


語義同步定位與建圖(SLAM)系統(tǒng)在對鄰近的語義相似物體進行建圖時面臨困境,特別是在復雜的室內環(huán)境中。本文提出了一種面向對象SLAM的語義增強(SEO-SLAM)的新型SLAM系統(tǒng),借助視覺語言模型(VLM)和多模態(tài)大語言模型(MLLMs)來強化此類環(huán)境中的對象級語義映射。
? 文章:
Learning from Feedback: Semantic Enhancement for Object SLAM Using Foundation Models
? 作者:
Jungseok Hong, Ran Choi, John J. Leonard
? 論文鏈接:
https://arxiv.org/abs/2411.06752
? 編譯:
INDEMIND
? 數(shù)據(jù)集:
jungseokhong.com/SEO-SLAM
01 本文核心內容
SLAM已從專注于幾何精度演變?yōu)槿诤险Z義信息,增強了其在諸如導航、操作和規(guī)劃等下游任務中的效用。這一演進與計算機視覺和深度學習的進步相契合,引入了更豐富且更精確的環(huán)境表征。近期在基礎模型方面的發(fā)展,例如大語言模型(LLM)、視覺語言模型(VLM)、以及多模態(tài)大語言模型(MLLM),已表明它們能夠在開放式詞匯設定下從數(shù)據(jù)中提取語義信息。若干研究顯示,基礎模型能夠對給定的包含語義特征的場景或地圖進行空間推理。除了建圖,還有研究提出了運用基礎模型的語義SLAM。

盡管取得了這些進展,語義SLAM仍存在關鍵挑戰(zhàn):(1)當探測器僅提供通用標簽(例如,所有鞋子均用“鞋”表示)時,難以區(qū)分緊鄰的相似物體。這導致相似物體融合為一個單一地標,如圖1a所示。(2)錯誤地標在長時間維持地圖一致性方面構成重大挑戰(zhàn)。此問題可能由傳感器測量的不確定性或場景變化引起,尤其在雜亂和動態(tài)的環(huán)境中。(3)對象探測器易受其訓練數(shù)據(jù)集中固有偏差的影響,導致某些對象存在持續(xù)的語義錯誤。
為應對這些挑戰(zhàn),我們旨在利用基礎模型的語義理解能力和SLAM的空間精度來構建在語義和空間上均一致的地圖。基礎模型具有強大的語義理解能力,但在沒有預先構建且嵌入語義特征的地圖時,空間推理能力有限。相反,SLAM系統(tǒng)擅長捕獲空間信息,但往往難以維持可靠的語義信息。通過整合這些優(yōu)勢,我們提出了對象SLAM的語義增強(SemanticEnhancementforObjectSLAM,SEO-SLAM)這一新穎方法,該方法利用VLM和MLLM實現(xiàn)語義SLAM。
我們在具有挑戰(zhàn)性的數(shù)據(jù)集上對SEO-SLAM進行評估,其在存在多個相似物體的環(huán)境中的準確性和穩(wěn)健性明顯提升。我們的系統(tǒng)在路標匹配精度和語義一致性方面優(yōu)于現(xiàn)有方法。結果表明,MLLM的反饋改進了以對象為中心的語義映射。
02 主要貢獻
1.將圖像標記、基于標簽的定位以及分割模型整合到SLAM流程中,以實現(xiàn)描述性開放式詞匯對象檢測,并優(yōu)化地標的語義信息。
2.利用MLLMs為現(xiàn)有地標生成更具描述性的標簽,并校正錯誤地標以減少感知混淆。
3.提出一種使用MLLM響應來更新多類別預測混淆矩陣并識別重復地標的方法。
4.實驗結果表明,在具有多個緊鄰相似對象的具有挑戰(zhàn)性的場景中,對象語義映射精度得到了提高。
5.引入在單個場景中具有語義相似對象的數(shù)據(jù)集,其中包含里程計、真實軌跡數(shù)據(jù)和真實對象信息。
03 方法架構
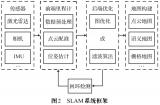
SEO-SLAM旨在通過整合豐富的語義信息來解決MAP問題。為了適應開放式詞匯表的語義,我們僅使用幾何信息來優(yōu)化MAP問題,并利用我們測量中的語義和幾何信息之間的聯(lián)系。這通過融合來自檢測器和深度圖像的語義信息來實現(xiàn)。我們的方法可以處理開放式詞匯表的語義類別,無需為多類預測混淆矩陣的類預測統(tǒng)計信息提供先驗知識。圖2展示了我們SEO-SLAM管道的整體架構。
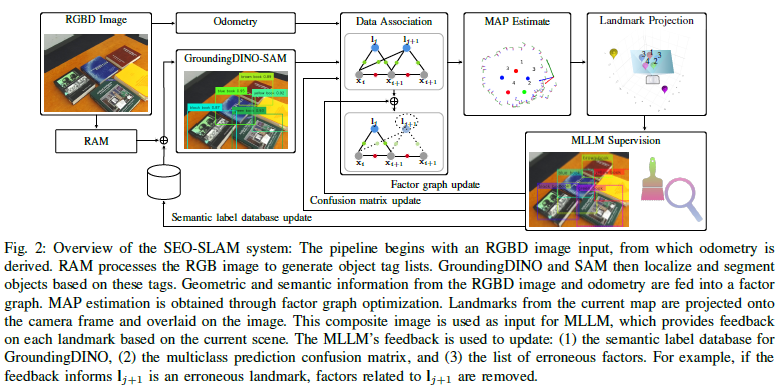
04 實驗
A.數(shù)據(jù)采集
我們在室內房間環(huán)境中采集了六個涵蓋日常物品的數(shù)據(jù)集(見表II)。依據(jù)現(xiàn)存物體的數(shù)量,我們將這些數(shù)據(jù)集歸類為小(約10個)、中(約20個)或大(約30個)類別。我們采用ZED2i立體相機來收集RGB圖像及里程數(shù)據(jù)。通過OptiTrack運動捕捉系統(tǒng)獲取真實軌跡。為構建具有挑戰(zhàn)性的場景,我們將相同類別的物體放置得較為臨近。
B.實驗設置
我們運用RAM++大型模型(加上swin大型模型)進行圖像標注,并濾除那些過于寬泛且不代表單個物體的標簽(例如,“坐”、“白色”、“許多物體”)。對象定位由GroundingDINO大型模型(swinbcogcoor)處理,而分割任務則使用帶有ViT-H模型的SAM完成。在我們的RGS模型中,我們將置信度閾值設為0.5,將GroundingDINO的IoU閾值設為0.5。對于MLLMs,我們利用ChatGPTAPI(gpt-4o版本),在LandmarkEval和ClassLabelGen中均使用默認設置,并異步執(zhí)行以優(yōu)化我們的系統(tǒng)速度。

我們針對這六個數(shù)據(jù)集(見表II)開展了實驗。我們的評估指標涵蓋地標語義的準確性、錯誤地標的數(shù)量以及絕對位姿誤差(APE)。我們對三種方法進行了比較:我們的SEO-SLAM方法,其使用RGS作為對象檢測器,并結合基于MLLM的反饋來細化地標;單獨使用RGS的方法,其運用RAM-Grounded-SAM進行開放詞匯檢測,且無MLLM反饋;以及YOLO方法(基準線),使用預先訓練的YOLOv8進行對象檢測。這種實驗設置使我們能夠全面評估在開放詞匯環(huán)境中不同數(shù)據(jù)集和方法的語義映射性能以及軌跡精度。
C.結果
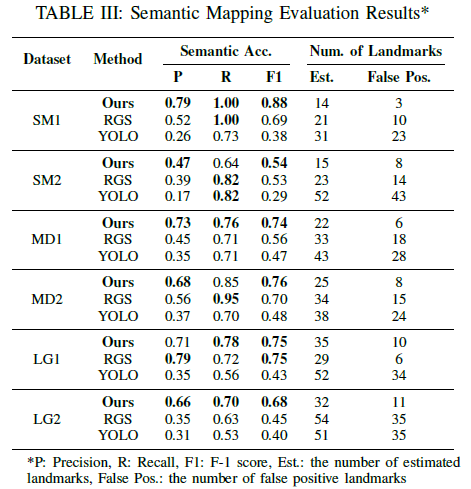
表III全面展示了在六個復雜程度各異的數(shù)據(jù)集上,我們的方法、RGS與YOLO之間語義映射性能的對比情況。結果表明,在語義準確性及地標數(shù)量估計方面,我們的方法始終優(yōu)于其他兩種方法。在多數(shù)數(shù)據(jù)集中,我們的方法達到了最高的精度和F1分數(shù),這表明借助反饋,語義準確性得到了提升。在SM1、MD1和LG2中這一情況尤為顯著,我們的方法保持了穩(wěn)定的性能,而RGS和YOLO的表現(xiàn)則有所下降。值得注意的是,與其他方法相比,我們的方法通常產(chǎn)生的假陽性地標更少,這顯示出其在復雜環(huán)境中的更強魯棒性。我們的方法表現(xiàn)出色,這可歸因于其能夠利用MLLM反饋來細化地標描述并降低感知混疊。然而,在LG1中,我們的方法與RGS的表現(xiàn)相近,原因是每個幀中的物體數(shù)量較多,從而降低了MLLM反饋的質量。總體而言,結果證明了SEO-SLAM在提高語義映射準確性和減少假陽性方面,在各種環(huán)境復雜度下都是有效的。

我們還評估了每種方法相對于里程計的軌跡誤差(圖5)。在所有數(shù)據(jù)集中,我們的方法始終顯示出更低的中位APE。RGS也表現(xiàn)良好,其中位誤差較低,異常值少于YOLO。YOLO顯示出最高的中位誤差和異常值,因為YOLO只能檢測訓練數(shù)據(jù)集中的物體。這表明我們的開放式詞匯檢測器在各種條件下更具穩(wěn)健性和準確性。圖4展示了MD1數(shù)據(jù)集的定性結果。SEO-SLAM成功區(qū)分了鄰近的物體,并展示了其根據(jù)場景變化更新語義地圖的能力。雖然SEO-SLAM能夠捕獲大多數(shù)物體,但當物體過于靠近時,有時也會遇到困難。例如,它在場景中僅繪制了一本書。
D.局限性
雖然SEO-SLAM在語義映射方面取得了顯著的改進,但仍需承認存在一些局限性。我們發(fā)現(xiàn),在SEO-SLAM中,MLLM難以從顏色相近且同屬一類的物體中生成非基于顏色的獨特標簽。此外,其性能對環(huán)境光照條件敏感,這可能會影響基于顏色的物體識別性能。未來,我們計劃通過元提示,使MLLM能夠依據(jù)物體的獨特特征生成標簽,以解決這些問題。
05 總結
我們提出了一種被命名為 SEO-SLAM 的創(chuàng)新方法,旨在擁擠的室內環(huán)境中強化對象級語義映射。此方法借助基礎模型的語義理解能力,通過引入 MLLMs 的反饋來化解現(xiàn)有語義 SLAM 系統(tǒng)中的關鍵難題。借助反饋,SEO-SLAM 能夠生成更具描述性的開放式詞匯對象標簽,同步校正導致虛假地標的諸因素,并動態(tài)更新多類混淆矩陣。實驗結果顯示,SEO-SLAM 在不同復雜程度的數(shù)據(jù)集上始終優(yōu)于基線方法,提升了語義準確性、地標估計精度和軌跡準確性。該方法尤其善于降低假陽性地標數(shù)量,并增強在存在多個相似對象環(huán)境中的穩(wěn)健性。故而,SEO-SLAM 標志著將基礎模型的語義理解能力與 SLAM 系統(tǒng)的空間精度相融合的重大進展。本文為在復雜動態(tài)的環(huán)境中達成更精確且穩(wěn)健的語義映射開辟了嶄新的路徑。(想要了解更多文章細節(jié)的讀者,可以閱讀一下論文原文~)
-
模型
+關注
關注
1文章
3527瀏覽量
50496 -
SLAM
+關注
關注
24文章
444瀏覽量
32528 -
LLM
+關注
關注
1文章
326瀏覽量
863
原文標題:更準確,更魯棒!利用VLM和MLLMs實現(xiàn)SLAM語義增強
文章出處:【微信號:gh_c87a2bc99401,微信公眾號:INDEMIND】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
基于深度學習的增強版ORB-SLAM3詳解
三維高斯?jié)姙R大規(guī)模視覺SLAM系統(tǒng)解析

【「# ROS 2智能機器人開發(fā)實踐」閱讀體驗】視覺實現(xiàn)的基礎算法的應用
一種基于點、線和消失點特征的單目SLAM系統(tǒng)設計

?VLM(視覺語言模型)?詳細解析

一種基于MASt3R的實時稠密SLAM系統(tǒng)

最新圖優(yōu)化框架,全面提升SLAM定位精度

如何設定機器人語義地圖的細粒度級別
激光雷達在SLAM算法中的應用綜述
MG-SLAM:融合結構化線特征優(yōu)化高斯SLAM算法

使用語義線索增強局部特征匹配

從算法角度看 SLAM(第 2 部分)

利用相對濕度傳感器增強功能實現(xiàn)超低功耗系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論