 使用華為云 X 實例部署圖數據庫 Virtuoso 并存儲 6500 萬條大數據的完整過程與性能測評
使用華為云 X 實例部署圖數據庫 Virtuoso 并存儲 6500 萬條大數據的完整過程與性能測評
前言
1. 部署Virtuoso圖數據庫的準備工作
1.1 選擇華為云X實例的原因
1.2 Virtuoso圖數據庫簡介
1.3 環境準備與系統配置
2. Virtuoso的安裝與配置
2.1 安裝Virtuoso
2.2 Virtuoso的基礎配置
3. 6500萬條數據的導入與管理
3.1 數據格式與導入方法
3.2 數據存儲結構
4. Virtuoso的性能測評
4.1 測試環境概述
4.2 數據導入速度
4.3 查詢性能測試
結語
前言
在大數據時代,圖數據庫以其強大的關系處理能力在復雜網絡、社交媒體分析、知識圖譜等領域得到了廣泛應用。而在云計算的蓬勃發展下,使用云服務器進行圖數據庫的部署與管理變得更加方便高效。本篇文章將詳細介紹如何在華為云 X 實例上部署開源圖數據庫 Virtuoso,并將 6500 萬條大數據存儲于其中,最后對數據庫的性能進行全面測評,為后續大規模數據管理提供有益參考。
1. 部署 Virtuoso 圖數據庫的準備工作
1.1 選擇華為云 X 實例的原因
華為云 X 實例具有高性能、低延遲、可擴展的特點,尤其適合對計算與存儲資源有較高需求的數據庫應用。相比于傳統服務器,云實例可以快速配置與調整資源,尤其在數據量逐步增加時,可以動態擴展,確保數據庫運行的穩定性與性能。此次選擇的華為云 X 實例配置為 3M 帶寬,4 核 CPU 和 12GB 內存,具備足夠的處理與存儲能力,能夠高效應對 6500 萬條數據的存儲需求。
最近華為云 828 B2B 企業節火熱進行中,Flexus X 實例的促銷力度相當誘人。對于有云服務需求的企業,這無疑是一個絕佳的機會,大家不妨前往了解一下。
1.2 Virtuoso 圖數據庫簡介
Virtuoso 是一款功能強大的通用型數據庫管理系統,支持關系數據和圖數據,尤其擅長處理 RDF 三元組形式的大規模圖數據。Virtuoso 支持 SPARQL 查詢語言,允許用戶高效地對圖數據進行查詢與操作。此次測試中,將利用 Virtuoso 來存儲大規模 nt 格式的 RDF 數據并進行性能測評。
1.3 環境準備與系統配置
在正式部署 Virtuoso 之前,首先需要對華為云 X 實例的操作系統和必要的依賴進行準備與配置。步驟如下:
操作系統選擇:我們選擇了 Huawei Cloud EulerOS 2.0 作為操作系統。該版本穩定性高,兼容性強,且社區支持廣泛,適合作為服務器環境。
安裝必備依賴:Virtuoso 運行所需的一些基礎依賴包括 openssl、flex、yacc 等開發工具,安裝命令如下:
yum install openssl-devel
yum install flex
yum install byacc -y
2. Virtuoso 的安裝與配置
2.1 安裝 Virtuoso
在依賴安裝完成后,我們開始從源碼安裝 Virtuoso。由于 Virtuoso 的開源版本支持我們對其進行靈活的調整和優化,因此采用源碼編譯的方式。安裝步驟如下:
下載 Virtuoso 源碼
wget https://sourceforge.net/projects/virtuoso/files/virtuoso/7.2.13/virtuoso-opensource-7.2.13.tar.gz
tar -zxvf virtuoso-opensource-7.2.13.tar.gz
cd virtuoso-opensource
編譯與安裝
./autogen.sh
./configure --prefix=/usr/local/virtuoso-opensource
make
sudo make install
啟動 Virtuoso 服務
安裝完成后,通過以下命令啟動 Virtuoso 數據庫服務:
cd /usr/local/virtuoso/var/lib/virtuoso/db
virtuoso-t -f &
2.2 Virtuoso 的基礎配置
安裝完成后,為確保 Virtuoso 能夠在大規模數據下穩定高效運行,需要對其配置文件進行適當修改。Virtuoso 的主要配置文件是`virtuoso.ini`,其中需要調整的關鍵參數包括內存使用、線程數、查詢緩存等。具體修改如下:
調整內存配置:將`NumberOfBuffers`和`MaxDirtyBuffers`參數調整為適應服務器內存的大小。
NumberOfBuffers = 170000MaxDirtyBuffers = 130000
設置線程數:根據實例的CPU核心數調整線程數,以最大化利用多核性能。
復制代碼
3. 6500 萬條數據的導入與管理
3.1 數據格式與導入方法
本次測試的數據集為 RDF 格式,包含 6500 萬條三元組數據,主要由資源(subjects)、屬性(predicates)和目標(objects)三部分組成。Virtuoso 支持多種數據導入方式,其中最常用的是通過 SPARQL 和 Bulk Loader 進行批量導入。我們選擇使用 Bulk Loader 來進行大規模數據導入,操作步驟如下:
準備 RDF 數據文件:將 RDF 數據文件上傳至 Virtuoso 服務器的指定目錄下。
配置 Bulk Loader:編輯`virtuoso.ini`文件,設置數據文件的導入路徑。
DirForAll = /data/import
執行數據導入命令:
使用 Virtuoso 的 isql 工具來批量導入數據:
ld_dir('/data/import', '*.nt', 'http://nttriple.com/graph');
rdf_loader_run();
3.2 數據存儲結構
Virtuoso 的存儲架構采用了高效的索引機制來存儲 RDF 數據。每一條 RDF 三元組都通過索引進行管理,確保了數據在寫入和讀取時的高效性。6500 萬條數據在導入過程中會自動生成相應的索引,Virtuoso 會根據查詢模式對索引進行優化,以提高后續查詢的性能。
4. Virtuoso 的性能測評
4.1 測試環境概述
本次性能測試基于華為云 X 實例,旨在評估 Virtuoso 在大規模數據存儲和查詢速度方面的表現。測試內容涵蓋了數據導入效率以及不同復雜度 SPARQL 查詢的響應時間。我們使用了 Virtuoso 自帶的 SPARQL 查詢接口進行測試,并通過多樣化的查詢場景模擬了實際使用中的各種操作負載。此外,針對高并發場景,測試了 Virtuoso 在華為云 X 實例多核處理器下的性能表現,確保數據庫能夠在大規模數據場景下高效運行。
4.2 數據導入速度
導入 6500 萬條 RDF 數據的整個過程耗時約 254 秒,平均每秒鐘處理約 25.59 萬條三元組數據。在幾年之前,同樣是導入這組數據,花的時間是大約 6 個小時,時間節約了近 100 倍,這得益于 Virtuoso 高效的批量導入機制以及華為云 X 實例的優秀 I/O 性能,數據導入的總體表現令人滿意。

4.3 查詢性能測試
我們設計了幾種典型的 SPARQL 查詢場景,分別測量了不同類型查詢的響應速度。
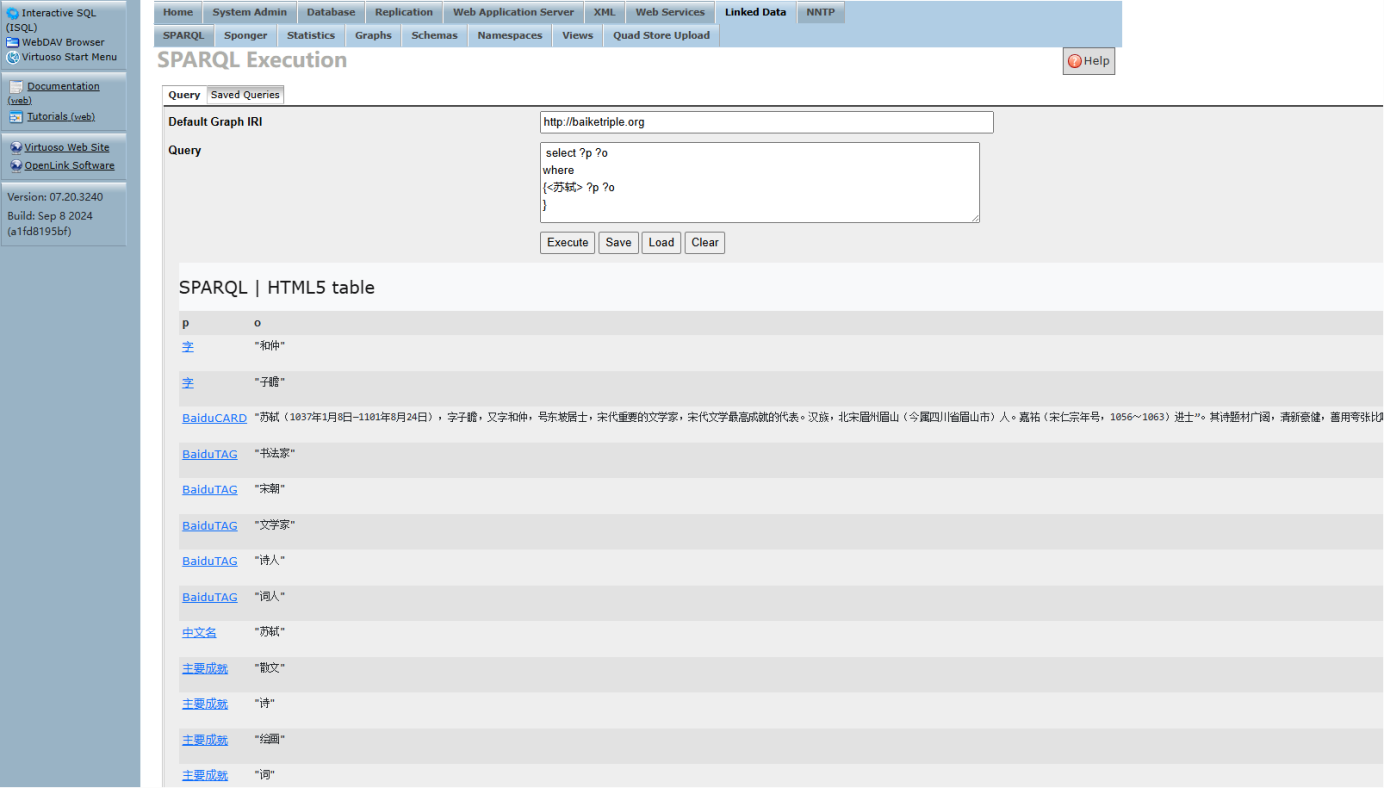
基本查詢
查詢某一特定資源的屬性信息,比如查詢蘇軾相關信息。
select ?p ?o
where
{<蘇軾> ?p ?o }
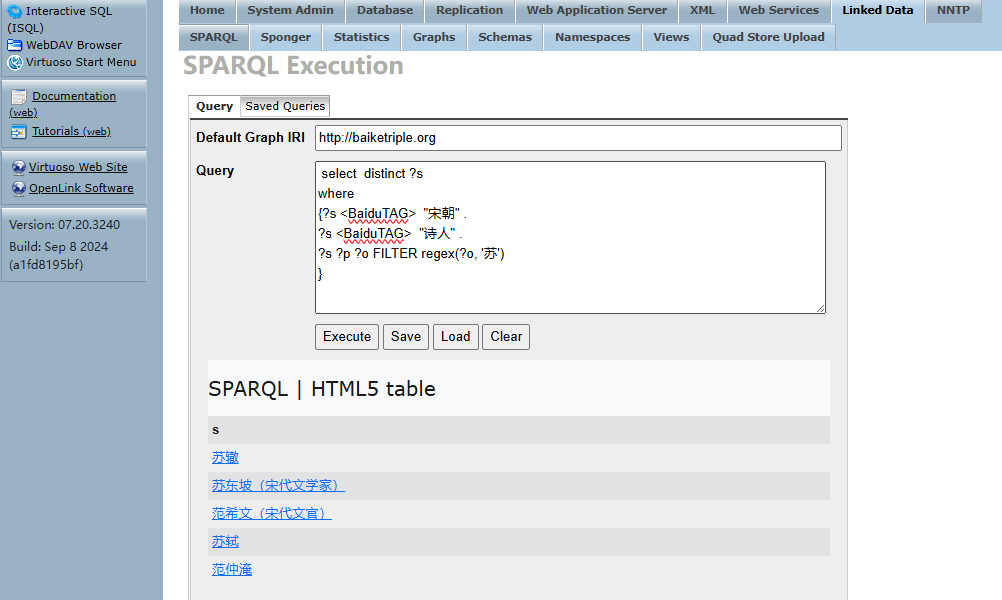
復雜模式查詢
查詢多個條件匹配的資源,涉及多跳關系的查找,比如查找百度標簽為“宋朝”,還有“詩人”,并且屬性中包含“蘇”的所有實體。
select distinct ?s
where
{?s "宋朝" .
?s "詩人" .
?s ?p ?o FILTER regex(?o, '蘇')
}
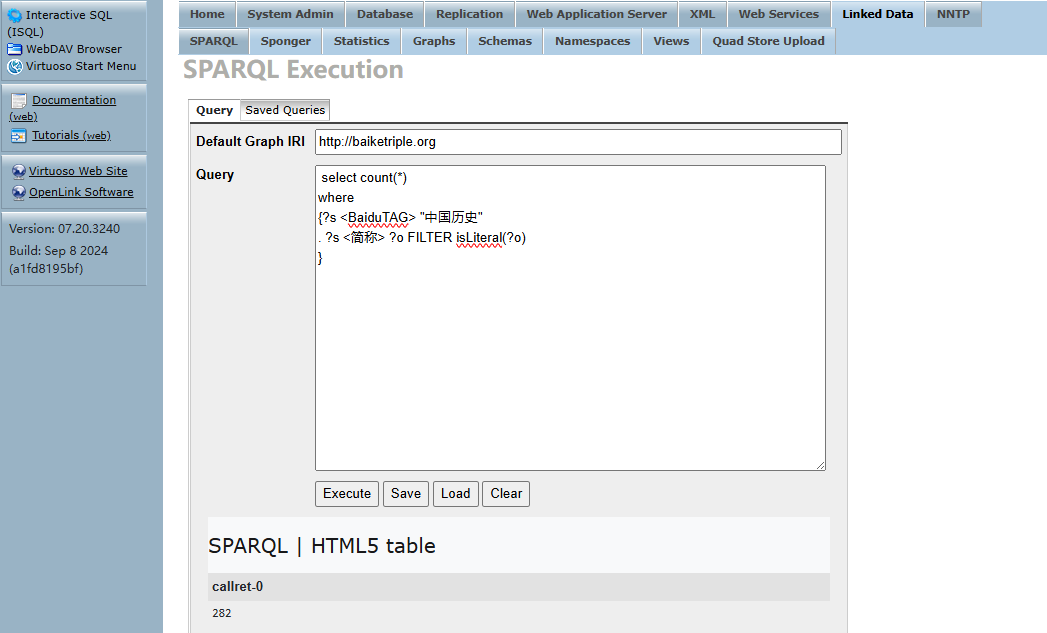
聚合查詢
對數據集進行統計,如計算節百度標簽為“中國歷史”的數據數量。
select count(*)
where
{?s "中國歷史"
. ?s <簡稱> ?o FILTER isLiteral(?o)
}
在 6500 萬條數據中進行 SPARQL 的簡單查詢、復雜查詢和聚合查詢,結果幾乎都能在秒級內返回,耗時極少。這不僅展現了 Virtuoso 在處理大規模數據時的優異性能,也證明了華為云 X 實例服務器的強大計算能力,確保了數據庫在高負載下的高效運行。
結語
在華為云 X 實例上成功部署 Virtuoso 圖數據庫并存儲 6500 萬條大數據的過程中,我們見證了云服務器與圖數據庫結合的強大優勢。Virtuoso 憑借其高效的存儲與查詢機制,在大規模數據環境下表現出色,而華為云 X 實例則為數據庫提供了穩定的運行環境。通過合理的性能優化措施,Virtuoso 可以在未來的大數據場景中發揮更大的作用,為復雜關系型數據的管理與查詢提供有力支持。
華為云 X 實例的彈性計算和高速網絡支持為大規模數據處理提供了堅實的基礎,使其成為部署圖數據庫的理想選擇。對于需要處理海量數據的應用場景,Virtuoso 在華為云 X 實例上的表現無疑是令人滿意的。
審核編輯 黃宇
-
數據庫
+關注
關注
7文章
3816瀏覽量
64448 -
大數據
+關注
關注
64文章
8894瀏覽量
137480 -
華為云
+關注
關注
3文章
2566瀏覽量
17455
發布評論請先 登錄
相關推薦
華為云榮登Gartner?云數據庫挑戰者象限
使用 Memtester 對華為云 X 實例進行內存性能測試

華為云 Flexus 云服務器 X 實例:在 openEuler 系統下搭建 MySQL 主從復制
華為云Flexus X實例,Redis性能加速評測及對比
華為云 Flexus X 實例 MySQL 性能加速評測及對比

數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

干貨分享 如何采集OPC DA數據并存儲到SQL Server數據庫?
“Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分節選
華為云多模數據庫 GeminiDB 架構與應用實踐直播問答實錄
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例





 工商網監
工商網監
評論