") CPU推理:AI算力配置新范式
CPU推理:AI算力配置新范式

在當(dāng)前的人工智能領(lǐng)域,尤其是涉及到深度學(xué)習(xí)的推理階段,行業(yè)普遍認(rèn)為GPU是唯一的選擇。然而,GPU的成本相對(duì)較高,且對(duì)于某些特定的應(yīng)用場(chǎng)景,其高昂的價(jià)格和較高的能耗成為了一大負(fù)擔(dān)。
相比之下,CPU作為一種性?xún)r(jià)比極高的推理硬件,逐漸進(jìn)入了人們的視野,尤其是在對(duì)結(jié)果準(zhǔn)確度有較高要求且需要考慮成本效益的行業(yè)中,如制造業(yè)、圖像處理與分析等。經(jīng)過(guò)數(shù)年的內(nèi)部研究,阿丘科技的工業(yè)AI視覺(jué)算法平臺(tái)軟件AIDI已經(jīng)成功驗(yàn)證了CPU推理的可行性,為行業(yè)提供了新的解決方案。
具體應(yīng)用場(chǎng)景01
舊產(chǎn)線(xiàn)改造
許多制造企業(yè)的生產(chǎn)線(xiàn)啟動(dòng)時(shí)間較早,初期采用的傳統(tǒng)算法并不過(guò)多依賴(lài)于GPU資源。隨著時(shí)間的發(fā)展,這些產(chǎn)線(xiàn)的主板可能無(wú)法支持新增的GPU、NPU、TPU等加速卡。
在這種情況下,如果企業(yè)希望在其生產(chǎn)線(xiàn)上添加AI檢測(cè)功能,全面更換工控機(jī)會(huì)導(dǎo)致成本激增,并延長(zhǎng)上線(xiàn)周期。通過(guò)使用AIDI提供的CPU推理模式,企業(yè)可以迅速實(shí)現(xiàn)AI檢測(cè)功能的上線(xiàn),同時(shí)避免了高昂的硬件升級(jí)費(fèi)用。
相關(guān)詞語(yǔ)解釋?zhuān)?/strong>
CPU(中央處理器,Central Processing Unit)
CPU是計(jì)算機(jī)的主要處理單元,負(fù)責(zé)執(zhí)行系統(tǒng)中的大部分基本指令集,包括算術(shù)邏輯運(yùn)算、控制單元的功能以及數(shù)據(jù)的移動(dòng)等。它通常設(shè)計(jì)為能夠高效地處理廣泛的任務(wù),從運(yùn)行操作系統(tǒng)到執(zhí)行應(yīng)用程序的各種任務(wù)。
GPU(圖形處理器,Graphics Processing Unit)
GPU最初是為加速計(jì)算機(jī)圖形渲染而設(shè)計(jì)的處理器,但現(xiàn)在其應(yīng)用范圍已經(jīng)遠(yuǎn)遠(yuǎn)超出了圖形處理領(lǐng)域。GPU擁有大量的核心,能夠并行處理大量數(shù)據(jù),這使得它們?cè)趫D像和視頻處理、深度學(xué)習(xí)、科學(xué)計(jì)算等領(lǐng)域非常有用。
NPU(神經(jīng)網(wǎng)絡(luò)處理器,Neural Network Processing Unit)
NPU是一種專(zhuān)門(mén)為處理機(jī)器學(xué)習(xí)算法而設(shè)計(jì)的微處理器,尤其是針對(duì)深度學(xué)習(xí)任務(wù)。NPU優(yōu)化了對(duì)向量和矩陣運(yùn)算的支持,這些運(yùn)算是神經(jīng)網(wǎng)絡(luò)訓(xùn)練和推理過(guò)程中的基礎(chǔ)。
TPU(張量處理單元,Tensor Processing Unit)
TPU是由谷歌開(kāi)發(fā)的一種定制ASIC(專(zhuān)用集成電路),專(zhuān)門(mén)用于加速機(jī)器學(xué)習(xí)工作負(fù)載,特別是針對(duì)使用TensorFlow框架的應(yīng)用程序。TPU能夠高效地執(zhí)行大規(guī)模的矩陣運(yùn)算,這對(duì)于訓(xùn)練和推斷階段的深度學(xué)習(xí)模型至關(guān)重要。
02
輕量型項(xiàng)目
對(duì)于一些新的項(xiàng)目,尤其是那些算力需求較小的場(chǎng)景(如圖像小于500萬(wàn)像素,僅需進(jìn)行圖像分類(lèi)或單圖推理,且可接受100毫秒的延遲),使用單個(gè)GPU卡往往無(wú)法達(dá)到滿(mǎn)負(fù)荷運(yùn)行的狀態(tài),從而造成資源浪費(fèi)。
這類(lèi)項(xiàng)目非常適合采用CPU進(jìn)行推理,訓(xùn)練階段則可以利用GPU工控機(jī)或云端資源。這種方法不僅能夠顯著降低硬件采購(gòu)成本,還能確保項(xiàng)目的順利推進(jìn)。
03
舊產(chǎn)線(xiàn)改造的具體情形
如下圖所示,通過(guò)傳統(tǒng)算法進(jìn)行項(xiàng)目的測(cè)量與檢測(cè),硬件配置主要為CPU+內(nèi)存+主板。
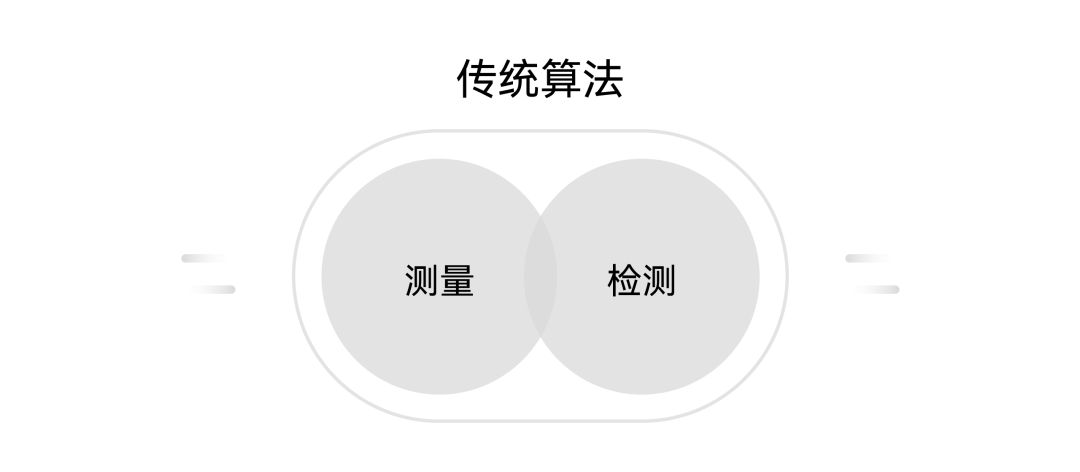
圖:舊產(chǎn)線(xiàn)
目前,舊產(chǎn)線(xiàn)改造通常有以下兩種情形。
情形一:硬件配置基本不變,即CPU+內(nèi)存+主板,通過(guò)傳統(tǒng)算法做測(cè)量,而利用AI算法做外觀檢測(cè)。
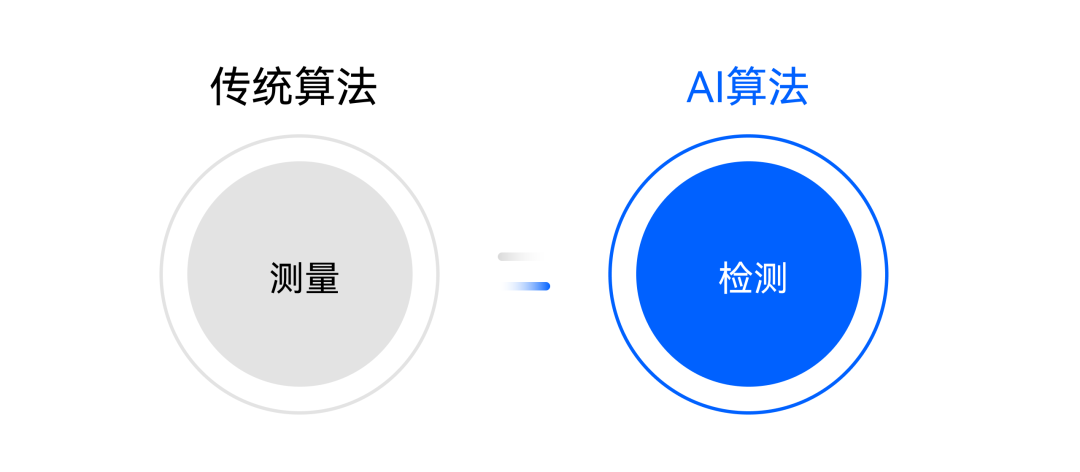
圖:情形一
情形二:硬件配置基本不變,即CPU+內(nèi)存+主板,通過(guò)傳統(tǒng)算法做測(cè)量與外觀檢測(cè),而利用AI算法做缺陷復(fù)判。
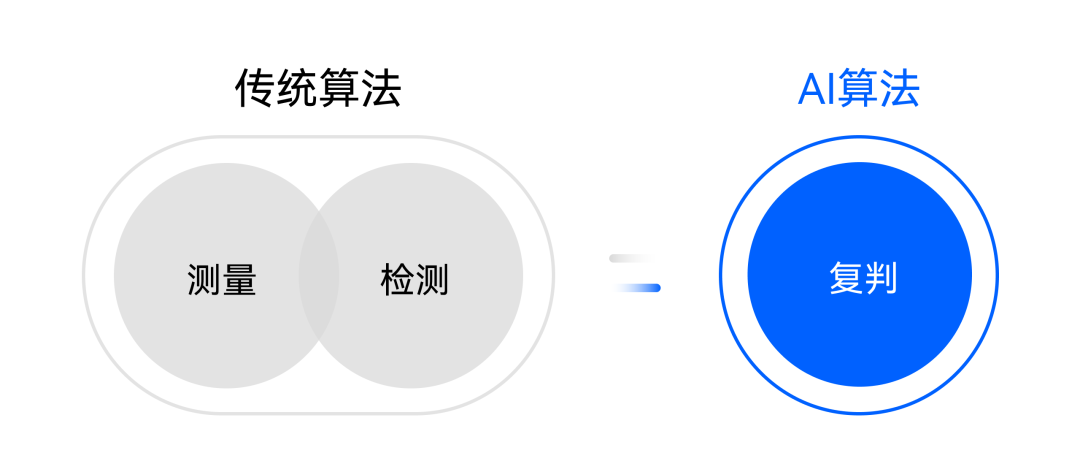
圖:情形二AIDI-CPU推理的優(yōu)勢(shì)01
推理速度比肩GTX1060,500萬(wàn)圖像像素級(jí)推理僅需50ms
AIDI的CPU推理在速度方面表現(xiàn)出色,其底層采用DefectNet網(wǎng)絡(luò)+Aqinfer推理引擎的創(chuàng)新模式。
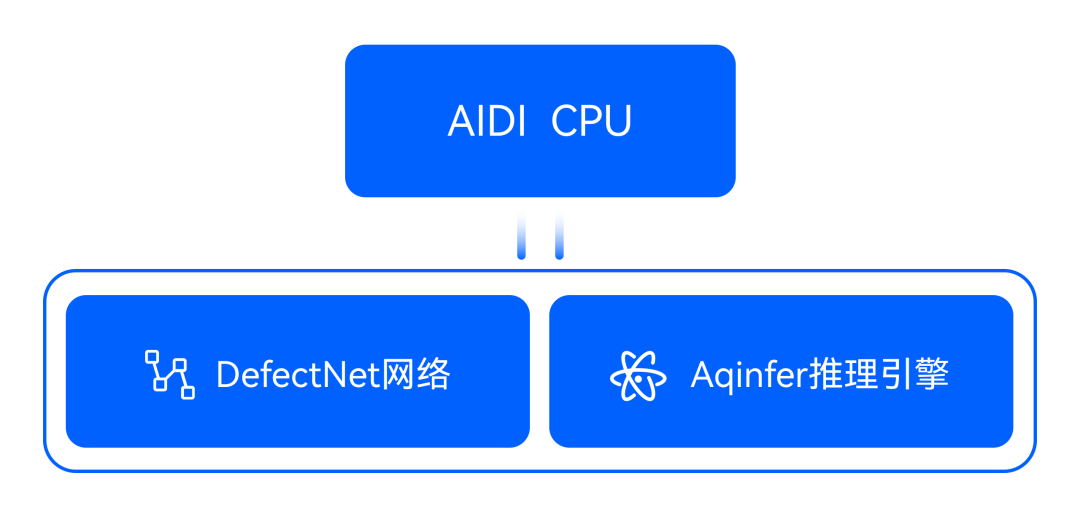
DefectNet網(wǎng)絡(luò)專(zhuān)門(mén)針對(duì)工業(yè)數(shù)據(jù)的特性而設(shè)計(jì),具備輕量且檢測(cè)能力強(qiáng)的特點(diǎn)。Aqinfer自研推理引擎則針對(duì)工業(yè)場(chǎng)景中圖像分辨率高、目標(biāo)小的特點(diǎn),在原本就較高的推理速度基礎(chǔ)上,進(jìn)一步優(yōu)化計(jì)算速度。
02
節(jié)省硬件成本,降低耗能風(fēng)險(xiǎn)
CPU在市場(chǎng)上供應(yīng)充足,價(jià)格相對(duì)更為親民,相較于一些高性能GPU,CPU的獲取成本更低。對(duì)于企業(yè)來(lái)說(shuō),尤其是預(yù)算有限的中小企業(yè),選擇CPU推理可以在不犧牲太多性能的前提下,大幅降低硬件采購(gòu)成本。
以一家小型服裝加工廠(chǎng)為例,在引入AI檢測(cè)系統(tǒng)時(shí),如果選擇GPU方案,高昂的硬件成本可能使其望而卻步;而采用CPU推理方案,僅需利用現(xiàn)有的工控機(jī)資源,就能實(shí)現(xiàn)基本的質(zhì)量檢測(cè)功能。
同時(shí),GPU的高功耗不僅增加了企業(yè)的用電成本,還會(huì)導(dǎo)致設(shè)備硬件容易因過(guò)熱等問(wèn)題而損壞。相比之下,CPU的功耗較低,運(yùn)行更加穩(wěn)定,能夠有效降低企業(yè)的能耗風(fēng)險(xiǎn)和設(shè)備維護(hù)成本。在長(zhǎng)期運(yùn)行過(guò)程中,這一優(yōu)勢(shì)將為企業(yè)節(jié)省大量的資金和人力投入。
03
快速驗(yàn)證,減少額外投資
利用CPU進(jìn)行AI推理,企業(yè)可以充分挖掘既有平臺(tái)的空閑算力,避免了為新的算力需求而進(jìn)行大規(guī)模的額外投資。在項(xiàng)目的初期驗(yàn)證階段,CPU推理能夠快速搭建起一個(gè)低成本的測(cè)試環(huán)境,幫助企業(yè)快速驗(yàn)證AI算法的可行性和有效性。例如,視覺(jué)團(tuán)隊(duì)可以先在現(xiàn)有的服務(wù)器上利用CPU進(jìn)行算法驗(yàn)證,根據(jù)驗(yàn)證結(jié)果再?zèng)Q定是否需要進(jìn)一步投資更強(qiáng)大的GPU算力。
成功案例
在某膠體檢測(cè)項(xiàng)目中,產(chǎn)品的檢測(cè)項(xiàng)涵蓋少膠、溢膠、斷膠、漏膠等關(guān)鍵指標(biāo)。老設(shè)備方案中,膠水識(shí)別采用的是傳統(tǒng)算法,但在實(shí)際應(yīng)用中,偶爾會(huì)出現(xiàn)定位不準(zhǔn)的問(wèn)題,這對(duì)產(chǎn)品質(zhì)量產(chǎn)生了一定的影響。為了提高檢測(cè)精度,降低過(guò)檢率,企業(yè)決定引入AI檢測(cè)方案。
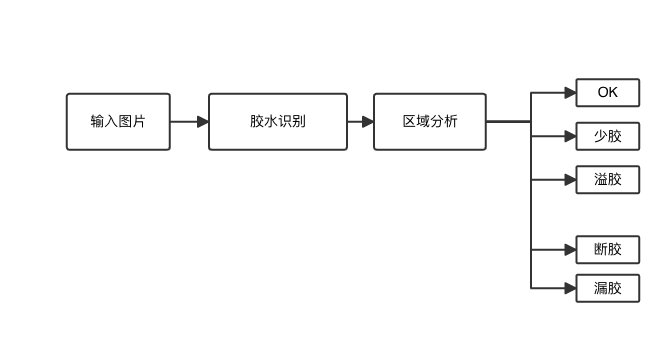
由于新增GPU需要對(duì)工控機(jī)配置進(jìn)行復(fù)雜的修改,并且采購(gòu)流程耗時(shí)較長(zhǎng),為了確保產(chǎn)線(xiàn)的正常運(yùn)行,不耽誤生產(chǎn)進(jìn)度,項(xiàng)目團(tuán)隊(duì)最終選擇了CPU推理方案。經(jīng)過(guò)實(shí)際測(cè)試和驗(yàn)證,該方案能夠直接上線(xiàn),并且取得了令人滿(mǎn)意的效果。
在此次項(xiàng)目中,圖像分辨率為1000W,客戶(hù)要求的CT(Cycle Time,周期時(shí)間)為1000ms,而實(shí)際CT時(shí)間僅為500ms,單圖推理時(shí)間更是縮短至100ms,完全滿(mǎn)足了上線(xiàn)要求。這一案例充分證明了阿丘科技AIDI的CPU推理在實(shí)際工業(yè)場(chǎng)景中的可行性和有效性,為其他類(lèi)似項(xiàng)目提供了寶貴的參考經(jīng)驗(yàn)。
綜上,CPU推理作為AI算力配置的新范式,在特定的應(yīng)用場(chǎng)景中展現(xiàn)出了獨(dú)特的優(yōu)勢(shì)。隨著技術(shù)的不斷發(fā)展和優(yōu)化,相信阿丘科技AIDI的CPU推理將在更多領(lǐng)域得到廣泛應(yīng)用,為企業(yè)的智能化轉(zhuǎn)型提供更加經(jīng)濟(jì)、高效的解決方案。
-
cpu
+關(guān)注
關(guān)注
68文章
10854瀏覽量
211578 -
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238252 -
AI算力
+關(guān)注
關(guān)注
0文章
72瀏覽量
8652
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
企業(yè)AI算力租賃是什么
AI推理CPU當(dāng)?shù)溃珹rm驅(qū)動(dòng)高效引擎

AI時(shí)代算力的重要性及現(xiàn)狀:平衡發(fā)展與優(yōu)化配置的挑戰(zhàn)
GPU算力開(kāi)發(fā)平臺(tái)是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】--全書(shū)概覽
青云科技強(qiáng)化AI算力架構(gòu),升級(jí)產(chǎn)品與服務(wù)體系
名單公布!【書(shū)籍評(píng)測(cè)活動(dòng)NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析
大模型時(shí)代的算力需求
如何基于OrangePi?AIpro開(kāi)發(fā)AI推理應(yīng)用

中國(guó)移動(dòng)發(fā)布基于飛騰CPU自主研發(fā)的賦能AI算力時(shí)代的新產(chǎn)品

AMD推出銳龍8000嵌入式處理器,AI算力高達(dá)39 T
256Tops算力!CSA1-N8S1684X算力服務(wù)器


立足算力,聚焦AI!順網(wǎng)科技全面走進(jìn)AI智算時(shí)代






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論