") 新黃金時代:抓住AI加速科學的機遇
新黃金時代:抓住AI加速科學的機遇
作者:Conor Griffin | Don Wallace |Juan Mateos-Garcia lHanna Schieve | Pushmeet Kohli,
翻譯:劉力 算力魔方創(chuàng)始人
編者按:文并不是逐字逐句翻譯,而是以更有利于中文讀者理解的目標,做了刪減、重構和意譯,并替換了多張不適合中文讀者的示意圖。
原文鏈接:https://deepmind.google/public-policy/ai-for-science/
全球?qū)嶒炇艺娜慌d起一場革命,科學家對AI的使用正迅猛增長。超過三分之一的博士后已利用大語言模型輔助整理文獻、撰寫綜述、編寫代碼等等。2024年10 月,AlphaFold 2的創(chuàng)建者 Demis Hassabis 和 John Jumper因使用人工智能預測蛋白質(zhì)結構而獲得諾貝爾化學獎,讓整個科學界迅速感受到用AI加速科學發(fā)現(xiàn)的益處。
科學家們致力于探究、預測并影響自然界與社會的運行規(guī)律,旨在激發(fā)并滿足人們的好奇心,同時解決社會面臨的重大問題。科學家對人工智能(AI)日益增長的運用,可能預示著更為深遠的變革——即科學能力邊界的一次非連續(xù)性飛躍。下面是五個我們認為迫切需使用AI的科學領域,這些機遇跨越不同學科,涵蓋從提出有力新假設到向世界分享研究成果的各個環(huán)節(jié)。
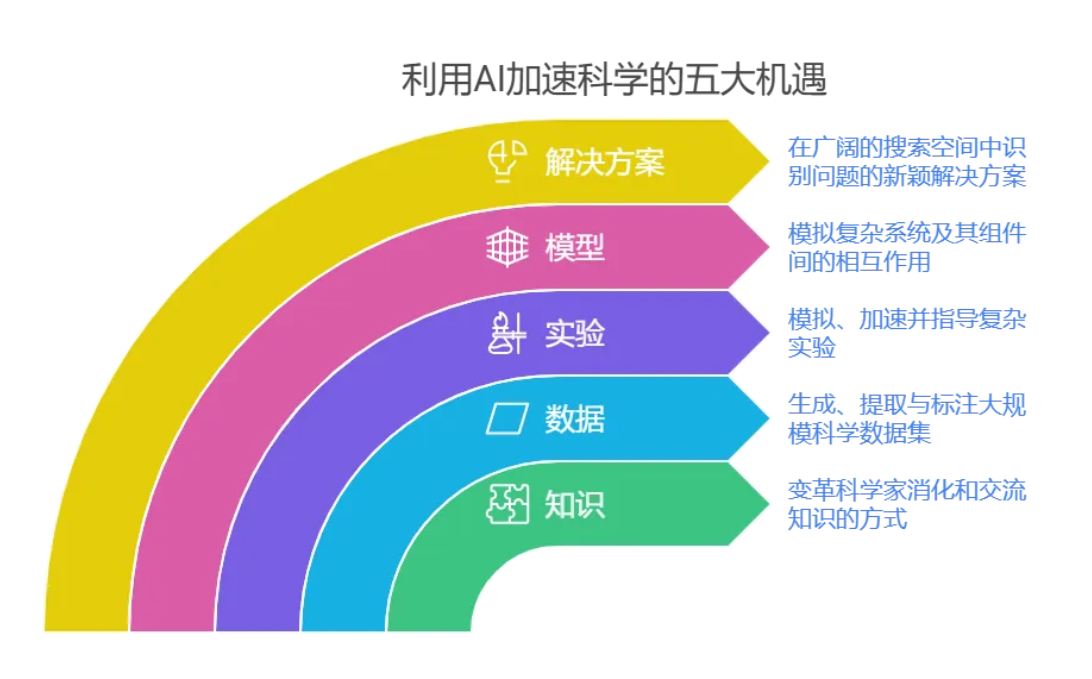
一,知識:改變科學家消化和交流知識的方式
為了做出新的發(fā)現(xiàn),科學家需要掌握一個不斷呈指數(shù)增長且越來越專業(yè)化的現(xiàn)有知識體系。這種“知識負擔”解釋了為什么取得突破性發(fā)現(xiàn)的科學家年齡越來越大、跨學科合作增多,并且更多地集中在頂尖大學中。這也說明了為何單人或小團隊撰寫的論文比例在下降——盡管小團隊往往更擅長推進顛覆性的科學理念。在分享研究成果方面,雖然出現(xiàn)了諸如預印本服務器和代碼庫等有益創(chuàng)新,但大多數(shù)科學家仍然通過內(nèi)容密集、術語繁重且僅限英文的論文來交流他們的發(fā)現(xiàn)。這種方式可能會阻礙而非激發(fā)政策制定者、企業(yè)和公眾對科學研究的興趣。科學家們已經(jīng)開始使用大語言模型(LLM)及其基礎上開發(fā)的早期科學助手來應對這些挑戰(zhàn),例如通過綜合文獻中最相關的見解。在一次早期演示中,我們的科學團隊利用Gemini,在一天內(nèi)從20萬篇相關論文中找到了特定數(shù)據(jù)并進行了提取與填充。未來的技術進步,如針對更多科學數(shù)據(jù)微調(diào)LLM以及長上下文窗口和引用使用的改進,將穩(wěn)步提升這些能力。正如我們在下文中所討論的,這些機遇并非沒有風險。但它們?yōu)閺母旧现匦滤伎寄承┛茖W任務提供了契機,比如在一個科學家可以利用LLM幫助批判、調(diào)整其對于不同受眾的意義或?qū)⒅D(zhuǎn)化為“交互式論文”或音頻指南的世界里,“閱讀”或“撰寫”一篇科學論文意味著什么。
二,數(shù)據(jù):挖掘、提取與標注大規(guī)模科學數(shù)據(jù)集
盡管人們常談論數(shù)據(jù)豐富的時代,但在自然與社會世界的諸多領域,從土壤、深海、大氣到非正規(guī)經(jīng)濟,科學數(shù)據(jù)依然長期匱乏。人工智能(AI)能以多種方式助力解決這一問題。
首先,AI能提升現(xiàn)有數(shù)據(jù)收集的準確性。例如,在DNA測序、樣本中細胞類型的檢測或動物聲音的捕捉過程中,AI能夠減少可能出現(xiàn)的噪聲和錯誤。同時,科學家們還能利用大型語言模型(LLMs)日益增強的跨圖像、視頻和音頻處理能力,從科學出版物、檔案以及教學視頻等不那么顯而易見的資源中,挖掘出隱藏的非結構化科學數(shù)據(jù),并將其轉(zhuǎn)化為結構化數(shù)據(jù)集。此外,AI還能為科學數(shù)據(jù)標注所需的輔助信息,以便科學家更好地利用這些數(shù)據(jù)。舉例來說,至少有三分之一的微生物蛋白質(zhì)缺乏關于其預期功能的可靠標注。2022年,我們的研究人員利用AI預測蛋白質(zhì)功能,為UniProt、Pfam和InterPro等數(shù)據(jù)庫增添了新條目。一旦經(jīng)過驗證,AI模型還能成為合成科學數(shù)據(jù)的新來源。例如,我們的AlphaProteo蛋白質(zhì)設計模型就是基于AlphaFold 2生成的超過1億個AI蛋白質(zhì)結構,以及來自蛋白質(zhì)數(shù)據(jù)庫的實驗結構進行訓練的。這些AI技術的應用能夠與其他急需的科學數(shù)據(jù)生成工作相輔相成,共同提高效益。例如,通過檔案數(shù)字化,或資助新的數(shù)據(jù)捕獲技術與方法(如當前正在進行的單細胞基因組學研究,旨在以前所未有的詳細程度創(chuàng)建單個細胞的強大數(shù)據(jù)集),我們可以進一步豐富科學數(shù)據(jù)的寶庫。
三,實驗:模擬、加速并指導復雜實驗
許多科學實驗耗資巨大、復雜且進展緩慢。有些實驗甚至因研究者無法獲取所需的設施、參與者或投入而根本無法進行。核聚變就是一個典型的例子。它有望成為一種幾乎無限、零排放的能源,并能推動海水淡化等高能耗創(chuàng)新技術的規(guī)模化應用。為實現(xiàn)核聚變,科學家需要創(chuàng)造并控制等離子體——物質(zhì)的第四種基本狀態(tài)。然而,建設所需設施極為復雜。國際熱核聚變實驗堆(ITER)的原型托卡馬克反應堆于2013年開始建設,但最早也要到2030年代中期才能開始進行等離子體實驗,盡管其他團隊希望在更短的時間內(nèi)建造出更小的反應堆。人工智能(AI)有助于模擬核聚變實驗,并顯著提高后續(xù)實驗時間的利用效率。一種方法是在物理系統(tǒng)的模擬上運行強化學習算法。2019年至2021年間,我們的研究人員與瑞士洛桑聯(lián)邦理工學院合作,展示了如何使用強化學習(RL)來控制托卡馬克反應堆模擬中的等離子體形狀。這些方法可以擴展到其他實驗設施,如粒子加速器、望遠鏡陣列或引力波探測器。雖然不同學科使用AI模擬實驗的方式各不相同,但共同之處在于,模擬通常是為了指導和啟發(fā)物理實驗,而非取代它們。例如,每個人的DNA中平均有9000多個錯義變異,即單個字母的替換。這些遺傳變異大多無害,但有些會破壞蛋白質(zhì)的功能,從而導致囊性纖維化等罕見遺傳病以及癌癥等常見病。測試這些變異影響的物理實驗通常僅限于單一蛋白質(zhì)。而我們的AlphaMissense模型能夠?qū)?100萬個潛在的人類錯義變異中的89%進行分類,判斷其可能有害還是無害,從而使科學家能夠?qū)⑽锢韺嶒灥闹攸c放在最有可能導致疾病的變異上。
四,模型:模擬復雜系統(tǒng)及其組件間的相互作用
在1960年的一篇論文中,諾貝爾物理學獎得主尤金·維格納對數(shù)學模型在模擬行星運動等重要自然現(xiàn)象時所展現(xiàn)出的“不可思議的有效性”贊嘆不已。然而,在過去的半個世紀里,那些依賴于方程組或其他確定性假設的模型在捕捉生物學、經(jīng)濟學、天氣等領域系統(tǒng)的全部復雜性時卻顯得力不從心。這反映了構成這些系統(tǒng)的交互部分數(shù)量龐大,以及它們所具備的動態(tài)性和出現(xiàn)新興、隨機或混沌行為的潛力。對這些系統(tǒng)進行建模的挑戰(zhàn)阻礙了科學家預測或控制它們行為的能力,尤其是在面對溫度升高、新藥問世或稅收政策調(diào)整等沖擊或干預時。人工智能(AI)能夠通過吸收更多關于這些系統(tǒng)的數(shù)據(jù),并學習數(shù)據(jù)中更強大的模式和規(guī)律,從而更準確地構建這些復雜系統(tǒng)的模型。例如,現(xiàn)代天氣預報就是科學與工程的杰出成果。對于政府和工業(yè)界而言,它為從可再生能源規(guī)劃到颶風和洪水防范等各項工作提供了重要信息。對于公眾而言,天氣是Google搜索中最受歡迎的非品牌查詢。傳統(tǒng)的數(shù)值預測方法基于精心定義的物理方程,這些方程為大氣復雜動態(tài)提供了非常有用但并非完美的近似。同時,這些方法的計算成本也很高昂。2023年,我們發(fā)布了一個深度學習系統(tǒng),能夠提前10天預測天氣狀況,在準確性和預測速度方面均優(yōu)于傳統(tǒng)模型。如下文所述,利用AI預測天氣變量還有助于緩解和應對氣候變化。例如,當飛機飛過潮濕區(qū)域時,可能會形成凝結尾跡,從而加劇航空業(yè)對全球變暖的影響。Google科學家最近利用AI預測潮濕區(qū)域可能出現(xiàn)的時間和地點,以幫助飛行員避免飛越這些區(qū)域。在許多情況下,AI將豐富而非取代傳統(tǒng)的復雜系統(tǒng)建模方法。例如,基于主體的建模通過模擬個體(如企業(yè)和消費者)之間的交互,來理解這些交互如何影響更大、更復雜的系統(tǒng)(如經(jīng)濟)。傳統(tǒng)方法要求科學家事先指定這些計算主體應如何行為。我們的研究團隊最近概述了科學家如何利用大語言模型(LLMs)創(chuàng)建更靈活的生成式主體,這些主體能夠進行交流并采取行動(如搜索信息或進行購買),同時還能對這些行動進行推理和記憶。科學家還可以利用強化學習來研究這些主體在更動態(tài)的模擬中如何學習和適應其行為,例如在新能源價格出臺或疫情應對政策實施時的反應。
五,解決方案:在廣闊的搜索空間中識別問題的新穎解決方案
眾多重要的科學問題都伴隨著數(shù)量龐大到幾乎無法理解的潛在解決方案。例如,生物學家和化學家的目標在于確定諸如蛋白質(zhì)等分子的結構、特性及功能。這類工作的一個目標就是設計出這些分子的新型版本,以用作抗體藥物、塑料降解酶或新材料。然而,在設計一種小分子藥物時,科學家們面臨著超過10400種選擇。這種龐大的解空間并不僅限于分子領域,而是許多科學問題的常態(tài),比如尋找數(shù)學問題的最佳證明、計算機科學任務的最有效算法,或是計算機芯片的最佳架構。傳統(tǒng)上,科學家們依靠直覺、試錯法、迭代或暴力計算等方法的組合來尋找最佳的分子、證明或算法。但這些方法在探索龐大的潛在解空間時顯得力不從心,導致許多更優(yōu)解未被發(fā)掘。人工智能(AI)能夠開辟這些解空間的新領域,同時更迅速地鎖定那些最有可能可行且有用的解決方案——這是一項需要精妙平衡的任務。例如,在7月,我們的AlphaProof和AlphaGeometry 2系統(tǒng)在國際數(shù)學奧林匹克競賽(一項精英高中生競賽)中正確解決了六道題目中的四道。這些系統(tǒng)利用我們的Gemini大語言模型架構,為給定的數(shù)學問題生成大量新穎的想法和潛在解決方案,并結合基于數(shù)學邏輯的系統(tǒng),迭代地逼近最有可能正確的候選解。
六,人工智能科學家還是人工智能賦能的科學家?
隨著人工智能在科學領域的日益廣泛應用,以及早期人工智能科學助理的出現(xiàn),人們開始質(zhì)疑人工智能的能力究竟能多快、多遠地發(fā)展,以及這對人類科學家意味著什么。當前基于大語言模型(LLM)的人工智能科學助理在相對狹窄的任務范圍內(nèi),如支持文獻綜述方面,僅做出了相對較小的貢獻。有合理的短期預測認為,它們將在這些任務上表現(xiàn)得更加出色,并有能力承擔更具影響力的任務,如幫助生成有力的假設,或幫助預測實驗結果。
然而,當前的系統(tǒng)在人類科學家所依賴的更深層次創(chuàng)造力和推理能力方面仍顯不足。為提升這些人工智能能力,人們正在付出努力,例如通過在我們的AlphaProof和AlphaGeometry 2實例中,將大型語言模型與邏輯推理引擎相結合,但還需取得更多突破。對于那些需要在濕實驗室進行復雜操作、與人類參與者互動或涉及冗長過程(如監(jiān)測疾病進展)的實驗,實現(xiàn)加速或自動化將更為困難。盡管如此,這些領域的研究也在進行中,例如新型實驗室機器人和自動化實驗室的研發(fā)。即使人工智能系統(tǒng)的能力得到提升,最大的邊際效益仍將來自于將其部署在能夠發(fā)揮其相對優(yōu)勢的用例中——如從海量數(shù)據(jù)集中快速提取信息的能力——以及幫助解決科學進步中的真正瓶頸,如上文概述的五個機遇,而非自動化人類科學家已經(jīng)做得很好的任務。隨著人工智能使科學變得更經(jīng)濟、更強大,對科學和科學家的需求也將增長。例如,近期的突破已經(jīng)催生了蛋白質(zhì)設計、材料科學和天氣預報等領域的一系列新興創(chuàng)業(yè)公司。與其他領域不同,盡管過去有人持相反觀點,但未來對科學的需求似乎幾乎沒有上限。新的進步總是在科學知識的地圖上開辟出新的、不可預測的領域,人工智能也將如此。正如赫伯特·西蒙所設想的那樣,人工智能系統(tǒng)也將成為科學研究的對象,科學家將在評估和解釋其科學能力,以及開發(fā)新型人機結合的科學系統(tǒng)中發(fā)揮主導作用。
如果你有更好的文章,歡迎投稿!
稿件接收郵箱:nami.liu@pasuntech.com
更多精彩內(nèi)容請點擊下方名片,關注“算力魔方?”公眾號!
審核編輯 黃宇
-
AI
+關注
關注
87文章
30728瀏覽量
268887 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238258
發(fā)布評論請先 登錄
相關推薦
互聯(lián)網(wǎng)演進跨越半世紀,智能化時代呼喚Net5.5G網(wǎng)絡新代際

《AI for Science:人工智能驅(qū)動科學創(chuàng)新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅(qū)動科學創(chuàng)新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅(qū)動科學創(chuàng)新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅(qū)動科學創(chuàng)新》第一章人工智能驅(qū)動的科學創(chuàng)新學習心得
華為云:構建AI原生思維,共贏智能未來
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅(qū)動科學創(chuàng)新
RISC-V在中國的發(fā)展機遇有哪些場景?
華為李鵬:擁抱5G-A,邁向體驗經(jīng)營新時代

助力科學發(fā)展,NVIDIA AI加速HPC研究

傳感器產(chǎn)業(yè)迎來黃金時代,矽典微賦能感知體驗再升級

在機遇與挑戰(zhàn)并存的AI時代,三星如何在DRAM領域開拓創(chuàng)新?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論