") 聚類分析基本概念梳理
聚類分析基本概念梳理
聚類分析:簡(jiǎn)稱聚類(clustering),是一個(gè)把數(shù)據(jù)對(duì)象劃分成子集的過(guò)程,每個(gè)子集是一個(gè)簇(cluster),使得簇中的對(duì)象彼此相似,但與 其他簇中的對(duì)象不相似。聚類成為自動(dòng)分類,聚類可以自動(dòng)的發(fā)現(xiàn)這些分組,這是突出的優(yōu)點(diǎn)。
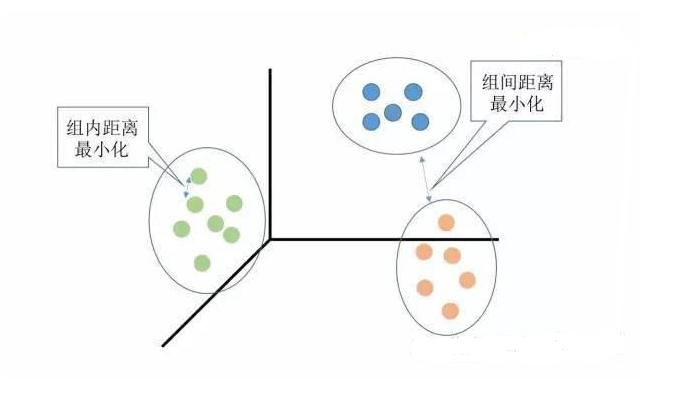
聚類分析是沒(méi)有給定劃分類別的情況下,根據(jù)樣本相似度進(jìn)行樣本分組的一種方法,是一種非監(jiān)督的學(xué)習(xí)算法。聚類的輸入是一組未被標(biāo)記的樣本,聚類根據(jù)數(shù)據(jù)自身的距離或相似度劃分為若干組,劃分的原則是組內(nèi)距離最小化而組間距離最大化,如下圖所示:
常見(jiàn)的聚類分析算法如下:
K-Means: K-均值聚類也稱為快速聚類法,在最小化誤差函數(shù)的基礎(chǔ)上將數(shù)據(jù)劃分為預(yù)定的類數(shù)K。該算法原理簡(jiǎn)單并便于處理大量數(shù)據(jù)。
K-中心點(diǎn):K-均值算法對(duì)孤立點(diǎn)的敏感性,K-中心點(diǎn)算法不采用簇中對(duì)象的平均值作為簇中心,而選用簇中離平均值最近的對(duì)象作為簇中心。
系統(tǒng)聚類:也稱為層次聚類,分類的單位由高到低呈樹(shù)形結(jié)構(gòu),且所處的位置越低,其所包含的對(duì)象就越少,但這些對(duì)象間的共同特征越多。該聚類方法只適合在小數(shù)據(jù)量的時(shí)候使用,數(shù)據(jù)量大的時(shí)候速度會(huì)非常慢。
基本概念梳理
監(jiān)督學(xué)習(xí):分類成為監(jiān)督學(xué)習(xí)(supervised learning),因?yàn)榻o定了類標(biāo)號(hào)的信息,即學(xué)習(xí)算法是監(jiān)督的,因?yàn)樗桓嬷總€(gè)訓(xùn)練元素的 類隸屬關(guān)系。
無(wú)監(jiān)督學(xué)習(xí)(unsupervised learning):因?yàn)闆](méi)有提供類標(biāo)號(hào)信息。
數(shù)據(jù)挖掘?qū)垲惖牡湫鸵笕缦拢嚎缮炜s性、處理不同屬性類的能力、發(fā)現(xiàn)任意形狀的簇、處理噪聲數(shù)據(jù)的能力、簇的分離性
基本聚類方法描述:
1.劃分方法:(這是聚類分析最簡(jiǎn)單最基本的方法)采取互斥簇的劃分,即每個(gè)對(duì)象必須恰好屬于一個(gè)組。劃分方法是基于距離的,給定要構(gòu)建的分區(qū)數(shù)k,劃分方法首先創(chuàng)建一個(gè)初始劃分,然后它采用一種迭代的重定位技術(shù),通過(guò)把對(duì)象從一個(gè)組移動(dòng)到另一個(gè)組來(lái)改進(jìn)劃分。一個(gè)好的劃分準(zhǔn)則是:同一個(gè)簇中的相關(guān)對(duì)象盡可能相互“接近”或相關(guān),而不同簇中的對(duì)象盡可能地“遠(yuǎn)離”或不同。(什么是啟發(fā)式方法?啟發(fā)式方法指人在解決問(wèn)題時(shí)所采取的一種根據(jù)經(jīng)驗(yàn)規(guī)則進(jìn)行發(fā)現(xiàn)的方法。其特點(diǎn)是在解決問(wèn)題時(shí),利用過(guò)去的經(jīng)驗(yàn),選擇已經(jīng)行之有效的方法,而不是系統(tǒng)地、以確定的步驟去尋求答案。 如k-均值(k-means)和k-中心點(diǎn)(k-mediods)方法)。
2.層次方法:層次方法創(chuàng)建給定數(shù)據(jù)對(duì)象集的層次分解。層次方法可以分為凝聚和分裂的方法。凝聚的方法,也稱自底向上的方法,開(kāi)始將每個(gè)對(duì)象作為單獨(dú)的一組,然后逐次合并相近的對(duì)象或組,直到所有的組合并成為一個(gè)組。分裂的方法,也成為自頂向下的方法,開(kāi)始將所有的對(duì)象置于一個(gè)簇中,在每次的迭代中,一個(gè)簇被劃分為更小的簇,直到每個(gè)最終每個(gè)對(duì)象在單獨(dú)的一個(gè)簇中。
3.基于密度的方法:大部分劃分方法基于對(duì)象之間的距離進(jìn)行聚類,這樣的方法只能發(fā)現(xiàn)球狀簇,而在發(fā)現(xiàn)任意形狀簇時(shí)遇到了困難。已經(jīng)開(kāi)發(fā)的基于密度的聚類方法,其主要思想是:只要“鄰域”中的密度(對(duì)象或數(shù)據(jù)點(diǎn)的數(shù)目)超過(guò)了某個(gè)閾值(用戶自定義),就繼續(xù)增長(zhǎng)給定的簇。
4.基于網(wǎng)格的方法:把對(duì)象空間量化為有限個(gè)單元,形成一個(gè)網(wǎng)格結(jié)構(gòu)。所有的聚類操作都在這個(gè)網(wǎng)格上進(jìn)行。這種方法的主要優(yōu)點(diǎn)是處理速度快。
劃分方法:
k-均值方法是怎樣工作的:k-均值方法把簇的形心定義為簇內(nèi)點(diǎn)的均值。流程如下:在D中隨機(jī)的選擇k個(gè)對(duì)象,每個(gè)對(duì)象代表一個(gè)簇的初始均值或中心。對(duì)剩下的每個(gè)對(duì)象,根據(jù)其各個(gè)簇中心的歐氏距離,將它分配到最相似的簇。然后該算法迭代的改善簇內(nèi)變差。對(duì)于每個(gè)簇,它使用上次迭代分配到該簇的對(duì)象,計(jì)算新的均值。然后使用更新后的均值作為新的簇中心,重新分配所有對(duì)象。這個(gè)過(guò)程被稱為迭代的重定位(iterative relocation)。 缺點(diǎn):對(duì)利群點(diǎn)比較敏感。
k-均值算法流程:
1.從數(shù)據(jù)集D中選擇k個(gè)對(duì)象作為初始簇的中心
2.根據(jù)簇中對(duì)象的均值,將每個(gè)對(duì)象分配到最相似的簇。然后更新簇的均值,也就是重新計(jì)算每個(gè)簇的對(duì)象的均值。直到簇中的均值不再發(fā)生變化時(shí)算法結(jié)束
k-中心點(diǎn)算法對(duì)k-均值方法的優(yōu)化:為了降低k-均值算法對(duì)離群點(diǎn)的敏感性,研究了k-中心點(diǎn)方法。我們可以不采用簇中對(duì)象的均值作為參考點(diǎn),而是使用實(shí)際對(duì)象來(lái)代表簇,每個(gè)簇使用一個(gè)代表對(duì)象。其余每個(gè)對(duì)象被分配到與其最為相似的代表性對(duì)象所在的簇中。
k-中心點(diǎn)算法:從數(shù)據(jù)集D中隨機(jī)選擇k個(gè)對(duì)象作為初始的代表對(duì)象或種子 2.將每個(gè)剩余的對(duì)象分配到最近的代表對(duì)象所代表的簇,并隨機(jī)的選擇一個(gè)非代表對(duì)象o并計(jì)算用o代替代表對(duì)象oj的總代價(jià)S,如果S《0,則o替換oj,形成新的k個(gè)代表對(duì)象的集合 3.當(dāng)簇內(nèi)的成員不再發(fā)生變化時(shí)則結(jié)束算法。
k-means VS k-mediods:當(dāng)存在噪聲利群點(diǎn)時(shí),k-中心點(diǎn)方法比k-均值方法更棒,這是因?yàn)橹行狞c(diǎn)不像均值那樣容易受到利群點(diǎn)或其他極端值的影響。然而k-中心點(diǎn)每次迭代的復(fù)雜度是O(k(n-k)^2) 。當(dāng)n合k比較大時(shí),這種計(jì)算開(kāi)銷變得相當(dāng)大,遠(yuǎn)高于k-均值方法。
基于密度的方法:
DBSCAN(一重基于高密度連通區(qū)域的基于密度的聚類):該算法找出核心對(duì)象,也就是其鄰域稠密的對(duì)象。它連接核心對(duì)象和它們的鄰域,形成稠密區(qū)域作為簇。
DBSCAN如何確定對(duì)象的鄰域?:用戶先指定一個(gè)參數(shù)e》0用來(lái)指定每個(gè)對(duì)象的鄰域半徑。對(duì)象o的e-鄰域是以o為中心、以e為半徑的空間。
DBSCAN算法流程:
1.首先標(biāo)記所有的對(duì)象為“未探索”
2.然后隨機(jī)選擇一個(gè)為探索的對(duì)象p并標(biāo)記為“已探索”
3.如果p的e-鄰域至少有MinPts(鄰域密度閾值)個(gè)對(duì)象,則創(chuàng)建一個(gè)新的簇C,并把p添加到C中,并把它們記作N,遍歷N中的每個(gè)成員p‘,如果p’的鄰域也至少有MinPts個(gè)對(duì)象則保留,否則把p‘從N中刪除。
4.否則標(biāo)記p為噪聲 5.直到把所有的對(duì)象都遍歷完為止
-
聚類分析
+關(guān)注
關(guān)注
0文章
16瀏覽量
7409
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
RAM技術(shù)的基本概念
STM32的中斷系統(tǒng)基本概念
電路的基本概念和基本定理
spss聚類分析樹(shù)狀圖
FPGA設(shè)計(jì)中時(shí)序分析的基本概念
介紹時(shí)序分析的基本概念lookup table

介紹時(shí)序分析基本概念MMMC
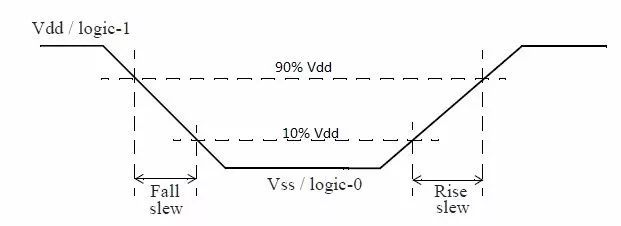
時(shí)序分析Slew/Transition基本概念介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論