 視頻目標跟蹤從0到1,概念與方法
視頻目標跟蹤從0到1,概念與方法
作者:ANKIT SACHAN來源:AI公園 -ronghuaiyang
導讀
從目標跟蹤的應用場景,底層模型,組件,類型和具體算法幾個方面對目標跟蹤做了全方面的介紹,非常好的入門文章。
在今天的文章中,我們將深入研究視頻目標跟蹤。我們從基礎開始,了解目標跟蹤的需求,然后了解視覺目標跟蹤的挑戰和算法模型,最后,我們將介紹最流行的基于深度學習的目標跟蹤方法,包括MDNET, GOTURN, ROLO等。本文希望你了解目標檢測。
目標跟蹤是在視頻中隨著時間的推移定位移動目標的過程。我們可以簡單地問,為什么我們不能在整個視頻的每一幀中使用目標檢測,然后我們可以再去跟蹤目標。這會有一些問題。如果圖像有多個物體,那么我們就無法將當前幀中的物體鏈接到前一幀中。如果你跟蹤的物體有幾幀不在鏡頭里,然后重新又出現,我們無法知道它是否是同一物體。本質上,在檢測過程中,我們一次只處理一張圖像,我們不知道物體的運動和過去的運動,所以我們不能在視頻中唯一地跟蹤物體。目標跟蹤在計算機視覺中有著廣泛的應用,如監視、人機交互、醫學成像、交通流監測、人類活動識別等。比如FBI想用全市的監控攝像頭追蹤一名駕車逃跑的罪犯。或者有一個需要分析足球比賽的體育分析軟件。或者你想在購物中心的入口處安裝一個攝像頭,然后計算每個小時有多少人進出,你不僅要對人進行跟蹤,還要為每個人創建路徑,如下所示。

當檢測失敗的時候,跟蹤可以接替工作
當視頻中有一個移動的物體時,在某些情況下,物體的視覺外觀并不清楚。在所有這些情況下,檢測都會失敗而跟蹤會成功,因為它也有物體的運動模型和歷史記錄。下面是一些例子,其中有目標跟蹤在工作和目標檢測失敗的情況:
- 遮擋:所述目標被部分或完全遮擋
- 身份切換:兩個目標交叉后,你如何知道哪個是哪個。
- 運動模糊:物體由于物體或相機的運動而被模糊。因此,從視覺上看,物體看起來不再一樣了。
- 視點變化:一個物體的不同視點在視覺上可能看起來非常不同,如果沒有上下文,僅使用視覺檢測就很難識別該物體。
- 尺度變化:物體尺度變化過大可能導致檢測失敗。
- 背景雜亂:目標附近的背景與目標有相似的顏色或紋理。因此,從背景中分離物體會變得更加困難。
- 光照變化:目標物體附近的光照顯著改變。因此,從視覺上識別它可能會變得更加困難。
低分辨率:當ground truth包圍框內的像素點非常少時,可能會在視覺上難以檢測到目標。
底層模型
目標跟蹤是計算機視覺中一個古老而又困難的問題。有各種各樣的技術和算法試圖用各種不同的方式來解決這個問題。然而,大多數的技術依賴于兩個關鍵的東西:
1. 運動模型
一個好的跟蹤器的關鍵部件之一是理解和建模目標的運動的能力。因此,一個運動模型被開發來捕捉一個物體的動態行為。預測物體在未來幀中的潛在位置,從而減少搜索空間。然而,只有運動模型可能會失敗,因為物體可能會不在視頻中,或者方向和速度發生突變。早期的一些方法試圖了解物體的運動模式并預測它。然而,這些方法的問題是,他們不能預測突然的運動和方向變化。這些技術的例子有光流,卡爾曼濾波,kanad-lucas-tomashi (KLT)特征跟蹤,mean shift跟蹤。
2. 視覺外觀模型
大多數高度精確的跟蹤器需要了解他們正在跟蹤的目標的外觀。最重要的是,他們需要學會從背景中辨別物體。在單目標跟蹤器中,僅視覺外觀就足以跨幀跟蹤目標,而在多目標跟蹤器中,僅視覺外觀是不夠的。
跟蹤算法的幾個組件
一般來說,目標跟蹤過程由四個模塊組成:
1、目標初始化:在此階段,我們需要通過在目標周圍繪制一個邊框來定義目標的初始狀態。我們的想法是在視頻的初始幀中繪制目標的邊界框,跟蹤器需要估計目標在視頻剩余幀中的位置。
2、外觀建模:現在需要使用學習技術學習目標的視覺外觀。在這個階段,我們需要建模并了解物體在運動時的視覺特征、包括在各種視點、尺度、光照的情況下。
3、運動估計:運動估計的目的是學習預測后續幀中目標最有可能出現的區域。
4、目標定位:運動估計給出了目標可能出現的區域,我們使用視覺模型掃描該區域鎖定目標的確切位置。一般來說,跟蹤算法不會嘗試學習目標的所有變化。因此,大多數跟蹤算法都比目標檢測快得多。
跟蹤算法的類型
1. 基于檢測與不需要檢測的跟蹤器
1.1 基于檢測的跟蹤:將連續的視頻幀給一個預先訓練好的目標檢測器,該檢測器給出檢測假設,然后用檢測假設形成跟蹤軌跡。它更受歡迎,因為可以檢測到新的目標,消失的目標會自動終止。在這些方法中,跟蹤器用于目標檢測失敗的時候。在另一種方法中,目標檢測器對每n幀運行,其余的預測使用跟蹤器完成。這是一種非常適合長時間跟蹤的方法。1.2 不需要檢測的跟蹤:不需要檢測的跟蹤需要手動初始化第一幀中固定數量的目標。然后在后續的幀中定位這些目標。它不能處理新目標出現在中間幀中的情況。
2. 單目標和多目標跟蹤器
2.1 單目標跟蹤:即使環境中有多個目標,也只跟蹤一個目標。要跟蹤的目標由第一幀的初始化確定。2.2 多目標跟蹤:對環境中存在的所有目標進行跟蹤。如果使用基于檢測的跟蹤器,它甚至可以跟蹤視頻中間出現的新目標。
3. 在線和離線跟蹤器
3.1 離線跟蹤器:當你需要跟蹤已記錄流中的物體時,使用離線跟蹤器。例如,如果你錄制了對手球隊的足球比賽視頻,需要進行戰略分析。在這種情況下,你不僅可以使用過去的幀,還可以使用未來的幀來進行更準確的跟蹤預測。3.2 在線跟蹤器:在線跟蹤器用于即時預測,因此,他們不能使用未來幀來改善結果。
4. 基于學習和基于訓練的策略
4.1 在線學習跟蹤器:這些跟蹤器通常使用初始化幀和少量后續幀來了解要跟蹤的目標。這些跟蹤器更通用因為你可以在任何目標周圍畫一個框并跟蹤它。例如,如果你想在機場跟蹤一個穿紅襯衫的人,你可以在一個或幾個幀內,在這個人周圍畫一個邊界框,跟蹤器通過這些框架了解目標物體,并繼續跟蹤那個人。
在線學習跟蹤器的核心思想是:中心的紅色方框由用戶指定,以它為正樣本,所有圍繞著目標的方框作為負樣本,訓練一個分類器,學習如何將目標從背景中區分出來。
4.2 離線學習跟蹤器:這些跟蹤器的訓練只在離線進行。與在線學習跟蹤器不同,這些跟蹤器在運行時不學習任何東西。這些跟蹤器在線下學習完整的概念,也就是說,我們可以訓練跟蹤器來識別人。然后這些跟蹤器可以用來連續跟蹤視頻流中的所有人。
流行的跟蹤算法
OpenCV的跟蹤API中集成了很多傳統的(非深度學習的)跟蹤算法。相對而言,大多數跟蹤器都不是很準確。但是,有時它們在資源有限的環境(如嵌入式系統)中運行會很有用。如果你不得不使用一個,我建議使用核相關過濾器(KCF)跟蹤器。然而,在實踐中,基于深度學習的跟蹤器在準確性方面遠遠領先于傳統跟蹤器。因此,在這篇文章中,我將討論用于構建基于AI的跟蹤器的三種關鍵方法。
1. 基于卷積神經網絡的離線訓練跟蹤器
這是早期的一系列跟蹤器之一,它將卷積神經網絡的識別能力應用于視覺目標跟蹤任務。GOTURN就是一種基于卷積神經網絡的離線學習跟蹤器,它根本不用在線學習。首先,跟蹤器使用成千上萬的視頻訓練一般目標的跟蹤。現在,這個跟蹤器可以用來毫無問題地跟蹤大多數目標即使這些目標不屬于訓練集。
GOTURN可以在GPU驅動的機器上運行非常快,即100fps。GOTURN已經集成到OpenCV跟蹤API(contrib部分)中。在下面的視頻鏈接中,原作者展示了GOTURN的能力。
2. 基于卷積神經網絡的在線訓練跟蹤器
這些是使用卷積神經網絡的在線訓練跟蹤器。其中一個例子就是多域網絡(MDNet),它是VOT2015挑戰賽的獲勝者。由于卷積神經網絡的訓練在計算上非常昂貴,所以這些方法在部署期間必須使用較小的網絡以快速訓練。然而,較小的網絡并沒有太多的區分能力。一種選擇是我們訓練整個網絡,但在推理過程中,我們使用前幾層作為特征提取器,也就是說,我們只改變在線訓練的最后幾層的權值。因此,我們用CNN作為特征提取器,最后幾層可以快速在線訓練。本質上,我們的目標是訓練一個能區分目標和背景的通用多域CNN。然而,這在訓練中帶來了一個問題,一個視頻的目標可能是另一個視頻的背景,這只會讓我們的卷積神經網絡混淆。因此,MDNet做了一些聰明的事情。它將網絡重新安排為兩部分:第一部分是共享部分,然后有一部分是獨立于每個域的。每個域意味著一個獨立的訓練視頻。首先在k個域上迭代訓練網絡,每個域都在目標和背景之間進行分類。這有助于我們提取獨立于視頻的信息,以便更好地學習跟蹤器的通用表示。
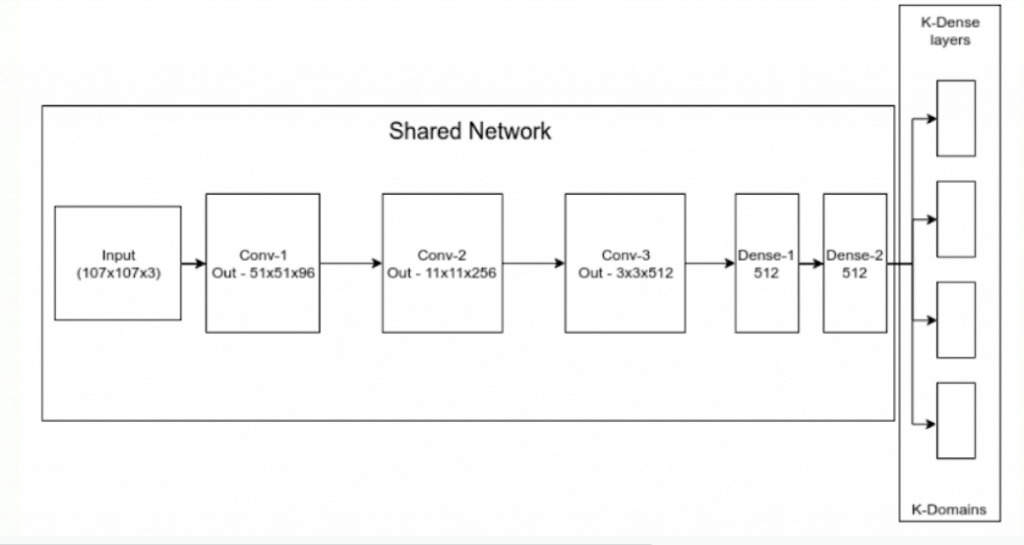
經過訓練,去除領域特定的二分類層,我們得到了一個特征提取器(上文共享網絡),它可以以通用的方式區分任何目標和背景。在推理(生產)過程中,最初的共享部分被用作特征提取器,刪除特定的領域層,并在特征提取器之上添加二分類層。這個二分類層是在線訓練的。在每一步中,通過隨機抽樣的方式搜索前一個目標狀態周圍的區域來尋找目標。MDNet是一種最精確的基于深度學習的在線訓練,不需要檢測,單目標跟蹤。
3. 基于LSTM+ CNN的基于視頻的目標跟蹤器
另一類目標跟蹤器非常流行,因為它們使用長短期記憶(LSTM)網絡和卷積神經網絡來完成視覺目標跟蹤的任。循環YOLO (ROLO)就是這樣一種單目標、在線、基于檢測的跟蹤算法。該算法使用YOLO網絡進行目標檢測,使用LSTM網絡進行目標軌跡檢測。LSTM與CNN的結合是厲害的,原因有二。a) LSTM網絡特別擅長歷史模式的學習,特別適合于視覺目標跟蹤。b) LSTM網絡的計算成本不是很高,因此可以構建非常快速的真實世界跟蹤器。
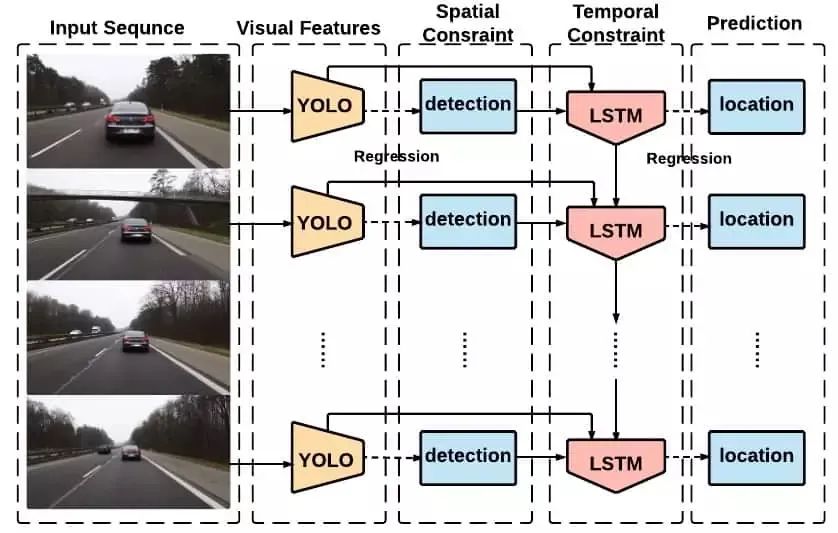
YOLO INPUT – 原始輸入幀
YOLO OUTPUT– 輸入幀中包圍框坐標的特征向量
LSTM INPUT – 拼接(圖像特征,包圍框坐標)
LSTM OUTPUT– 被跟蹤目標的包圍框坐標上面的圖我們這樣理解:
- 輸入幀通過YOLO網絡。
- 從YOLO網絡得到兩個不同的輸出(圖像特征和邊界框坐標)
- 這兩個輸出送到LSTM網絡
LSTM輸出被跟蹤目標的軌跡,即包圍框
初步的位置推斷(來自YOLO)幫助LSTM注意某些視覺元素。ROLO探索了時空上的歷史,即除了地理位置的歷史,ROLO還探索了視覺特征的歷史。即使當YOLO的檢測是有缺陷的,比如運動模糊,ROLO也能保持穩定跟蹤。此外,當目標物體被遮擋時,這樣的跟蹤器不太會失敗。最近,有更多基于LSTM的目標跟蹤器,它們通過許多改進比ROLO好得多。但是,我們在這里選擇了ROLO,因為它簡單且容易理解。希望這篇文章能讓你對視覺目標跟蹤有一個很好的理解,并對一些成功的關鍵目標跟蹤方法有一些見解。
英文原文:https://cv-tricks.com/object-tracking/quick-guide-mdnet-goturn-rolo/
-
視頻
+關注
關注
6文章
1942瀏覽量
72884 -
目標跟蹤
+關注
關注
2文章
88瀏覽量
14881 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
發布評論請先 登錄
相關推薦
基于OPENCV的運動目標跟蹤實現
視頻運動目標跟蹤系統設計

視頻序列中運動目標檢測與跟蹤的方法有哪些詳細資料說明






 工商網監
工商網監
評論