

感謝眾多用戶(hù)及合作伙伴一直以來(lái)對(duì)NVIDIA TensorRT-LLM的支持。TensorRT-LLM 的 Roadmap 現(xiàn)已在 GitHub 上公開(kāi)發(fā)布!
TensorRT-LLM
持續(xù)助力用戶(hù)優(yōu)化推理性能
TensorRT-LLM 可在 NVIDIA GPU 上加速和優(yōu)化最新的大語(yǔ)言模型(Large Language Models)的推理性能。該開(kāi)源程序庫(kù)在 /NVIDIA/TensorRT-LLM GitHub 資源庫(kù)中免費(fèi)提供。
近期,我們收到了許多用戶(hù)的積極反饋,并表示,TensorRT-LLM 不僅顯著提升了性能表現(xiàn),還成功地將其應(yīng)用集成到各自的業(yè)務(wù)中。TensorRT-LLM 強(qiáng)大的性能和與時(shí)俱進(jìn)的新特性,為客戶(hù)帶來(lái)了更多可能性。
Roadmap 現(xiàn)已公開(kāi)發(fā)布
過(guò)往,許多用戶(hù)在將 TensorRT-LLM 集成到自身軟件棧的過(guò)程中,總是希望能更好地了解 TensorRT-LLM 的 Roadmap。即日起,NVIDIA 正式對(duì)外公開(kāi) TensorRT-LLM 的 Roadmap ,旨在幫助用戶(hù)更好地規(guī)劃產(chǎn)品開(kāi)發(fā)方向。
我們非常高興地能與用戶(hù)分享,TensorRT-LLM 的 Roadmap 現(xiàn)已在 GitHub 上公開(kāi)發(fā)布。您可以通過(guò)以下鏈接隨時(shí)查閱:
https://github.com/NVIDIA/TensorRT-LLM
圖 1. NVIDIA/TensorRT-LLM GitHub 網(wǎng)頁(yè)截屏
這份 Roadmap 將為您提供關(guān)于未來(lái)支持的功能、模型等重要信息,助力您提前部署和開(kāi)發(fā)。
同時(shí),在 Roadmap 頁(yè)面的底部,您可通過(guò)反饋鏈接提交問(wèn)題。無(wú)論是問(wèn)題報(bào)告還是新功能建議,我們都期待收到您的寶貴意見(jiàn)。
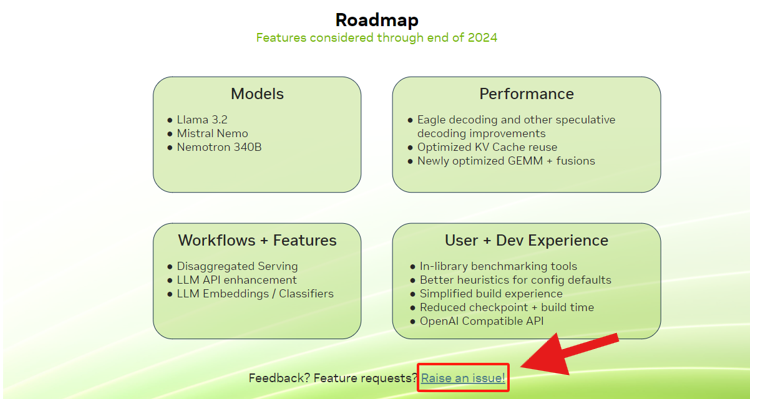
圖 2.Roadmap 整體框架介紹
利用 TensorRT-LLM
優(yōu)化大語(yǔ)言模型推理
TensorRT-LLM 是一個(gè)用于優(yōu)化大語(yǔ)言模型(LLM)推理的庫(kù)。它提供最先進(jìn)的優(yōu)化功能,包括自定義 Attention Kernel、Inflight Batching、Paged KV Caching、量化技術(shù)(FP8、INT4 AWQ、INT8 SmoothQuant 等)以及更多功能,以讓你手中的 NVIDIA GPU 能跑出極致推理性能。
TensorRT-LLM 已適配大量的流行模型。通過(guò)類(lèi)似 PyTorch 的 Python API,可以輕松修改和擴(kuò)展這些模型以滿足自定義需求。以下是已支持的模型列表。

我們鼓勵(lì)所有用戶(hù)定期查閱 TensorRT-LLM Roadmap。這不僅有助于您及時(shí)了解 TensorRT-LLM 的最新動(dòng)態(tài),還能讓您的產(chǎn)品開(kāi)發(fā)與 NVIDIA 的技術(shù)創(chuàng)新保持同步。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5238瀏覽量
105730 -
GitHub
+關(guān)注
關(guān)注
3文章
481瀏覽量
17432 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
677
原文標(biāo)題:NVIDIA TensorRT-LLM Roadmap 現(xiàn)已在 GitHub 上公開(kāi)發(fā)布!
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
小白學(xué)大模型:從零實(shí)現(xiàn) LLM語(yǔ)言模型

使用NVIDIA RTX PRO Blackwell系列GPU加速AI開(kāi)發(fā)
無(wú)法在OVMS上運(yùn)行來(lái)自Meta的大型語(yǔ)言模型 (LLM),為什么?
京東廣告生成式召回基于 NVIDIA TensorRT-LLM 的推理加速實(shí)踐
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

解鎖NVIDIA TensorRT-LLM的卓越性能
如何在 OrangePi 5 Pro?的?NPU?上運(yùn)行?LLM

TensorRT-LLM低精度推理優(yōu)化

Arm推出GitHub平臺(tái)AI工具,簡(jiǎn)化開(kāi)發(fā)者AI應(yīng)用開(kāi)發(fā)部署流程
NVIDIA Nemotron-4 340B模型幫助開(kāi)發(fā)者生成合成訓(xùn)練數(shù)據(jù)

魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
新款Nvidia Titan GPU正在開(kāi)發(fā)中?或?qū)魯∥?b class='flag-5'>發(fā)布的RTX 5090

Mistral Large 2現(xiàn)已在Amazon Bedrock中正式可用
NVIDIA 通過(guò) Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持
NVIDIA 通過(guò) Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持,實(shí)現(xiàn)邊緣實(shí)時(shí)醫(yī)療、工業(yè)和科學(xué) AI 應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論