討論。
Agent and Multi-Model Framework:如4.3章所討論,Agent 和Multi-Model框架的最近工作,通過利用大模型的強大能力,顯著提高了Agent處理復雜任務和人類請求的能力。這些框架在增加大模型計算需求的同時,在大模型輸出內容的結構中引入了更多的并行性,從而為數據級和系統級優化(如輸出組織技術)創造了機會。此外,這些框架自然地引入了一個新的優化級別,即pipeline級別,它具有在該級別上提高效率的潛力。
此外,越來越多的研究趨勢側重于將AI智能體擴展到多模態領域,通常使用多模態大模型(Large multimodal Models, LMM)作為這些Agent系統的核心。為了提高這些新興的基于LMM的智能體的效率,為LMM設計優化技術是一個很有前途的研究方向。
Long-Context LLMs:目前,大模型面臨著處理越來越長的輸入上下文的挑戰。然而,自注意力操作(Transformer-style大模型的基本組成部分)表現出與上下文長度相關的二次復雜度,對最大上下文長度施加了限制在訓練和推理階段。各種策略已經被探索了來解決這一限制,包括輸入壓縮(第4.1節)、稀疏注意力(第5.2.2節)、低復雜度結構的設計(第5.1.3節)和注意算子的優化(第6.1.1節)。值得注意的是,具有次二次或線性復雜性的非transformer架構(第5.1.3節)最近引起了研究人員的極大興趣。
盡管它們效率很高,但與Transformer架構相比,這些新架構在各種能力(如上下文學習能力和遠程建模能力)上的競爭力仍有待考察。因此,從多個角度探索這些新架構的功能并解決它們的局限性仍然是一個有價值的追求。此外,為各種場景和任務確定必要的上下文長度,以及確定將作為未來大模型基礎支柱的下一代架構,這一點至關重要。
Edge Scenario Deployment:盡管提高大模型推理的效率已經有了許多工作,但將大模型部署到資源極其有限的邊緣設備(如移動電話)上仍然存在挑戰。最近,許多研究人員對具有1B ~ 3B參數的較小語言模型的預訓練表現出了興趣。這種規模的模型在推理過程中提供了更少的資源成本,并且與更大的模型相比,具有實現泛化能力和競爭性能的潛力。然而,開發如此高效和強大的小型語言模型的方法仍然沒有得到充分的探索。
一些研究已經開啟了這個有希望的方向。例如,MiniCPM通過沙盒實驗來確定最優的預訓練超參數。PanGu-π-Pro建議使用來自模型修剪的矩陣和技術來初始化預訓練打磨謝謝的模型權重。MobileLLM在小型模型設計中采用了“深而薄”的架構,并提出了跨不同層的權重共享,在不增加額外內存成本的情況下增加層數。然而,小模型和大模型之間仍存在性能差距,需要未來的研究來縮小這一差距。未來,迫切需要研究如何識別邊緣場景下的模型尺度,并探索各種優化方法在設計上的邊界。
除了設計較小的模型之外,系統級優化為大模型部署提供了一個有前途的方向。最近一個值得注意的項目,MLC-LLM成功地在移動電話上部署了LLaMA-7B模型。MLC-LLM主要使用融合、內存規劃和循環優化等編譯技術來增強延遲并降低推理期間的內存成本。此外,采用云邊緣協作技術或設計更復雜的硬件加速器也可以幫助將大模型部署到邊緣設備上。
Security-Efficiency Synergy:除了任務性能和效率外,安全性也是大模型應用中必須考慮的關鍵因素。目前的研究主要集中在效率優化方面,沒有充分解決安全考慮的操作。因此,研究效率和安全性之間的相互作用,并確定當前的優化技術是否會損害大模型的安全性是至關重要的。如果這些技術對大模型的安全性產生負面影響,一個有希望的方向是開發新的優化方法或改進現有的方法,以實現大模型的效率和安全性之間更好的權衡。
8 總結
高效的大模型推理側重于減少大模型推理過程中的計算、內存訪問和內存成本,旨在優化諸如延遲、吞吐量、存儲、功率和能源等效率指標。作者在本綜述中提供了高效大模型推理研究的全面回顧,提出了關鍵技術的見解,建議和未來方向。首先,作者引入了包含數據級、模型級和系統級優化的分層分類法。隨后,在這一分類方法的指導下,作者總結每個層次和子領域的研究。對于模型量化和高效服務系統等成熟的技術,作者進行了實驗來評估和分析它們的性能。在此基礎上,提出了實踐建議。為該領域的從業者和研究人員提出建議并確定有前途的研究途徑。
-
大模型
+關注
關注
2文章
2423瀏覽量
2640 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:3萬字詳細解析清華大學最新綜述工作:大模型高效推理綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
用tflite接口調用tensorflow模型進行推理
【飛凌RK3568開發板試用體驗】RKNN模型推理測試
壓縮模型會加速推理嗎?
如何提高YOLOv4模型的推理性能?
AscendCL快速入門——模型推理篇(上)
HarmonyOS:使用MindSpore Lite引擎進行模型推理
主流大模型推理框架盤點解析
澎峰科技發布大模型推理引擎PerfXLLM
基于LLM的表格數據的大模型推理綜述

自然語言處理應用LLM推理優化綜述







 工商網監
工商網監
評論