") 基于 Flexus 云服務(wù)器 X 實例體驗大模型部署體驗測評
基于 Flexus 云服務(wù)器 X 實例體驗大模型部署體驗測評
前言
當(dāng)下,各種大模型層出不窮,先有 openai 的 chatgpt,后有百度文心一言,再就是國內(nèi)大模型齊頭并進的搶先發(fā)布。
讓普通的開發(fā)者不必為不能體驗 chatgpt 而擔(dān)憂,國內(nèi)的大模型速度也很快。但是大家目前都是在體驗,能不能部署一下試試呢?
今天,我們就以華為云 Flexus 云服務(wù)器 X 實例來部署一下,順便測測其性能看看。
在華為云 828 B2B 企業(yè)節(jié)狂潮中,F(xiàn)lexus X 實例的限時大促銷震撼來襲,絕對是你不容錯過的超級福利!對于那些追求極致算力、對自建 MySQL、Redis、Nginx 性能有著苛刻要求的技術(shù)極客們,這次活動無疑是你們的專屬盛宴!趕緊抓住這個千載難逢的機會,讓業(yè)務(wù)效能飛躍升級!!!
注意:本文為高端局,對于還不知道怎么使用 shell 工具,不知道云服務(wù)器為何物?不知道大模型為何物的讀者可以退出啦,本文不太適合
部署千問大模型
之前一直就想搞個大模型玩玩了,奈何電腦配置不打夠,所以只能是可望而不可及,今天,就單獨用這款華為云 Flexus 云服務(wù)器 X 實例來試試。
本文我們基于 Ollama 部署和運行大模型,那么,何為 Ollama?
不過官網(wǎng)上都是洋文,看著比較吃力。我搜了些資料,給大家現(xiàn)個丑:
Ollama 是一個強大的框架,設(shè)計用于在 Docker 容器中部署 LLM。Ollama 的主要功能是在 Docker 容器內(nèi)部署和管理 LLM 的促進者,它使該過程變得非常簡單。它幫助用戶快速在本地運行大模型,通過簡單的安裝指令,可以讓用戶執(zhí)行一條命令就在本地運行開源大型語言模型,例如 Llama 2。
下面,我們來開始實操!

我們可以直接從瀏覽器中輸入,然后會自動下載,當(dāng)然,我們也可以直接從 shell 工具中下載,不過就是有點慢,他這個東西還很大。

等待的過程挺漫長,可以先去找點別的事兒去做。
接著等待....
終于在漫長的等待過程中,我們將 ollama 下載下來了啦,下面我們就可以開始體驗了!!!
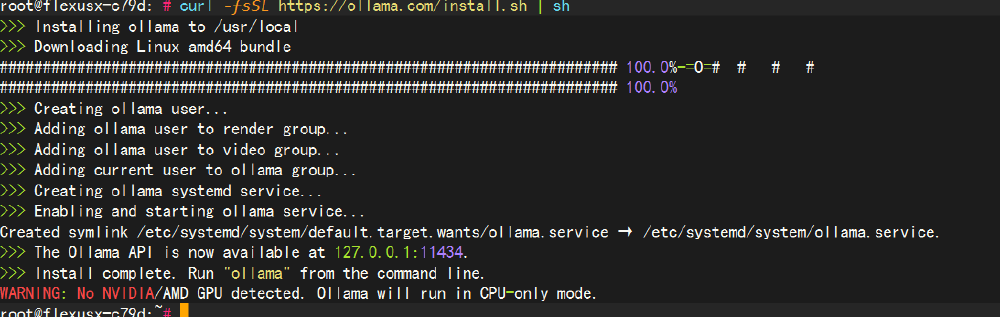
1.啟動 ollama 的服務(wù)
當(dāng)我們服務(wù)器中有了 ollama 的服務(wù)后,我們需要啟動他!命令如下:
systemctl start ollama.service
然后我們在執(zhí)行一下下面的命令,看看服務(wù)是否已經(jīng)啟動:
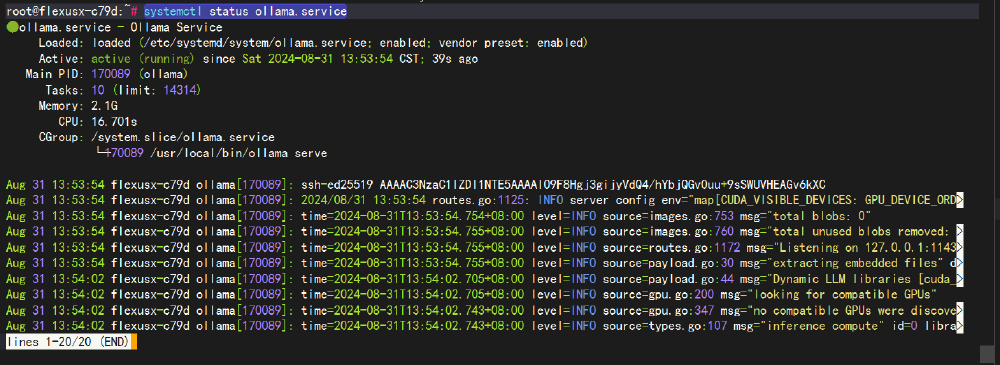
systemctl status ollama.service
3. 設(shè)置服務(wù)開機自啟動:
sudo systemctl enable ollama
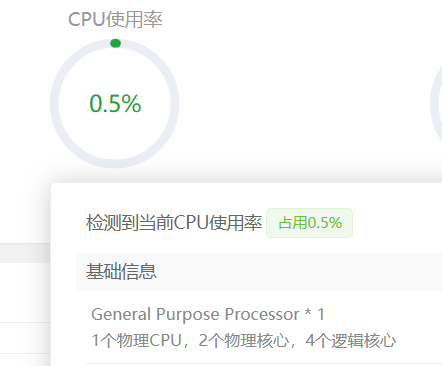
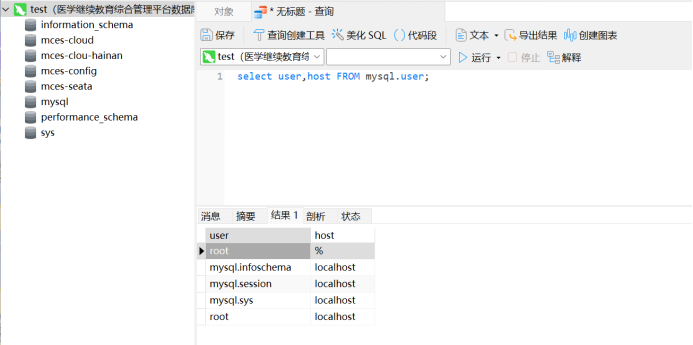
1.查看內(nèi)存占用情況。
兩個方法都可以查看,第一是從寶塔面板中查看,第二就是直接輸入命令:
free -h

大家可以看的出來,used 這一列,表示的是已使用,目前來看,并不多。
1.運行大模型
我們先來看看 ollama 支持的大模型有哪些?
我們先跑個小點的千問大模型吧,千問 0.5B 的模型看看。
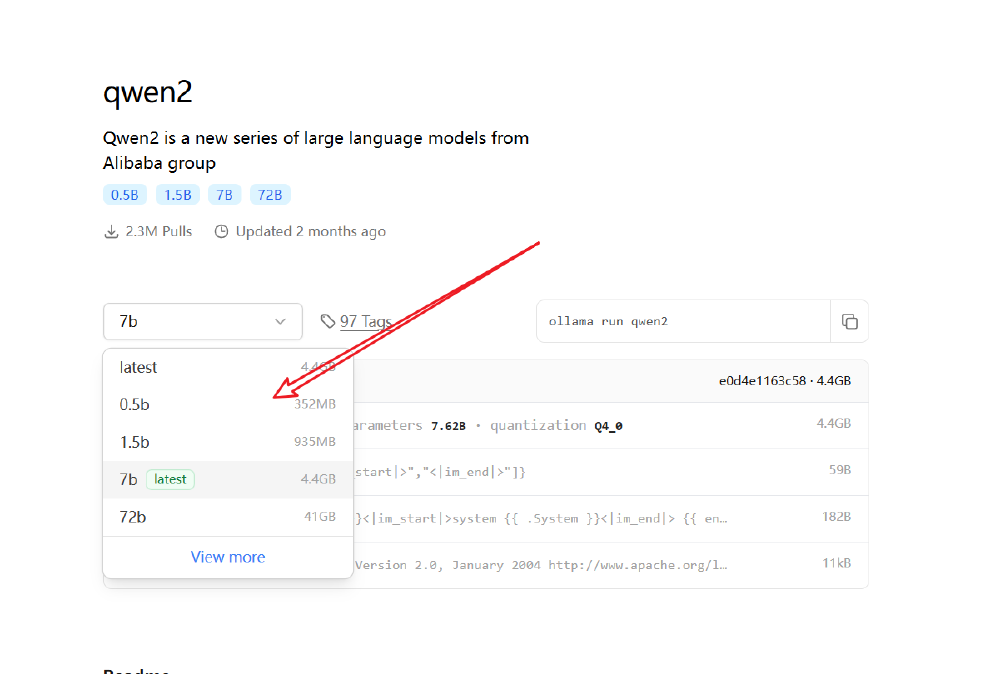
輸入命令:
ollama run qwen2:0.5b

還是繼續(xù)等待....等待的過程中,為了不浪費時間,可以看看別的事兒。

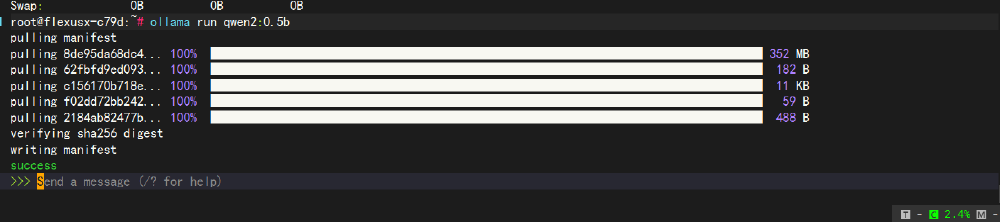
等待完成,下面我們就可以看到:Send a message 這句話了,表示我們可以直接使用大模型提問啦
1.體驗大模型
我們輸入個問題試試看看:
[MISSING IMAGE: , ]不知道為啥,他非要說自己是李政保,還說的有鼻子有眼的,質(zhì)量的問題我們不管,我們看性能和速度問題。
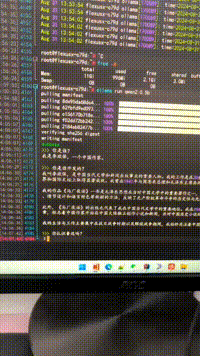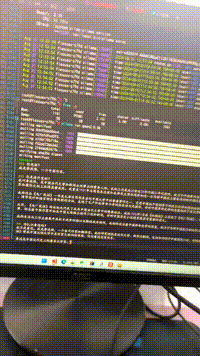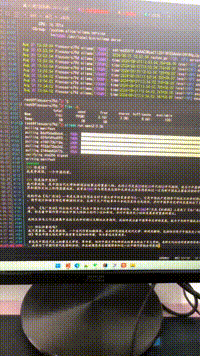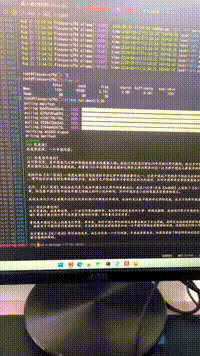
簡單的錄了個小視頻,這速度還是很快的。可見這服務(wù)器的性能還是不錯的,感興趣的伙伴們,可以嘗試跑跑更大的模型試試。
總體來說,這次活動的力度還是蠻大的,主要是服務(wù)器性能也確實可以,不用 GPU 也可以跑大模型了,本文就是我們單純的用 CPU 就行跑的,體驗很好。
至此,本文 over。
審核編輯 黃宇
-
云服務(wù)器
+關(guān)注
關(guān)注
0文章
580瀏覽量
13362 -
華為云
+關(guān)注
關(guān)注
3文章
2468瀏覽量
17414 -
大模型
+關(guān)注
關(guān)注
2文章
2439瀏覽量
2672
發(fā)布評論請先 登錄
相關(guān)推薦
華為云 Flexus X 實例云服務(wù)器詳細操作教程
華為云 Flexus X 實例 MySQL 性能加速評測及對比

基于華為云 Flexus 云服務(wù)器 X 實例搭建 Linux 學(xué)習(xí)環(huán)境
華為云 Flexus X 實例 docker 部署 Jitsi 構(gòu)建屬于自己的音視頻會議系統(tǒng)
采用 Flexus 云服務(wù)器 X 實例搭建 RTSP 直播服務(wù)器
基于 Flexus X 實例云服務(wù)器的評測 - 大模型對比評測
華為 Flexus 云服務(wù)器 X 實例 使用流程
基于 Flexus X 實例云服務(wù)器的實際場景 - 等保三級服務(wù)器設(shè)置
如何選擇合適的云服務(wù)器 --X 實例購買指南和配置詳細說明
Flexus X 實例 ultralytics 模型 yolov10 深度學(xué)習(xí) AI 部署與應(yīng)用

云服務(wù)器 Flexus X 實例 MySQL 應(yīng)用加速測試
重塑云服務(wù),華為云 Flexus X 實例破解云服務(wù)傳統(tǒng)難題

華為云 Flexus 云服務(wù)器 X 實例以黑科技驅(qū)動,開辟高性能低成本云服務(wù)新路徑





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論