") NVIDIA RTX AI Toolkit擁抱LoRA技術(shù)
NVIDIA RTX AI Toolkit擁抱LoRA技術(shù)
在 RTX AI PC 和工作站上使用最新版 RTX AI Toolkit 微調(diào) LLM,最高可將性能提升至原來(lái)的 6 倍。
憑借其快速理解、總結(jié)和生成基于文本的內(nèi)容的能力,大語(yǔ)言模型(LLM)正在推動(dòng) AI 領(lǐng)域中的一些極為激動(dòng)人心的發(fā)展。
LLM 的這些能力可支持各種場(chǎng)景,包括生產(chǎn)力工具、數(shù)字助理、電子游戲中的 NPC 等。但它們并非萬(wàn)能的解決方案,開發(fā)者通常必須對(duì) LLM 進(jìn)行微調(diào),使 LLM 適應(yīng)他們應(yīng)用的需求。
NVIDIA RTX AI Toolkit 可通過(guò)一種名為“低秩自適應(yīng)(LoRA)”的技術(shù),讓用戶輕松地在 RTX AI PC 和工作站上微調(diào)和部署 AI 模型。現(xiàn)已推出的最新版支持在 NVIDIA TensorRT-LLM AI 加速庫(kù)中同時(shí)使用多個(gè) LoRA,最高可將微調(diào)模型的性能提升至原來(lái)的 6 倍。
通過(guò)微調(diào)提升性能
LLM 必須經(jīng)過(guò)精心定制,才能實(shí)現(xiàn)更高的性能并滿足用戶日益增長(zhǎng)的需求。
雖然這些基礎(chǔ)模型是基于海量數(shù)據(jù)訓(xùn)練出來(lái)的,但它們通常缺乏開發(fā)者的特定場(chǎng)景所需的上下文。例如,通用型 LLM 可以生成游戲?qū)υ挘芸赡軙?huì)忽略文風(fēng)的細(xì)微差別和微妙之處。例如,以一位有著黑暗過(guò)往并蔑視權(quán)威的林地精靈的口吻編寫對(duì)話時(shí),LLM 很有可能會(huì)忽略需要展現(xiàn)出來(lái)的微妙文風(fēng)。
為了獲得更符合自己需求的輸出,開發(fā)者可以使用與應(yīng)用場(chǎng)景相關(guān)的信息對(duì)模型進(jìn)行微調(diào)。
以開發(fā)一款利用 LLM 生成游戲內(nèi)對(duì)話的應(yīng)用為例。微調(diào)時(shí),首先需要使用預(yù)訓(xùn)練模型的權(quán)重,例如角色可能會(huì)在游戲中說(shuō)出的內(nèi)容的相關(guān)信息。為使對(duì)話符合相應(yīng)文風(fēng),開發(fā)者可以基于較小的示例數(shù)據(jù)集(例如以更詭異或更邪惡的語(yǔ)氣編寫的對(duì)話)調(diào)整模型。
在某些情況下,開發(fā)者可能希望同時(shí)運(yùn)行所有不同的微調(diào)流程。例如,他們可能希望為不同的內(nèi)容頻道生成以不同的語(yǔ)氣編寫的營(yíng)銷文案。同時(shí),他們可能還希望總結(jié)文檔并提出文風(fēng)方面的建議,以及為文生圖工具起草電子游戲場(chǎng)景描述和圖像提示詞。
同時(shí)運(yùn)行多個(gè)模型并不現(xiàn)實(shí),因?yàn)?GPU 顯存無(wú)法同時(shí)容納所有模型。即使能同時(shí)容納,模型的推理時(shí)間也會(huì)受制于顯存帶寬(即 GPU 從顯存讀取數(shù)據(jù)的速度)。
擁抱 LoRA 技術(shù)
解決上述問(wèn)題的常用方法是使用低秩自適應(yīng)(LoRA)等微調(diào)技術(shù)。簡(jiǎn)單來(lái)說(shuō),您可以將這種技術(shù)視為補(bǔ)丁文件,其中包含微調(diào)流程中的定制過(guò)程。
訓(xùn)練完畢后,定制的 LoRA 可以在推理過(guò)程中與基礎(chǔ)模型無(wú)縫集成,額外的性能開銷極少。開發(fā)者可以將多個(gè) LoRA 連接到單個(gè)模型上,以服務(wù)多種場(chǎng)景。這樣既能使顯存占用率保持在較低水平,又能為各個(gè)特定場(chǎng)景提供所需的額外細(xì)節(jié)內(nèi)容。
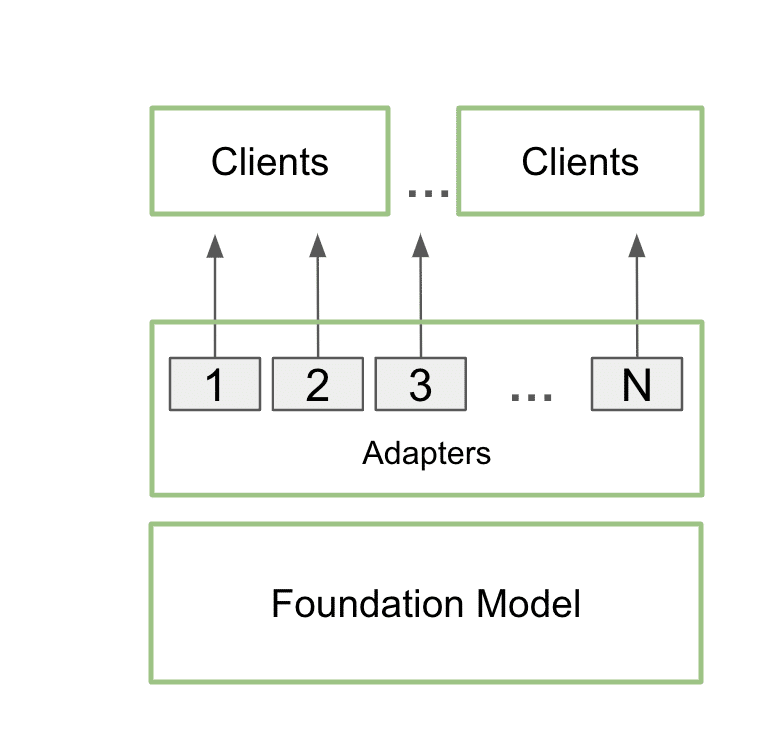
使用多 LoRA 功能通過(guò)單個(gè)基礎(chǔ)模型同時(shí)支持多個(gè)客戶端和場(chǎng)景的架構(gòu)圖
在實(shí)際操作中,這意味著應(yīng)用可以在顯存中只保留一個(gè)基礎(chǔ)模型,同時(shí)使用多個(gè) LoRA 實(shí)現(xiàn)多種定制。
這個(gè)過(guò)程稱為多 LoRA 服務(wù)。當(dāng)對(duì)模型進(jìn)行多次調(diào)用時(shí),GPU 可以并行處理所有調(diào)用,更大限度地利用其 Tensor Core 并盡可能減少對(duì)顯存和帶寬的需求,以便開發(fā)者在工作流中高效使用 AI 模型。使用多 LoRA 的微調(diào)模型的性能最高可提升至原來(lái)的 6 倍。
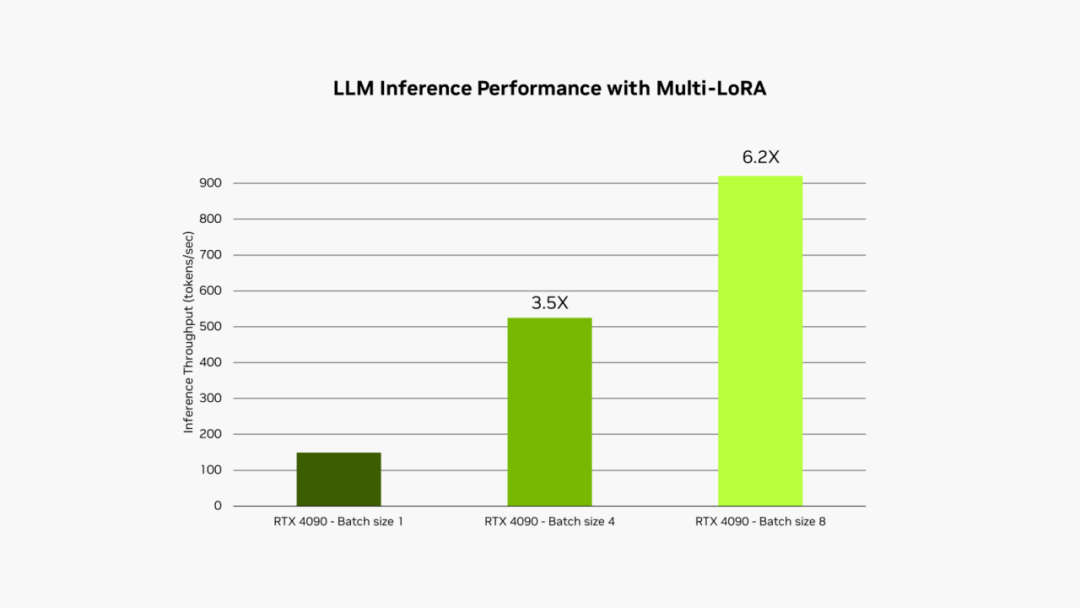
在 GeForce RTX 4090 臺(tái)式電腦 GPU 上運(yùn)行 Llama 3B int4 時(shí),應(yīng)用 LoRA 的 LLM 的推理性能。輸入序列長(zhǎng)度為 1,000 個(gè) token,輸出序列長(zhǎng)度為 100 個(gè) token。LoRA 最大秩為 64。
在前文所述的游戲內(nèi)對(duì)話應(yīng)用的示例中,通過(guò)使用多 LoRA 服務(wù),應(yīng)用的范圍可以擴(kuò)展到同時(shí)生成劇情元素和插圖,兩者都是由單個(gè)提示驅(qū)動(dòng)的。
用戶可以輸入基本的劇情創(chuàng)意,然后 LLM 會(huì)充實(shí)這個(gè)概念,在基本創(chuàng)意的基礎(chǔ)上進(jìn)行擴(kuò)展,提供詳細(xì)的基礎(chǔ)劇情。然后,應(yīng)用可以使用相同的模型,并通過(guò)兩個(gè)不同的 LoRA 進(jìn)行增強(qiáng),以完善劇情并生成相應(yīng)的圖像。其中一個(gè) LoRA 負(fù)責(zé)生成 Stable Diffusion 提示詞,以便使用本地部署的 Stable Diffusion XL 模型創(chuàng)建視覺(jué)效果。同時(shí),另一個(gè)針對(duì)劇情寫作進(jìn)行微調(diào)的 LoRA 可以編寫出結(jié)構(gòu)合理、引人入勝的敘事內(nèi)容。
在這種情況下,兩次推理均使用相同的模型,這可確保推理過(guò)程所需的空間不會(huì)顯著增加。第二次推理涉及文本和圖像生成,采用批量推理的方式執(zhí)行。這使得整個(gè)過(guò)程能夠在 NVIDIA GPU 上異常快速且高效地推進(jìn)。這樣一來(lái),用戶便能快速迭代不同版本的劇情,輕松完善敘事和插圖。
LLM 正在成為現(xiàn)代 AI 的一大重要組成部分。隨著采用率和集成率的提升,對(duì)于功能強(qiáng)大、速度快、具有特定于應(yīng)用的定制功能的 LLM 的需求也將與日俱增。RTX AI Toolkit 新增的多 LoRA 支持可為開發(fā)者提供強(qiáng)有力的全新方法來(lái)加速滿足上述需求。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4978瀏覽量
102989 -
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268888 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809
原文標(biāo)題:不同凡響:NVIDIA RTX AI Toolkit 現(xiàn)提供多 LoRA 支持
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
研華科技全員積極擁抱AI時(shí)代
NVIDIA RTX和AI技術(shù)為STEM學(xué)習(xí)增添動(dòng)力
NVIDIA助力企業(yè)創(chuàng)建定制AI應(yīng)用
NVIDIA RTX AI套件簡(jiǎn)化AI驅(qū)動(dòng)的應(yīng)用開發(fā)
RTX AI PC和工作站提供強(qiáng)大AI性能
NVIDIA Studio技術(shù)如何改善創(chuàng)意工作流
Nvidia 再推出特供版顯卡 GeForce RTX 5090D

NVIDIA推出用于支持在全新GeForce RTX AI筆記本電腦上運(yùn)行的AI助手及數(shù)字人
NVIDIA宣布全面推出 NVIDIA ACE 生成式 AI 微服務(wù)
NVIDIA發(fā)布兩款新的專業(yè)顯卡RTX A1000、RTX A400

NVIDIA數(shù)字人技術(shù)加速部署生成式AI驅(qū)動(dòng)的游戲角色

NVIDIA RTX 5090痛失512位顯存!

TensorRT LLM加速Gemma!NVIDIA與谷歌牽手,RTX助推AI聊天
NVIDIA展示游戲、創(chuàng)作、生成式AI和機(jī)器人領(lǐng)域的創(chuàng)新成果
NVIDIA發(fā)布中國(guó)定制版RTX 4090D






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論