 2024,大模型殺進“決賽圈”
2024,大模型殺進“決賽圈”

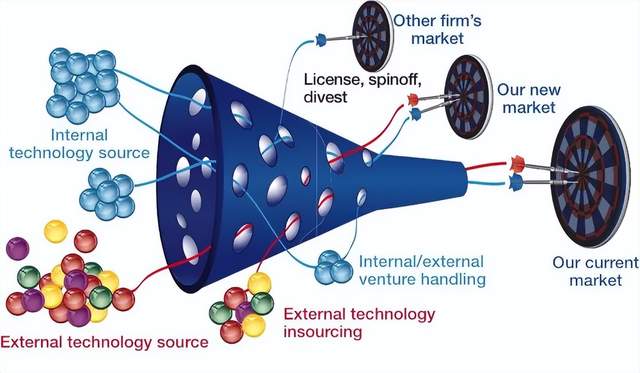
Henry Chesbrough在著作《通過技術創新盈利勢在必行》中,曾提出過一個創新的“漏斗模型”。開放式創新一開始鼓勵百花齊放,但最終只有10%的技術能夠通過這個漏斗,成功抵達目標市場target market,進入到商業化與產業化的下一個階段,而其余的90%的技術,逐漸淡出人們的視野。
大模型的2024,就經歷了漏斗秩序的殘酷檢驗。
2023年初,業界最關注的問題是“中國能不能孕育出頂尖的大模型”。隨后一年,國產大模型數量的井噴式增長,完成備案并上線服務的大模型數量已達100多個。
于是到了2024年初,大家最關注的問題已經變為“這么多的大模型,我們該怎么消化和利用?”
如今來看,經過百模大戰,基礎大模型已“去九存一”。只有約10%的具有市場活力、用戶活躍度高的大模型脫穎而出,進入到了決賽圈。大模型的商業市場,也從百家爭鳴,收束為兩股勢力:
一是以互聯網、云計算企業為代表的科技巨頭,包括百度的文心大模型、阿里的通義大模型、騰訊的混元大模型、字節跳動的豆包大模型、華為的盤古大模型。二是以“AI六小虎”為代表的頭部創企,比如智譜AI的智譜清言、零一萬物的Yi大模型家族。
可以說,大模型在2024年,走過了一個完整的“漏斗模型”。但重資產的大模型行業,競爭也遠比一般技術更殘酷。我們預計,99%的大模型都會喪失產業空間。所以,這場模型淘汰賽并未到終局。接下來,基礎模型的創新漏斗還會進一步收窄,最終僅留下三四個產品,作為AI基礎設施。
我們還是有必要花一點篇幅,來回溯一下2024年的大模型淘汰賽,留下了哪些種子選手。

2024國內外的大模型格局,都呈現出鮮明的馬太效應。在海外,OpenAI、谷歌、微軟等巨頭屹立不倒,而眾多大模型初創公司,諸如Stability AI、Adept、Humane、Reka AI等,則排隊尋求出售。
國內的情況也大致相似。以互聯網和云廠商為代表的科技巨頭(百度、阿里、騰訊、華為、京東、字節跳動),以及融資能力出眾的AI創企(AI六小虎),成為大模型商業市場中具備活力的競爭者。
潮水退去,暴露出沙灘上的礁石,而產學各界煉大模型的熱情消退,我們得以在2024年看到更清晰的大模型商業模式。具體來說,大模型成功穿過漏斗,需要三種動力:
1.可持續的資源投入。AI大模型是一個重資產行業,2024年Scaling Law仍未失效,隨著模型不斷變大,訓練新模型所需要的高質量數據量與計算量也在增加。這就像登山,百尺竿頭更進一步。而頭部企業在資金、技術、數據等方面的優勢日益凸顯,代表就是字節跳動。

字節跳動2024年才開始全力押注大模型,5月推出的豆包大模型很快就在業內嶄露頭角,日均Tokens使用量從5月份的1200億,9月突破了1.3萬億。憑借此前的火山云基礎設施和人才團隊積累,以及這一年大舉挖人、增加投入,在幾個月內就建立了優勢壁壘。
3.快速迭代的模型能力。字節跳動的后來居上、快速超車,也說明AI大模型并沒有特別安全的護城河。模型能力在不斷貶值,有了新的更高級的模型版本,舊模型就不值錢了;有了開源模型,能力接近的閉源模型就會被開發者放棄。這就要求模廠不斷開發更強大的新模型,迭代舊模型。
比如文心大模型,得益于百度在芯片、框架、模型和應用上的全棧布局,以及飛槳深度學習平臺和文心的聯合優化,文心大模型的迭代速度,一直處于業內領先水平。2024年百度在文心大模型4.0的基礎上,相繼推出了文心大模型4.0工具版、文心大模型4.0 Turbo,推理速度和效果進一步提升。而模型的迭代速度快,有助于增強用戶和開發者的信心,增加使用黏性和付費意愿。

3.可變現的商業通道。模廠的競爭,不僅表現在基礎模型的研發上,而體現在后續的商業推廣。
2024年,大模型從“價格戰”殺到了“免費戰”,5月字節跳動將國內大模型的市場價格帶入“厘時代”,隨后文心大模型就宣布兩大主力模型ENIRESpeed和ENIRELite全面免費。隨著模型進入免費時代,模廠就必須有其他商業通道來實現營收,收回自己在大模型上的前期投入。
其中,科技巨頭大多直接掌握著用戶數據、應用產品和渠道資源,可以讓AI大模型觸達最終用戶,為價值付費。比如百度文庫app,就通過AI改造,上線了基于文心大模型的智能PPT、智能畫本等一系列AI功能,付費用戶快速增長,目前已有數千萬AI月活用戶。
而AI創企則有望憑借新銳的技術和產品解決方案,在商業市場中脫穎而出。“六小虎”中,零一萬物明確表示不會放棄預訓練模型。目前,零一萬物正基于Yi 系列基座模型的標準化能力,深入業務場景的垂直精細化切口,推出了數字人解決方案“如意”、營銷短視頻解決方案“萬視”。
總的來說,2024的大模型產業,就是一個又一個的大模型被推向市場之后,不得不面對一個狹窄的“漏斗”出口,經歷一場艱難的淘汰賽。互聯網與云計算巨頭和極少數AI獨角獸,成功穿過漏斗,抵達下一階段。

2024年的淘汰賽洗禮,讓大模型去九存一,產業格局更加合理,只留下了約10%的大模型進入決賽圈。
從結果看,大模型呈現出“強者恒強”的馬太效應。那么,這些強者是怎么從戰場中廝殺出來的呢?如果說2023年,大模型的關鍵一戰,是基礎設施攻堅戰,各個模廠都不遺余力地建設訓練大模型所需要的算力集群和高端硬件資源,那么2024年,大模型的關鍵一戰,則轉向了商業市場的爭奪戰。
爭奪活躍用戶,這一年大模型的商業市場有兩個主題:
主題一,燒錢營銷。
基于大模型的生成式AI(AIGC)產品,可以通過為用戶提供服務來完成商業轉化,這也成為大模型最直接、最快速的商業化路徑。2024年,AIGC產品爆發,根據《生成式人工智能服務已備案信息》顯示,截至2024年11月,我國共有309個生成式人工智能產品完成備案。而如此繁多的AIGC產品,存在大量重疊的功能,于是,模廠不得不通過大規模、高頻次的市場推廣和營銷活動,來爭奪活躍用戶,提高用戶基數。

月之暗面、智譜等都被報道過在營銷上砸了重金,kimi智能助手的平均單個用戶獲客成本高達30元。
這些燒錢營銷的AIGC產品,切實提升品牌知名度和用戶基數,但也必須承認,最終能夠激活多大的商業價值尚不明確。
主題二,走向應用。
不燒錢買流量,不賠本賺吆喝,大模型有可能賺到錢嗎?那就需要向應用走。走向產業,走向廣大用戶和開發者,通過價值付費、項目付費等實現商業化,2024年,“大模型致用”已經是事實。
首先是智能體,讓大模型更有用。大模型的應用從AI助手,轉向了智能體,比如豆包、kimi、文小言等,能夠自動拆解指令并執行一些簡單的操作,“自動駕駛”水平更好,極大地提升了技術的可用性。
其次是工具鏈,讓大模型更好用。文心智能體平臺、字節跳動扣子、阿里通義千問等,都推出了智能體技術及工具鏈的支撐能力,普通人也能快速低成本地制作屬于自己的智能體。其中,押注“AI應用化”的百度在智能體生態上布局最全,推出了APP builder、Agent builder等開發平臺,以及本地部署一體機等硬件,支持C端和行業用戶開發專屬智能體。字節跳動的扣子也極易上手,用戶可以復制官方的高質量模板,結合私有數據快速完成智能體開發,并發布到字節系等產品中使用。
“砸錢買量”“以用換量”,這兩大主題交織在2024年的大模型商業化之戰中,一家模廠可能綜合運用這兩種手段,來確保大模型的用戶基數與市場活力,穩固住這一階段的領航地位。

消費級技術,有一個基本規則:將復雜技術簡單化,從而解鎖突破性應用。就像我們平時發郵件,不需要探究背后的SMTP協議,使用手機支付,也不必弄懂背后的加密技術。這種“藏起代碼”的簡化,使得技術更加易用,因此能夠更快普及和擴展。
由此,我們可以預測一下,底層模型的“決賽圈”可能發生哪些變化:
模型數量變少。科技巨頭和AI創企領航的大模型們,還將繼續洗牌,最終只留下3—4個基礎模型,作為基礎設施來支撐豐富多樣的下游應用。這個過程中,投入的可持續性、迭代速度、商業化能力依然會發揮關鍵影響,互聯網公司和云廠商的勝算更大。
使用進一步簡化。目前來看,大模型技術的使用還有繼續簡化的空間。比如智能體開發,仍然沒有實現低代碼或零代碼,一旦涉及個性化場景的專業插件、知識庫、數據處理等,開發工程的復雜度就又會變高,阻攔一些行業專家開發專業性更強的智能體,這限制了大模型在B端的爆發。所以2025年,智能體開發與專屬模型訓練,應該會變得更簡單、傻瓜式,想上手AI開發的零基礎讀者不妨期待一下。
生態變大。人人都能上手AI開發,涉及對私有敏感數據的訓練分析,以及多種多樣的個性化功能需求,因此基礎模廠不能只提供對一個底層模型的簡單封裝,而要支持本地訓練與部署,多種模型的調用與組合,更多元的發布渠道,這些要求基礎模廠能夠將AI硬件、AI終端、垂類模廠、渠道伙伴等都納入自身的生態體系內,共同滿足用戶的定制化需求。“朋友圈”有多大,也是2025年的一個大模型賽點。
2024年,底層模型的中場戰事宣告結束,進入決賽圈。隨著大模型的漏斗被收束到最小,AI應用的漏斗才剛剛開始噴發。你聽,“人人皆可AI”的2025離我們越來越近了。

審核編輯 黃宇
-
AI
+關注
關注
87文章
30728瀏覽量
268886 -
大模型
+關注
關注
2文章
2423瀏覽量
2640
發布評論請先 登錄
相關推薦
2024全國大學生FPGA創新設計競賽紫光同創杯勇攀新高
云知聲榮登2024大模型企業TOP50榜單
預決賽節點公布丨第七屆CCF開源創新大賽火熱進行中!

杰和科技圈粉無數!2024 ISVE展會回顧

西井科技成功入選《2024大模型典型示范應用案例集》

2024“芯原杯”全國嵌入式軟件開發大賽決賽成功舉辦
商湯“日日新”大模型全面賦能2024 WAIC
華為HDC 2024看點 華為云盤古大模型5.0正式發布

華為ICT大賽2023-2024全球總決賽獲獎名單揭曉

云天勵飛入選2024中國AI基礎大模型創新企業

2024中國AI大模型產業發展報告

名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
2024國內各手機品牌大語言模型進展






 工商網監
工商網監
評論