 大模型,在內卷中尋找出口
大模型,在內卷中尋找出口

2024年,大模型進展不斷。從年初的Sora到最新的o3,更新更好的模型不斷被推出,“內卷”到底有沒有發生?
我們要先確定“內卷”的定義,指某一類產業模式,發展到一種確定形式后,陷入“高水平均衡陷阱”,出現“沒有發展的增長”,這種局面一直無法被打破,那就會走向停滯和危機。
而這一年,大模型的scaling law法則越來越受到挑戰,訓練模型的算力集群已經從萬卡發展到十萬卡,擴大了十倍,而模型的智商并沒有以這個倍率提高。應用端也沒有出現killer app(殺手級應用),模型廠商開始了流血換量的價格戰……這些特征與“內卷”的定義是契合的。
那么接下來的問題就是,內卷化讓大模型陷入危機了嗎?以及脫離內卷的出口,究竟在哪里?

在內卷化周期中,一個產業是很難保持活力和創新動力的。大模型內卷化的加劇,也讓行業進入調整期。
首先可以感受到的,就是公眾和投資者的失望。2023年,人們都用“AI一天,人間一年”來形容AI的發展,美股 “七姐妹”(蘋果、微軟、谷歌母公司alphabet、亞馬遜、英偉達、特斯拉、Meta)更是在這一股熱潮下屢創新高。而近來我們明顯看到,這股熱情已經回落。
OpenAI的股東、接入模型API的服務商企業,都公開抱怨過,AI能力沒有太大進展了。剛剛結束的為期12天的OpenAI 發布會,也大多是對已有模型、產品或技術路線的增強,符合預期,但缺乏亮點,無法為AGI提供強支撐。OpenAI前首席科學家Ilya在NeurIPS 2024大會上提出“預訓練將會終結(Pre-training as we know it will end)”,更是給大眾澆了一瓢涼水。
來自產學各界的質疑態度是一個比較危險的信號,因為歷史上的AI寒冬都源于信心缺失和投資退潮。
另一個危機信號,是產品同質化競爭和淘汰賽加劇。
基礎模型的競賽,也在2024變得格外激烈,一是模型數量過密,且性能表現逐漸趨同,尤其是開源模型與閉源模型的差距在快速縮小,進入同質化競爭。
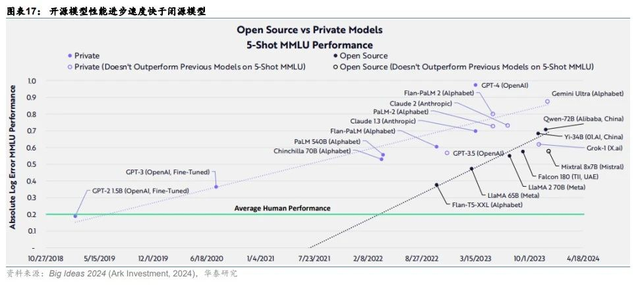
二是同一廠商的模型家族,也在加速淘汰,比如GPT-3.5-Turbo就退役了,由GPT-4o mini取代,國內模廠的模型也基本如此,用戶都愿意用加量不加價、物美價更廉的新模型,舊模型沒人愿意用了。GPT-4o Mini發布后,API 的使用量翻了一番。
激烈的同質化競爭,讓模廠不敢減少訓練新模型的投入,又為了應對價格戰而不得不下調token價格,結果就是經濟負擔越來越重。可以說,目前大模型無論是外部的宏觀形勢,還是企業的微觀經營狀態,都沒有2023年那么積極了。

模型層面,底層技術路線、數據瓶頸等無法在短期內得到有效突破,那么從商業層面尋找出路,就成為必然。
2024年,我們能看到大模型內卷,給商業模式帶來的諸多挑戰。
一是云+API模式,流血降價、以價換量并不是最優解。
API調用量付費,是大模型的主要變現模式之一,通過token降價來贏得更多大模型業務上云,獲得長期收益,是云廠商價格戰的基本邏輯。但目前來看,以價換量似乎并不奏效。
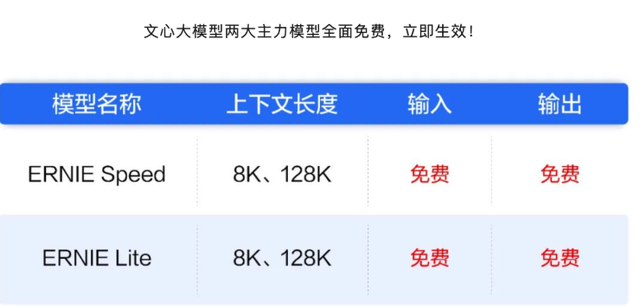
究其原因,是因為B端客戶更關注模廠的長期性、模型質量,質在價先,可靠優先。所以,我們看到,一部分以價換量成功的云廠商,本身就具有比較強的模型能力,比如文心一言兩款主力模型免費之后,百度智能云的日調用量一個月翻了十倍。基于豆包大模型家族的火山云,token調用量也大幅上升,甚至有客戶的tokens調用量增長了5000倍。這說明新用戶會傾向于頭部模型,而老用戶要么不考慮替換現有模型,要么會把雞蛋放在多個頭部廠商的籃子里,趁降價接入更多模型,最終留下性價比高的。而不打價格戰的云廠商,比如華為云將盤古大模型作為“尖刀產品”,也在B端市場取得了不錯的成績,與行業伙伴協同打造的煤炭大模型、醫藥大模型及數智化解決方案,今年在垂直領域的多個企業內被復用。很多行業用戶考慮華為云,就有企業抗風險能力強,能在基礎模型堅持投入,業務穩健運營的預期考量。
上述企業說明,云+API模式成功的根本,是“質在價先”。
二是訂閱制,由于大模型內卷化,導致用戶粘性低、忠誠度不高,會員市場呈現出極高的分散性。
因為大模型的更新換代非常快,一方面新模型在質量和性價比上往往更好,“等等黨”更愿意觀望;另外很多舊模型會不再更新或退役,這就讓會員更不愿意跟平臺長期綁定。這就導致模廠為了不斷吸引新用戶,拉新營銷活動難以停止,獲客成本居高不下,而且影響用戶體驗,需要高頻彈窗廣告,打擾用戶,開發出多個會員等級和收費權益套餐,增加了用戶的決策疲勞。而好不容易拉來的新客戶,往往使用一段時間之后就轉向免費版本,或者更新更便宜的友商產品,長期續費率不高。
可以看到,大模型的內卷化,導致大多數模廠難以說服客戶和開發者,與其建立長期信賴關系。這就給后續的商業變現與價值挖掘,造成了極大挑戰。

告別內卷,就要向外尋找出路。數量多、同質化的大模型,形成了一個密度很高的堰塞湖。那么逃離內卷,就必須疏浚河道,緩解擁塞。所以,2025,將是大模型商業基礎設施日趨完善的一年,通過更全面的“水利設施”,讓大模型應用者和開發者們能夠更方便地取用。
如何判斷一個大模型是否“外向”?有以下幾個衡量標準:
一是模型的開放度或者說兼容性。
如前所說,內卷化周期中,用戶并不愿意將雞蛋放在一個籃子里,或者跟某一個模廠進行長期綁定,這就需要模型具備很強的開放度和兼容性。比如騰訊混元大模型的免費資源包,同時支持hunyuan-pro、hunyuan-standard、hunyuan-turbo等多個模型共享,支撐第三方平臺、ISV服務商為客戶提供多種模型的靈活選擇與切換、模型競技場等,來滿足最終客戶對多元多模的需求。

二是更細致地開發工具。
將大模型技術轉化為生產力,還需要加工工具、工作流等更細致的支持,比如此次OpenAI就為Sora打造了Remix、Blend和Loop三個專業工具,來支撐更好的視頻生成,為此支付每月200美元的Pro用戶也不少。國內,我們實測過的,字節跳動的扣子開發平臺、百度文心智能體開發平臺等的開發工具也已經很容易上手了。
三是大模型應用從開發到商業化的“端到端”支持。
2024年并沒有出現國民級的第三方AI應用。一方面是模型能力本身還需要提升,一些AI智能體平臺充斥著大量低水平、易復制的個人智能體,對話體驗、理解能力、多模態任務等的效果一般,沒有太大商業價值;另一方面,是很多開發者不知道AI應用如何商業化,所以還沒有投入太大精力去開發市場缺乏的產品,滿足尚未解決的需求,這就需要平臺加大對開發者的商業資源扶持。
歸根結底,技術天花板短期內難以突破,大模型市場飽和與同質化競爭的局面就不會宣布解決。大模型要取得商業成功,前提是用戶和開發者的業務能否成功,這是為什么完善的商業基礎設施必不可少。
逃離內卷的堰塞湖,所有模廠2025年都必須回答的問題是:如果大模型是水和電,那么用戶和開發者擰開開關,究竟能得到什么?

審核編輯 黃宇
-
AI
+關注
關注
87文章
30809瀏覽量
268954 -
大模型
+關注
關注
2文章
2437瀏覽量
2668
發布評論請先 登錄
相關推薦
【「大模型啟示錄」閱讀體驗】營銷領域大模型的應用
AIGC技術在內容創作中的應用
國產MCU廠商,靠什么從內卷中脫穎而出?
“反內卷”的智能座艙向何處去?

如何找出住宅中的電路火災隱患?

光伏行業內卷還有多久?
旗幟鮮明反內卷,連接器上下游如何做到?

2024年含直線電機3D打印機在內共出口182.9萬臺

深度學習中的模型權重
【大語言模型:原理與工程實踐】大語言模型的評測
韓國2月出口下跌,半導體出口反增39.1%
數組和鏈表在內存中的區別 數組和鏈表的優缺點
SPICE中的熱模型介紹






 工商網監
工商網監
評論