 多維數據庫有哪些
多維數據庫有哪些
多維數據庫可以簡單地理解為:將數據存放在一個n維數組中,而不是像關系數據庫那樣以記錄的形式存放。因此它存在大量稀疏矩陣,人們可以通過多維視圖來觀察數據。
多維數據庫是指將數據存放在一個門維數組中,而不是像關系數據庫那樣以記錄的形式存放。因此它存在大量稀疏矩陣,人們可以通過多維視圖來觀察數據。多維數據庫增加了一個時間維,與關系數據庫相比,它的優勢在于可以提高數據處理速度,加快反應時間,提高查詢效率。
1. 多維數據庫簡介
多維數據庫(Multi Dimesional Database,MDD)可以簡單地理解為:將數據存放在一個n維數組中,而不是像關系數據庫那樣以記錄的形式存放。因此它存在大量稀疏矩陣,人們可以通過多維視圖來觀察數據。多維數據庫增加了一個時間維,與關系數據庫相比,它的優勢在于可以提高數據處理速度,加快反應時間,提高查詢效率。MDD的信息是以數組形式存放的,所以它可以在不影響索引的情況下更新數據。因此MDD非常適合于讀寫應用。
1.1. 關系數據庫存在的問題
利用SQL進行關系數據庫查詢的局限性:
1) 查詢因需要“join”多個表而變得比較煩瑣 ,查詢語句(SQL) 不好編程;
2) 數據處理的開銷往往因關系型數據庫要訪問復雜數據而變得很大。
關系型數據庫管理系統本身局限性:
1) 數據模型上的限制
關系數據庫所采用的兩維表數據模型,不能有效地處理在大多數事務處理應用中,典型存在的多維數據。其不可避免的結果是,在復雜方式下,相互作用表的數量激增,而且還不能很好地提供模擬現實數據關系的模型。關系數據庫由于其所用數據模型較多,還可能造成存儲空間的海量增加和大量浪費,并且會導致系統的響應性能不斷下降。而且,在現實數據中,有許多類型是關系數據庫不能較好地處理的 。
2) 性能上的限制
為靜態應用例如報表生成,而設計的關系型數據庫管理系統,并沒有經過針對高效事務處理而進行的優化過程。其結果往往是某些關系型數據庫產品,在對GUI和Web的事務處理過程中,沒有達到預期的效果。除非增加更多的硬件投資,但這并不能從根本上解決問題。
用關系數據庫的兩維表數據模型,可以處理在大多數事務處理應用中的典型多維數據,但其結果往往是建立和使用大量的數據表格,仍很難建立起能模擬現實世界的數據模型。并且在數據需要作報表輸出時,又要反過來將已分散設置的大量的兩維數據表,再利用索引等技術進行表的連接后,才能找到全部所需的數據,而這又勢必影響到應用系統的響應速度。
3) 擴展伸縮性上的限制
關系數據庫技術在有效支持應用和數據復雜性上的能力是受限制的。關系數據庫原先依據的規范化設計方法,對于復雜事務處理數據庫系統的設計和性能優化來說,已經無能為力。此外,高昂的開發和維護費用也讓企業難以承受。
4) 關系數據庫的檢索策略,如復合索引和并發鎖定技術,在使用上會造成復雜性和局限性。
1.2. 多維數據庫的相關定義
維(Dimension):是人們觀察數據的特定角度,是考慮問題時的一類屬性,屬性集合構成一個維(時間維、地理維等)。
維的層次(Level):人們觀察數據的某個特定角度(即某個維)還可以存在細節程度不同的各個描述方面(時間維:日期、月份、季度、年)。
維的成員(Member):維的一個取值,是數據項在某維中位置的描述。(“某年某月某日”是在時間維上位置的描述)。
度量(Measure):多維數組的取值。(2000年1月,上海,筆記本電腦,0000)。
OLAP的基本多維分析操作有鉆取(Drill-up和Drill-down)、切片(Slice)和切塊(Dice)、以及旋轉(Pivot)等。
鉆取:是改變維的層次,變換分析的粒度。它包括向下鉆取(Drill-down)和向上鉆取(Drill-up)/上卷(Roll-up)。Drill-up是在某一維上將低層次的細節數據概括到高層次的匯總數據,或者減少維數;而Drill-down則相反,它從匯總數據深入到細節數據進行觀察或增加新維。
切片和切塊:是在一部分維上選定值后,關心度量數據在剩余維上的分布。如果剩余的維只有兩個,則是切片;如果有三個或以上,則是切塊。
旋轉:是變換維的方向,即在表格中重新安排維的放置(例如行列互換)。
1.3. 多維數據庫的特點
后關系型數據庫的主要特征是將多維處理和面向對象技術結合到關系數據庫上。這種數據庫使用強大而靈活的對象技術,將經過處理的多維數據模型的速度和可調整性結合起來。由于它獨有的可兼容性,對于開發高性能的交換處理應用程序來說,后關系型數據庫非常理想。在后關系型數據庫管理系統中,采用了更現代化的多維模型,作為數據庫引擎。并且,這種以稀疏數組 為基礎的獨特的多維數據庫架構,是從已成為國際標準的數據庫語言基礎上繼承和發展的,是已積累了實踐經驗的先進而可靠的技術。
多維數據模型能使數據建模更加簡單,因為開發人員能夠方便地用它來描述出復雜的現實世界結構,而不必忽略現實世界的問題,或把問題強行表現成技術上能夠處理的形態,而且多維數據模型使執行復雜處理的時間大大縮短。例如開發一個服裝連鎖店信息管理系統時,如果用關系數據庫,就需要建立許多表,一張表用來說明每種款式所具有的顏色和尺寸,另一張表用來建立服裝和供應商之間的映射,并表示它是否已被賣出,此外還需要建一些表來表示價格變化、各店的庫存等等。每成交一筆生意,所有這些表都需要修改,很快這些關系數據庫就會變得笨重而緩慢。而在多維數據模型中,可以將這些數據看做是存在于一個“立方體”中,這個“立方體”有足夠多的“面”,以便對數據進行完全分類,如款式、顏色、價格、庫存等等都能夠立刻互相映射,獲取數據極其迅速,而且由于清除了冗余的數據,多維數據庫非常簡單,不僅好用,而且更經濟。
2. 現有多維數據庫相關分類
現有的多維數據庫主要分為“純”多維數據庫和“準”多維數據庫,前者以cache這種不依附與關系數據庫的數據庫種類為主,后者主要是依附于關系數據庫,在其之上提取數據生成多維數據表便于進行統計和分析。
現有的準多維數據庫大多是基于關系數據庫為基礎,在關系數據庫提供數據的基礎上建立多維數據,便于查詢和分析。主要包括以下幾個:基于Oracle的ORACLE EXPRESS SERVER,基于SQL Server的Microsoft SQL Server Analysis Services,基于DB2的OLAP Server以及Hyperion Essbase 數據庫。
2.1. Cache數據庫
Caché 數據庫是一種面向對象的多維數據庫,同時支持SQL的訪問方式。在數據庫的劃分上,超越關系數據庫被稱為第三代,后關系型數據庫。該數據庫有以下特點:
1、速度快。Cache數據庫在同等條件下查詢相同數據比Oracle等普通數據庫要快。Cache是基于普通關系型數據庫如:Oracle, SQL server, Sybase等的基礎之上并有所改進而產生的。Caché在性能上可以和內存數據庫比美,在一臺筆記本上可以實現每秒數萬條的插入速度。Caché獨特的動態的位圖索引技術 可以實現數據庫在更新的同時做查詢和分析,而不影響使用性能。
2、使用簡單。Cache數據庫支持標準SQL語句,因此不太熟悉M語言 的用戶依然可以輕易對數據庫中的數據進行操作。
3、接口容易。Cache數據庫支持ODBC標準接口,因此在與其他系統進行數據交換時非常容易。同時Cache亦可以將數據輸出成文本文件格式以供其它系統訪問調用。
4、真正的3層結構。Cache數據庫能夠真正意義上實現3層結構,實現真正的分布式服務。升級擴容方便。正因為由上述分布式3層結構,所以當醫院需要增加客戶端PC或醫院進行擴大規模時,不需要重新購買或更新主服務器,只需要適當增加二級服務器的數量即可,二級服務器相對來說要比主服務器要便宜許多,因此,醫院可節約資金減少重復投資。
5、對象型編輯。Cache數據庫是真正的對象型數據庫,開發時用戶可直接用數據庫定義自己想要的對象,然后再在其它開發工具中調用該對象的方法和屬性即可完成開發工作,非常方便。支持遠程映射和鏡像。Cache數據庫支持遠程的映射和鏡像,比如在不同城市之間,或在同一城市的不同區域之間,Cache可以進行鏡像(Mapping),使不同區域的Cache數據庫同步聯系起來,雖然在不同區域,但大家使用起來就像共用一個數據庫。
6、靈活性。基于Caché數據庫的應用軟件不僅可以不經修改便能在多種操作系統平臺上(如Windos98/NT、各種UNIX和Linux環境下運行,也可以隨意布署運行在兩層或三層的C/S結構即客戶機/服務器環境中,或者B/S結構即瀏覽器/服務器環境中。而且應用服務器和數據庫服務器的數量是在運行中是隨意可以增加擴充而不影響運行。
7、支持WEB開發。Cache 數據庫提供自帶的Web開發工具,使用維護非常方便,符合當今軟件業發展的趨勢。
8、價格便宜。Cache數據庫的價格比Oracle要便宜許多。
這種數據庫已經超越了傳統關系數據庫的局限,在Internet或Client/Server環境下任務關鍵和突發大負載的情況下,Caché具有獨特超群的高響應速率特性、高度靈活的可伸縮性能、高強度聯機處理能力。
在InterSystems 全球業務里,有50%是醫療行業,30%在金融業、另外20%在船務、飯店管理、會議系統等方面。所有這些行業都有一個共同點,都需一個龐大的數據庫,數據需要很快更新。國外的成功案例已經有許多,如:美國十大醫院、三大醫療衛生實驗機構、全球最大的在線證券交易公司、美林投資集團、美國國防部等均采用了Caché數據庫;國內目前也有一些應用,但主要限于醫療行業,如:北京安貞醫院、福州軍區總醫院和哈爾濱醫科大學第一附屬醫院等。在美國和歐洲的HIS系統中,CACHE數據庫所占的比例是最大的,被醫療界公認為首選數據庫。
2.2. Microsoft SQL Server Analysis Services
SQL Server 2008 Analysis Services工具,實現了多維分析數據庫的構建,同時提供了管理工具與用戶訪問軟件。它使用了一種稱為“Block Computation(分塊計算)”的技術,存儲模式使得分區的聚合和其源數據的復本以多維結構存儲在分析服務器計算機上。利用了多維數據集的稀缺性,僅處理非 NULL 數據,以提高查詢效率。更加適合于頻繁使用的多維數據集中的分區和對快速查詢響應的需要。能夠極大地提高查詢效率,因此可以更細的粒度進行分析。Analysis Services 中的數據挖掘算法提供了這種預測分析能力,而 SQL Server 2008 Analysis Services 改善了數據挖掘算法,可以實現更全面的分析。
SQL Server 2008 Analysis Services 新引進了一套創新的 Best Practice Design Alerts(最佳實踐設計警報),可在開發流程的早期階段對潛在的設計問題自動發出通知,這會減少由于設計錯誤導致的時間浪費,并有利于實施更快的開發流程。SQL Server 2008 Analysis Services 利用新的、改進的多維數據集、維度和屬性設計器,進一步提高了開發人員的工作效率。Analysis Services 可以進行縮放,以支持許多規模達到兆兆字節并且服務于數千名用戶的數據庫。SQL Server 2008 Analysis Services 提供了與數據庫引擎所用的類似的 Dynamic Management Views(動態管理視圖)。這些特性提供了實時的企業系統信息,用于監視、分析和進行性能調整。SQL Server 2008 Analysis Services 之后,新的備份存儲子系統會使備份時間隨著數據庫大小的增加僅按線性增長。
Analysis Services 10.0 OLE DB 訪問接口 (msolap100.dll) 是應用程序與 Microsoft Analysis Services 進行交互的接口。ADOMD.NET 是用于與 Microsoft SQL Server Analysis Services 進行通信的 Microsoft .NET Framework 數據訪問接口。
2.3. Oracle Express Server
Oracle Express Server是一個先進的計算機引擎和數據高速緩存。它使用多維模型,多維模型最能反應用戶對其業務的思考方法,將電子表格的行和列擴展三維或者更多的維。維可以是時間、產品、產品系列、地區,用戶分析的對象可以是像單位銷售額這樣的綜合數據。對于多維模型的查詢是很迅速的。這些查詢是對數組中的某一部分的算術計算。因此,這個數組支持最大、最復雜的OLAP應用。
Express Server能夠存儲和管理多維數組,或者通過一種只需很少、甚至不需索引的復雜的多維高速緩存方案,提供直接面向關系的分析。Oracle Express Server不僅支持多維模型,而且具有分析、預測、建模,以及對進行假設分析的能力。具有用于數學、財務、統計和時間序列管理等方面的內置功能。具有伸縮性、強健性和基于應用的特性,支持多個用戶,并且為大型庫實現完整性控制。靈活的數據組織方式,數據可以存放在Express Server內,也可直接在RDB上使用,有內建的分析函數和4GL用戶自己定制查詢。
Oracle Express Server是先進的多維計算引擎,是進行OLAP分析的基礎。Express Server的最新版本是6.3,這個版本在處理能力、分析功能等多方面有重大改進。
1. 處理能力的提高:Express Server 6.3展示了OLAP 服務器最快的計算能力和查詢性能。Express Server 6.3引入了很多新特性,可以極大提高Express Server對大數據量和大的并發用戶數的支持。
2. 更快的匯總計算:Express Server 6.3引入了全新的匯總計算管理機制。新的匯總機制允許定制匯總方法,并且可以顯著降低裝載和匯總計算的時間。
3. 分析功能的提高:新引入的統計分析函數將使Express Server 6.3的分析能力顯著提高。
4. 預測功能的提高:新的預測系統將提供數據抽樣和基于數據模式推薦最佳預測方法的能力。
5. 基于Web的管理工具:Express Server 的管理將由新的Express Instance Manger統一進行,Express Instance Manger是基于Java的應用,可以和Oracle Enterprise Manager集成。這使DBA可通過Oracle Enterprise Manager的Java窗口或Browser對NT或UNIX上的多維數據庫進行管理。
6. Oracle Express 對Web技術的支持:Express Server 的一個重要發展策略是支持Internet計算,這也是Express產品領先于同類產品的一個重要方面。DBA可通過Oracle Enterprise Manager的Java窗口或Browser對NT或UNIX上的多維數據庫進行管理。Express Server 從6.0版本開始增加了Express Web Agent選項,使基于Express Server的OLAP應用擁有了Web公布能力
7. 支持各種關系型數據庫系統的集成。
2.4. DB2 OLAP Server
IBM公司提供了一套基于可視數據倉庫的商業智能(BI)解決方案,包括:Visual Warehouse(VW)、Essbase/DB2 OLAP Server 5.0、IBM DB2 UDB,以及來自第三方的前端數據展現工具(如BO)和數據挖掘工具(如SAS)。其中,VW是一個功能很強的集成環境,既可用于數據倉庫建模和元數據管理,又可用于數據抽取、轉換、裝載和調度。Essbase/DB2 OLAP Server支持“維”的定義和數據裝載。Essbase/DB2 OLAP Server不是ROLAP(Relational OLAP)服務器,而是一個(ROLAP和MOLAP)混合的HOLAP服務器,在Essbase完成數據裝載后,數據存放在系統指定的DB2 UDB數據庫中。
嚴格說來,IBM自己并沒有提供完整的數據倉庫解決方案,該公司采取的是合作伙伴戰略。例如,它的前端數據展現工具可以是Business Objects的BO、Lotus的Approach、Cognos的Impromptu或IBM的Query Management Facility;多維分析工具支持Arbor Software的Essbase和IBM(與Arbor聯合開發)的DB2 OLAP服務器;統計分析工具采用SAS系統。
IBM DB2 OLAP Server把Hyperion Essbase的OLAP引擎和DB2的關系數據庫集成在一起。,與Essbase API完全兼容,數據用星型模型存放在關系數據庫DB2中。
2.5. Hyperion Essbase
Hyperion Essbase是一個聯機分析處理(OLAP)服務器,使用一個多維模型從一系列數據源中提取數據,計算后對它們加以綜合,然后提供對結果的快速訪問。是一個多維數據庫服務器,可以創建“塊存儲”或“聚合存儲”數據庫,前者用于需要進行讀/寫訪問的小型、高密度的數據集,后者用于具有很多維度和只讀訪問的稀疏、銷售分析類型的應用程序。
Essbase是BI軟件hyperion的多維數據庫,目前已更新至11版本。 它不同于通常意義上的關系數據庫,Essbase把數據按“塊”劃分,每個數據塊會定義不同的維度。其中Essbase有7個默認維度,并可以自行定義13個用戶維度。 7個默認維度為科目、期間、年份、情景、貨幣、版本、實體。
Essbase的特點:
1、 高性能:快速地查詢響應
2、 計算/分析能力
聚合
無限制的跨維計算能力
場景假設分析
分攤
趨勢分析/回歸分析
決策樹/神經網絡/關聯分析
財務智能/貨幣轉換
數學函數
預測
Hyperion Essbase現狀:以服務器為中心的分布式體系結構–有超過100個的應用程序;有300多個用Essbase作為平臺的開發商;具有幾百個計算公式,支持多種計算;用戶可以自己構件復雜的查詢;快速的響應時間,支持多用戶同時讀寫;有30多個前端工具可供選擇;支持多種財務標準;能與ERP或其他數據源集成;全球用戶超過1500家
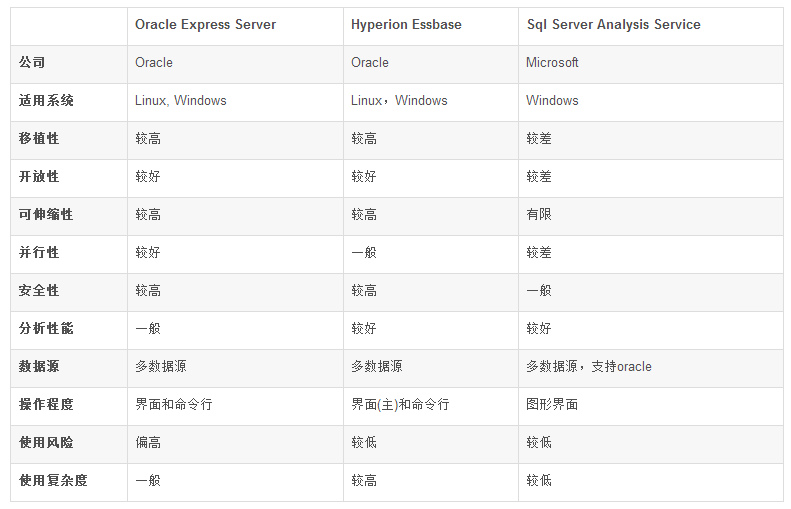
3. 簡要比較
綜合以上5種多維數據庫的比較如下:
作為醫療界公認為首選數據庫,Cache數據庫的優點較多,如具有較快的查詢速度,使用簡單和靈活性等特點,適合在開發階段直接使用,由于采用直接插入數據的形式,所以對已有未用Cache的老產品不太適合,數據的遷移性不太好。
作為微軟在多維數據上應用的典型產品,Analysis Services具有較好的查詢和分析性能,并且由于Sql Server的廣泛應用,使得Analysis Services有較多的應用。Sql Server 2008對Analysis Services做出了一些改進,進一步提高了查詢效率和分析能力。在數據源方面適用于多種數據源,但是該系統的應用環境只是windows,不能用于Linux系統上。
Oracle支持關系數據存儲和多維數據存儲,利用Oracle Express Server實現多維數據的存儲,在Express Server 6.3公布之前,Oracle Express Server 的技術更新的太慢,占用的內存很大,影響了其應用。Express Server 6.3提高了處理能力和分析能力,但是提高的程度有待于驗證。
DB2 OLAP Server是一個ROLAP和MOLAP混合的HOLAP服務器,在Essbase完成數據裝載后,數據存放在系統指定的DB2 UDB數據庫中。對Essbase的API完全兼容。主要應用在DB2的數據庫之上。
Hyperion Essbase是多維數據庫服務器,支持從廣泛的數據源提取數據,但與 Oracle OLAP 將數據存儲在關系數據庫引擎外不同,它通常將數據存儲在自己的專用服務器上,從而具有較快的查詢響應以及計算分析能力。
考慮現在應用的數據庫為Oracle數據庫,盡管cache數據庫和DB2 OLAP Server性能較高,但短時間內使用這兩種產品的可能性不大,現有數據庫數據不能快速順利的移植或者應用到Cache數據庫,DB2 OLAP Server會依托于Hyperion Essbase數據庫,與現用的Oracle數據庫同時使用會有些累贅。所以暫時選擇以下三種策略。
策略1:Oracle + Oracle Express Server
策略2:Oracle + Hyperion Essbase
策略3:Oracle + SQL Server Analysis Service
綜合比較上述三種策略如下:?
表1:三種策略比較
-
多維數據
+關注
關注
0文章
6瀏覽量
6560 -
多維數據庫
+關注
關注
0文章
2瀏覽量
1459
發布評論請先 登錄
相關推薦
數據倉庫和多維數據庫的區別在哪里
數據庫教程之如何進行數據庫設計
數據庫學習教程之數據庫的發展狀況如何數據庫有什么新發展
數據庫有哪些常見的應用結構數據庫應用結構的使用資料概述
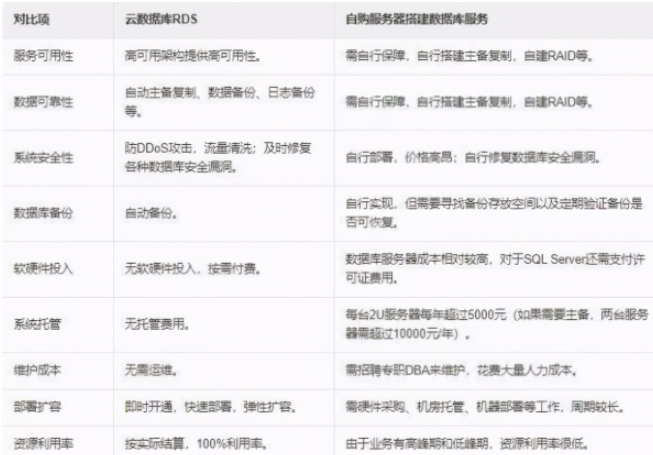
恒訊科技介紹:什么是數據庫?有哪些類型?
云數據庫和普通數據庫區別?|PetaExpress云端數據庫
輕量級數據庫有哪些
python讀取數據庫數據 python查詢數據庫 python數據庫連接
什么是JSON數據庫

關于JSON數據庫

數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫






 工商網監
工商網監
評論