


作者:
黃明明英特爾創新大使
李翊瑋英特爾開發者技術推廣經理
1背景
在以往的實踐中,當我們針對 ultralytics 的 YOLO 模型開展訓練工作時,可供選擇的計算設備通常局限于 CPU、mps 以及 cuda 這幾種。然而,自 PyTorch2.5 版本發布之后,情況有了新的變化,PyTorch2.5正式開始支持英特爾顯卡,也就是說,此后我們能夠借助英特爾 銳炫 顯卡來進行模型訓練了。
具體而言,PyTorch2.5 版本能夠在不同的操作系統及對應的英特爾顯卡系列上提供支持。在 Linux 系統下,它支持 英特爾 數據中心 GPU Max 系列;在 Windows 系統下,則支持英特爾銳炫系列。倘若您想要嘗試通過不同的方式來利用英特爾顯卡進行相關操作,可以參考網址來安裝 GPU 驅動。
接下來,本文將會選用基于英特爾酷睿 Ultra 7 185H 的AI PC在 Windows 平臺展開具體的演示與應用,以便讓大家更為直觀地了解相關的操作流程與實際效果。
2安裝驅動
Linux
如果你正在使用 Linux 操作系統,并且希望充分發揮英特爾獨立顯卡的性能優勢,那么安裝正確的 GPU 驅動程序至關重要。在這個過程中,你可以參考網址https://dgpu-docs.intel.com/driver/client/overview.html,該網站提供了詳細且全面的指導,能夠幫助你順利完成 GPU 驅動的安裝。
Windows
在使用英特爾顯卡的過程中,若你購買的是正版系統并且使用的是默認的 Windows 系統,通常情況下,系統會默認安裝英特爾 銳炫控制面板。這一控制面板為用戶提供了便捷的圖形設置和管理功能,使用戶能夠根據自身需求對顯卡進行個性化的調整。
然而,若你發現系統中并未安裝英特爾 銳炫控制面板,也無需擔憂,你可以前往英特爾官方支持網站進行下載。英特爾為用戶提供了豐富的支持資源,其中包括針對顯卡相關問題的詳細解決方案和各類實用工具的下載鏈接。你可以訪問網址,在該頁面中,你能夠找到與英特爾圖形產品支持相關的各類信息,涵蓋了眾多英特爾處理器系列、顯卡產品以及相關技術和解決方案。通過瀏覽該頁面,你可以獲取到更為全面的產品支持信息,有助于你深入了解英特爾圖形產品的特性和功能。
另外,對于如何在 Windows 10 和 Windows 11 系統中安裝英特爾圖形驅動程序,你可以參考網址https://www.intel.com/content/www/us/en/support/articles/000005629/graphics/processor-graphics.html。該頁面詳細介紹了兩種安裝方法,推薦的方法是使用英特爾 驅動程序與支持助手(Intel Driver & Support Assistant)自動檢測并安裝驅動程序。你只需下載該助手,它將為你智能識別系統所需的驅動程序并完成安裝過程,更多信息可查看英特爾 驅動程序與支持助手常見問題解答(FAQ)。
PyTorch安裝
安裝Pytorch就比較簡單了,首先建立一個虛擬的Python環境,然后:
$pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/xpu
注意:--index-url https://download.pytorch.org/whl/nightly/xpu請務必加上,如不加上可能安裝的是非XPU版本。
驗證:
import torch
若提示 “******xpu.dll 找不到”,先檢查安裝是否完整,回顧有無遺漏、報錯或中斷情況,確認依賴組件是否安裝到位。同時排查網絡是否被劫持,可換網絡環境或用檢測工具查看。
若存在問題,要重新下載安裝。在此之前,刪除 pip 的緩存,清理舊文件與錯誤記錄,保障后續下載完整無誤,順利完成安裝,恢復程序正常運行。
$pip uninstall torch $pip uninstall torchaudio $pip uninstall torchvision $pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/xpu
確認XPU是否可以使用:
torch.xpu.is_available() True
3使用XPU進行模型訓練
之前在英特爾主機上展開模型訓練,執行相應代碼就能開啟流程,可因未引入CUDA,僅靠 CPU 運算,訓練耗時長得令人咋舌。就拿筆者實操來說,以往用 CPU 訓練,滿滿六個小時才跑完一輪,效率極低。
好在如今情況大變樣,同樣的訓練任務,用AI PC內置的英特爾銳炫 graphics耗時銳減,現在只需一個半小時即可完成,效率提升顯著。
model = YOLO("yolo11s.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="yolo.yaml", epochs=100, imgsz=640)
依據官方文檔指引,在利用相關工具開展訓練工作時,倘若要啟用除默認設備之外的其他設備,操作流程原本十分便捷,僅需在 train 方法里精準傳入對應的 device 參數,便能輕松達成設備切換,適配多樣化的硬件資源,實現訓練效能的優化提升。
然而,就當前情況而言,ultralytics 官方框架尚未提供對 XPU 的原生支持,這無疑給我們借助 XPU 強大算力來加速訓練進程設置了一道障礙。若執意要在訓練流程中啟用 XPU,那就不得不對源代碼進行深度剖析與針對性修改,這一過程既考驗技術功底,又伴隨著代碼穩定性、兼容性等諸多潛在風險。
但值得慶幸的是,即便受限于Ultralytics官方對 XPU 支持的暫缺現狀,我們仍有變通之法。可以繞開復雜的源代碼改動,轉而在外層通過合理設置訓練設備的方式,巧妙引導訓練任務適配期望的硬件設備,以此確保訓練工作能夠在符合自身硬件條件與算力訴求的環境下高效、平穩開展。
if __name__ == '__main__':
freeze_support()
# Load a model
model = YOLO("yolo11s.pt") # load a pretrained model (recommended for training) and transfer weights
device_str = "xpu:0"
device = torch.device(device_str)
model = model.to(device)
# Train the model
results = model.train(data="switch.yaml", epochs=100, imgsz=640)
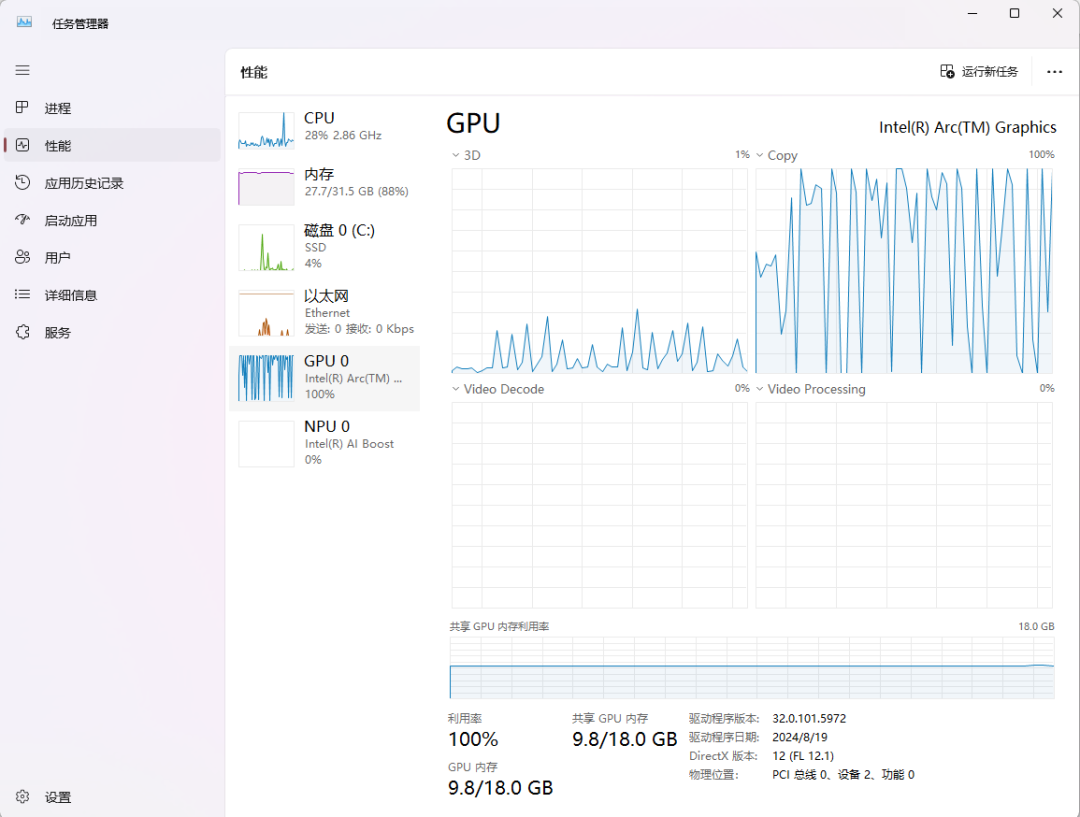
4總結
本文圍繞深度學習模型訓練效率提升與硬件資源優化利用這一核心主題,聚焦于英特爾AI PC系列平臺,深入闡述了從傳統 CPU 訓練模式向 XPU 賦能訓練模式的轉型歷程,尤其以 YOLO 模型訓練作為典型范例展開剖析。
過往依賴 CPU 開展 YOLO模型訓練時,受限于 CPU 單核處理能力與串行運算機制,訓練周期冗長,硬件資源利用率也處于較低水平,極大制約了模型迭代優化的速度。而隨著 英特爾AI PC系列平臺搭載的 XPU 技術登場,局面得以徹底扭轉。文中詳述了如何借助這一先進平臺,將訓練算力基石從 CPU 平穩遷移至 XPU,充分釋放 XPU 兼具的多元處理單元協同優勢與高效并行計算效能。在這一轉變過程中,訓練時間得到了大幅度壓縮,原本漫長的訓練時長銳減,效率實現數倍乃至數十倍的躍升,讓模型訓練從耗時 “長跑” 變為高效 “沖刺”。
更為關鍵的是,這種基于 XPU 的訓練革新絕非僅惠及 YOLO 模型。立足長遠,憑借 XPU 卓越的架構設計與強勁算力支撐,后續眾多依托 torch 框架構建的模型及前沿技術,均可無縫接入并深度運用其強大能力。無論是復雜的圖像識別、語義分割,還是自然語言處理領域的深度神經網絡模型,XPU 都將成為它們加速迭代、突破性能瓶頸的 “強效催化劑”,真正達成對深度學習技術全方位的加速賦能,推動整個領域朝著更高效、更智能的方向闊步邁進。
-
英特爾
+關注
關注
61文章
10194瀏覽量
174650 -
Linux
+關注
關注
87文章
11509瀏覽量
213709 -
WINDOWS
+關注
關注
4文章
3613瀏覽量
91382 -
AI
+關注
關注
88文章
35093瀏覽量
279465 -
模型
+關注
關注
1文章
3517瀏覽量
50400
原文標題:開發者實戰|使用英特爾 AI PC 為 YOLO 模型訓練加速
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
開啟AI PC新紀元!英特爾酷睿Ultra重磅發布,勝任200億參數大語言模型

英特爾面向中國市場發布Gaudi2處理器,加速大模型訓練和推理

英特爾媒體加速器參考軟件Linux版用戶指南
英特爾通過AI參考套件加速AI發展

英特爾攜手PC產業伙伴,邁向規模化應用AI的未來

英特爾啟動首個AI PC加速計劃

英特爾新處理器,掀AI PC戰火
英特爾酷睿Ultra通過全新英特爾vPro平臺將AI PC惠及企業
英特爾發布AI PC加速計劃,確立AI PC新標準
英特爾宣布AI PC加速計劃新增兩項AI舉措
浪潮信息"源2.0"大模型YuanChat支持英特爾最新商用AI PC


英特爾計劃明年AI PC出貨一億臺
使用PyTorch在英特爾獨立顯卡上訓練模型





 工商網監
工商網監

評論