 ARM發布兩款針對移動終端的AI芯片架構:物體檢測和機器學習處理器
ARM發布兩款針對移動終端的AI芯片架構:物體檢測和機器學習處理器
ARM發布了兩款針對移動終端的AI芯片架構,物體檢測(Object Detection,簡稱OD)處理器和機器學習(Machine Learning,簡稱ML)處理器。
以往,ARM都是架構準備好了,才發公告。這次一反常態,沒貨卻先發公告:OD處理器,計劃在第一季度才能提供給合作伙伴;ML處理器得等到年中,這也看出了ARM很焦急。
畢竟在過去的幾個月中,尤其是在移動端圈子里,機器學習在半導體行業中很熱。
好幾家提供芯片架構的公司都宣布了提供消費者解決方案,連華為都開始自主研發架構了。那么多玩家入場,ARM卻沒啥動作。
直到現在,ARM才把重點放在了Armv8.2的CPU ISA擴展上,該擴展借助半精度浮點和整數點產品來簡化和加速神經網絡的專用指令。
除了CPU的改進之外,還看到了G72中機器學習的GPU改進。雖然這兩項改進都有所幫助,但想要最大性能和效率,這些改進還不夠。
在測試Kirin 970的NPU和Qualcomm的DSP時,可以看出,專用架構上運行推理的效率,比在CPU上運行的效率高出一個數量級以上。
正如ARM官方解釋的那樣,Armv8.2和GPU的改進只是建立機器學習解決方案的第一步,還必須研究對專用解決方案的需求。
ARM也從合作的小伙伴那里感受到了行業的壓力,才熬出來ML處理器。
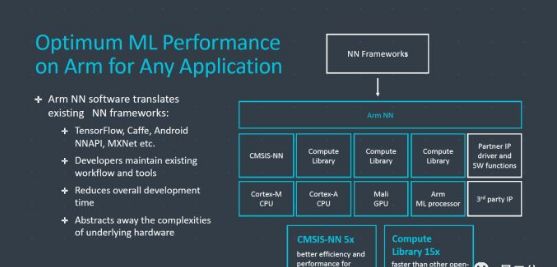
下面簡單介紹一下這次發布的兩個新的架構:機器學習ML處理器以及OD處理器。
ML處理器,是專門為加速神經網絡模型推理所設計的。這種架構比傳統的CPU和GPU架構有明顯的優勢。
在執行機器學習任務時,這款ML處理器可為數據優化內存管理。
這款處理器具有數據可高度重復使用的特點,能最大限度地減少數據的輸入和輸出,從而實現高性能和高效率。

ML處理器,理論上可在1.5W功率下,有超過4.6TOPs(8位整數)的理論吞吐量,最高可達3TOPs / W。
雖然TOPs值并不能完全體現處理器的性能,不過它對于行業標準化仍然有用。
作為一個完全獨立的獨立IP(電路功能)模塊,ML處理器具有自己的ACE-Lite接口,可集成到SoC中,也可以集成到DynamiQ中。
此外,ARM沒有透露ML處理器更多的架構信息。
OD處理器,是針對物體檢測的任務進行了優化。盡管ML處理器也能完成相同的任務,但OD處理器可以更快。給單項任務提供專用架構,才能夠獲得最大效率。

ARM也考慮到了可能會出現OD和ML處理器集成在一起用的情況:OD處理器負責把圖像中的目標處理區分割出來,然后把它們傳遞給ML處理器,進行更細顆粒度的處理。

ARM還提供大量軟件,幫助開發人員將他們的神經網絡模型應用到不同的NN框架中。從今天開始,這些軟件大家可以在ARM開發者網站找到,同時也在Github上提供。
考慮到SoC開發的周期,基于新架構的芯片大概得在2019年年中或年末才能發布。ARM這次,可以說半導體及架構供應商中響應AI趨勢比較慢的企業了。
-
ARM
+關注
關注
134文章
9084瀏覽量
367390 -
AI
+關注
關注
87文章
30728瀏覽量
268892 -
機器學習
+關注
關注
66文章
8406瀏覽量
132567
原文標題:擁抱AI大趨勢,ARM發布兩款AI芯片架構
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Arm自研AI芯片,英偉達、MTK聯合研發Arm AI PC處理器,算力之戰升級
Cincoze德承推出兩款全新GPU嵌入式工控機
恩智浦eIQ AI和機器學習開發軟件增加兩款新工具
ARM處理器和CPU有什么區別
ARM處理器和CISC處理器的區別
ARM處理器的結構和特點
ARM處理器概述和發展歷程
ARMxy ARM工業控制器支持深度學習應用于物體檢測

6nm異構多核!國內首款Arm架構AI PC處理器此芯P1發布

Arm發布針對旗艦智能手機的新一代CPU和GPU IP
Arm發布新一代旗艦智能手機芯片設計
聯發科或將與英偉達開發Arm架構AI PC處理器
NVIDIA推出兩款基于NVIDIA Ampere架構的全新臺式機GPU
繼Instinct MI300X之后,AMD推出兩款車載AI芯片






 工商網監
工商網監
評論