") Kaggle知識點(diǎn):使用大模型進(jìn)行特征篩選
Kaggle知識點(diǎn):使用大模型進(jìn)行特征篩選
本文轉(zhuǎn)自:Coggle數(shù)據(jù)科學(xué)
數(shù)據(jù)挖掘的核心是是對海量數(shù)據(jù)進(jìn)行有效的篩選和分析。傳統(tǒng)上數(shù)據(jù)篩選依賴于數(shù)據(jù)驅(qū)動的方法,如包裹式、過濾式和嵌入式篩選。隨著大模型的發(fā)展,本文將探討如何利用大模型進(jìn)行特征篩選。
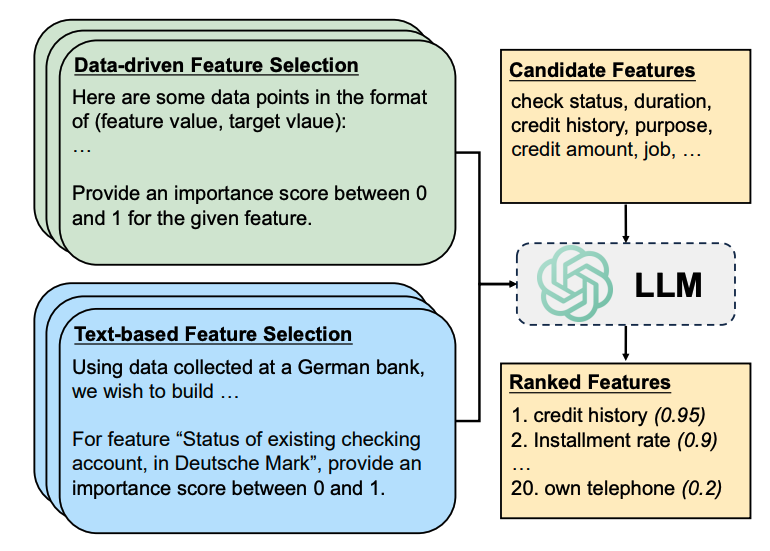
篩選思路
數(shù)據(jù)驅(qū)動方法依賴于數(shù)據(jù)集中的樣本點(diǎn)進(jìn)行統(tǒng)計(jì)推斷,而基于文本的方法需要描述性的上下文以更好地在特征和目標(biāo)變量之間建立語義關(guān)聯(lián)。
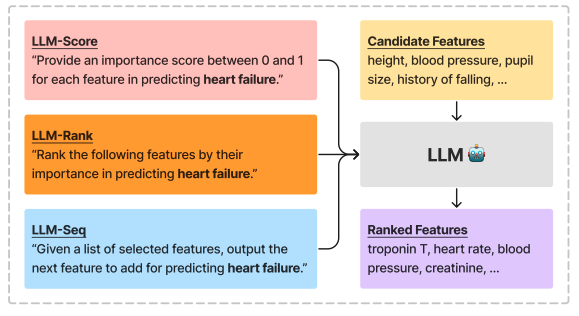
這種方法利用了大型語言模型(LLMs)中豐富的語義知識來執(zhí)行特征選擇。大模型將利用數(shù)據(jù)集描述(desd)和特征描述(desf),描述特征的重要性。
- LLM生成的特征重要性得分(LLM-Score)
- LLM生成的特征排名(LLM-Rank)
- 基于LLM的交叉驗(yàn)證篩選(LLM-Seq)
實(shí)驗(yàn)設(shè)置
- 模型:實(shí)驗(yàn)中使用了不同參數(shù)規(guī)模的LLMs,包括LLaMA-2(7B和13B參數(shù))、ChatGPT(約175B參數(shù))和GPT-4(約1.7T參數(shù))。
- 比較方法:將基于LLM的特征選擇方法與傳統(tǒng)的特征選擇基線方法進(jìn)行比較,包括互信息過濾(MI)、遞歸特征消除(RFE)、最小冗余最大相關(guān)性選擇(MRMR)和隨機(jī)特征選擇。
- 數(shù)據(jù)集:使用了多個數(shù)據(jù)集進(jìn)行分類和回歸任務(wù)的評估,包括Adult、Bank、Communities等。
實(shí)現(xiàn)細(xì)節(jié):對于每個數(shù)據(jù)集,固定特征選擇比例為30%,并在16-shot、32-shot、64-shot和128-shot的不同數(shù)據(jù)可用性配置下進(jìn)行評估。使用下游L2懲罰的邏輯/線性回歸模型來衡量測試性能,并使用AUROC和MAE作為評估指標(biāo)。
實(shí)驗(yàn)結(jié)果
將LLM-based特征選擇方法與傳統(tǒng)的特征選擇基線方法進(jìn)行比較,包括LassoNet、LASSO、前向序貫選擇、后向序貫選擇、遞歸特征消除(RFE)、最小冗余最大相關(guān)性選擇(MRMR)、基于互信息(MI)的過濾和隨機(jī)特征選擇。
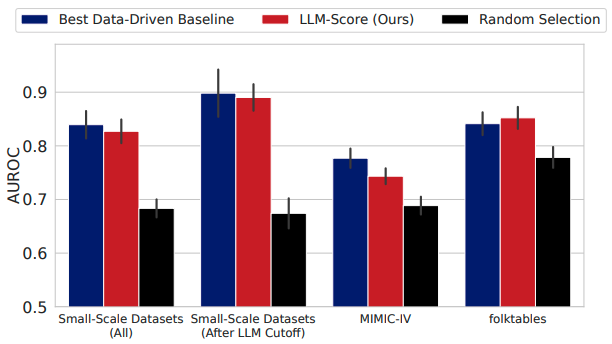
- 發(fā)現(xiàn)1:在小規(guī)模數(shù)據(jù)集上,基于文本的特征選擇方法比數(shù)據(jù)驅(qū)動的方法更有效。在幾乎所有的LLM和任務(wù)中,基于文本的特征選擇方法的性能都超過了數(shù)據(jù)驅(qū)動方法。
- 發(fā)現(xiàn)2:使用最先進(jìn)的LLMs進(jìn)行基于文本的特征選擇,在每種數(shù)據(jù)可用性設(shè)置下都能與傳統(tǒng)特征選擇方法相媲美。
- 發(fā)現(xiàn)3:當(dāng)樣本數(shù)量增加時,使用LLMs的數(shù)據(jù)驅(qū)動特征選擇會遇到困難。特別是當(dāng)樣本大小從64增加到128時,分類任務(wù)的性能顯著下降。
- 發(fā)現(xiàn)4:與數(shù)據(jù)驅(qū)動特征選擇相比,基于文本的特征選擇顯示出更強(qiáng)的模型規(guī)模擴(kuò)展性。
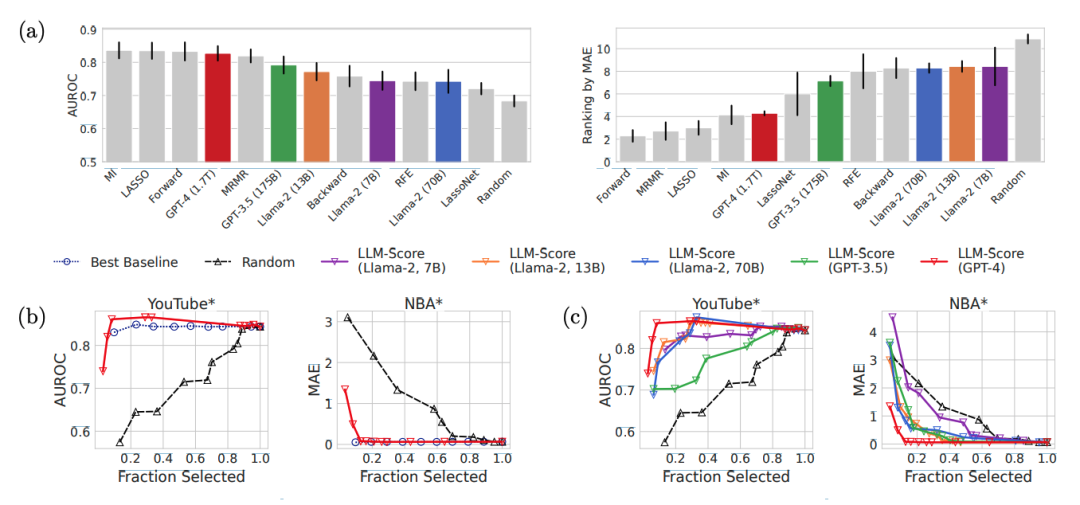
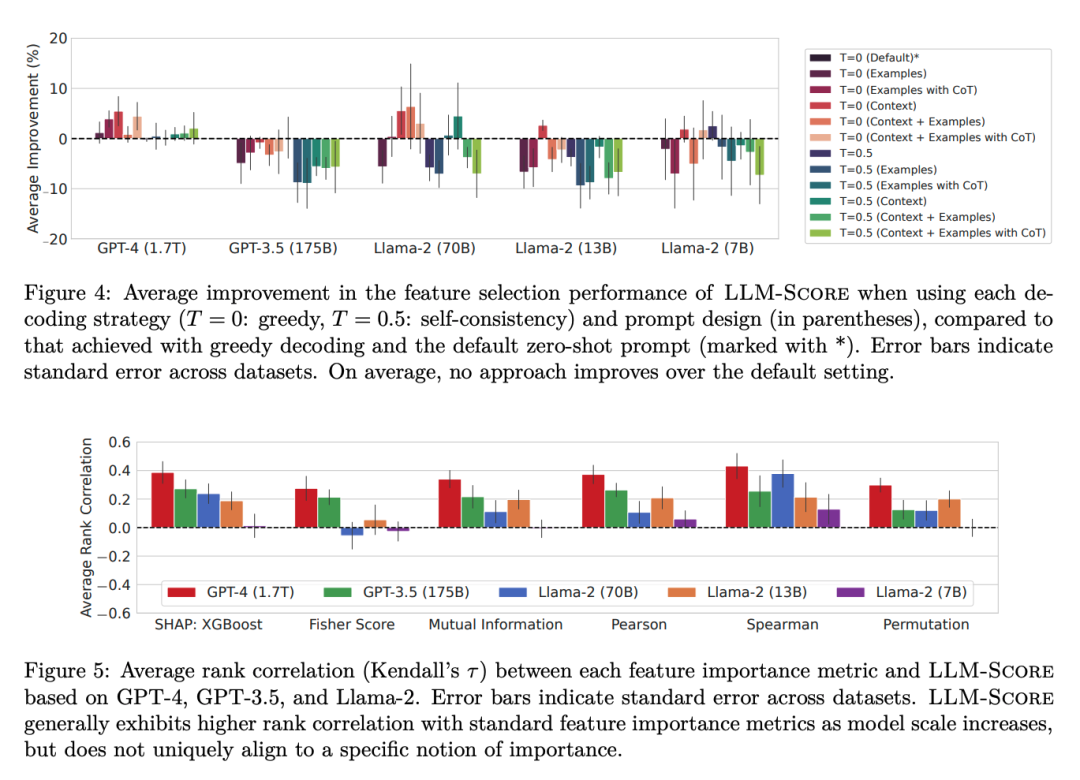
GPT-4基于LLM-Score在folktables數(shù)據(jù)集上整體表現(xiàn)最佳,在MIMIC-IV數(shù)據(jù)集上顯著優(yōu)于LassoNet和隨機(jī)特征選擇基線。LLM-Score在選擇前10%和30%的特征時,與最佳數(shù)據(jù)驅(qū)動基線的性能相媲美,且明顯優(yōu)于隨機(jī)選擇。在醫(yī)療保健等復(fù)雜領(lǐng)域,LLM-Score即使在沒有訪問訓(xùn)練數(shù)據(jù)的情況下,也能有效地進(jìn)行特征選擇。
參考文獻(xiàn)
https://arxiv.org/pdf/2408.12025
- https://arxiv.org/pdf/2407.02694
-
語言模型
+關(guān)注
關(guān)注
0文章
520瀏覽量
10268 -
海量數(shù)據(jù)
+關(guān)注
關(guān)注
0文章
3瀏覽量
888 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640
發(fā)布評論請先 登錄
相關(guān)推薦
使用PADS軟件進(jìn)行PCB設(shè)計(jì),有哪些基礎(chǔ)知識點(diǎn)?
計(jì)算機(jī)組成原理考研知識點(diǎn)歸納
基于知識點(diǎn)的改進(jìn)型遺傳組卷算法的研究

高一數(shù)學(xué)知識點(diǎn)總結(jié)
高二數(shù)學(xué)知識點(diǎn)總結(jié)
嵌入式知識點(diǎn)總結(jié)

數(shù)字電路知識點(diǎn)總結(jié)


STM32 RTOS知識點(diǎn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論