") 在邊緣設(shè)備上設(shè)計和部署深度神經(jīng)網(wǎng)絡(luò)的實用框架
在邊緣設(shè)備上設(shè)計和部署深度神經(jīng)網(wǎng)絡(luò)的實用框架
???? 機器學習和深度學習應用程序正越來越多地從云端轉(zhuǎn)移到靠近數(shù)據(jù)源頭的嵌入式設(shè)備。隨著邊緣計算市場的快速擴張,多種因素正在推動邊緣人工智能的增長,包括可擴展性、對實時人工智能應用的不斷增長的需求,以及由強大而高效的軟件工具鏈補充的低成本邊緣設(shè)備的可用性。此外,需要避免通過網(wǎng)絡(luò)傳輸數(shù)據(jù)——無論是出于安全原因還是僅僅為了盡量減少通信成本。
邊緣人工智能涵蓋廣泛的設(shè)備、傳感器、微控制器、片上多微處理器、應用處理器和專用片上系統(tǒng)——包括相對強大的邊緣服務器和物聯(lián)網(wǎng)模塊。參考社區(qū),TinyML 基金會,成立于 2019 年,專注于開發(fā)機器學習模型并將其部署在內(nèi)存、處理能力和能耗預算有限的資源極其受限的嵌入式設(shè)備上。TinyML 開辟了獨特的機會,包括可使用廉價電池甚至小型太陽能電池板供電的應用程序,以及在低成本硬件上本地處理數(shù)據(jù)的大規(guī)模應用程序。當然,TinyML 也帶來了各種挑戰(zhàn)。其中一個挑戰(zhàn)是機器學習和嵌入式系統(tǒng)開發(fā)人員必須優(yōu)化應用程序的性能和占用空間,這需要熟練掌握人工智能和嵌入式系統(tǒng)。
在這樣的背景下,本文介紹了一種在邊緣設(shè)備上設(shè)計和部署深度神經(jīng)網(wǎng)絡(luò)的實用框架。該框架基于 MATLAB 和 Simulink 產(chǎn)品,以及 STMicroelectronics Edge AI 工具,可幫助團隊快速提升深度學習和邊緣部署方面的專業(yè)知識,使他們能夠克服使用 TinyML 時遇到的常見障礙。這反過來又使他們能夠快速構(gòu)建和基準測試概念驗證 TinyML 應用程序。在工作流程的第一步中,團隊使用 MATLAB 構(gòu)建深度學習網(wǎng)絡(luò),使用貝葉斯優(yōu)化調(diào)整超參數(shù),使用知識提煉,并使用修剪和量化壓縮網(wǎng)絡(luò)。最后一步,開發(fā)人員使用集成到 ST Edge AI Developer Cloud—一項免費的在線服務,用于在 STMicroelectronics 32 位 (STM32、Stellar) 微控制器和微處理器(包括配備集成 AI 的傳感器)上開發(fā) AI,以對已部署的深度學習網(wǎng)絡(luò)的資源利用率和推理速度進行基準測試(圖 1)。
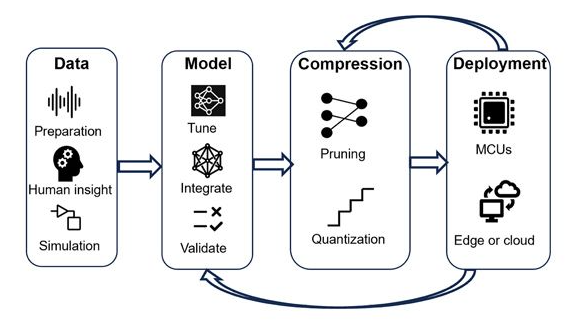
圖 1. 將深度學習網(wǎng)絡(luò)部署到微控制器和邊緣設(shè)備的迭代工作流程。反饋回路有助于形成更精確、更微小的模型。
▼
網(wǎng)絡(luò)設(shè)計、訓練和超參數(shù)優(yōu)化
一旦工程師收集、預處理并準備好用于深度學習應用程序的數(shù)據(jù)集,下一步就是訓練和評估候選模型,其中可以包括預訓練模型,例如 NASNet、SqueezeNet、Inception-v3 和 ResNet-101,或者機器學習工程師使用深度網(wǎng)絡(luò)設(shè)計器(圖 2)。多個模型提供了可用于快速啟動開發(fā)的示例,包括以下示例模型:圖像,視頻,聲音 和激光雷達點云分類;物體檢測;姿勢估計;和波形分割。
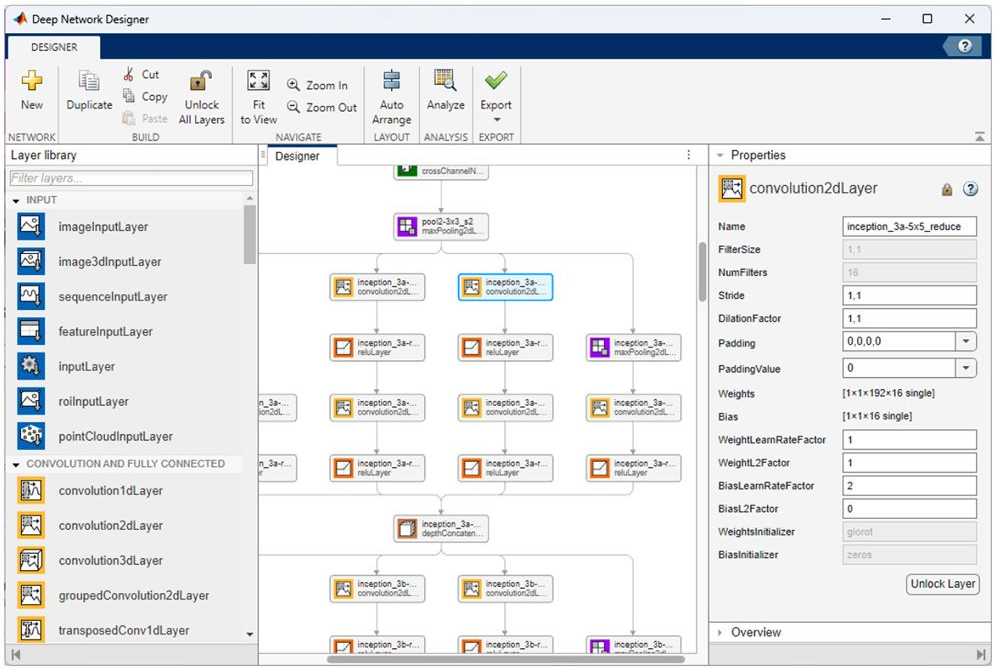
圖 2. 深度網(wǎng)絡(luò)設(shè)計器在設(shè)計器面板中顯示網(wǎng)絡(luò)的多層。
深度學習網(wǎng)絡(luò)的性能在很大程度上取決于控制其訓練的參數(shù)和描述其網(wǎng)絡(luò)架構(gòu)的參數(shù)。這些超參數(shù)示例包括學習率和批量大小,以及層數(shù)、層的類型以及層之間的連接。適當?shù)某瑓?shù)調(diào)整可以使模型實現(xiàn)更高的準確性和更好的性能,即使在 TinyML 應用程序運行的資源受限的環(huán)境中也是如此。然而,選擇和微調(diào)超參數(shù)值以找到優(yōu)化性能的組合可能是一項困難且耗時的任務。
貝葉斯優(yōu)化非常適合分類和回歸深度學習網(wǎng)絡(luò)的超參數(shù)優(yōu)化,因為它可以有效地探索高維超參數(shù)空間以找到最佳或接近最佳的配置。在 MATLAB 中,機器學習開發(fā)人員可以使用 bayesopt 函數(shù)使用貝葉斯優(yōu)化來找到最佳超參數(shù)值。例如,它可以提供一組要評估的超參數(shù)(例如卷積層的數(shù)量、初始學習率、動量和 L2 正則化)以及要最小化的目標函數(shù)(例如驗證誤差)。然后該函數(shù)可以使用 bayesopt 選擇一組或多組超參數(shù)配置,以便在工作流程的下一階段進一步探索。
▼
知識提煉
資源受限的嵌入式設(shè)備可用內(nèi)存有限。知識提煉是一種減少深度學習網(wǎng)絡(luò)占用空間同時保持高精度的方法。該技術(shù)使用更大、更準確的教師網(wǎng)絡(luò)來教更小的學生網(wǎng)絡(luò)進行預測。關(guān)鍵在于師生網(wǎng)絡(luò)架構(gòu)中的損失函數(shù)的選擇。
在前面的步驟中訓練的網(wǎng)絡(luò)可以用作教師模型。學生網(wǎng)絡(luò)是教師模型的較小但相似的版本。通常,學生模型包含較少的 convolution-batchnorm-ReLU 模塊。為了考慮降維,在學生網(wǎng)絡(luò)中添加了最大池化層或全局平均池化層。與教師網(wǎng)絡(luò)相比,這些修改顯著減少了可學習內(nèi)容的數(shù)量。
必須定義知識提煉損失函數(shù)來訓練學生網(wǎng)絡(luò)。它由學生網(wǎng)絡(luò)、教師網(wǎng)絡(luò)的輸入、具有對應目標的輸入數(shù)據(jù)和溫度超參數(shù)確定。從經(jīng)驗上講,損失函數(shù)由以下兩項的加權(quán)平均值組成:1)硬損失,即學生網(wǎng)絡(luò)輸出與真實標簽之間的交叉熵損失;2)軟損失,即學生網(wǎng)絡(luò)日志與教師網(wǎng)絡(luò)日志之間帶溫度的 SoftMax 的交叉熵損失。
訓練后的學生網(wǎng)絡(luò)更好地保留了教師網(wǎng)絡(luò)的準確性,并減少了可學習參數(shù),使其更適合部署到嵌入式設(shè)備中。
▼
模型壓縮與優(yōu)化
訓練階段的有效設(shè)計和超參數(shù)優(yōu)化是必不可少的第一步;然而,這還不足以確保在邊緣設(shè)備上的部署。因此,通過模型修剪和量化進行訓練后優(yōu)化對于進一步減少深度神經(jīng)網(wǎng)絡(luò)的內(nèi)存占用和計算要求非常重要。
網(wǎng)絡(luò)壓縮最有效的方法之一是量化。這是因為沒有大容量傳感器輸出浮點表示,所以數(shù)據(jù)是以整數(shù)精度獲取的。通過量化,目標是通過減少存儲網(wǎng)絡(luò)參數(shù)所需的內(nèi)存占用,并通過用更少的位數(shù)表示模型的權(quán)重和激活來提高計算速度。例如,這可能涉及用 8 位整數(shù)替換 32 位浮點數(shù)——同樣,當可能這樣做時,僅接受預測準確度的輕微下降。量化可以節(jié)約使用嵌入式內(nèi)存,這對于邊緣資源受限的傳感器、微控制器和微處理器(圖 3)至關(guān)重要。此外,整數(shù)運算在硬件上通常比浮點運算更快,從而提高微控制器的推理性能。這使得模型消耗的電量更少,使其更適合部署在電池供電或能源受限的設(shè)備上,例如移動電話和物聯(lián)網(wǎng)設(shè)備。雖然訓練后量化可能會引入一些精度損失,MATLAB 中的量化工具旨在最大限度地減少對模型精度的影響。采用微調(diào)、校準等技術(shù)來保持量化模型的性能。在 MATLAB 中,dlquantizer 函數(shù)簡化了將深度神經(jīng)網(wǎng)絡(luò)的權(quán)重、偏差和激活量化為 8 位整數(shù)值的過程。
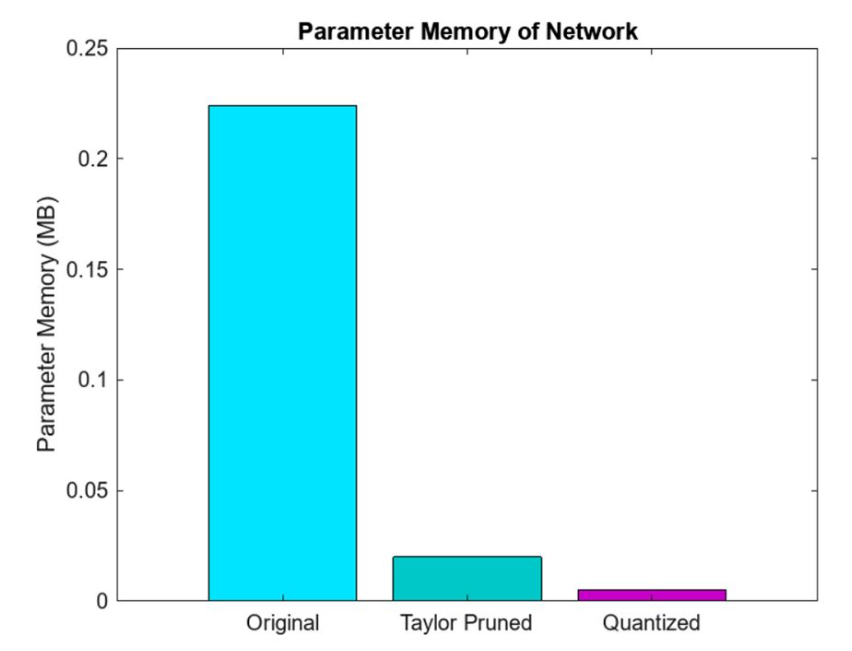
圖 3. MATLAB修剪和量化后深度神經(jīng)網(wǎng)絡(luò)的內(nèi)存占用。
相比之下,修剪技術(shù)側(cè)重于通過最小化操作冗余來降低網(wǎng)絡(luò)的復雜性。這對于大幅降低計算復雜性至關(guān)重要。其目的是識別并刪除那些對網(wǎng)絡(luò)預測影響不大的連接、權(quán)重、過濾器甚至整個層。投影是 MATLAB 的專有技術(shù),用于通過有選擇地刪除不太重要的權(quán)重或連接來優(yōu)化神經(jīng)網(wǎng)絡(luò)。此過程降低了模型的復雜性,從而減小了模型尺寸并加快了推理時間,同時又不會顯著影響性能。雖然常規(guī)修剪通常涉及直接基于閾值去除低幅度權(quán)重,但投影可能采用更復雜的標準和方法來確保網(wǎng)絡(luò)的基本特征得到保留。此外,投影通常旨在維持權(quán)重空間的幾何特性,與傳統(tǒng)修剪方法相比,可能產(chǎn)生更高效、更穩(wěn)健的模型。
▼
ST Edge AI Developer Cloud 基準測試
在 MATLAB 中完成初始網(wǎng)絡(luò)設(shè)計、超參數(shù)優(yōu)化、提煉和壓縮后,工作流程的下一步是在微控制器或微處理器上評估該設(shè)計的性能。具體來說,工程師需要評估網(wǎng)絡(luò)的閃存和 RAM 要求以及推理速度等因素。
ST Edge AI Developer Cloud 旨在通過對 ST Edge 設(shè)備上的網(wǎng)絡(luò)進行快速基準測試來簡化工作流程的這一階段。要將此服務用于在 MATLAB 中開發(fā)的 TinyML 應用程序,您首先需將網(wǎng)絡(luò)導出為 ONNX 格式。將生成的 ONNX 文件上傳到 ST Edge AI Developer Cloud 后,工程師可以選擇要在其上運行基準測試的 ST 設(shè)備(圖 4)。
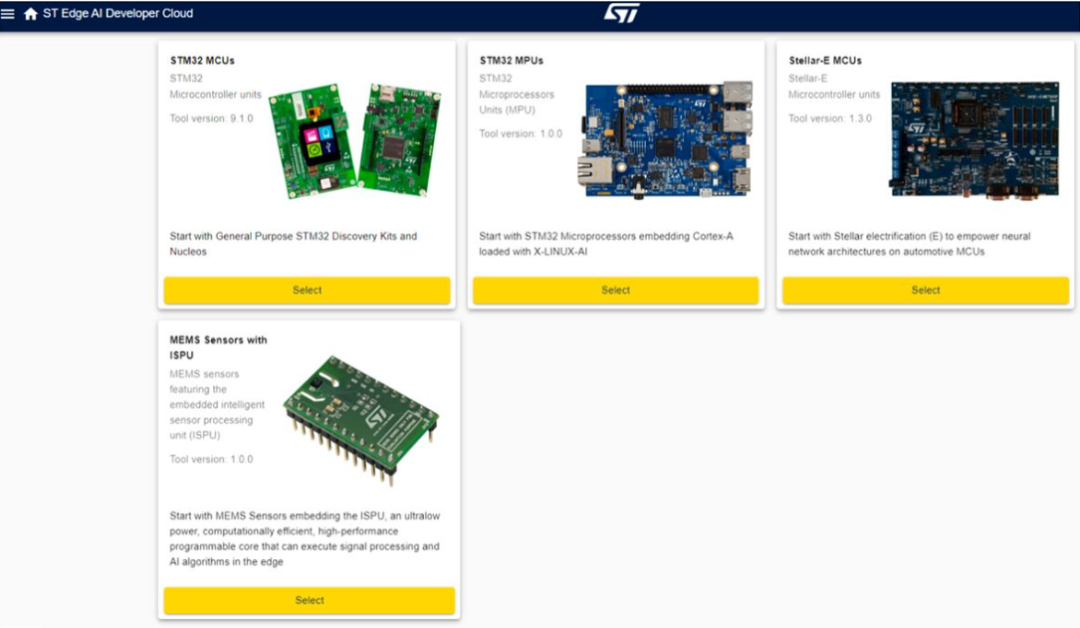
圖 4. 可在 ST Edge AI Developer Cloud 用戶界面中進行基準測試的設(shè)備。
基準測試完成后,ST Edge AI Developer Cloud 會提供一份詳細說明結(jié)果的報告(圖 5)。ST Edge AI Developer Cloud 提供的性能分析工具提供了各種詳細的見解,包括內(nèi)存使用情況、處理速度、資源利用率和模型準確性。開發(fā)人員會收到有關(guān) RAM 和閃存消耗的信息,以及模型不同層和組件的內(nèi)存分配細目。此外,這些工具還提供每一層的執(zhí)行時間和總體推理時間,以及詳細的時序分析以識別和優(yōu)化緩慢的操作。資源利用率統(tǒng)計數(shù)據(jù)(包括 CPU 和硬件加速器使用情況以及功耗指標)有助于優(yōu)化能源效率。
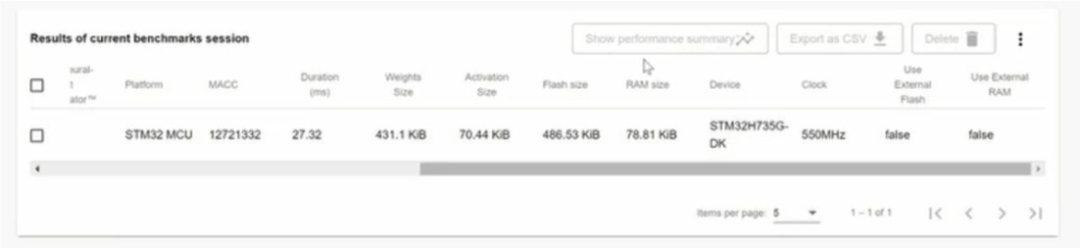
圖 5. ST Edge AI Developer Cloud 中典型基準測試會話的結(jié)果。
通過審查基準測試結(jié)果,工程師可以確定下一步的最佳行動方案。如果網(wǎng)絡(luò)設(shè)計能夠輕松地適應具有較低推理時間的給定邊緣設(shè)備的約束,他們可能會探索使用更小的設(shè)備或使用更大、更復雜的網(wǎng)絡(luò)來提高預測準確性的機會。另一方面,如果網(wǎng)絡(luò)設(shè)計太大,由于使用外部 Flash 或 RAM 而導致推理時間變慢,那么團隊可能會尋找具有更多嵌入式 Flash 和 RAM 的計算能力更強大的設(shè)備,或者他們可能會使用 MATLAB 執(zhí)行額外的超參數(shù)優(yōu)化、知識提煉、修剪和量化迭代以進一步壓縮網(wǎng)絡(luò)。ST Edge AI Developer Cloud 還提供自動代碼生成,以簡化在 ST 設(shè)備上部署 AI 模型。該功能將訓練有素的 AI 模型轉(zhuǎn)換為與 STMicroelectronics 的傳感器、微控制器和微處理器兼容的優(yōu)化 C 代碼。
▼
從基準測試到部署
工作流程的最后一步是部署到傳感器、微控制器或微處理器。有了基準測試結(jié)果,工程師們就可以做出明智的決定,選擇一個平臺,比如 STM32 Discovery Kit,在真實硬件上評估他們的 TinyML 應用程序。根據(jù)應用情況,他們可能需要將深度神經(jīng)網(wǎng)絡(luò)與其他組件(例如控制器)集成,并在部署之前將其合并到更大的系統(tǒng)中。對于這些用例,他們可以進一步擴展工作流程,在 Simulink 中對其他組件進行建模,運行系統(tǒng)級仿真以驗證設(shè)計,并使用 Embedded Coder 和 Embedded Coder Support Package for STMicroelectronics STM32 Processors 生成 C/C++ 代碼以部署到 STM32 設(shè)備。
◆ ◆ ◆ ◆
-
matlab
+關(guān)注
關(guān)注
185文章
2974瀏覽量
230382 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100713 -
機器學習
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132561
原文標題:MathWorks × STMicroelectronics | 在邊緣設(shè)備上快速部署深度學習
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
卷積神經(jīng)網(wǎng)絡(luò)的層級結(jié)構(gòu)和常用框架
基于深度神經(jīng)網(wǎng)絡(luò)的激光雷達物體識別系統(tǒng)及其嵌入式平臺部署
深度神經(jīng)網(wǎng)絡(luò)是什么
可分離卷積神經(jīng)網(wǎng)絡(luò)在 Cortex-M 處理器上實現(xiàn)關(guān)鍵詞識別
如何使用stm32cube.ai部署神經(jīng)網(wǎng)絡(luò)?
輕量化神經(jīng)網(wǎng)絡(luò)的相關(guān)資料下載
基于深度神經(jīng)網(wǎng)絡(luò)的激光雷達物體識別系統(tǒng)
卷積神經(jīng)網(wǎng)絡(luò)一維卷積的處理過程
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應用
如何使用TensorFlow將神經(jīng)網(wǎng)絡(luò)模型部署到移動或嵌入式設(shè)備上
基于虛擬化的多GPU深度神經(jīng)網(wǎng)絡(luò)訓練框架
深度神經(jīng)網(wǎng)絡(luò)在識別物體上的能力怎樣
在Arduino Nano BLE Sense 33邊緣設(shè)備上訓練神經(jīng)網(wǎng)絡(luò)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論