 深度學習工作負載中GPU與LPU的主要差異
深度學習工作負載中GPU與LPU的主要差異
當前,生成式AI模型的參數規模已躍升至數十億乃至數萬億之巨,遠遠超出了傳統CPU的處理范疇。在此背景下,GPU憑借其出色的并行處理能力,已成為人工智能加速領域的中流砥柱。然而,就在GPU備受關注之時,一個新的競爭力量——LPU(Language Processing Unit,語言處理單元)已悄然登場,LPU專注于解決自然語言處理(NLP)任務中的順序性問題,是構建AI應用不可或缺的一環。
本文旨在探討深度學習工作負載中GPU與LPU的主要差異,并深入分析它們的架構、優勢及性能表現。
GPU 架構
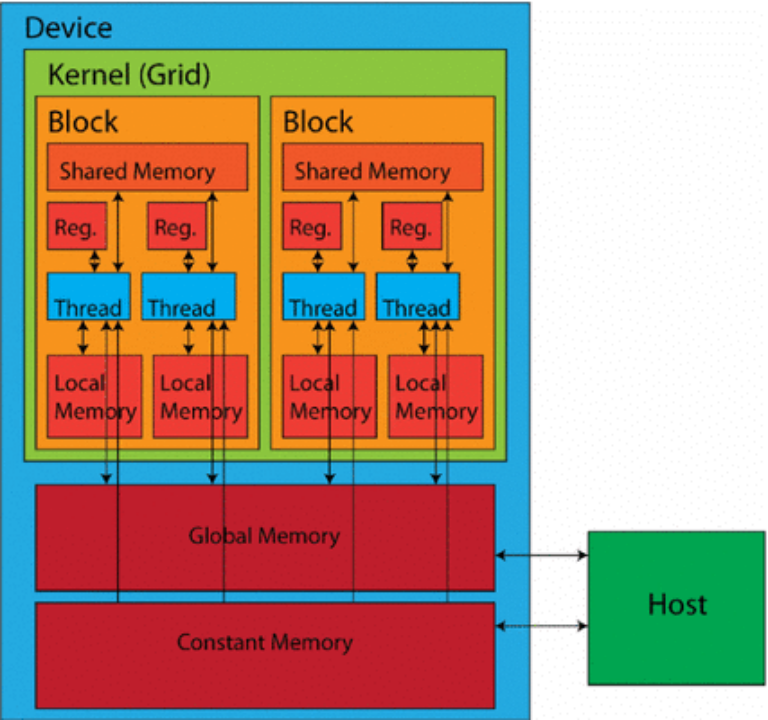
GPU 的核心是計算單元(也稱為執行單元),其中包含多個處理單元(在 NVIDIA GPU中稱為流處理器或 CUDA 核心),以及共享內存和控制邏輯。在某些架構中,尤其是為圖形渲染而設計的架構中,還可能存在其他組件,例如光柵引擎和紋理處理集群 (TPC)。
每個計算單元由多個小型處理單元組成,能夠同時管理和執行多個線程。它配備有自己的寄存器、共享內存和調度單元。計算單元通過并行操作多個處理單元,協調它們的工作以高效處理復雜任務。每個處理單元負責執行基本算術和邏輯運算的單獨指令。
處理單元和指令集架構 (ISA)
計算單元中的每個處理單元被設計用于執行由GPU的指令集架構(ISA)定義的一組特定指令。ISA確定處理單元可以執行的操作類型(算術、邏輯等)以及這些指令的格式和編碼。不同的 GPU 架構可能具有不同的 ISA,這會影響其在特定工作負載下的性能和功能。某些 GPU 為特定任務(例如圖形渲染或機器學習)提供專用 ISA,以優化這些用例的性能。
雖然處理單元可以處理通用計算,但許多 GPU 還包含專門的單元來進一步加速特定的工作負載(例如,Double-Precision Units處理高精度浮點計算)。此外,專為加速矩陣乘法設計的Tensor Core(NVIDIA)或Matrix Core(AMD)現在是計算單元的組成部分。
GPU 使用多層內存層次結構來平衡速度和容量。最靠近處理核心的是小型片上寄存器,用于臨時存儲經常訪問的數據和指令。這種寄存器文件提供最快的訪問時間,但容量有限。
共享內存是一種快速、低延遲的內存空間,可在計算單元集群內的處理單元之間共享。共享內存促進了計算過程中的數據交換,從而提高受益于線程塊內數據重用的任務的性能。
全局內存作為主內存池適用于片上存儲器無法容納的較大數據集和程序指令。全局內存比寄存器或共享存儲器提供更大的容量,但訪問時間較慢。
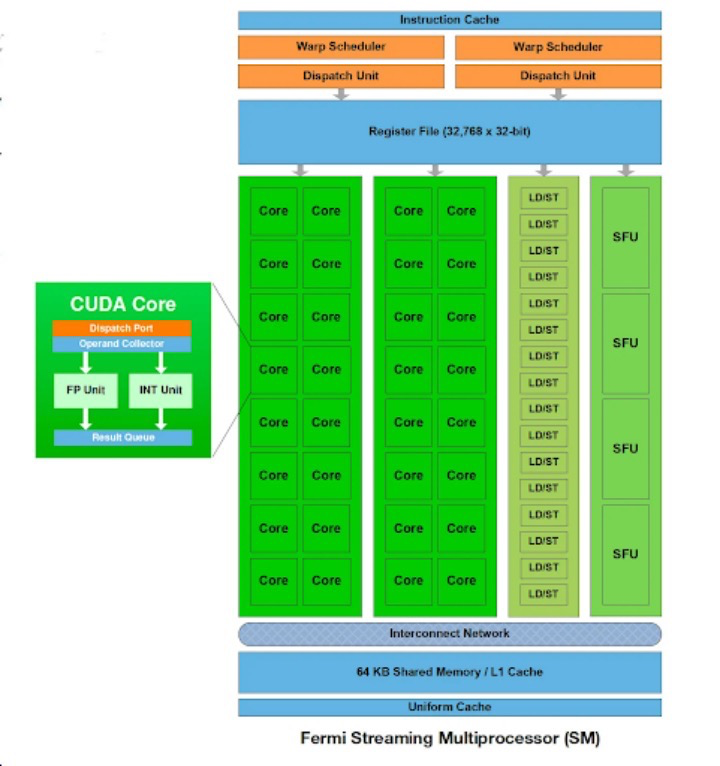
GPU 內的通信網絡
GPU性能的關鍵在于處理單元、內存及其他組件間的高效通信。為此,GPU采用了多種互連技術和拓撲結構。以下是它們的分類及工作原理:
高帶寬互連
基于總線的互連:這是GPU中常見的連接方式,它提供了組件間數據傳輸的共享路徑。盡管實現簡單,但在高流量情況下,由于多個組件要爭奪總線訪問權,可能會形成瓶頸。
片上網絡 (NoC) 互連:高性能GPU則傾向于采用NoC互連,這種方案更具可擴展性和靈活性。NoC 由多個互連的路由器組成,負責在不同組件之間路由數據包,相較于傳統的總線系統,它能提供更高的帶寬和更低的延遲。
點對點 (P2P) 互連:P2P 互連支持特定組件(例如處理單元和內存庫)之間的直接通信,無需共享公共總線,因此可以顯著減少關鍵數據交換的延遲。
互連拓撲
交叉開關(Crossbar Switch):該拓撲允許任意計算單元與任意內存模塊通信,提供了靈活性,但當多個計算單元需要同時訪問同一個內存模塊時,可能會形成瓶頸。
Mesh網絡:該拓撲中每個計算單元都以網格狀結構與其相鄰單元相連,減少了資源爭用,并實現了更高效的數據傳輸,尤其適用于本地化通信模式。
環形總線:計算單元和內存模塊以循環方式連接。這樣數據就可以單向流動,與總線相比,可以減少爭用。雖然廣播效率不如其他拓撲,但它仍然可以使某些通信模式受益。
此外,GPU還需與主機系統(CPU和主內存)通信,這通常通過PCI Express(PCIe)總線完成,它是一種高速接口,支持GPU與系統其他部分之間的數據傳輸。
通過結合不同的互連技術和拓撲,GPU 可以優化各個組件之間的數據流和通信,從而實現跨各種工作負載的高性能。為了最大限度地利用其處理資源,GPU 使用了兩種關鍵技術:多線程和流水線。
多線程:GPU 通常采用同步多線程(SMT),允許單個計算單元同時執行來自相同或不同程序的多個線程,從而能夠更好地利用資源,即使任務具有一些固有的串行部分。GPU支持兩種形式的并行性:線程級并行(TLP)和數據級并行(DLP)。TLP涉及同時執行多個線程,常采用單指令多線程(SIMT)模型;而DLP則利用矢量指令在單個線程內處理多個數據元素。
流水線:通過將復雜任務分解為更小的階段來進一步提高效率,然后在計算單元內的不同處理單元上同時進行處理,從而減少總體延遲。GPU通常采用深度流水線架構,指令被分解為眾多小階段,流水線不僅在處理單元內部實現,還應用于內存訪問和互連中。
綜上所述,眾多流處理器、針對特定工作負載設計的專用單元、多層內存結構以及高效的互連組合,共同賦予了GPU同時處理大量數據的能力。
LPU的架構
LPU 是市場上的新產品,盡管目前知名度不高,但其性能卻極為出色,專為滿足自然語言處理(NLP)工作負載的獨特計算需求而設計。這里重點討論 Groq 的 LPU。
Groq LPU采用了Tensor Streaming Processor(TSP)架構,這一設計特別針對順序處理進行了優化,與 NLP 工作負載的性質完美契合。與GPU在處理NLP任務時可能因內存訪問模式不規則而遇到的挑戰不同,TSP擅長處理數據的順序流,從而能夠更快、更有效地執行語言模型。
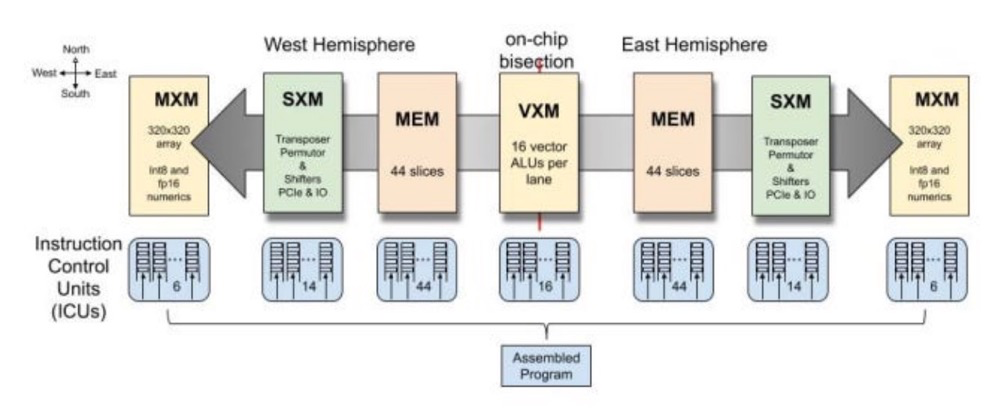
LPU 架構還解決了大規模 NLP 模型中經常遇到的兩個關鍵瓶頸:計算密度和內存帶寬。通過精心管理計算資源并優化內存訪問模式,LPU 可確保有效平衡處理能力和數據可用性,從而顯著提高 NLP 任務的性能。
LPU 尤其擅長推理任務,包括使用預訓練的語言模型來分析和生成文本。其高效的數據處理機制和低延遲設計使其成為聊天機器人、虛擬助手和語言翻譯服務等實時應用的理想選擇。LPU 還集成了專用硬件來加速注意力機制等關鍵操作,這對于理解文本數據中的上下文和關系至關重要。
軟件堆棧
為了彌補LPU專用硬件與NLP軟件之間的差距,Groq提供了全面的軟件堆棧。專用的編譯器能夠優化并翻譯NLP模型和代碼,使它們在LPU架構上高效運行。該編譯器兼容流行的NLP框架,如TensorFlow和PyTorch,讓開發人員能夠無需大幅改動,即可利用他們現有的工作流程和專業知識。
LPU的運行時環境負責執行期間的內存分配、線程調度和資源利用率管理。它還為開發人員提供了API,方便他們與LPU硬件進行交互,從而輕松實現定制和集成到各種NLP應用程序中。
內存架構
Groq LPU 采用多層內存架構,確保數據在計算的各個階段都隨時可用。最靠近處理單元的是標量和矢量寄存器,它們為頻繁訪問的數據(如中間結果和模型參數)提供快速的片上存儲。LPU 使用更大、更慢的二級 (L2) 緩存來存儲不常訪問的數據,減少了從較慢的主內存中獲取數據的需要。
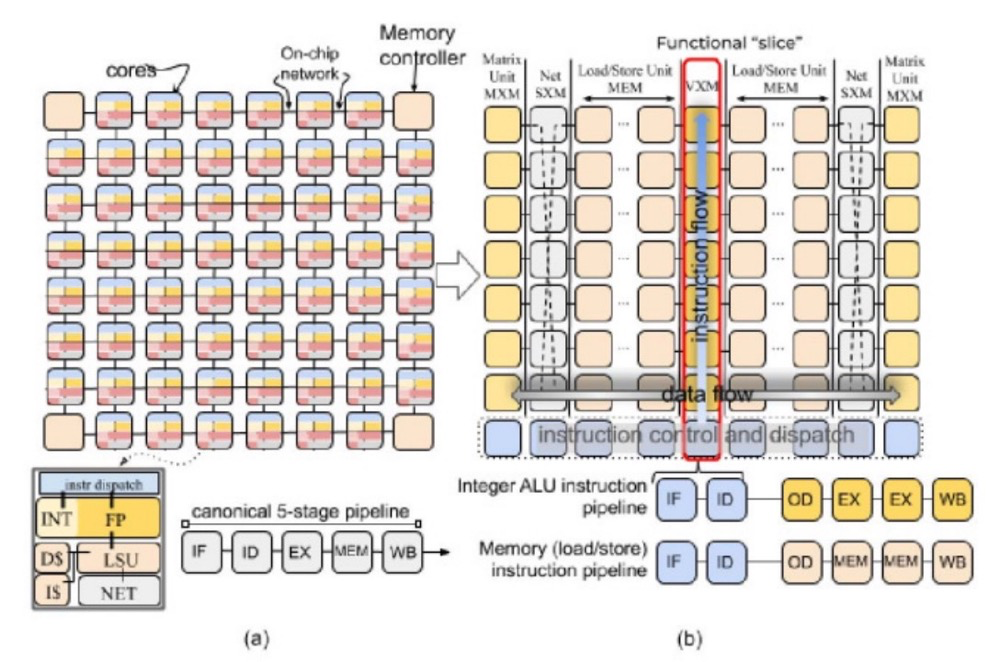
大容量數據的主要存儲是主存儲器,用于存儲預訓練模型以及輸入和輸出數據。在主存儲器中分配了專用的模型存儲以確保高效訪問預訓練模型的參數。
此外,LPU 還集成了高帶寬片上 SRAM,進一步減少了對外部存儲器的依賴,從而最大限度地減少延遲并提高了吞吐量。這對于處理大量數據的任務,如語言建模,尤為關鍵。
互連技術
Groq LPU 使用互連技術以促進處理單元和內存之間的高效通信。基于總線的互連可處理一般通信任務,而片上網絡 (NoC) 互連可為要求更高的數據交換提供高帶寬、低延遲通信。點對點 (P2P) 互連可實現特定單元之間的直接通信,從而進一步降低關鍵數據傳輸的延遲。
性能優化
為了最大限度地利用處理資源,LPU 采用了多線程和流水線技術。神經網絡處理集群 (NNPC) 將專門為 NLP 工作負載設計的處理單元、內存和互連分組。每個 NNPC 可以同時執行多個線程,從而顯著提高吞吐量并實現線程和數據級并行。
流水線技術將復雜任務分解為多個小階段,允許不同的處理單元同時處理不同的階段,從而進一步提高效率。這可減少總體延遲并確保數據通過 LPU 的連續流動。
性能比較
LPU 和 GPU 具有不同的用例和應用。
LPU 被設計為NLP算法的推理引擎,因此很難在相同的基準上直接將這兩類芯片進行并排比較。Groq的LPU在加速AI模型推理方面的表現尤為出色,其速度遠超當前市場上的任何GPU,其每秒最多可生成五百個推理令牌,這意味著用它來撰寫一本小說,可能僅需幾分鐘的時間。
相比之下,GPU并非專為推理而設計,它們的應用范圍更為廣泛,涵蓋了整個AI生命周期,包括推理、訓練和部署各種類型的AI模型。此外,GPU還廣泛應用于數據分析、圖像識別和科學模擬等領域。
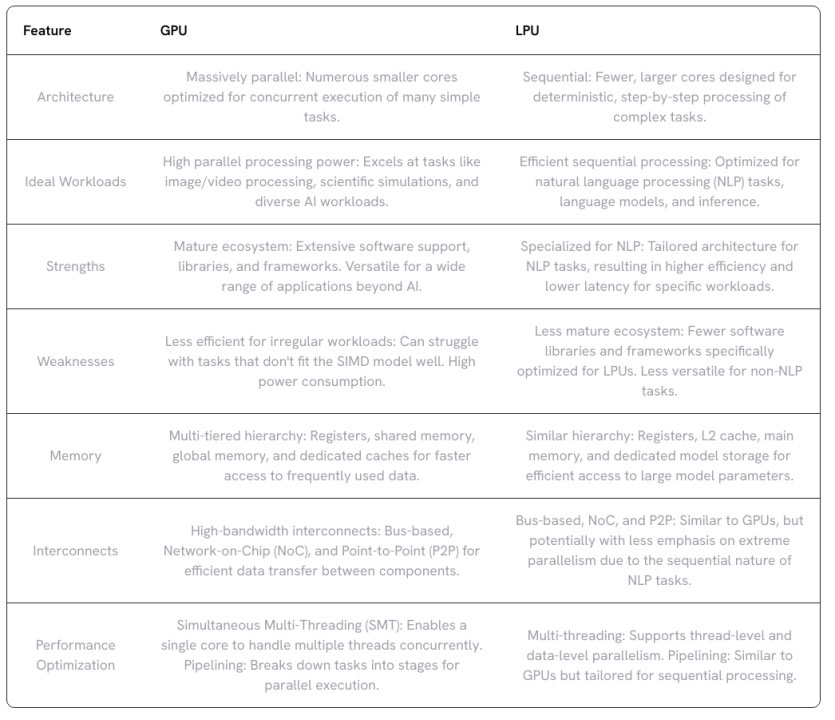
在處理大型數據集時,LPU和GPU都表現出色。LPU能夠容納更多數據,從而進一步加快推理過程。而GPU在通用并行處理方面也表現出色。它能夠加速涉及大型數據集和并行計算的各種任務,因此在數據分析、科學模擬和圖像識別等領域中發揮著不可替代的作用。
總體而言,如果你的工作負載高度并行,且需要在各種任務中實現高計算吞吐量,那么GPU可能是更好的選擇。特別是當你需要處理從開發到部署的整個AI流程時,GPU無疑是最值得投資的硬件選擇。但如果你主要關注NLP應用,特別是那些涉及大型語言模型和推理任務的應用程序,那么LPU的專門架構和優化可以在性能、效率和潛在降低成本方面提供顯著優勢。
-
gpu
+關注
關注
28文章
4729瀏覽量
128890 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:GPU 與 LPU:哪個更適合 AI 工作負載?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
相比GPU和GPP,FPGA是深度學習的未來?
深度學習框架TensorFlow&TensorFlow-GPU詳解
Mali GPU支持tensorflow或者caffe等深度學習模型嗎
什么是深度學習?使用FPGA進行深度學習的好處?
深度學習方案ASIC、FPGA、GPU比較 哪種更有潛力

優化用于深度學習工作負載的張量程序

深度學習的GPU共享工作
深度學習如何挑選GPU?

GPU在深度學習中的應用與優勢







 工商網監
工商網監
評論