 超越人類視覺!昱感微“多維像素”多模態超級攝像頭方案產品賦能超凡感知力
超越人類視覺!昱感微“多維像素”多模態超級攝像頭方案產品賦能超凡感知力
如今人工智能發展之日新月異,令人不由感嘆也許科幻電影里仿生人的應用不再是遙不可及,那么未來AI會超越人類甚至取代人類嗎?也許現在AI的大腦還無法做到,但眼睛已經做到,機器視覺的感知力已全面超越人類視覺——人眼只能感知所見目標大概的距離/位置/速度以及外觀信息,并且受到天氣、光線等因素影響較大;昱感微“多維像素”多模態感知方案的超級攝像頭每秒可輸出30幀(甚至更高頻率)多模態融合感知數據,每一幀不僅有高清圖像數據,還有對應像素級的目標精準3D空間位置坐標距離、速度、溫度(目標熱輻射)、對應材質(RCS)等數據,并且感知力不受天氣、光線等因素影響。
多模態融合感知的“多維像素”數據
那么昱感微“多維像素”多模態感知超級攝像頭是如何做到的呢?首先,昱感微采用最前沿的多維像素多模態前融合技術,將可見光攝像頭、紅外攝像頭、4D毫米波雷達/激光雷達的探測數據在前端(數據獲取時)融合,并將各傳感器的探測數據“坐標統一、時序對齊”,最后以“多維像素”的數據格式輸出;昱感微的核心技術創新——“多維像素”,它是指在可見光攝像頭像素信息上加上其它傳感器對于同源目標感知的信息:即圖像數據+雷達探測目標的距離、速度、散射截面R的感知數據+紅外傳感器探測的熱輻射圖像數據疊加組合到一起,以攝像頭的像素為顆粒度組合全部感知數據,每個像素不僅有視覺信息,還包含了雷達和紅外傳感器的探測數據,形成多維度(多模態)測量參數矩陣數組。
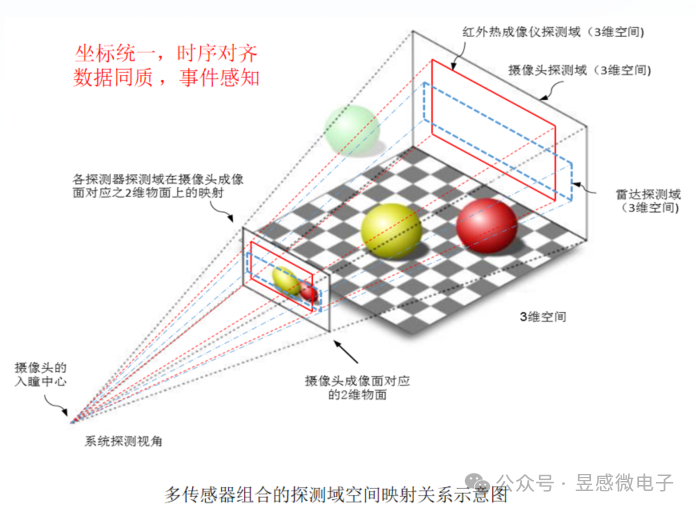
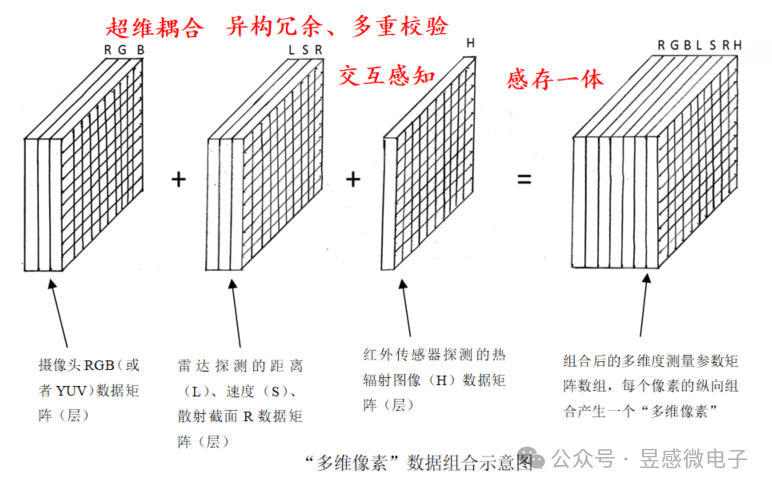
目前的傳感器融合感知技術存在的挑戰,正如埃隆馬斯克所說的:“激光雷達和雷達與視覺結合所帶來的感知不一致性使得這些技術無法達到理想的效果”,昱感微的“多維像素”多模態感知方案能夠幫助大家徹底解決這個技術難題, 而且還能達到1+1>2的效果。在高分辨率寬動態的可見光攝像頭感知基礎上,雷達提供目標的距離、速度維度的精準感知還可以幫助可見光攝像頭克服天氣光線的影響,攝像頭的圖像又為雷達增添了語義信息,進一步提高雷達點云的置信度以及感知信息量;遠紅外攝像頭有針對性的目標熱輻射圖像感知則賦予了自動駕駛系統卓越的夜視能力。昱感微“多維像素”超級攝像頭就像是一雙比人眼更敏銳的眼睛,看到的不僅僅是一幅幅二維的圖像,還有更多維度的精確信息(目標的距離/速度/3D空間位置/溫度/材質等),形成完整的多模態“視覺語言”,令自動駕駛系統可以精確全面地感知道路上各種狀況。
提升性能+降本增效,融合感知的最優解
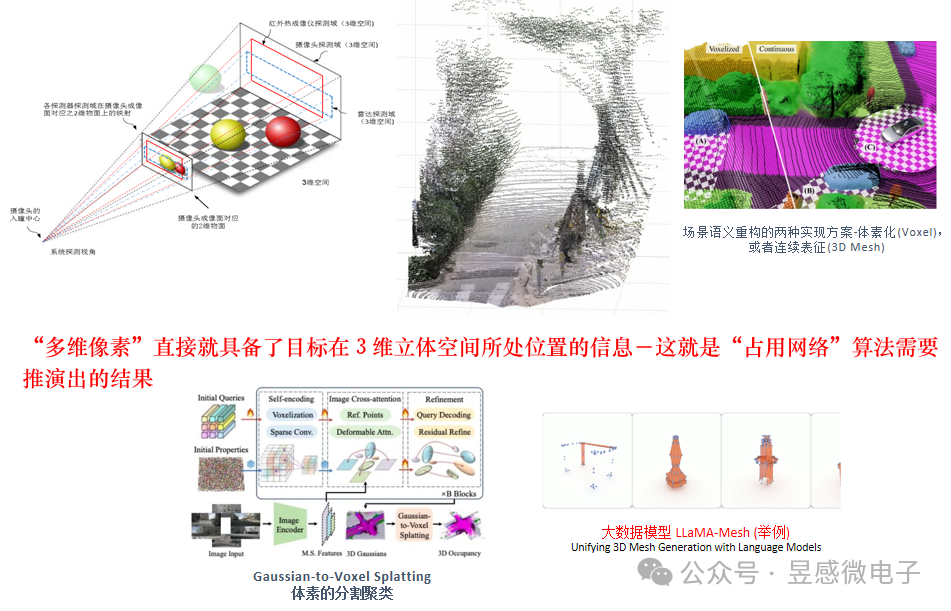
多維像素還可以直接高效支持“占用網絡” (Occupancy Network)算法。占用網格是指將感知空間劃分為一個個立體網格(體素),通過檢測網格空間是否被占用來完成3D空間場景的語義表征(包括探測到各類異形物體)——這也是特斯拉等車廠目前力推的視覺算法。昱感微的“多維像素”包含了目標的圖像信息、3D空間位置信息、目標的速度信息和材質信息,可以直接高效實時支持占用網格中的體素算法。并且,昱感微目前已經可以提供的產品的空間感知分辨率(右下圖)的精準度遠高于特斯拉公開方案中的體素顆粒度(左下圖)。

基于“多維像素”感知數據來做場景語義重構(體素Voxel,或者,立體連續表征3D Mesh),然后支持大數據模型,是最精準高效并節省算力的實現方法。
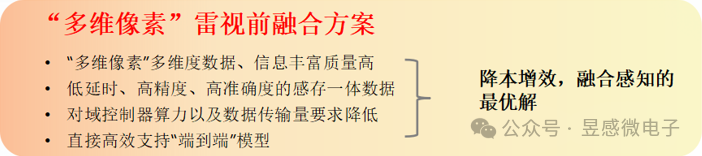
昱感微“多維像素”超級攝像頭方案實時輸出豐富高質量的多維度感知數據,其對目標與環境的3D物理空間感知與定位精度可以達到圖像像素級的精度,多模態感知精度大幅優于人類視覺;此外,得益于“多維像素”包含的豐富高效的感知數據在輸出時就已經完成了全部目標感知數據(對應圖像像素)的確認與精準定位,“多維像素”超級攝像頭方案可大幅降低系統對域控制器算力的要求,并且還能夠高效支持“端到端”感知系統以及生成式驗證系統(高效支撐數字化場景重構)。“多維像素”數據的組合格式在不降低感知有效信息量的前提下大幅降低了數據體量,傳感器感知端側的感知數據傳輸到中央域控端的系統傳輸成本也可以進一步降低。總體來看,昱感微“多維像素”超級攝像頭方案可為客戶提升性能、降本增效,是融合感知的最優解。
審核編輯 黃宇
-
攝像頭
+關注
關注
59文章
4836瀏覽量
95599 -
AI
+關注
關注
87文章
30728瀏覽量
268886
發布評論請先 登錄
相關推薦
多光譜火焰檢測攝像頭



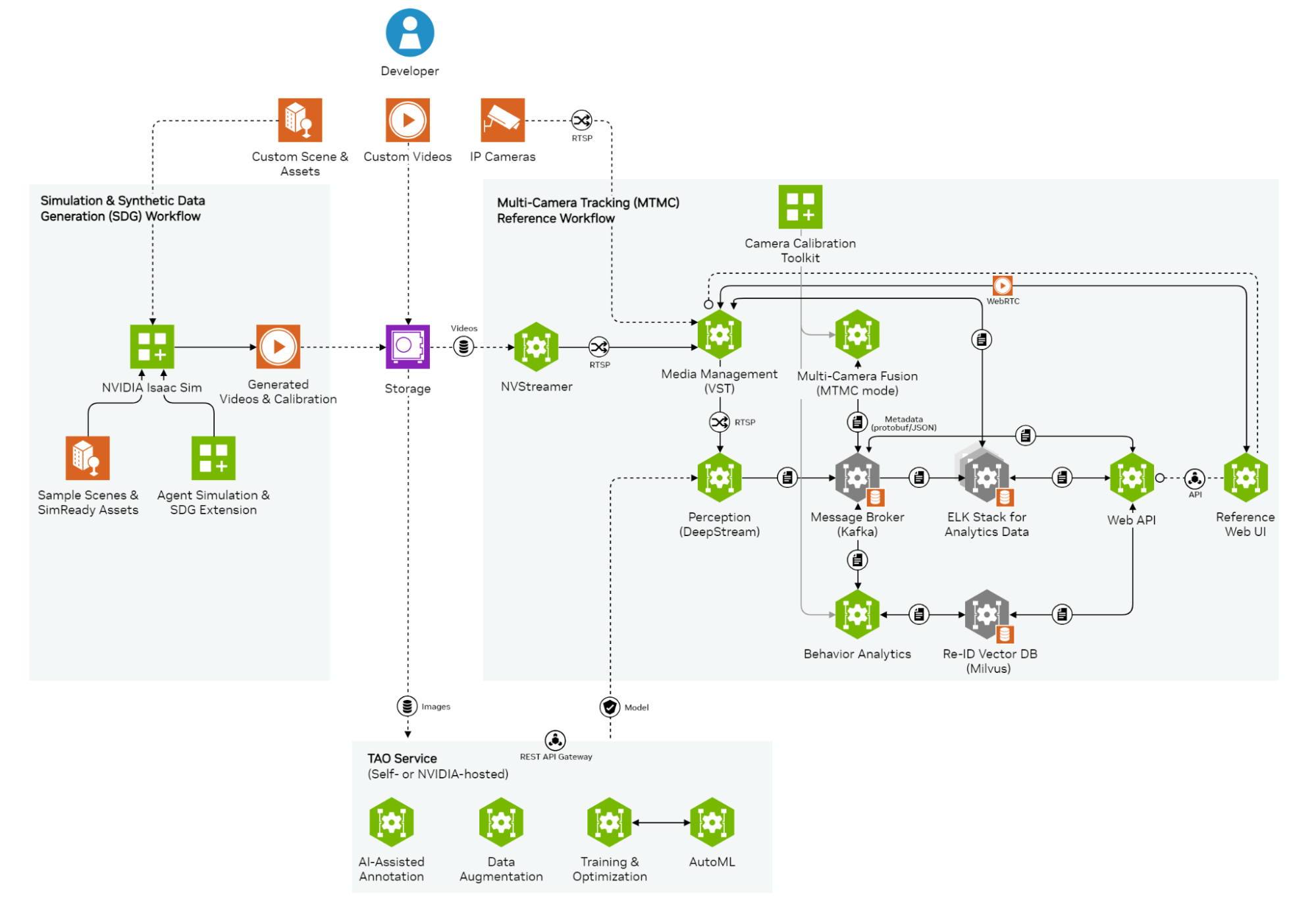
NVIDIA多攝像頭追蹤工作流的應用架構
車規攝像頭被“智子鎖死在800萬像素”?
Epson推出多攝像頭接口芯片S2D13P04
銀牛微電子3D視覺感知方案賦能小米CyberDog系列仿生四足機器人






 工商網監
工商網監
評論