 LeCun親授的深度學習入門課:從飛行器的發明到卷積神經網絡
LeCun親授的深度學習入門課:從飛行器的發明到卷積神經網絡
前言
深度學習和人腦有什么關系?計算機是如何識別各種物體的?我們怎樣構建人工大腦?這是深度學習入門者繞不過的幾個問題。很幸運,這里有位大牛很樂意為你講解。LeCun從鳥類對飛行器發明的影響開始講起,層層遞進、逐步深入到深度學習的本質,可以說非常新手友好了。機不可失,還不來圍觀這堂由大神親自授課的深度學習入門指南?
講座的主要內容:
今天來,給大家簡單介紹一下深度學習。但我們不從AI開始講起,而是從人類發明飛行器開始講。
依照達芬奇飛行器草圖做的第一款飛行器,完全照搬了鳥類的外形。那時候根本不知道飛行底層的原理,所以只能從自然界的生物獲得靈感,照葫蘆畫瓢。
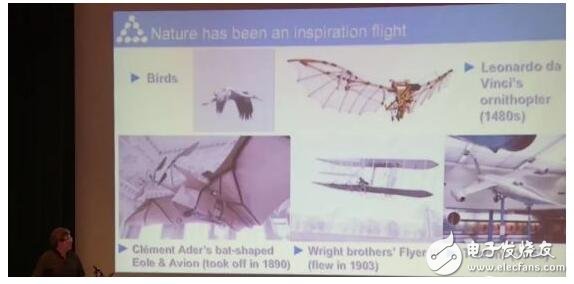
第一次飛行,只成功離地15公分,還是20公分的樣子,飛行器就掛了。所以我們還是需要更系統的方法,就是后來萊特兄弟造飛行器用到的一套方法,飛行終于成為了現實。
一般來說,理論認知都是在實踐積累之后才有的。
飛行就說這么多。
那么問題來了。
人工智能可以從大自然里獲得靈感嗎?
很明顯,這個想法很舊啦。我們先看一下生物界的智能體。
人類的大腦,差不多有850億個神經元。而每個神經元都有上萬個突觸,在一千到十萬個之間不等。人腦相當高效,能耗才25瓦特,是PC的十分之一。
每個有大腦的動物都能學習,不同動物的學習方式可能不同,有些比較簡單。它們并不需要特別好的視覺,或者其他智能體的教導,就能自己去學。
我們嘗試找出動物學習的機制,然后用來訓練機器學習。

慢慢地,從1940年起,就有了打造智能機器的想法。于是就冒出來了感知機(Perceptron)。
它不是一臺計算機,而是一個計算機模擬器。輸入值是電壓,超過某個閾值,就打開。低于閾值,就關閉。而權重是可以被訓練的,就像一個可旋轉調節的鈕。
盡管現在我們可以用三行Python代碼實現它,但在那年代已經算是大型的計算機了。
這個感知機是怎么運轉起來的呢?
原理是很簡單的,你需要先集齊一堆訓練數據。
比如說任務是圖像識別,那么輸入就是圖像的一個個像素。當每個像素用0,1表示時,那么就可以組成一串數字。
你給機器一張圖,字母A,然后輸出應該是1。那么訓練的時候,就讀取圖像中的像素,調高那些能增強最終結果是1,也就是判定字母是A的像素的權重,并調低偏離最終結果的像素的權重。

數學上只需要一行Python代碼就可以搞定。
事實上,雖然這個辦法是直覺上想出來的,但后來幾年發現這個問題可以總結成幾個方程,也是受到了生物學的啟發。
我們回到人的大腦是怎么學習的。
每個神經元是通過突觸來連接其他神經元,從而傳遞信號。
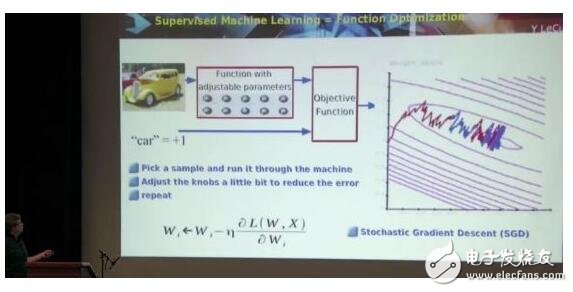
但數學上,這個概念被簡化了,將感知機里的權重看成一個個的旋鈕。
對于具體的輸入,根據輸出的錯誤再調參數,訓練,重復,直到目標函數的值越來越小(目標函數的值,表示的是你得到的輸出和你想要的輸出的差值)。
這叫做梯度下降(gradient descent),依然是很簡單的數學問題。
舉個稍微復雜一點的例子,我們要做一個圖片分類器,辨識汽車、飛機、椅子等物體。

它們的外觀千變萬化,我們怎樣讓計算機認出每一類物體呢?
這需要依賴大量的手動調整。給系統一張車的照片,如果系統將它認成車,紅燈亮起。如果紅燈不亮,就調整這些按鈕,讓紅燈的亮度增強;輸入飛機的圖片,調整按鈕,讓綠燈亮度增強。
輸入足夠多的訓練數據不停調整按鈕,直到機器能夠辨認出來它從來沒見過的相片為止,那么就算訓練成功了。
你們肯定會問,這個能識別圖像的神秘盒子里到底裝了什么?
這個答案,在過去的幾十年里,一直在變。
傳統的模式識別,是給它一張圖,然后過一個特征提取器。這個特征提取器是人工搭建的,把這些圖像的像素變成一串數字,然后用簡單的算法吸收消化,得到這張圖的內容。這種方法在深度學習出現以前一直都在用。
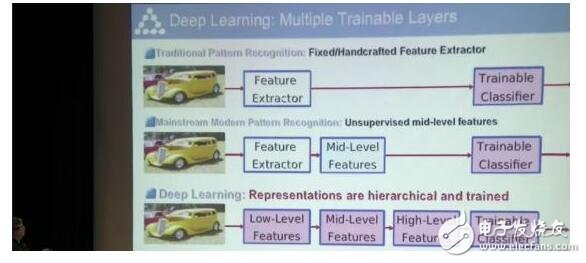
而深度學習是把模塊分成可以被訓練的好幾層。就像視覺信號的傳遞一樣,需要多步來提取信息。
下一個我們要問的問題是,我們應該往這些可訓練的模塊箱里放什么東西?
“多層”的概念是50年代提出的,到80年代時用的人稍微多了起來。

每一層都是由簡單的單元組成,而單元又是基于上一層的輸入,經過不同程度的權重處理得到的。然后如果值超過閾值,就繼續往下走,低于閾值就不取。
那么,我們要如何訓練機器呢?
這其實是不斷調小偏差的過程。問題的關鍵在于往什么方向調整參數、調整到什么程度,才可以拿到我們想要的輸出。
1980年,這個問題才有了解決方案。
這個方案是一個復雜的數學概念的實際應用, 叫鏈式法則(Chain rule)。
當你有一個網絡的時候, 你有的是連續的功能區塊(Functional block)。
每一個區塊或者做矩陣乘法,或者是給每個輸入做一個非線性的運算。我們來看看系統之中分離出來的一個區塊。

你可以簡單地算出來輸出值。比如說這是一個線性的矩陣乘法模塊,參數乘以向量,這樣你就能拿到輸出的向量。這兩個區塊有不一樣的維度。
現在假設,對于每個向量中任何元素的調整,我們都知道損失會往什么方向變化。
損失函數的斜率,表示的是我們得到的輸出和我們想要輸出的差值。通過計算,可以得出圖中綠色的向量,從上到下計算一個遞歸公式,通過反向傳播,就能得到cost和所有模塊相關的梯度。
很多現在的平臺,在你寫程序定義網絡后,都可以自動運行反向傳播,計算梯度。
這些問題都解決了之后呢,我們就可以建一個人工的大腦了嗎?
要知道,人腦每秒可以做10的17次方的運算,神經元數量達到10的11次方。
我們來看一款運算速度很快的芯片。右下角的英偉達Titan-V,這個GPU每秒可做10的15次方運算,比人腦要慢100倍。

所以大家算算,即使芯片的速度翻一倍要18個月的話,那還要多長時間能達到和我們人腦一樣?如果要讓芯片在合理的大小范圍的話,我認為我們還要等多幾十年。
但這個不是主要問題。主要問題是我們不知道怎么編程它們、怎么訓練它們、訓練原則是什么。
這個GPU很便宜,才3000刀,但是現在大家都在買來挖礦,所以已經買不到了。
我說過很多次了,如果在我職業生涯中,能夠造一個智能體,像大鼠一樣具有常識,我會感到很開心很滿足。我們現在也許有相應的算力了,但我們還沒有搞清楚潛在原則。現在是這個底層原理限制住了。
好啦,現在我們來跳出來看看生物還有沒有給我們別的啟發。
Hubel & Wiesel 1962這個生物研究工作太有名了,大家都知道的,是70年代拿了諾貝爾獎的。工作本身是在60年代做的,是視覺信號傳遞的生理結構。
簡單的細胞檢測位置信息,復雜的細胞整合簡單細胞受到刺激的信息。
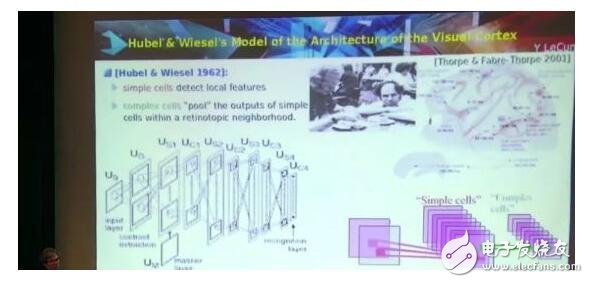
所以,如果有一個特殊的動機,稍微移動一點,復雜細胞都會被激活。
Fukushima 1982年造了一個計算模型,就是描述簡單細胞和復雜細胞之間的層級關系。這個是80年代的工作,那時候還沒有合適的學習算法。所以用了其他的非監督型算法。
后來,我受到這個算法啟發,造了一個含有相似構造的網絡,用反向傳播算法來訓練,就是我們平時說的卷積神經網絡(CNN)。
下面是卷積神經網絡的示意圖。
圖像中的像素會激活CNN中的單元。但我不敢稱他們為神經元,不然神經科學家會不爽。因為比起神經元來說,這些單元實在是太簡單了。

每個單元,看起來像patch。這些單元會和閾值比,比他們高,就打開。低的話就關上。
可以看到這個用激光筆指出的patch是系數。
左邊這個是輸入patch,把系數向量和輸入向量乘在一起。用系數把整個輸入刷一遍,然后你記錄就能得到右邊的結果。
如果它們能夠匹配的話,就得到高度激活的結果,不匹配就得到非激活的結果。
這在數學上就叫做離散型卷積。
經過了層層卷積核的系數處理,最后得到的是最右邊的壓縮過的信息。
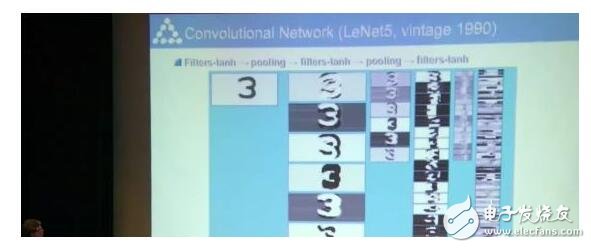
我們90年代中期的時候弄了一個很牛的模型。不僅能夠認出來一個字母,還能認出多個字母,還不用先分割開。當時如果用經典數學算法就必須先分割。
等到無法從圖像中分割出物體時,我們模型的重要性就顯現出來了。
這個模型中每一層都是卷積的,同時進行分割和識別。
這是那個時候年輕的我,把一張紙條放在一個攝像頭下面,然后按一下鍵盤。這是1993年的時候(嘴上說的是1992年)。
這是我在新澤西的時候貝爾實驗室那會兒的電話號碼,現在已經不用了。

在幾秒鐘之內,就可以處理圖像,識別出數字。
訓練數據量不用很多,哪怕是很小的、不同的手寫體,都能識別成這樣,效果很不錯了。
為了以合適的速度跑起來這個程序,我們用了特殊的硬件DSP 32C,速度可到 20 FLOPS。最后,我們用這個造了一個可以識別支票的系統。于1996年左右開始鋪開使用。
到90年代末,這套系統已經在處理10%到20%左右的支票了。如果你夠老的話,也許你的支票被這套系統讀取過。
這么看,這套系統還是挺成功的。可惜在90年代中期,在機器學習圈里,大家對神經網絡的熱情消失了。
很大一個原因是,這套系統需要大量的計算力投入才軟件系統里。這樣才有可能跑起來。
這一切都發生在MATLAB、微軟系統、Linux出現之前,AT&T都還沒公開相應的硬件資源。沒有大型計算機,或大型數據集,大家做這個都只能靠直覺。
其實在那個時候,很多東西都很玄學,我們并不能從數學的角度去解釋他們。
不能解釋背后的原理的話,就沒辦法形成一套理論。沒有理論就很混亂,都發不了文章。
哪怕事實上,這些方法是可用的,但是也被拋棄了。
不過我們當中的某些人,知道,這方法最終還是會回來的。因為在某些情況下,這套方法是更好的。
因為它們會自己學習,不僅僅是識別圖像,還能夠抽象地表示這個世界。它們能夠找到事物的本質,然后找到不同部分之間的聯系,然后組裝成以個整體。它們做的事情很強大,所以也需要更多的數據。
在1996年和2002年之間,我幾乎停止了這方面的研究,改做圖像壓縮。
2003年的時候我又開始搞回這個了。我們做了一輛有兩個攝像頭小車,讓人來控制它,當距離障礙物2米的時候,我們會控制它向左轉或向右轉來避開障礙物。然后,我們訓練一個CNN來看兩個攝像頭采到的畫面,去預測方向盤轉向的角度。

只需要20分鐘的訓練數據,這個CNN就可以自己開車了!遇到障礙物的時候,它會自行轉向避開。
在這套系統的啟發下,DARPA舉辦了LAGR(Learning Applied to Ground Vehicles),一個150萬美元的項目。

你可以看到這個機器人有四個攝像頭,內部裝了三臺計算機,可以在自然環境中自動行駛。我們訓練了一個CNN,讓它告訴我們在畫面上,哪些區域是可以順利通過的。
使用傳統的立體視覺成像技術,也能實現這個功能。但是,立體成像很貴,工作范圍也很有限,大概能做到10米的距離。
這就是CNN的一種用途。
很快我們就意識到,不能只是標記一個區域能不能通過,更有意思的是,看圖中的某些像素屬于哪個物體。(物體識別分類)。
舉個例子來說,這些是天,樹,窗,路等等。

這是有人騎著自行車上路拍到的第一人稱視角畫面,這個算法不能說完美,它認為這里是沙漠,實際上在曼哈頓不可能有沙漠。
不過,它識別行人等主要目標的能力都不錯,而且即使在普通電腦上跑,也比當時最領先的系統快100倍。這個算法讓很多人產生了靈感,認為我們能把它用到無人駕駛上。
2014年,有兩個公司很快就把這個技術拿過去用了。一個是MobilEye,另一個是Nvidia。

2010年之前,這些研究都在低調地進行著,后來,事情有了變化。
2011年的時候,深度學習在語音識別上有了重大的進展。
在2012年年底,深度學習在ImageNet比賽上一舉成名。ImageNet數據集包含1000類物體的130萬張照片,傳統圖像分類算法在這個數據集上取得的最低錯誤率大約是26%。
2012年,一個多倫多大學做出來的大型CNN,將錯誤率降到了15%。他們是第一個正式用GPU跑這么大的CNN的團隊。
于是,突然之間,整個計算機視覺領域都開始使用這項技術。我從來沒見過一個研究領域如此快速地從一種技術轉向另一種。
其實就在2011年,我們還提交了一篇論文到CVPR。這篇論文打敗了當時最好的記錄,但是卻被拒了。因為那個時候人們都不相信CNN能取得這么好的成績。因為大家沒見過,于是,他們就主觀臆斷地認為我們犯規了之類的。
但是3年之后,世道完全反過來了。你不用CNN,文章都不可能被接收。
不過這也不是一件好事。因為這樣會滅殺多樣性。講這件事是想讓大家知道,這在當時是一個多么重大的革命。
這些網絡都特別大,有上百萬個按鈕、單元和權重。網絡的第一層檢測的都是一些基本motif,比如邊緣、線條等等。
有的CNN多達50層,甚至更多。為什么我們需要這么多層?

神經網絡的多層架構對應著數據的組成型結構,不同層檢測不同的特征,比如線條、邊緣等底層特征,圓圈、弧線、角等中層特征,更接近圖形的高層特征。
這個世界的所有事物呈現都是分層的。比如文本,就是從字母,字,詞,從句,句子,段落組成的。
愛因斯坦曾經說過,這個世界最不可思議的事,是所有東西都是可以被理解的。
世界上最令人費解的事情是,世界是可以理解的。
過去幾年大量的公司做了很多努力,讓這些技術落地,并規模化。
開始列舉最近各種研究進展
比如說,我們現在用256個CNN,1小時就能完成在整個ImageNet上的訓練,錯誤率達到23.74。
計算機視覺的最前沿研究Mask R-CNN,可以做物體分割,關鍵點檢測,人體姿態捕捉等等。用Sparse ConvNet還可以做3D語義分割——

另外,CNN還能用在和視覺沒什么關系的領域,比如做翻譯。這對于Facebook來說很有用,幫助用戶翻譯短篇的文章。
今天分享提到的很多資料,都是開源的。
卷積神經網絡可以應用在很多領域,比如在無人駕駛上,可以幫機器用視覺感知環境。在醫學影像、基因學、物理學等等各種領域都有應用,而且幾乎每天都有新的落地領域出現。
深度學習不僅能感知,還能推理。
比如說,我們可以根據一張圖片,提出問題,
下圖中方塊的數量比黃色的物體多嗎?
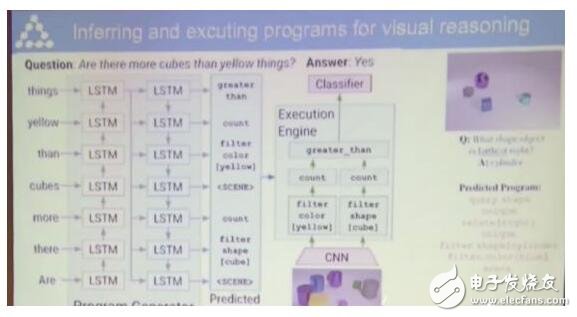
如果是人類來回答這個問題,需要分別數一數方塊和黃色物體的數量,然后比較這兩個數量的大小。
對于神經網絡來說,就需要一個模塊來分類出方塊和黃色物體,另一個模塊來數數,還需要一個模塊比較大小給出答案。
這個神經網絡是動態的會隨著輸入的變化而變化,輸入會決定神經網絡的架構。
另外,用記憶模塊來增強神經網絡也是一個很有意思的研究方向。
在講座中,立昆老師又提到了他最近推崇的可微分編程。感興趣的同學可以閱讀之前的文章,以及自行看視頻。
最后,立昆老師還強調了一點:目前,機器并沒有通用的智能,也沒有嘗常識。

未來智能實驗室是人工智能學家與科學院相關機構聯合成立的人工智能,互聯網和腦科學交叉研究機構。由互聯網進化論作者,計算機博士劉鋒與中國科學院虛擬經濟與數據科學研究中心石勇、劉穎教授創建。
未來智能實驗室的主要工作包括:建立AI智能系統智商評測體系,開展世界人工智能智商評測;開展互聯網(城市)云腦研究計劃,構建互聯網(城市)云腦技術和企業圖譜,為提升企業,行業與城市的智能水平服務。
-
深度學習
+關注
關注
73文章
5500瀏覽量
121118
原文標題:LeCun親授的深度學習入門課:從飛行器的發明到卷積神經網絡
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
卷積神經網絡的基本概念、原理及特點
循環神經網絡和卷積神經網絡的區別
卷積神經網絡的實現原理
卷積神經網絡的基本結構和工作原理
cnn卷積神經網絡分類有哪些
卷積神經網絡訓練的是什么
深度學習與卷積神經網絡的應用
卷積神經網絡的原理與實現
卷積神經網絡的基本結構及其功能
卷積神經網絡的原理是什么

詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論