 在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化
Recurrent Drafting (簡稱 ReDrafter) 是蘋果公司為大語言模型 (LLM) 推理開發并開源的一種新型推測解碼技術,該技術現在可與 NVIDIA TensorRT-LLM 一起使用。ReDrafter 幫助開發者大幅提升了 NVIDIA GPU 上的 LLM 工作負載性能。NVIDIA TensorRT-LLM 是一個 LLM 推理優化庫,提供了一個易于使用的 Python API 來定義 LLM 和構建 NVIDIA TensorRT 引擎,這些引擎具有頂尖的優化功能,可在 GPU 上高效執行推理。優化功能包括自定義 Attention Kernel、Inflight Batching、Paged KV Caching、量化技術 (FP8、INT4 AWQ、INT8 SmoothQuant) 等。
推測解碼 (Speculative decoding)是一種通過并行生成多個 token 來加速 LLM 推理的技術。它使用較小的“draft”模塊預測未來的 token,然后由主模型進行驗證。該方法通過更好地利用可用資源實現低延遲推理,在保持輸出質量的同時大大縮短了響應時間,尤其是在低流量時段。
ReDrafter 運用基于循環神經網絡 (RNN)的采樣 (稱為 Drafting) 并結合之前在 Medusa 等其他技術中使用的樹狀注意力,預測和驗證來自多個可能路徑的draft token 以提高準確性,并在解碼器的每次迭代中接受一個以上 token。NVIDIA 與蘋果公司合作,在 TensorRT-LLM 中添加了對該技術的支持,使更加廣泛的開發者社區能夠使用該技術。
ReDrafter 與 TensorRT-LLM 的集成擴大了該技術的覆蓋范圍,解鎖了新的優化潛力,并改進了 Medusa 等先前的方法。Medusa 的路徑接受和 token 采樣發生在 TensorRT-LLM 運行時,需要在接受路徑未知的情況下處理所有可能的未來路徑,而且其中大部分路徑最終都會被丟棄,這就給引擎內部帶來了一些開銷。為了減少這種開銷,ReDrafter 要求在 drafting下一次迭代的未來 token 之前,先驗證 token 并接受最佳路徑。
為了進一步減少開銷,TensorRT-LLM 更新后在單個引擎中整合了drafting和驗證邏輯,不再依賴運行時或單獨的引擎。這種方法為 TensorRT-LLM 內核選擇和調度提供了更大的自由度,通過優化網絡實現了性能的最大化。
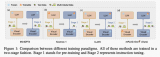
為了更好地說明 ReDrafter 的改進,圖 1 展示了 TensorRT-LLM 中 ReDrafter 實現與 Medusa 實現的主要區別。大多數與推測解碼相關的組件都在 ReDrafter 的引擎內完成,這大大簡化了 ReDrafter 所需的運行時更改。
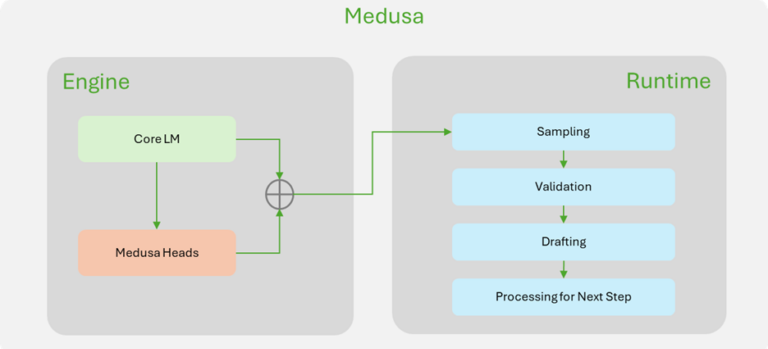
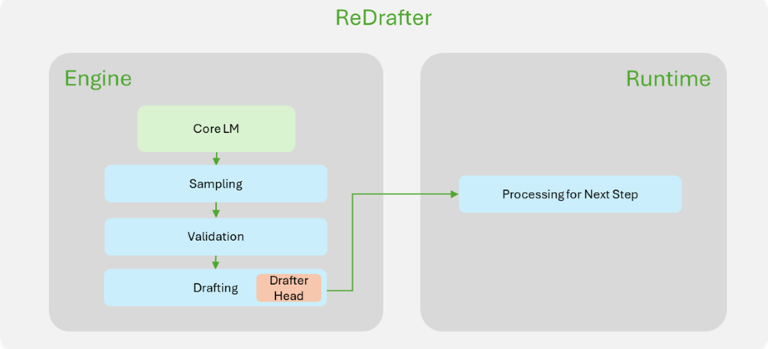
圖 1. NVIDIA TensorRT-LLM 中
Medusa(左)和 ReDrafter(右)實現的比較
下面將深入探討有助于在 TensorRT-LLM 中啟用 ReDrafter 的一些變化。
兼容 Inflight-batching
批處理的引擎
Inflight-batching (IFB) 是一種通過批量處理上下文階段和生成階段請求,來顯著提高吞吐量的策略。鑒于上下文階段請求與生成階段請求的處理方式不同(生成階段請求需要 draft token 驗證),因此結合 IFB 的推測解碼會給管線帶來更大的復雜性。ReDrafter 將驗證邏輯移至模型定義內部,因此引擎在驗證過程中也需要該邏輯。與注意力插件類似,該批處理被分成兩個較小的批處理:一個用于上下文請求,另一個用于生成請求。然后,每個較小的批處理進入計算工作流,最后再合并成一個批處理進行 drafting 流程。
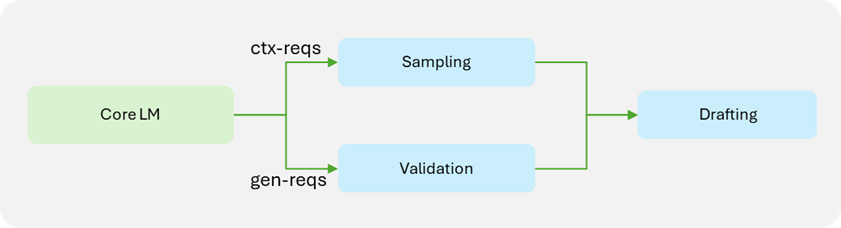
圖 2. ReDrafter 兼容 TensorRT-LLM 引擎的
Inflight-batching 批處理計算工作流
請注意,這種方法要求任一路徑上的所有運算符都支持空張量。如果一個批處理由所有上下文請求或所有生成請求組成,就可能出現空張量。該功能增加了 TensorRT-LLM API 的靈活性,使未來定義更復雜的模型成為可能。
實現引擎內驗證和 Drafting
為了在引擎內進行驗證和 draft,TensorRT-LLM 更新時加入了對許多新操作的支持,這樣 PyTorch 代碼就可以輕松地轉化成一個 TensorRT-LLM 模型的定義。
以下 PyTorch 代碼摘錄是蘋果公司的 PyTorch 實現的 ReDrafter。TensorRT-LLM 實現幾乎就是 PyTorch 版本的直接逐行映射。
PyTorch
def unpack(
packed_tensor: torch.Tensor,
unpacker: torch.Tensor,
) -> torch.Tensor:
assert len(packed_tensor.shape) == 3
last_dim_size = packed_tensor.shape[2]
batch_size, beam_width, beam_length = unpacker.shape
unpacked_data_indices = unpacker.view(
batch_size, beam_width * beam_length, 1).expand(
-1, -1, last_dim_size
)
unpacked_tensor = torch.gather(
packed_tensor, 1, unpacked_data_indices).reshape(
batch_size, beam_width, beam_length, -1
)
return unpacked_tensor
TensorRT-LLM
def _unpack_beams(
x: Tensor,
indices: Tensor,
num_beams: int,
beam_length: int
) -> Tensor:
assert x.rank() == 3
d0 = shape(x, 0, INT_DTYPE_STR)
dl = shape(x, -1, INT_DTYPE_STR)
indices = view(
indices, [-1, num_beams * beam_length, 1], False)
res_shape = concat([d0, num_beams, beam_length, dl])
res = view(gather_nd(x, indices), res_shape, False)
return res
當然,這只是一個非常簡單的例子。如要了解更復雜的示例,請參見束搜索實現。借助為 ReDrafter 添加的新功能,就可以改進 TensorRT-LLM 中的 Medusa 實現,從而進一步提高其性能。
ReDrafter
在 TensorRT-LLM 中的性能
根據蘋果公司的基準測試,在采用 TP8 的 NVIDIA GPU 上使用 TensorRT-LLM 的 ReDrafter 最多可將吞吐量提高至基礎 LLM 的 2.7 倍。
請注意,任何推測解碼技術的性能提升幅度都會受到諸多因素的大幅影響,包括:
GPU 利用率:推測解碼通常用于低流量場景,由于批量較小,GPU 資源的利用率通常較低。
平均接受率:由于推測解碼必須執行額外的計算,而其中很大一部分計算最終會在驗證后被浪費,因此每個解碼步驟的延遲都會增加。所以要想通過推測解碼獲得任何性能上的優勢,平均接受率必須高到足以彌補增加的延遲。這受到束數量、束長度和束搜索本身質量(受訓練數據影響)的影響。
任務:在某些任務(例如代碼完成)中預測未來的 token 更容易,使得接受率更高,性能也會因此而提升。
總結
NVIDIA 與蘋果公司的合作讓 TensorRT-LLM 變得更加強大和靈活,使 LLM 社區能夠創造出更加復雜的模型并通過 TensorRT-LLM 輕松部署,從而在 NVIDIA GPU 上實現無與倫比的性能。這些新特性帶來了令人興奮的可能性,我們熱切期待著社區使用 TensorRT-LLM 功能開發出新一代先進模型,進一步改進 LLM 工作負載。
-
NVIDIA
+關注
關注
14文章
4985瀏覽量
103027 -
模型
+關注
關注
1文章
3238瀏覽量
48827 -
LLM
+關注
關注
0文章
287瀏覽量
327
原文標題:NVIDIA TensorRT-LLM 現支持 Recurrent Drafting,實現 LLM 推理優化
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA TensorRT與Apache Beam SDK的集成
學習資源 | NVIDIA TensorRT 全新教程上線

阿里云 & NVIDIA TensorRT Hackathon 2023 決賽圓滿收官,26 支 AI 團隊嶄露頭角

周四研討會預告 | 注冊報名 NVIDIA AI Inference Day - 大模型推理線上研討會
現已公開發布!歡迎使用 NVIDIA TensorRT-LLM 優化大語言模型推理

點亮未來:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驅動的 Windows PC 上運行新模型
如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
魔搭社區借助NVIDIA TensorRT-LLM提升LLM推理效率
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

TensorRT-LLM低精度推理優化

NVIDIA TensorRT-LLM Roadmap現已在GitHub上公開發布






 工商網監
工商網監
評論