

目錄
1.Tricore尋址模式
2.lsl鏈接文件Section分析
3.限定符對于代碼的影響
4.小結
1.Tricore尋址模式
今天聊個好玩的事情。 之前ARM培訓的時候,他們對于函數形參的先后順序、數據類型、對齊方式等等做了介紹,詳細分析了上述操作不同寫法對于CPU的通用寄存器使用效率上的影響,這給我留下了一點印象,但不多。 而最近我在用ADS驗英飛凌LMU、DSPR、PSRP等等訪問效率時,發現了這樣一行代碼:
#pragma section farbss lmubss#pragma ,section,咱們都非常熟悉了,這個farbss是什么意思呢?以前做BSW還真沒多大關注這個。 查看Tasking的手冊,得到了一些答案,如下:
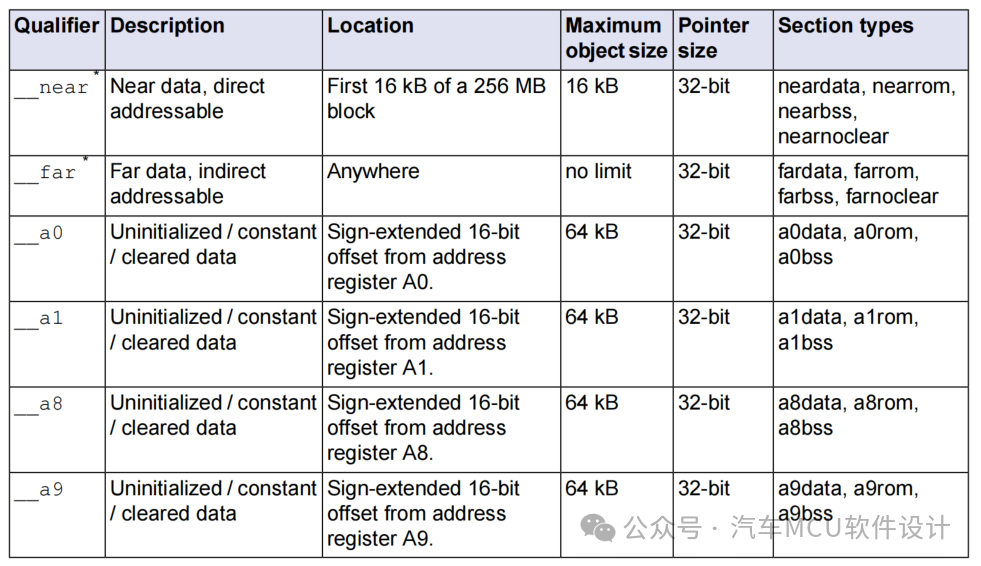
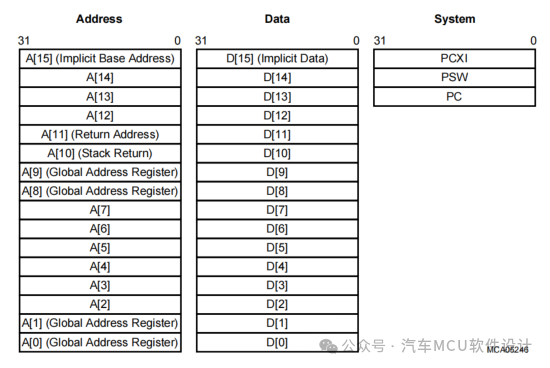


2.lsl鏈接文件Section分析
在ADS給的lsl模板中,可以看到關于上述限定符以及對應section type的描述,例如:
/*Near Abbsolute Addressable Data Sections*/
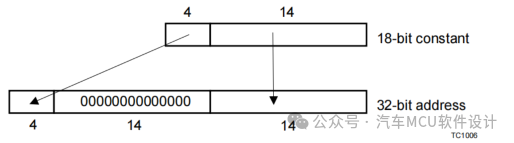
section_layout abs18
{
group
{
}
}
/*Relative A0/A1/A8/A9 Addressable Sections*/
section_layout linear
{
group
{
}
}
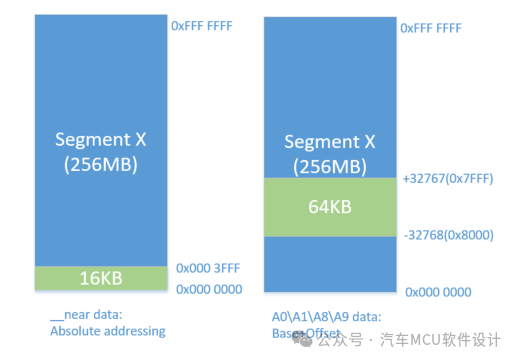
其中,abs18表示18bit絕對尋址空間,linear表示線性地址空間,如下圖所示:
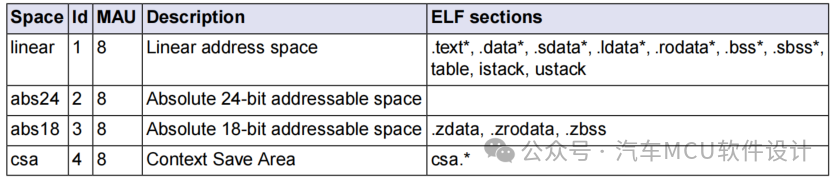
.bss:未初始化數據
.bss_a0a1a8a9:未初始化數據,用寄存器A0A1A8A9尋址
.data:已初始化數據
.data_a0a1a8a9:已初始化的數據,用寄存器A0A1A8A9尋址
.sbss:未初始化的數據,a0尋址
.sdata:已初始化的數據,a0尋址
.zbss:未初始化數據,abs18尋址
.zdata:已初始化數據,abs18尋址
我們在Cpu0_main.c里定義兩個變量,不添加任何限定符,如下:

編譯生成出來的map,可以看到這兩個變量是放在.bss中:  ?對應lsl定義的Far Data Section:
?對應lsl定義的Far Data Section:
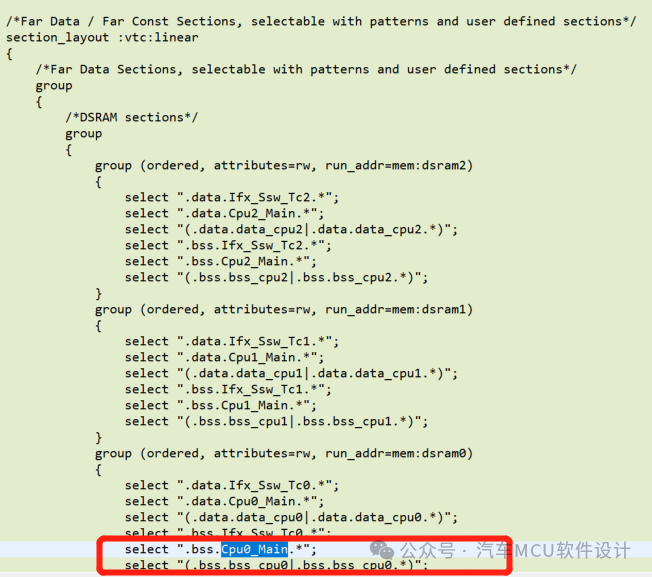
如果加上限定符__near,如下:
uint32 __near example_x ; uint32 __near example_y;編譯出來發現已經放到了zbss段

ltc E121: relocation error in "task1": relocation value 0x50000000, type R_TRICORE_16SM, offset 0x34, section ".text.Cpu0_Main.core0_main" at address 0x800023bc is not within a 16-bit signed range from the value of A0 as defined by the symbol _SMALL_DATA_
這就意味著,如果要使用寄存器+偏移尋址的方式,那么就必須是A0A1...寄存器中內容上下偏移±32KB,例如,當A0寄存器里內容為0xD0018000時,那么通過A0寄存器尋址的所有變量就應該在0xD0010000 - 0xD001FFFF。這個場景后面構建了我們再討論,但至少我們確定了利用寄存器+偏移的方式多用于局部變量訪問。
3.限定符對于代碼的影響
第二節我們發現了利用不同限定符將變量發到不同的section里,但是變量的地址始終沒有變化,那這到底有什么用呢? 編譯出來的C代碼最終會以匯編形式展示給機器,因此我們來看看不同限定符下對于代碼的影響。 1)添加__near限定符,編譯得到的結構,代碼如下:
uint32 __near example_x ;
uint32 __near example_y;
void main(void)
{
example_x = 3;
example_y=example_x+2;
}
得到匯編代碼如下
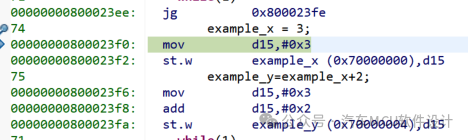
將立即數3賦給寄存器D15
D15的值直接賦給變量(x)
立即數3賦給寄存器D15
D15和2相加
將D15的值直接賦給變量(y)
統計攏共5條指令完成x=3,y=x+2這個操作; 2)添加__far限定符,得到如下
uint32 __far example_x ;
uint32 __far example_y;
void main(void)
{
example_x = 3;
example_y=example_x+2;
}
匯編代碼如下:
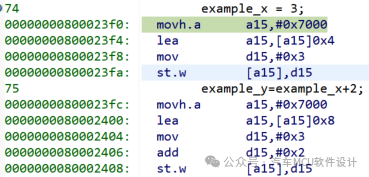
x的賦值:
將0x7000給到地址寄存器A15高16bit,低位補0,這時候A15 = 0x70000000
加載有效地址到A15,因為x地址為0x70000004,故A15 = 0x70000004
將數據3移至D15;
將D15賦給A15指向的地址
y的賦值
將0x7000給到地址寄存器A15高16bit,低位補0,這時候A15 = 0x70000000
加載有效地址到A15,因為y地址為0x70000008,故A15 = 0x70000008
將數據3移至D15,并加2;
將D15賦給A15指向的地址
總計9條指令,咋一看僅僅節省了4條指令,但從統計角度來看,效率提升了44.44%,Flash消耗更少了。 同樣兩行C代碼,僅僅因為尋址方式的不同,匯編指令差異如此之大 ,從而影響系統運行效率。
4.小結
現在MCU的性能越來越強大,導致我在使用上越來越隨意,對于這種特別底層的知識非常匱乏,直到遇到了系統優化問題,才會去從這些角度來考慮。總結下來,在系統性能優化時要注意:
構建memory限定符使用場景以優化代碼執行效率;
多使用靠近CPU的memory,例如ARM TCM、Tricore DSPR、PSPR;
通過調試匯編代碼,也更進一步了解了Tricore內核的運行原理;接下來,思考如何將這些理論引入到工程代碼中。
-
寄存器
+關注
關注
31文章
5424瀏覽量
123509 -
效率
+關注
關注
0文章
151瀏覽量
20402 -
TriCore
+關注
關注
0文章
15瀏覽量
11892
原文標題:TC3xx分析--如何提高系統運行效率
文章出處:【微信號:eng2mot,微信公眾號:汽車ECU開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
三相電機驅動系統逆變器故障補救與容錯策略
基于Infineon TC4D9+TLF4D985的Aurix StartKit
電機大范圍調速的綜合電壓調制策略
嵌入式系統存儲的軟件優化策略
EE-401:ADSP-SC5xx/215xx SHARC處理器系統優化技術

電力系統中電動車充電樁布局與調度的優化策略探究






 工商網監
工商網監

評論