") AI數(shù)據(jù)中心的布線考量
AI數(shù)據(jù)中心的布線考量
簡(jiǎn)介 /
幾十年來(lái),人工智能 (AI) 的威脅一直是科幻小說(shuō)不變的主題。熒幕反派角色,比如 HAL 9000、終結(jié)者、復(fù)制人和《黑客帝國(guó)》中的機(jī)器人,都站在了人類的對(duì)立面,迫使人類必須克服這些技術(shù)帶來(lái)的威脅。最近,DALLE-2 和 ChatGPT 的發(fā)布引起了廣大公眾對(duì) AI可以做什么的極大興趣,也引發(fā)了人們關(guān)于 AI 將如何改變教育和工作性質(zhì)的討論。AI 也是當(dāng)前和未來(lái)數(shù)據(jù)中心增長(zhǎng)的主要驅(qū)動(dòng)力。
AI 包含以下三個(gè)方面: 在訓(xùn)練期間,大量數(shù)據(jù)被輸入算法,算法使用數(shù)據(jù)并從數(shù)據(jù)中“學(xué)習(xí)”。 然后,算法接觸新數(shù)據(jù)集,并將負(fù)責(zé)基于在訓(xùn)練期間學(xué)習(xí)的內(nèi)容生成新知識(shí)或結(jié)論。例如,這是一張貓的照片嗎?此過(guò)程稱作“推理 AI”。 第三個(gè)方面是“生成式 AI”,這可能比較有意思。生成式 AI 是指算法根據(jù)簡(jiǎn)單的提示“創(chuàng)建”原始輸出,包括文本、圖像、視頻、代碼等。
AI 計(jì)算由圖形處理單元 (GPU) 進(jìn)行處理,GPU 是專為并行處理而設(shè)計(jì)的芯片,非常適合 AI。用于訓(xùn)練和運(yùn)行 AI 的模型會(huì)占用大量處理能力,這通常是單臺(tái)機(jī)器無(wú)法承受的。
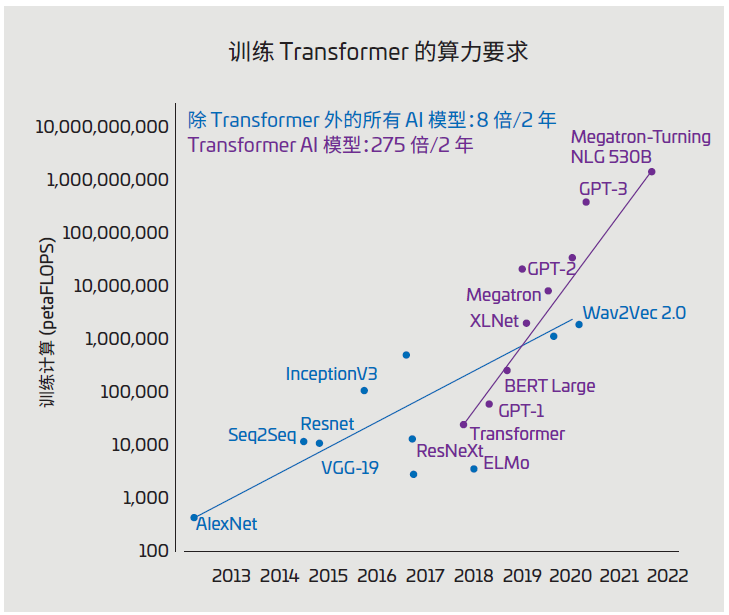
圖 1:AI 模型大小(單位:petaFLOPS)
(資料來(lái)源:https://blogs.nvidia.com/blog/2022/03/25/what-is-a-transformer-model/)
圖 1 顯示了 A I 模型的歷史增長(zhǎng)情況, 單位為petaFLOPS(每秒千萬(wàn)億次浮點(diǎn)運(yùn)算)。處理這些大型模型需使用多個(gè)服務(wù)器和機(jī)架上的眾多互聯(lián)GPU。AI 數(shù)據(jù)中心部署了幾十個(gè)這樣的 AI 集群,而將所有內(nèi)容連接在一起以保持?jǐn)?shù)據(jù)流動(dòng)的布線基礎(chǔ)設(shè)施正面臨著一系列棘手挑戰(zhàn)。
以下內(nèi)容概述了 AI 數(shù)據(jù)中心布線的一些關(guān)鍵挑戰(zhàn)和機(jī)遇,以及一些最佳實(shí)踐和成功技巧。
典型數(shù)據(jù)中心架構(gòu) /
幾乎所有現(xiàn)代數(shù)據(jù)中心,尤其是超大規(guī)模數(shù)據(jù)中心,使用的都是折疊式 Clos 架構(gòu),也稱為“分支和骨干”架構(gòu)。數(shù)據(jù)中心的所有分支交換機(jī)都連接到所有骨干交換機(jī)。在數(shù)據(jù)中心中,服務(wù)器機(jī)架連接到機(jī)架頂部 (ToR) 交換機(jī)。然后,ToR 連接到行末端的分支交換機(jī)或通過(guò)光纜連接到另一個(gè)房間。機(jī)架中的服務(wù)器通過(guò)一至兩米的短銅纜連接到 ToR,傳輸 25G 或 50G信號(hào)。
這種配置可讓數(shù)據(jù)中心使用很少的光纜。例如,使用 F16 架構(gòu)的 Meta 數(shù)據(jù)中心(參見圖 2),一行中每臺(tái)服務(wù)器機(jī)架有 16根雙工光纜。這些線纜從 ToR 延伸到行的末端,在那里它們與模塊連接,將雙工光纖組合成 24 根光纜。接著,這 24 根光纜延伸到另一個(gè)房間,與分支交換機(jī)連接。
數(shù)據(jù)中心在實(shí)施 AI 時(shí),會(huì)將 AI 集群部署在采用傳統(tǒng)架構(gòu)的計(jì)算集群旁。傳統(tǒng)計(jì)算有時(shí)稱為“前端網(wǎng)絡(luò)”,AI 集群有時(shí)稱為“后端網(wǎng)絡(luò)”。
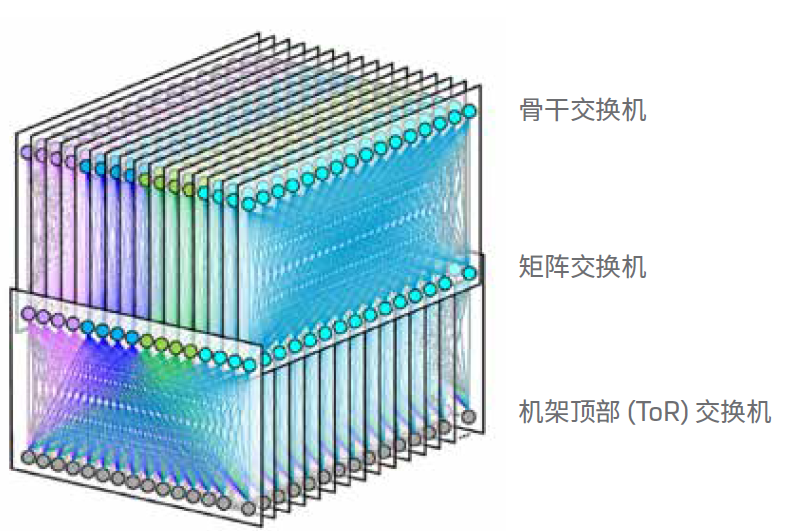
圖 2:FaceBook F16 數(shù)據(jù)中心網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)
(資料來(lái)源:https://engineering..com/2019/03/14/data-center-engineering/f16-minipack/)
帶有 AI 集群的數(shù)據(jù)中心 /
如上所述,AI 集群具有特有的數(shù)據(jù)處理要求,因此需要新的數(shù)據(jù)中心架構(gòu)。GPU 服務(wù)器需要更多的服務(wù)器間連接,但是由于電力和散熱的限制,每個(gè)機(jī)架不得不減少服務(wù)器的數(shù)量。因此,與傳統(tǒng)數(shù)據(jù)中心相比,AI 數(shù)據(jù)中心中的機(jī)架間布線更多。每臺(tái) GPU 服務(wù)器都連接到行內(nèi)或房間內(nèi)的交換機(jī)。這些鏈路需要在長(zhǎng)距離內(nèi)達(dá)到 100G 到 400G 的速率,而這是銅纜所無(wú)法支持的。此外,每臺(tái)服務(wù)器都需要連接到交換機(jī)網(wǎng)絡(luò)、存儲(chǔ)和帶外管理。
例如:NVIDIA
舉個(gè)例子,可以看看 AI 領(lǐng)域知名企業(yè) NVIDIA 提出的架構(gòu)。NVIDIA 發(fā)布了新款 GPU 服務(wù)器 DGX H100,該服務(wù)器具有 4 個(gè) 800G 交換機(jī)端口(作為 8 個(gè) 400GE 運(yùn)行)、4 個(gè) 400GE 存儲(chǔ)端口以及 1GE 和 10GE 管理端口。一個(gè) DGXSuperPOD(圖 3)可以包含 32 個(gè)這樣的 GPU 服務(wù)器,這些GPU 服務(wù)器可連接到單行中的 18 臺(tái)交換機(jī)。然后,每行將擁有 384 個(gè) 400GE 光纖鏈路用于交換機(jī)網(wǎng)絡(luò)和存儲(chǔ),還有 64個(gè)銅纜鏈路用于管理。數(shù)據(jù)中心中光纖鏈路的數(shù)量將顯著增加。前面提到的 F16 架構(gòu)將在服務(wù)器機(jī)架數(shù)量保持不變的情況下?lián)碛?128 (8x16) 根雙工光纜。
AI 集群的鏈路有多長(zhǎng)?/
在 NVIDIA 描繪的理想場(chǎng)景中,AI 集群中的所有 GPU 服務(wù)器將緊密結(jié)合在一起。與高性能計(jì)算 (HPC) 一樣,AI/機(jī)器學(xué)習(xí)算法對(duì)延遲極為敏感。有人估計(jì),運(yùn)行大型訓(xùn)練模型有 30%的時(shí)間花在網(wǎng)絡(luò)延遲上,70% 的時(shí)間花在計(jì)算上。由于訓(xùn)練一個(gè)大模型的成本可能高達(dá) 1000 萬(wàn)美元,因此這種網(wǎng)絡(luò)延遲時(shí)間代表著一筆巨大的費(fèi)用。即使是節(jié)省 50 納秒或 10 米光纖的延遲,效果也非常明顯。AI 集群中幾乎所有的鏈路都限制在 100 米范圍內(nèi)。
不幸的是,并非所有數(shù)據(jù)中心都能夠在同一行部署 GPU 服務(wù)器機(jī)架。這些機(jī)架需要大約 40 kW 才能為 GPU 服務(wù)器供電。這一功率比典型服務(wù)器機(jī)架的更高,按較低功率要求構(gòu)建的數(shù)據(jù)中心將需要騰出專門的 GPU 機(jī)架空間。
如何選擇收發(fā)器?/
運(yùn)營(yíng)商應(yīng)仔細(xì)考慮其 AI 集群使用哪些光收發(fā)器和光纜才能更大限度地降低成本和功耗。如上所述,AI 集群中的最長(zhǎng)鏈路將限制為 100 米。由于距離短,光學(xué)設(shè)備成本將主要集中在收發(fā)器上。使用并行光纖的收發(fā)器將具有一個(gè)優(yōu)勢(shì):它們不需要使用光復(fù)用器和分解復(fù)用器進(jìn)行波分復(fù)用 (WDM)。這降低了并行光纖收發(fā)器的成本和功耗。收發(fā)器節(jié)省下的費(fèi)用遠(yuǎn)遠(yuǎn)抵消了多芯光纖取代雙工光纜所略微增加的成本。例如,使用帶有八芯光纖的 400G-DR4 收發(fā)器比采用雙工光纜的 400G-FR4 收發(fā)器更具成本效益。
單模和多模光纖應(yīng)用可以支持長(zhǎng)達(dá) 100 米的鏈路。硅光子技術(shù)的發(fā)展降低了單模收發(fā)器的成本,使其更接近等效多模收發(fā)器的成本。我們的市場(chǎng)研究表明,對(duì)于高速收發(fā)器 (400G+),單模收發(fā)器的成本是等效多模收發(fā)器成本的兩倍。雖然多模光纖的成本略高于單模光纖,但由于多芯光纖成本主要由 MPO 連接器決定,因此多模和單模光纖之間的成本差異較小。
此外,高速多模收發(fā)器的功耗比單模收發(fā)器少一兩瓦。單個(gè) AI集群具有 768 個(gè)收發(fā)器(128 個(gè)內(nèi)存鏈路 + 256 個(gè)交換機(jī)鏈路x2),使用多模光纖將節(jié)省高達(dá) 1.5 kW 的功率。與每個(gè) DGXH100 消耗的 10 kW 相比,這似乎微不足道,但對(duì)于 AI 集群來(lái)說(shuō),任何降低功耗的機(jī)會(huì)都非常寶貴。
在 2022 年,IEEE 短距離光纖工作小組完成了 IEEE 802.3db的工作,該規(guī)范為新的超短距離 (VR) 多模收發(fā)器確立了標(biāo)準(zhǔn)。此新標(biāo)準(zhǔn)針對(duì)的是 AI 集群等行內(nèi)布線,最大覆蓋范圍為50 米。這些收發(fā)器有可能更大程度地降低 AI 連接的成本和功耗。
收發(fā)器與 AOC /
許多 AI、ML 和 HPC 集群使用有源光纜 (AOC) 來(lái)互聯(lián) GPU 和交換機(jī)。AOC 是兩端集成了光發(fā)射器和接收器的光纜。大多數(shù) AOC 用于短距離,通常與多模光纖和 VCSEL 搭配使用。高速 (>40G) 有源光纜將使用與連接光收發(fā)器的光纜相同的 OM3 或 OM4 光纖。AOC 中的收發(fā)器未必和設(shè)備兼容,如果不兼容將無(wú)法工作。AOC 的收發(fā)器直接接入設(shè)備即可,但是由于安裝人員測(cè)試 AOC 中的收發(fā)器,因此不需要具備清潔和檢查光纖連接器所需的技能。
AOC 的缺點(diǎn)是它們不具備收發(fā)器所擁有的靈活性。AOC 安裝非常耗時(shí),因?yàn)椴季€時(shí)必須連接收發(fā)器。正確安裝帶有扇出功能的 AOC 尤其具有挑戰(zhàn)性。AOC 的故障率是同等收發(fā)器的兩倍。當(dāng) AOC 發(fā)生故障時(shí),必須通過(guò)網(wǎng)絡(luò)來(lái)安裝新的 AOC。這會(huì)占用計(jì)算時(shí)間。最后,當(dāng)需要升級(jí)網(wǎng)絡(luò)鏈路時(shí),必須拆除有問(wèn)題的 AOC 并更換為新的 AOC。相對(duì)于 AOC 連接而言,光纖布線是基礎(chǔ)設(shè)施的一部分,并且可以在幾代數(shù)據(jù)速率迭代升級(jí)中保持生命力。
結(jié)論 /
仔細(xì)考慮 AI 集群的布線將有助于節(jié)省成本、功耗和安裝時(shí)間。合理的光纖布線將使企業(yè)能夠充分受益于人工智能。
-
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
4761瀏覽量
72033 -
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268886 -
布線
+關(guān)注
關(guān)注
9文章
771瀏覽量
84322
原文標(biāo)題:數(shù)據(jù)中心白皮書系列丨AI 數(shù)據(jù)中心的布線考量
文章出處:【微信號(hào):康普中國(guó),微信公眾號(hào):康普中國(guó)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Meta AI數(shù)據(jù)中心網(wǎng)絡(luò)用了哪家的芯片

怎樣保障數(shù)據(jù)中心不間斷電源不斷電 提供可靠安全的供配電#數(shù)據(jù)中心
AI時(shí)代,我們需要怎樣的數(shù)據(jù)中心?AI重新定義數(shù)據(jù)中心

數(shù)據(jù)中心液冷需求、技術(shù)及實(shí)際應(yīng)用
數(shù)據(jù)中心布線標(biāo)準(zhǔn)有什么
HNS 2024:星河AI數(shù)據(jù)中心網(wǎng)絡(luò),賦AI時(shí)代新動(dòng)能

數(shù)據(jù)中心布線光纜設(shè)計(jì)方案





#MPO預(yù)端接 #數(shù)據(jù)中心機(jī)房 #機(jī)房布線








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論