 數據壓縮的性能指標
數據壓縮的性能指標
在現今的電子信息技術領域,正發生著一場有長遠影響的數字化革命。由于數字化的多媒體信息尤其是數字視頻、音頻信號的數據量特別龐大,如果不對其進行有效的壓縮就難以得到實際的應用。因此,數據壓縮技術已成為當今數字通信、廣播、存儲和多媒體娛樂中的一項關鍵的共性技術。
1.什么是數據壓縮
其作用是:能較快地傳輸各種信號,如傳真、Modem通信等;
在現有的通信干線并行開通更多的多媒體業務,如各種增值業務;緊縮數據存儲容量,如 CD-ROM、VCD和DVD等;
降低發信機功率,這對于多媒體移動通信系統尤為重要。
由此看來,通信時間、傳輸帶寬、存儲空間甚至發射能量,都可能成為數據壓縮的對象。
2.數據為何能被壓縮
首先,數據中間常存在一些多余成分,既冗余度。如在一份計算機文件中,某些符號會重復出現、某些符號比其他符號出現得更頻繁、某些字符總是在各數據塊中可預見的位置上出現等,這些冗余部分便可在數據編碼中除去或減少。冗余度壓縮是一個可逆過程,因此叫做無失真壓縮,或稱保持型編碼。
其次,數據中間尤其是相鄰的數據之間,常存在著相關性。如圖片中常常有色彩均勻的背影,電視信號的相鄰兩幀之間可能只有少量的變化影物是不同的,聲音信號有時具有一定的規律性和周期性等等。因此,有可能利用某些變換來盡可能地去掉這些相關性。但這種變換有時會帶來不可恢復的損失和誤差,因此叫做不可逆壓縮,或稱有失真編碼、摘壓縮等。
此外,人們在欣賞音像節目時,由于耳、目對信號的時間變化和幅度變化的感受能力都有一定的極限,如人眼對影視節目有視覺暫留效應,人眼或人耳對低于某一極限的幅度變化已無法感知等,故可將信號中這部分感覺不出的分量壓縮掉或“掩蔽掉”。這種壓縮方法同樣是一種不可逆壓縮。
對于數據壓縮技術而言,最基本的要求就是要盡量降低數字化的在碼事,同時仍保持一定的信號質量。不難想象,數據壓縮的方法應該是很多的,但本質上不外乎上述完全可逆的冗余度壓縮和實際上不可逆的嫡壓縮兩類。冗余度壓縮常用于磁盤文件、數據通信和氣象衛星云圖等不允許在壓縮過程中有絲毫損失的場合中,但它的壓縮比通常只有幾倍,遠遠不能滿足數字視聽應用的要求。在實際的數字視聽設備中,差不多都采用壓縮比更高但實際有損的嫡壓縮技術。
只要作為最終用戶的人覺察不出或能夠容忍這些失真,就允許對數字音像信號進一步壓縮以換取更高的編碼效率。摘壓縮主要有特征抽取和量化兩種方法,指紋的模式識別是前者的典型例子,后者則是一種更通用的摘壓縮技術。
3數字音、視頻的壓縮標準
數字音頻壓縮技術標準分為電話語音壓縮、調幅廣播語音壓縮和調頻廣播及CD音質的寬帶有頻壓縮3種。
(1)電話(200HZ-3.4kHZ)語音壓縮,主要有國際電信聯盟(ITU)的G.711(64kbit/s、G.721(32kbit/s)、G.728(16kbit/s)和G.729(8kbit/的建議等,用于數字電話通信。
(2)調幅廣播(50HZ-7kHZ)語音壓縮,采用ITU的G.722(64kbit/s)建議,用于優質語音、音樂、音頻會議和視頻會議等。
(3)調頻廣播(20HZ-15kHZ)及CD音質(20HZ-20kH)的寬帶音頻壓縮,主要采用MPEG-1或2雙杜比AC-3等建議,用于CD、MD、MPC、VCD、DVD、HDTV和電影配音等。
視頻壓縮技術標準主要有:
①ITU H.261建議,用于ISDN信道的PC電視電話、桌面視頻會議和音像郵件等通信終端。
②MPEG-1視頻壓縮標準,用于 VCD、MPC、PC/TV一體機、交互電視ITV和電視點播VOD。
③MPEG-2/ITU H.262視頻標準,主要用于數字存儲。視頻廣播和通信,如HDTV、CATV、DVD、VOD和電影點播MOD等。
④ITU H.263建議,用于網上的可視電話、移動多媒體終端、多媒體可視圖文、遙感、電子郵件、電子報紙和交互式計算機成像等。
⑤MPEG-4和 ITU H.VLC/L低碼率多媒體通信標準仍在發展之中。
4.數據壓縮的實現
在各種數據類型中,最難實現的是數字機頻的實時壓縮,因為視頻信號尤其是HDTV信號所占據的帶寬甚寬,實時壓縮需要很高的處理速度。現在,視頻解碼以及音頻的編碼、解碼多依賴于專用芯片或數字信號處理器(DSP)未完成,并已有許多廠商推出了音視合一的單片MPEG-1、MPEG-2解碼器。我國在發展數據壓縮技術過程中,則充分利用了軟件人才優勢。
在軟件實現方面,由于PC主機的處理能力正在飛速提高,直接利用主CPU編程實現各種視聽壓縮和解碼算法對于桌面系統及家用多媒體將越來越有吸引力。
1996年上半年,Intel向全球軟件界發布了它的微處理器媒體擴展(MMX)技術。這種技術主要是在Pentium或Pentium Pro芯片中增加了8個64位寄存器和57條功能強大的新指令,以提高多媒體和通信應用程序中某些計算密集的循環速度。MMX采用單指令多數據(SIMD)技術并行處理多個信號采樣值,可使不同的應用程序性能成倍提高。如:視頻壓縮可提高1.5倍,圖像處理可提高40倍,音頻處理可提高3.7偌,語音識別可提高1.7倍,三維動畫可提高20倍。
與Pentium完全兼容的P55C芯片是1998年3月正式推出的。以后推出的Pentium、Pentium pro或P7等CPU,均將支持MMX指令。
在數據壓縮的硬件實現方面,根本的出路是要有自己的音像壓縮芯片(特別是解壓芯片),不管是專用集成電路(ASIC)實現,還是借助于通用DSP來編程。
而這一類芯片,目前還只是“霧里看花”。
不過我們相信,在不久的將來,這些也會成為現實。
不同壓縮算法的性能比較
JDK GZIP ——這是一個壓縮比高的慢速算法,壓縮后的數據適合長期使用。JDK中的java.util.zip.GZIPInputStream / GZIPOutputStream便是這個算法的實現。
JDK deflate ——這是JDK中的又一個算法(zip文件用的就是這一算法)。它與gzip的不同之處在于,你可以指定算法的壓縮級別,這樣你可以在壓縮時間和輸出文件大小上進行平衡。可選的級別有0(不壓縮),以及1(快速壓縮)到9(慢速壓縮)。它的實現是java.util.zip.DeflaterOutputStream / InflaterInputStream。
LZ4壓縮算法的Java實現——這是本文介紹的算法中壓縮速度最快的一個,與最快速的deflate相比,它的壓縮的結果要略微差一點。如果想搞清楚它的工作原理,我建議你讀一下這篇文章。它是基于友好的Apache 2.0許可證發布的。
Snappy——這是Google開發的一個非常流行的壓縮算法,它旨在提供速度與壓縮比都相對較優的壓縮算法。我用來測試的是這個實現。它也是遵循Apache 2.0許可證發布的。
壓縮測試
要找出哪些既適合進行數據壓縮測試又存在于大多數Java開發人員的電腦中(我可不希望你為了運行這個測試還得個幾百兆的文件)的文件也著實費了我不少工夫。最后我想到,大多數人應該都會在本地安裝有JDK的文檔。因此我決定將javadoc的目錄整個合并成一個文件——拼接所有文件。這個通過tar命令可以很容易完成,但并非所有人都是Linux用戶,因此我寫了個程序來生成這個文件:
public class InputGenerator {
private static final String JAVADOC_PATH = “your_path_to_JDK/docs”;
public static final File FILE_PATH = new File( “your_output_file_path” );
static
{
try {
if ( !FILE_PATH.exists() )
makeJavadocFile();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void makeJavadocFile() throws IOException {
try( OutputStream os = new BufferedOutputStream( new FileOutputStream( FILE_PATH ), 65536 ) )
{
appendDir(os, new File( JAVADOC_PATH ));
}
System.out.println( “Javadoc file created” );
}
private static void appendDir( final OutputStream os, final File root ) throws IOException {
for ( File f : root.listFiles() )
{
if ( f.isDirectory() )
appendDir( os, f );
else
Files.copy(f.toPath(), os);
}
}
}
在我的機器上整個文件的大小是354,509,602字節(338MB)。
測試
一開始我想把整個文件讀進內存里,然后再進行壓縮。不過結果表明這么做的話即便是4G的機器上也很容易把堆內存空間耗盡。
于是我決定使用操作系統的文件緩存。這里我們用的測試框架是JMH。這個文件在預熱階段會被操作系統加載到緩存中(在預熱階段會先壓縮兩次)。我會將內容壓縮到ByteArrayOutputStream流中(我知道這并不是最快的方法,但是對于各個測試而言它的性能是比較穩定的,并且不需要花費時間將壓縮后的數據寫入到磁盤里),因此還需要一些內存空間來存儲這個輸出結果。
下面是測試類的基類。所有的測試不同的地方都只在于壓縮的輸出流的實現不同,因此可以復用這個測試基類,只需從StreamFactory實現中生成一個流就好了:
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(1)
@Warmup(iterations = 2)
@Measurement(iterations = 3)
@BenchmarkMode(Mode.SingleShotTime)
public class TestParent {
protected Path m_inputFile;
@Setup
public void setup()
{
m_inputFile = InputGenerator.FILE_PATH.toPath();
}
interface StreamFactory
{
public OutputStream getStream( final OutputStream underlyingStream ) throws IOException;
}
public int baseBenchmark( final StreamFactory factory ) throws IOException
{
try ( ByteArrayOutputStream bos = new ByteArrayOutputStream((int) m_inputFile.toFile().length());
OutputStream os = factory.getStream( bos ) )
{
Files.copy(m_inputFile, os);
os.flush();
return bos.size();
}
}
}
這些測試用例都非常相似(在文末有它們的源代碼),這里只列出了其中的一個例子——JDK deflate的測試類;
public class JdkDeflateTest extends TestParent {
@Param({“1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”})
public int m_lvl;
@Benchmark
public int deflate() throws IOException
{
return baseBenchmark(new StreamFactory() {
@Override
public OutputStream getStream(OutputStream underlyingStream) throws IOException {
final Deflater deflater = new Deflater( m_lvl, true );
return new DeflaterOutputStream( underlyingStream, deflater, 512 );
}
});
}
}
測試結果
輸出文件的大小
首先我們來看下輸出文件的大小:
||實現||文件大小(字節)|| ||GZIP||64,200,201|| ||Snappy (normal)||138,250,196|| ||Snappy (framed)|| 101,470,113|| ||LZ4 (fast)|| 98,316,501|| ||LZ4 (high) ||82,076,909|| ||Deflate (lvl=1) ||78,369,711|| ||Deflate (lvl=2) ||75,261,711|| ||Deflate (lvl=3) ||73,240,781|| ||Deflate (lvl=4) ||68,090,059|| ||Deflate (lvl=5) ||65,699,810|| ||Deflate (lvl=6) ||64,200,191|| ||Deflate (lvl=7) ||64,013,638|| ||Deflate (lvl=8) ||63,845,758|| ||Deflate (lvl=9) ||63,839,200||
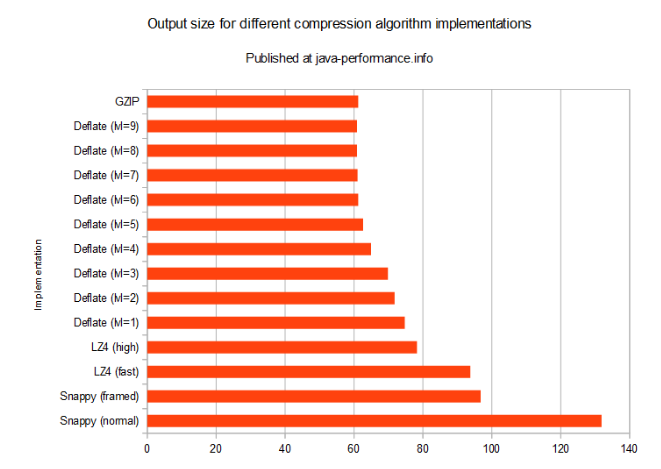
可以看出文件的大小相差懸殊(從60Mb到131Mb)。我們再來看下不同的壓縮方法需要的時間是多少。
壓縮時間
||實現||壓縮時間(ms)|| ||Snappy.framedOutput ||2264.700|| ||Snappy.normalOutput ||2201.120|| ||Lz4.testFastNative ||1056.326|| ||Lz4.testFastUnsafe ||1346.835|| ||Lz4.testFastSafe ||1917.929|| ||Lz4.testHighNative ||7489.958|| ||Lz4.testHighUnsafe ||10306.973|| ||Lz4.testHighSafe ||14413.622|| ||deflate (lvl=1) ||4522.644|| ||deflate (lvl=2) ||4726.477|| ||deflate (lvl=3) ||5081.934|| ||deflate (lvl=4) ||6739.450|| ||deflate (lvl=5) ||7896.572|| ||deflate (lvl=6) ||9783.701|| ||deflate (lvl=7) ||10731.761|| ||deflate (lvl=8) ||14760.361|| ||deflate (lvl=9) ||14878.364|| ||GZIP ||10351.887||
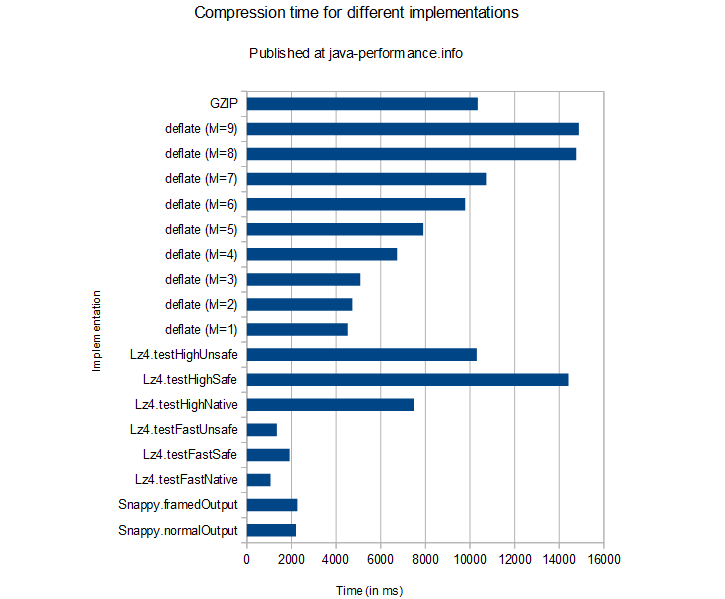
我們再將壓縮時間和文件大小合并到一個表中來統計下算法的吞吐量,看看能得出什么結論。
吞吐量及效率
||實現||時間(ms)||未壓縮文件大小||吞吐量(Mb/秒)||壓縮后文件大小(Mb)|| ||Snappy.normalOutput ||2201.12 ||338 ||153.5581885586 ||131.8454742432|| ||Snappy.framedOutput ||2264.7 ||338 ||149.2471409017 ||96.7693328857|| ||Lz4.testFastNative ||1056.326 ||338 ||319.9769768045 ||93.7557220459|| ||Lz4.testFastSafe ||1917.929 ||338 ||176.2317583185 ||93.7557220459|| ||Lz4.testFastUnsafe ||1346.835 ||338 ||250.9587291688 ||93.7557220459|| ||Lz4.testHighNative ||7489.958 ||338 ||45.1270888301 ||78.2680511475|| ||Lz4.testHighSafe ||14413.622 ||338 ||23.4500391366 ||78.2680511475|| ||Lz4.testHighUnsafe ||10306.973 ||338 ||32.7933332124 ||78.2680511475|| ||deflate (lvl=1) ||4522.644 ||338 ||74.7350443679 ||74.7394561768|| ||deflate (lvl=2) ||4726.477 ||338 ||71.5120374012 ||71.7735290527|| ||deflate (lvl=3) ||5081.934 ||338 ||66.5101120951 ||69.8471069336|| ||deflate (lvl=4) ||6739.45 ||338 ||50.1524605124 ||64.9452209473|| ||deflate (lvl=5) ||7896.572 ||338 ||42.8033835442 ||62.6564025879|| ||deflate (lvl=6) ||9783.701 ||338 ||34.5472536415 ||61.2258911133|| ||deflate (lvl=7) ||10731.761 ||338 ||31.4952969974 ||61.0446929932|| ||deflate (lvl=8) ||14760.361 ||338 ||22.8991689295 ||60.8825683594|| ||deflate (lvl=9) ||14878.364 ||338 ||22.7175514727 ||60.8730316162|| ||GZIP ||10351.887 ||338 ||32.651051929 ||61.2258911133||
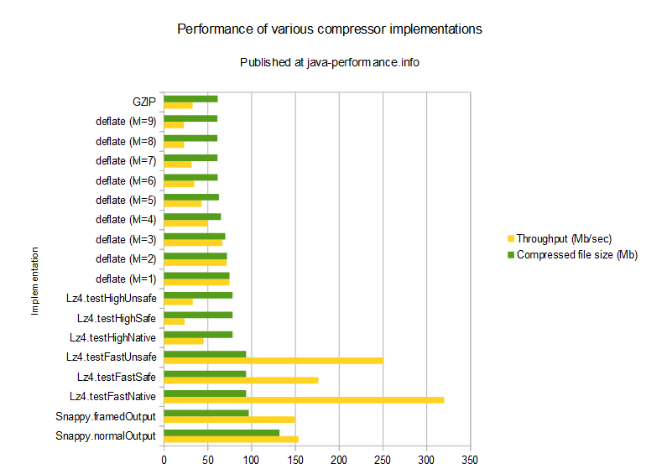
可以看到,其中大多數實現的效率是非常低的:在Xeon E5-2650處理器上,高級別的deflate大約是23Mb/秒,即使是GZIP也就只有33Mb/秒,這大概很難令人滿意。同時,最快的defalte算法大概能到75Mb/秒,Snappy是150Mb/秒,而LZ4(快速,JNI實現)能達到難以置信的320Mb/秒!
從表中可以清晰地看出目前有兩種實現比較處于劣勢:Snappy要慢于LZ4(快速壓縮),并且壓縮后的文件要更大。相反,LZ4(高壓縮比)要慢于級別1到4的deflate,而輸出文件的大小即便和級別1的deflate相比也要大上不少。
因此如果需要進行“實時壓縮”的話我肯定會在LZ4(快速)的JNI實現或者是級別1的deflate中進行選擇。當然如果你的公司不允許使用第三方庫的話你也只能使用deflate了。你還要綜合考慮有多少空閑的CPU資源以及壓縮后的數據要存儲到哪里。比方說,如果你要將壓縮后的數據存儲到HDD的話,那么上述100Mb/秒的性能對你而言是毫無幫助的(假設你的文件足夠大的話)——HDD的速度會成為瓶頸。同樣的文件如果輸出到SSD硬盤的話——即便是LZ4在它面前也顯得太慢了。如果你是要先壓縮數據再發送到網絡上的話,最好選擇LZ4,因為deflate75Mb/秒的壓縮性能跟網絡125Mb/秒的吞吐量相比真是小巫見大巫了(當然,我知道網絡流量還有包頭,不過即使算上了它這個差距也是相當可觀的)。
總結
如果你認為數據壓縮非常慢的話,可以考慮下LZ4(快速)實現,它進行文本壓縮能達到大約320Mb/秒的速度——這樣的壓縮速度對大多數應用而言應該都感知不到。
如果你受限于無法使用第三方庫或者只希望有一個稍微好一點的壓縮方案的話,可以考慮下使用JDK deflate(lvl=1)進行編解碼——同樣的文件它的壓縮速度能達到75Mb/秒。
-
數據壓縮
+關注
關注
0文章
31瀏覽量
10135 -
性能指標
+關注
關注
0文章
14瀏覽量
7900
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論