 飛龍入海:ANSYS官方的大模型應用
飛龍入海:ANSYS官方的大模型應用
寫在前面的話
大模型差不多是一項發明,其重要性不亞于電的發現和電燈的發明。
大模型的基礎是使用Transformer算法識別了人類語言(大致等同于人類的思維邏輯)的內在關系和特征,學習了海量知識的內在關聯規律,并以人們需要的形式進行輸出。
大模型在通用代碼編制方面已經展現了強大的能力,那么對于細分行業的代碼編程是否具有輔助價值?
ANSYS官方發表了以下這篇大模型輔助Redhawk MapReduce建模的方法。
大模型與工程仿真代碼
大型語言模型 (LLM) 在自然語言處理 (NLP) 的發展中發揮著重要作用,在各種應用中展示了非凡的多功能性,包括特定領域的問答和代碼生成 。顯著的進步導致了最先進的模型,如 GPT-4 、Claude 和 Mistral,后者集成了 “Mixture-Experts” (MoE)。
檢索增強生成 (RAG) 框架被廣泛用于通過從外部數據庫中檢索事實內容來增強專業領域的 LLM,從而減輕幻覺并提高性能。這種方法涉及將數據解析為字符有限的重疊片段,并將它們轉換為基于向量的檢索的嵌入,從而賦予 LLM 精確的特定領域知識。
代碼生成是 LLM 的一個關鍵應用,但它在特定領域的工程任務中提出了各種挑戰,例如在 Ansys RedHawk-SC (RH-SC) 平臺上的任務。在這里,由于任務的復雜性和缺乏編碼專業知識,用戶經常難以創建 MapReduce (注)Python 腳本。通過自然語言指令自動生成此腳本可以顯著提高工作效率并增強用戶體驗。
MapReducePython 代碼不僅需要對 RH-SC 架構有深入的了解,還需要復雜電路設計方面的專業知識。缺乏全面的技術文檔和稀缺的電子設計自動化 (EDA) 在線資源使 LLM 難以獲得必要的領域知識。
雖然 ChatEDA 試圖通過微調 Llama2和在開源 EDA 工具上實現自規劃代碼生成來解決這些問題,但這種方法成本高昂。其他方法,如 TestPilot和 Veri-Gen已經顯示出在我們的專業上下文中生成代碼的局限性。
為了克服這些挑戰,ANSYS提出了基于 RAG 的新方法,而無需對 LLM 進行任何形式的預訓練或微調。其中的Data Splitter 和 Data Renovation 技術改進了語義文本分割并豐富了段落內容,從而避免了直接文檔提取的典型混亂。這些方法顯著提高了 RAG 的嵌入準確性,從而更有效地檢索信息,從而提高了超越傳統字符計數分割技術的整體性能。同時引入一種新穎的提示技術 Implicit Knowledge Expansion and Contemplation (IKEC),將 IKEC 與思維鏈 (CoT) 方法相結合,以探索潛在的性能改進。
通過實現這些數據預處理和自規劃代碼生成提示策略,可以生成符合用戶需求的腳本。經過 180 多位ANSYS專家的投票,結果證實了Splitter 和 Renovation 方法顯著提高了代碼生成的質量。
框架
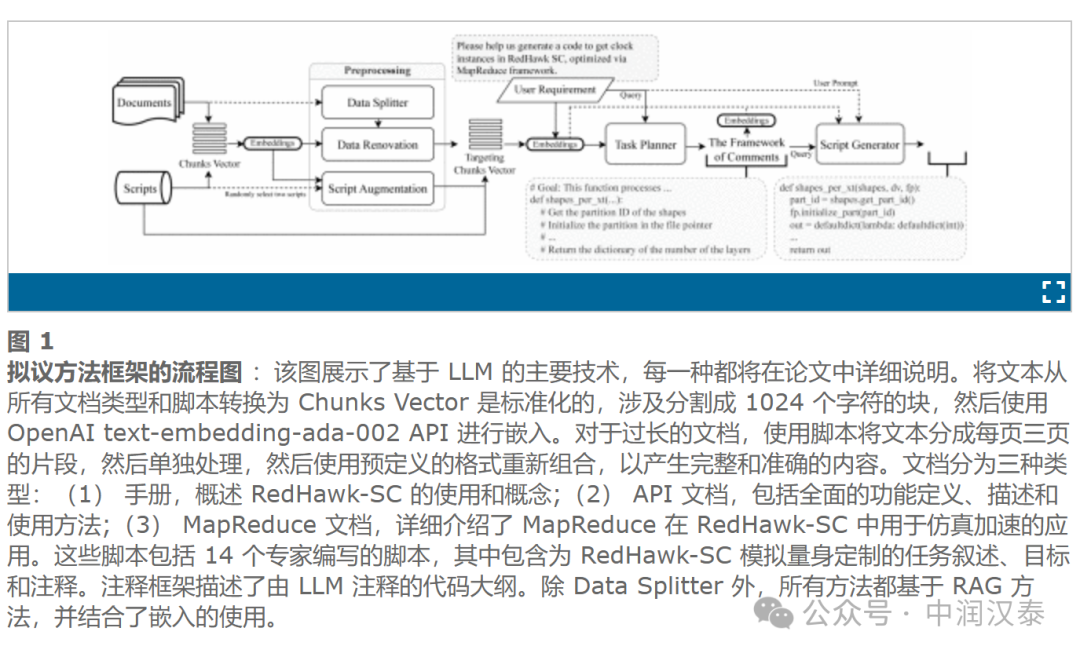
Splitter
RAG 方法的有效性取決于文本的相關性,由嵌入計算確定。傳統的 RAG 技術通常按字符數對文本進行分段,可能會產生缺乏主題焦點的塊。因此,這些塊生成的嵌入不能充分表示目標主題,從而降低了檢索高質量文本內容的可能性。
Data Splitter 通過對文本進行語義分割來解決此問題,專注于有意義的單元,例如 API 函數和概念,同時保留原始文本格式并糾正格式問題。我們將文本分割成固定的頁面單位,讓 LLM 確定段落的完整性。不完整的句段將保持未閉合狀態,從而促進無縫后處理以組合完整的段落。
如下圖所示,數據拆分器將提取的文檔內容精確劃分為不同的、集中的片段,從而有效地解決可能出現的格式問題。確定在何處拆分文本的任務類似于“二元分類問題”,這對于 LLM 來說相對簡單。因此,使用 LLM 來完成這項任務,在這種情況下放棄使用 RAG 技術。

Data Renovation
Data Renovation 解決了技術文檔通常簡潔性所帶來的挑戰。它使 LLM 能夠有條不紊地用易于理解的知識豐富每個段落,從而增強嵌入——即使 LLM 已經熟悉這些知識。我們利用 LlamaIndex 提供的 RAG 框架為原始文檔和腳本提供深深植根于源材料上下文的補充內容,從而確保信息的可靠性。
Data Splitter 處理的每個段落隨后按順序更新。從圖中值得注意的是,翻新一絲不茍地納入了內容中提到的關鍵術語的額外細節。
Script Augmentation
獲取帶有詳細注釋的腳本通常是一項具有挑戰性的工作。在只有有限數量的此類腳本可用的情況下,如果我們提示 LLM 基于參考腳本生成“全新”腳本,由于 LLM 的專業知識有限,結果通常是混亂的輸出。如圖 2 所示,隨機選擇了兩個腳本,并采用 RAG 框架來鼓勵在創建具有明確、特定于任務目的的新腳本時進行 “重大結構更改”(重建)。此方法可確保生成的腳本具有令人滿意的質量。通過重復生成結構多樣的腳本,可以豐富腳本增強的參考資料庫。
隱性知識擴展與沉思 (IKEC)
IKEC技術是我們在工作中開發的一種新穎方法,旨在促使LLM利用自己的知識庫在內部擴展和豐富它最有信心的內容。這個過程涉及 LLM 在得出最終結果之前進行深思熟慮和深入的思考。此外,我們還嘗試將這項技術與 CoT 流程集成,這是出于對哪些內部提示可能有助于 LLM 性能的好奇心。
結論
本文介紹了在特定領域問題中提高 LLM 的 RAG 性能的四個顯著貢獻:數據拆分、數據更新、腳本增強和 IKEC。通過對文本進行語義分割和以高 LLM 置信度更新內容,這些技術有助于在 RAG 的數據檢索過程中改進以主題為中心的嵌入。Data Splitter 和 Data Renovation 技術在數據源級別增強嵌入的新應用特別具有創新性。
這些貢獻的有效性已通過涉及ANSYS 28 名領域專家的小組和 182 票分析的全面評估得到驗證。結果表明,Data Splitter 和 Data Renovation 方法顯著提高了專業領域內 MapReduce 應用程序中 RHSC 的代碼生成質量。具體來說,歸因于這些方法的改進可量化地大于 CoT,數據拆分器方法的改進是 CoT 提示的 1.43 倍,數據翻新方法的改進是 CoT 的 0.45 倍。
注:MapReduce 是一種編程模型和關聯的實現,用于處理和生成適用于各種實際任務的大型數據集。用戶根據 map 和 reduce 函數指定計算,底層運行時系統會自動在大規模機器集群之間并行計算,處理機器故障,并安排機器間通信以有效利用網絡和磁盤。
-
代碼
+關注
關注
30文章
4779瀏覽量
68521 -
大模型
+關注
關注
2文章
2423瀏覽量
2640 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:飛龍入海:ANSYS官方的大模型應用
文章出處:【微信號:SinoEngineer,微信公眾號:中潤漢泰】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
第8章 時間歷程后處理器--第13章 ANSYS新界面Workbench環境
基于ANSYS的高速磨削電主軸動靜態性能分析
SGS受邀參加Ansys車規芯片功能安全和可靠性研討會
Ansys和英特爾代工合作開發多物理場簽核解決方案
Ansys多物理場解決方案已獲得英特爾代工(Intel Foundry)認證

Ansys業績超預期,新思科技或以350億美元收購
新思科技計劃收購Ansys,350億美元!
Synopsys將以350億美元并購Ansys

新思科技將以350億美元收購Ansys
熱仿真工具Ansys Discovery的使用案例
Ansys宣布推出其最新的基于人工智能(AI)的技術—Ansys SimAI






 工商網監
工商網監
評論