

一、優化內核相關參數
配置文件/etc/sysctl.conf
配置方法直接將參數添加進文件每條一行
sysctl -a 可以查看默認配置 sysctl -p 執行并檢測是否有錯誤
1、網絡相關
net.core.somaxconn=65535 一個端口最大監聽TCP連接隊列的長度 net.core.netdev_max_backlog=65535 數據包速率比內核處理快時,送到隊列的數據包上限 net.ipv4.tcp_max_syn_backlog=65535 TCP syn 隊列的最大長度, 第一次握手的連接參數過大可能也會遭受syn flood攻擊 net.ipv4.tcp_fin_timeout=10 fin超時時間,表示如果套接字由本端要求關閉,這個參數決定了它保持在FIN-WAIT-2狀態的時間 net.ipv4.tcp_tw_reuse=1 是否允許將TIME-WAIT sockets重新用于新的TCP連接,默認為0 關閉 net.ipv4.tcp_tw_recycle=1 是否開啟TCP連接中TIME-WAIT sockets的快速回收,默認為0 關閉
關于網絡參數調優模板,主機配置為8G和16G內存【按需調整】
| 參數 | 默認配置 | 調整配置 | 說明 |
|---|---|---|---|
| fs.file-max | 1048576 | 9999999 | 所有進程打開的文件描述符數 |
| fs.nr_open | 1635590 | 1635590 | 單個進程可分配的最大文件數 |
| net.core.rmem_default | 124928 | 262144 | 默認的TCP讀取緩沖區 |
| net.core.wmem_default | 124928 | 262144 | 默認的TCP發送緩沖區 |
| net.core.rmem_max | 124928 | 8388608 | 默認的TCP最大讀取緩沖區 |
| net.core.wmem_max | 124928 | 8388608 | 默認的TCP最大發送緩沖區 |
| net.ipv4.tcp_wmem | 4096 16384 4194304 | 4096 16384 8388608 | TCP發送緩沖區 |
| net.ipv4.tcp_rmem | 4096 87380 4194304 | 4096 87380 8388608 | TCP讀取緩沖區 |
| net.ipv4.tcp_mem | 384657 512877 769314 | 384657 512877 3057792 | TCP內存大小 |
| net.core.netdev_max_backlog | 1000 | 5000 | 在每個網絡接口接收數據包的速率比內核處理這些包的速率快時,允許送到隊列的數據包的最大數目 |
| net.core.optmem_max | 20480 | 81920 | 每個套接字所允許的最大緩沖區的大小 |
| net.core.somaxconn | 128 | 2048 | 每一個端口最大的監聽隊列的長度,這是個全局的參數 |
| net.ipv4.tcp_fin_timeout | 60 | 30 | 對于本端斷開的socket連接,TCP保持在FIN-WAIT-2狀態的時間(秒)。對方可能會斷開連接或一直不結束連接或不可預料的進程死亡 |
| net.core.netdev_max_backlog | 1000 | 10000 | 在每個網絡接口接收數據包的速率比內核處理這些包的速率快時,允許送到隊列的數據包的最大數目 |
| net.ipv4.tcp_max_syn_backlog | 1024 | 2048 | 對于還未獲得對方確認的連接請求,可保存在隊列中的最大數目。如果服務器經常出現過載,可以嘗試增加這個數字 |
| net.ipv4.tcp_max_tw_buckets | 5000 | 5000 | 系統在同時所處理的最大timewait sockets數目 |
| net.ipv4.tcp_tw_reuse | 0 | 1 | 是否允許將TIME-WAIT sockets重新用于新的TCP連接 |
| net.ipv4.tcp_keepalive_time | 7200 | 900 | 表示TCP鏈接在多少秒之后沒有數據報文傳輸時啟動探測報文(發送空的報文) |
| net.ipv4.tcp_keepalive_intvl | 75 | 30 | 表示前一個探測報文和后一個探測報文之間的時間間隔 |
| net.ipv4.tcp_keepalive_probes | 9 | 3 | 表示探測的次數 |
注意:
參數值并不是設置的越大越好,有的需要考慮服務器的硬件配置,參數對服務器上其它服務的影響等。
2、本地端口號
有時候我們修改了文件句柄限制數后,錯誤日志又會提示 "Can’t assignrequested address"。
這是因為TCP 建立連接,在創建 Socket 句柄時,需要占用一個本地端口號(與 TCP 協議端口號不一樣),相當于一個進程,便于與其它進程進行交互。
而Linux內核的TCP/IP 協議實現模塊對本地端口號的范圍進行了限制。當端口號用盡,就會出現這種錯誤了。
我們可以修改本地端口號的范圍。
#查看IP協議本地端口號限制 cat /proc/sys/net/ipv4/ip_local_port_range #一般系統默認為以下值 32768 61000 #修改本地端口號 vim /etc/sysctl.conf #修改參數 net.ipv4.ip_local_port_range = 1024 65000 #保存修改后,需要執行sysctl命令讓修改生效 sysctl -p
注意:
1、net.ipv4.ip_local_port_range的最小值為1024,1024以下的端口已經規劃為TCP協議占用,如果想將 TCP 協議端口設置為8080等大端口號,可以將這里的最小值調大。
2、如果存在應用服務端口號大于1024的,應該將 net.ipv4.ip_local_port_range 的起始值修改為大于應用服務端口號,否則服務會報錯。
kernel.shmmax=4294967295 該參數定義了共享內存段的最大尺寸(以字節為單位)。 其值應>=sag_max_size初始化參數的大小,否則SAG由多個內存段構成,效率降低, 還要不小于物理內存的一半,默認情況下在32位x86系統中,Oracle SGA最大不能超過1.7GB. kernel.shmmni=4096 這個內核參數用于設置系統范圍內共享內存段的最大數量。該參數的默認值是 4096. kernel.shmall = 2097152 該參數表示系統任意時刻可以分配的所有共享內存段的總和的最大值(以頁為單位). 其值應不小于shmmax/page_size.缺省值就是2097152,如果服務器上運行的所有實例的 SGA總和不超過8GB(通常系統可分配的共享內存的和最大值為8GB),通常不需要修改. vm.swappiness=0 內存分配策略,設置為0是告訴系統除非虛擬內存完全滿了 否則不要使用交換區 風險: 降低操作系統性能 在系統資源不足下,容易被OOM kill掉
二、提高資源限制上限
配置文件位于 /etc/security/limit.conf
* soft nofile 65535 * hard nofile 65535
" * "對所有用戶有效
soft 當前系統生效的設置
hard 系統所能設定的最大值
nofile 打開文件的最大數目
65535 限制的數量
需要重啟系統生效
案例
一次nginx在早高峰時段大量用戶同時請求驗證出現連接緩慢問題,問題是由于資源限制問題導致
日志信息
2024/04/25 0823 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0824 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0824 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0825 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0825 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0826 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0826 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0827 [crit] 37451#0: accept4() failed (24: Too many open files) 2024/04/25 0827 [crit] 37451#0: accept4() failed (24: Too many open files)
報錯原因
通過ulimit -a命令查詢,發現主機最初設置系統文件最大打開數(open files )過于保守,致使早高峰時段大量用戶同時請求驗證出現連接緩慢問題。
core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 127886 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 127886 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited
進一步查看nginx進程的limit限制,發現nginx主進程軟限制是1024,硬限制是4096。
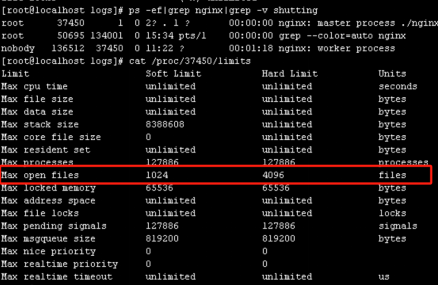
解決方式
修改配置文件/etc/security/limits.conf,增加配置以下配置并重啟Nginx主進程:
root soft nofile 65535 root hard nofile 65535 * soft nofile 65535 * hard nofile 65535
Nginx配置文件增加配置:
worker_rlimit_nofile 65535;
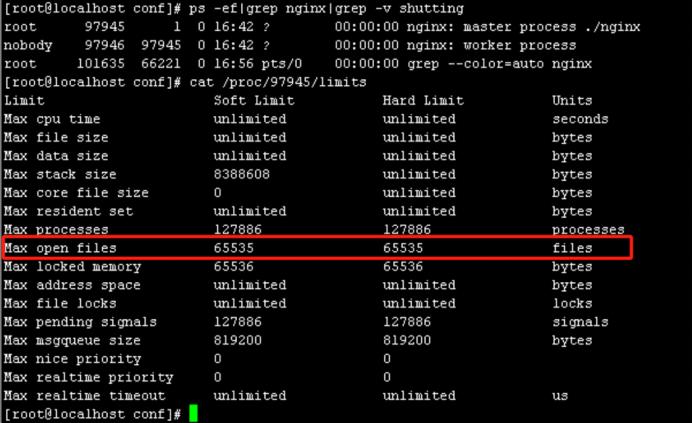
驗證
nginx進程最大文件打開數已設置成功
三、磁盤調度策略
參數路徑:/sys/block/devname/queue/scheduler
簡介:
noop電梯式調度策略
實現了一個FIFO隊列 傾向餓死讀而利于寫 對閃存設備 RAM和嵌入式系統是最好的選擇
deadline 截止時間調度策略
確保了在一個截止時間內服務請求 這個截止時間是可調整的 而默認讀期限短于寫期限
對于數據庫類應用是最好的選擇
anticipatory 預料IO調度策略
本質上和deadline一樣 但在最后一次讀操作后 要等待6ms 才能繼續進行對其他IO請求進行調度 將一些小寫入流合并成一個大寫入流 用寫入延遲換取最大的寫入吞吐量 適合寫入較多的環境 比如文件服務器 對數據庫環境表現很差
cfq 絕對公平算法
內核參數存儲路徑
| 文件/目錄 | 作用 |
|---|---|
| /proc/sys/abi/* | 用于提供對外部二進制的支持,比如在類UNIX系統,SCO UnixWare 7、SCO OpenServer和SUN Solaris 2上編譯的軟件。默認情況下是安裝的,也可以在安裝過程中移除。 |
| /proc/sys/fs/* | 設置系統允許的打開文件數和配額等。 |
| /proc/sys/kernel/* | 可以啟用熱插拔、操作共享內存、設置最大的PID文件數和syslog中的debug級別。 |
| /proc/sys/net/* | 優化網絡,IPV4和IPV6 |
| /proc/sys/vm/* | 管理緩存和緩沖 |
-
Linux
+關注
關注
87文章
11465瀏覽量
212837 -
主機
+關注
關注
0文章
1033瀏覽量
35821
原文標題:Linux之性能優化
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
HBase性能優化方法總結
Linux系統的性能優化策略
Linux和Android系統故障和優化性能的方法和流程探討
談一談Linux基礎之Makfile文件
基于Linux的Socket網絡編程的性能優化

Linux之chardev_buttom_linux_struc
Linux之chardev_buttom_linux_struc
Linux CPU的性能應該如何優化
影響Linux性能的因素與優化方法
Linux內核slab性能優化的核心思想





 工商網監
工商網監

評論