") 基于AX650N/AX630C部署多模態(tài)大模型InternVL2-1B
基于AX650N/AX630C部署多模態(tài)大模型InternVL2-1B
背景
InternVL2是由上海人工智能實驗室OpenGVLab發(fā)布的一款多模態(tài)大模型,中文名稱為“書生·萬象”。該模型在多學(xué)科問答(MMMU)等任務(wù)上表現(xiàn)出色,并且具備處理多種模態(tài)數(shù)據(jù)的能力。
本文將通過走馬觀花的方式,基于InternVL2家族中最小的InternVL2-1B模型來介紹其技術(shù)特點。同時也將分享基于愛芯元智的AX650N、AX630C兩款端側(cè)AI芯片適配InternVL2-1B的基本操作方法,向業(yè)界對端側(cè)多模態(tài)大模型部署的開發(fā)者提供一種新的思路,促進社區(qū)對端側(cè)多模態(tài)大模型的探索。
技術(shù)特性
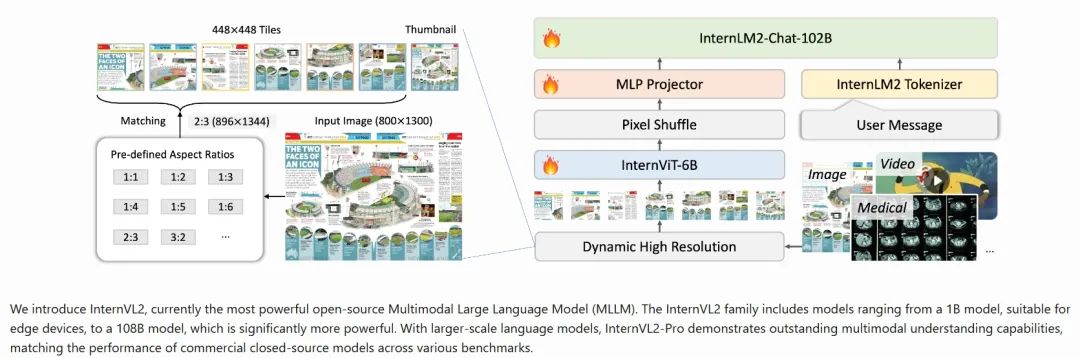
多模態(tài)處理能力:與更大規(guī)模的版本一樣,InternVL2-1B支持圖像和文本數(shù)據(jù)的聯(lián)合處理,旨在理解和生成跨模態(tài)的內(nèi)容。
輕量化設(shè)計:1B參數(shù)規(guī)模意味著相對較小的模型尺寸,這使得InternVL2-1B更適合部署在資源受限的環(huán)境中,如移動設(shè)備或邊緣計算場景中。盡管參數(shù)較少,通過精心設(shè)計,它仍能保持良好的性能。
漸進式對齊訓(xùn)練策略:采用從小到大、從粗到精的方式進行訓(xùn)練,這樣可以利用更少的計算資源達到較高的效果,同時也促進了模型的知識遷移能力。
高效的架構(gòu)設(shè)計:為了在有限的參數(shù)下實現(xiàn)最佳性能,InternVL2-1B可能采用了特別優(yōu)化的網(wǎng)絡(luò)結(jié)構(gòu)或注意力機制,確保即使在較低參數(shù)量的情況下也能有效地捕捉復(fù)雜的視覺語言關(guān)聯(lián)性。
支持多種下游任務(wù):盡管是較小型號,InternVL2-1B應(yīng)該仍然能夠執(zhí)行一系列基本的視覺-語言任務(wù),比如圖像描述生成、視覺問答等,為用戶提供了一定程度的功能多樣性。
開放源代碼與模型權(quán)重:如果遵循OpenGVLab的一貫做法,那么InternVL2-1B的代碼及預(yù)訓(xùn)練模型應(yīng)該也是開源提供的,方便研究者和開發(fā)者使用。
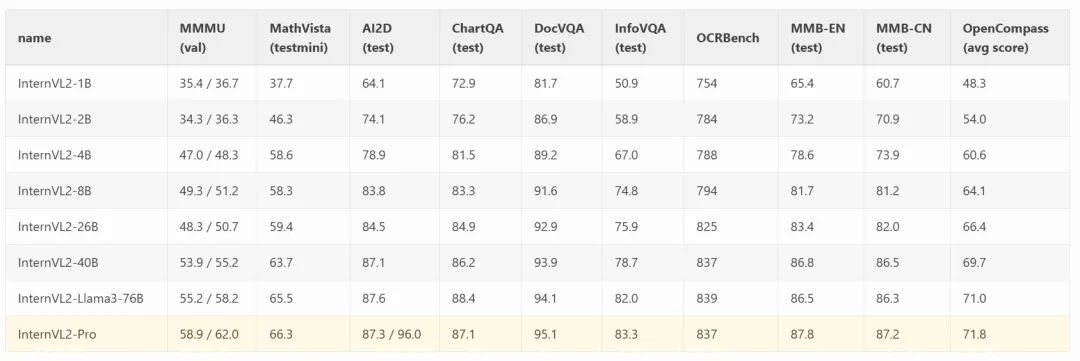
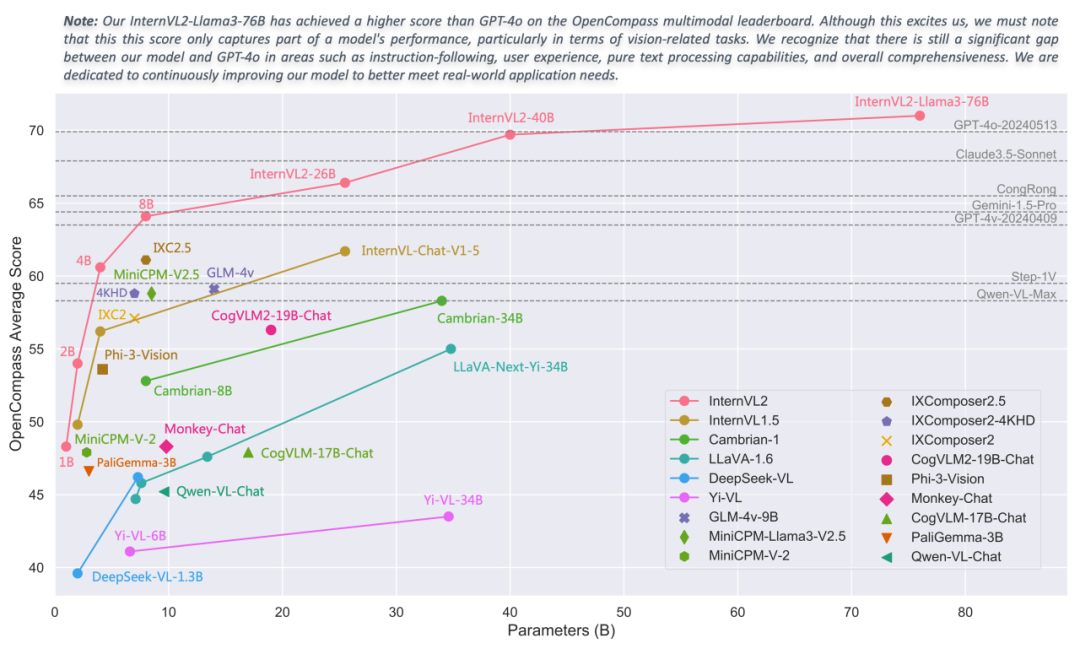
性能指標(biāo)
AX650N
愛芯元智第三代高能效比智能視覺芯片AX650N。集成了八核Cortex-A55 CPU,高能效比NPU,支持8K@30fps的ISP,以及H.264、H.265編解碼的 VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI輸入,千兆Ethernet、USB、以及HDMI 2.0b輸出,并支持32路1080p@30fps解碼內(nèi)置高算力和超強編解碼能力,滿足行業(yè)對高性能邊緣智能計算的需求。通過內(nèi)置多種深度學(xué)習(xí)算法,實現(xiàn)視覺結(jié)構(gòu)化、行為分析、狀態(tài)檢測等應(yīng)用,高效率支持基于 Transformer結(jié)構(gòu)的視覺大模型和語言類大模型。提供豐富的開發(fā)文檔,方便用戶進行二次開發(fā)。
AX630C
愛芯元智第四代智能視覺芯片AX630C,該芯片集成新一代智眸4.0AI-ISP,最高支持4K@30fps實時真黑光,同時集成新一代通元4.0高性能、高能效比NPU引擎,使得產(chǎn)品在低功耗、高畫質(zhì)、智能處理和分析等方面行業(yè)領(lǐng)先。提供穩(wěn)定易用的SDK軟件開發(fā)包,方便用戶低成本評估、二次開發(fā)和快速量產(chǎn)。幫助用戶在智能家居應(yīng)用和其他AIoT項目中發(fā)揮更大的價值。
AX630C應(yīng)該是目前能效比&性價比&能跑LLM/VLM的最佳的端側(cè)AI芯片了,因此有客戶基于AX630C出品了LLM Module,歡迎關(guān)注/試用。
模型轉(zhuǎn)換
經(jīng)常在AI芯片上部署AI算法模型的同學(xué)都知道,想要把模型部署到芯片上的NPU中運行,都需要使用芯片原廠提供的NPU工具鏈,這里我們使用的是Pulsar2。
Pulsar2是愛芯元智的新一代NPU工具鏈,包含模型轉(zhuǎn)換、離線量化、模型編譯、異構(gòu)調(diào)度四合一超強功能,進一步強化了網(wǎng)絡(luò)模型高效部署的需求。在針對第三代、第四代NPU架構(gòu)進行了深度定制優(yōu)化的同時,也擴展了算子&模型支持的能力及范圍,對Transformer結(jié)構(gòu)的網(wǎng)絡(luò)也有較好的支持。
從Pulsar2 3.2版本開始,已經(jīng)增加了大語言模型編譯的功能,隱藏在pulsar2 llm_build的子命令中。
模型獲取
git clone https://github.com/AXERA-TECH/ax-llm-build.git cd ax-llm-build pip install -U huggingface_hub huggingface-cli download --resume-download OpenGVLab/InternVL2-1B/ --local-dir OpenGVLab/InternVL2-1B/
ax-llm-build:用于暫存編譯LLM、VLM時所依賴的各種輔助小工具、腳本文件(持續(xù)更新)。
一鍵編譯
qtang@gpux2:~/huggingface$ pulsar2 llm_build --input_path OpenGVLab/InternVL2-1B/ --output_path OpenGVLab/InternVL2-1B-ax650 --kv_cache_len 1023 --hidden_state_type bf16 --prefill_len 128 --chip AX650 Config( model_name='InternVL2-1B', model_type='qwen2', num_hidden_layers=24, num_attention_heads=14, num_key_value_heads=2, hidden_size=896, intermediate_size=4864, vocab_size=151655, rope_theta=1000000.0, max_position_embeddings=32768, rope_partial_factor=1.0, rms_norm_eps=1e-06, norm_type='rms_norm', hidden_act='silu', hidden_act_param=0.03, scale_depth=1.4, scale_emb=1, dim_model_base=256, origin_model_type='internvl_chat' ) 2024-10-31 0030.400 | SUCCESS | yamain.command.llm_build109 - prepare llm model done! building vision model ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/1 024 building llm decode layers ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24/24 013 building llm post layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/1 027 2024-10-31 0036.175 | SUCCESS | yamain.command.llm_build185 - build llm model done! 2024-10-31 0051.955 | SUCCESS | yamain.command.llm_build364 - check llm model done!
embed提取和優(yōu)化
chmod +x ./tools/fp32_to_bf16 chmod +x ./tools/embed_process.sh ./tools/embed_process.sh OpenGVLab/InternVL2-1B/ OpenGVLab/InternVL2-1B-ax650
最終InternVL2-1B-ax650目錄下包含以下內(nèi)容:
qtang@gpux2:~/huggingface$ tree -lh OpenGVLab/InternVL2-1B-ax650/ [1.6K] OpenGVLab/InternVL2-1B-ax650/ ├── [325M] intervl_vision_part_224.axmodel // vit-l model ├── [259M] model.embed_tokens.weight.bfloat16.bin // embed file ├── [ 16M] qwen2_p128_l0_together.axmodel // llm layer ├── [ 16M] qwen2_p128_l10_together.axmodel ├── [ 16M] qwen2_p128_l11_together.axmodel ├── [ 16M] qwen2_p128_l12_together.axmodel ...... ├── [ 16M] qwen2_p128_l5_together.axmodel ├── [ 16M] qwen2_p128_l6_together.axmodel ├── [ 16M] qwen2_p128_l7_together.axmodel ├── [ 16M] qwen2_p128_l8_together.axmodel ├── [ 16M] qwen2_p128_l9_together.axmodel └── [141M] qwen2_post.axmodel
上板示例
相關(guān)材料
為了方便大家快速試用,我們在網(wǎng)盤中已經(jīng)提供好了預(yù)編譯模型和基于AX650N、AX630C兩種芯片平臺的預(yù)編譯示例:

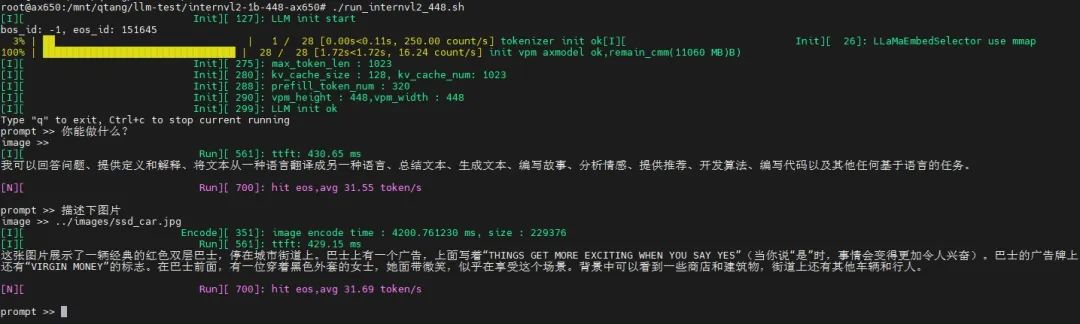
大尺寸
基于AX650N,展示輸入圖片尺寸為448*448的示例,圖片信息量大,解讀更詳細,甚至展示了其OCR、中英翻譯的能力。
小尺寸
基于AX630C,展示輸入圖片尺寸為224*224的示例:
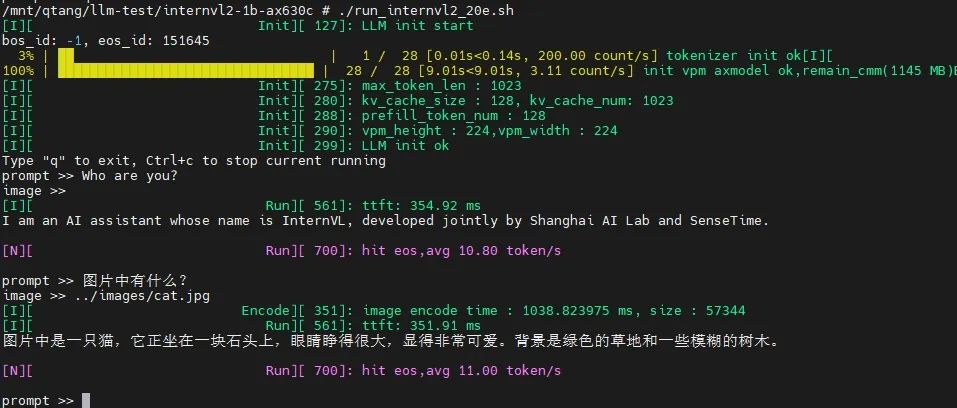
目前我們暫時未對Vision Part模塊的ViT-L模型進行量化加速,所以圖片編碼的速度稍微有點慢。但是本身AX650N、AX630C計算ViT模型的效率是非常高的,后續(xù)我們會持續(xù)優(yōu)化推理耗時。
部署優(yōu)化探討
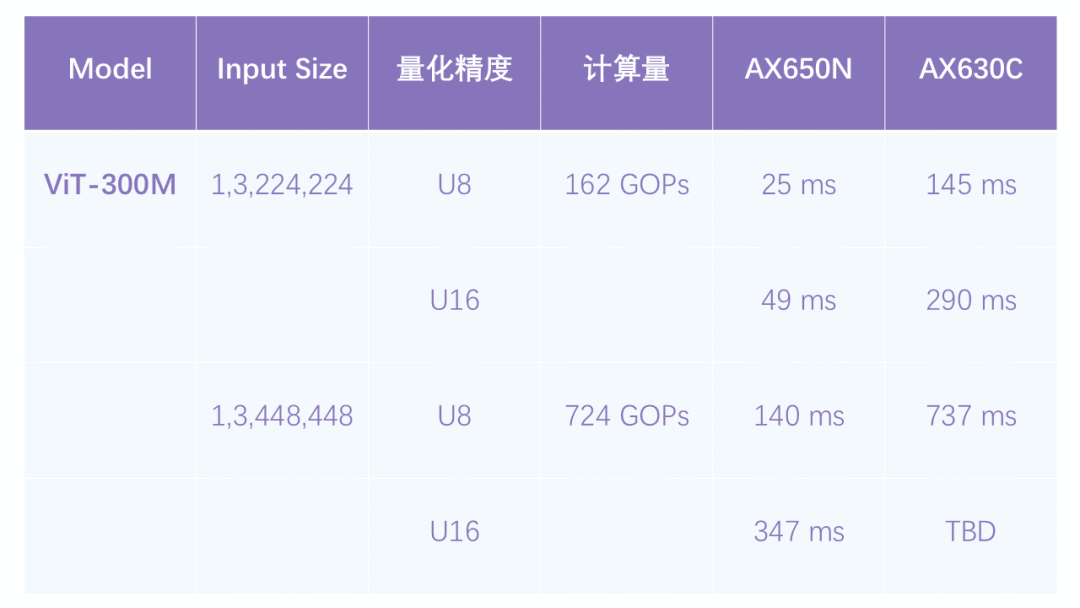
輸入圖片越大,Vision Part(Image Encoder)生成的特征向量越多,計算量越大,即使是InternVL2 Family中最小的1B版本,其Vision Part也是采用的基于ViT-Large規(guī)模的圖像編碼模型。
圖片生成的特征向量越多,輸入LLM的prompt就越長,input tokens越多,TTFT耗時越大。

我們順便統(tǒng)計了224與448兩種輸入尺寸采用U8、U16量化后的推理耗時,提升還是很明顯。
結(jié)束語
雖然我們只嘗試了最小的InternVL2-1B部署,但能在原本定位于低成本家用攝像頭芯片(AX630C)上本地流暢運行VLM已經(jīng)是一個重大突破,例如無需聯(lián)網(wǎng)(包括藍牙)的智能眼鏡、智能的“拍立得”、以及各種有趣的穿戴設(shè)備。
隨著大語言模型小型化的快速發(fā)展,越來越多有趣的多模態(tài)AI應(yīng)用已經(jīng)從云端服務(wù)遷移到端側(cè)設(shè)備。我們會緊跟行業(yè)最新動態(tài),適配更多的端側(cè)大模型,歡迎大家持續(xù)關(guān)注。
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238246 -
AI芯片
+關(guān)注
關(guān)注
17文章
1879瀏覽量
34990 -
愛芯元智
+關(guān)注
關(guān)注
1文章
78瀏覽量
4830 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
原文標(biāo)題:愛芯分享 | 基于AX650N/AX630C部署多模態(tài)大模型InternVL2-1B
文章出處:【微信號:愛芯元智AXERA,微信公眾號:愛芯元智AXERA】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于AX650N/AX630C部署端側(cè)大語言模型Qwen2
愛芯元智發(fā)布第三代智能視覺芯片AX650N,為智慧生活賦能

【愛芯派 Pro 開發(fā)板試用體驗】篇一:開箱篇
【愛芯派 Pro 開發(fā)板試用體驗】愛芯元智AX650N部署yolov5s 自定義模型
【愛芯派 Pro 開發(fā)板試用體驗】愛芯元智AX650N部署yolov8s 自定義模型
【愛芯派 Pro 開發(fā)板試用體驗】ax650使用ax-pipeline進行推理
CAT-AX41-C8422B CRADLE N 繼電器 V23162
CAT-AX41-D1B AXICOM D2N 靈敏型

愛芯元智第三代智能視覺芯片AX650N高能效比SoC芯片
基于AX650N部署EfficientViT
基于AX650N部署視覺大模型DINOv2
愛芯元智發(fā)布新一代IPC SoC芯片AX630C和AX620Q

愛芯元智AX620E和AX650系列芯片正式通過PSA Certified安全認(rèn)證

基于AX650N芯片部署MiniCPM-V 2.0高效端側(cè)多模態(tài)大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論