 亞馬遜云科技AI Networking解決方案回顧
亞馬遜云科技AI Networking解決方案回顧
前一段時間的2024 re:Invent 大會中,亞馬遜云科技可謂是重磅連連,發布了全套最新AI networking基礎設施方案。亞馬遜云科技公用計算高級副總裁 Peter DeSantis 首先引用了一篇 2020 年的論文:“AI 場景中巨量的計算負載,并不能完全通過 Scale Out AI 集群來解決,同樣也需要 Scale Up單臺 AI 服務器的能力。” 基于這樣的設計思想,Peter 推出了 Trainium2 Server 和 Trainium2 UltraServer。同時單個芯片性能對于集群的總效率也起到了重要的基礎算力作用,本文主要回顧亞馬遜最新的AI Networking片內/片間/網間綜合解決方案。
Trainium2 服務器
Trainium2 和 Trainium2-Ultra 服務器的構建塊就是我們所說的 Trainium2“物理服務器”。每個 Trainium2 物理服務器都有一個獨特的架構,占用 18 個機架單元 (RU),由一個 2 機架單元 (2U) CPU 機頭托盤組成,該托盤連接到八個 2U 計算托盤。在服務器的背面,所有計算托盤都使用類似于 GB200 NVL36 的無源銅背板連接在一起形成一個 4×4 2D 環面,不同之處在于,對于 GB200 NVL36,背板將每個 GPU 連接到多個 NVSwitches,而在 Trainium2 上,沒有使用交換機,所有連接都只是兩個加速器之間的點對點連接。
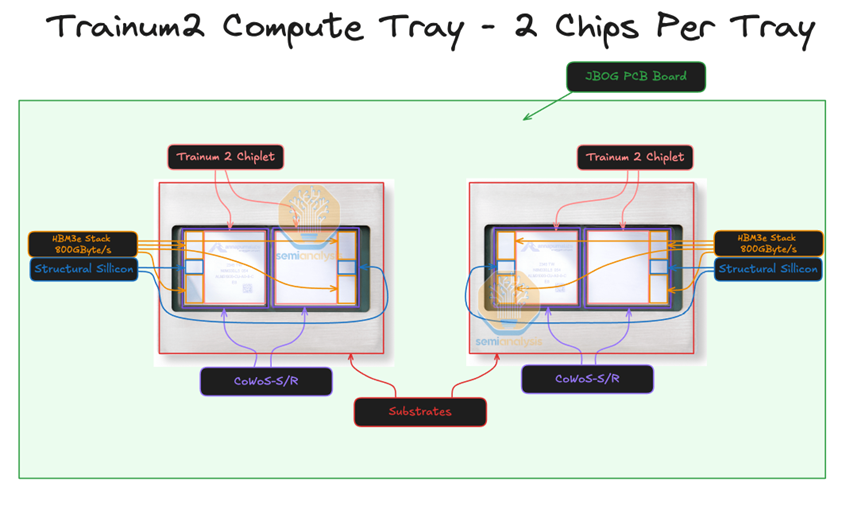
每個 2U 計算托盤有兩個 Trainium 芯片,沒有 CPU。這與 GB200 NVL72 架構不同,在 GB200 NVL72 架構中,每個計算托盤在同一個托盤中同時具有 CPU 和 GPU。每個 Trainium2 計算托盤通常也被稱為 JBOG,即“只是一堆 GPU”,因為每個計算托盤沒有任何 CPU,不能獨立運行。
(來源:Semianalysis)
Scale Inside 單個芯片片內互聯
Trainium2芯片
于 2023 年發布, Trainium2 采用了Multi-Die Chiplet架構,并使用CoWoS-S/R先進封裝技術,將計算芯粒和(HBM)模塊集成在一個緊湊的封裝(Package)內。具體而言,每個 Trainium2 單卡內封裝了 2 個 Trainium2 計算Die,而每個Die旁邊都配備了 2 塊 96GB HBM3 內存模塊,提供高達 46TB/s 的帶寬。目前沒有提及Multi-die間的互聯協議,暫且理解為私有協議。 這種先進的封裝設計克服了芯片尺寸的工程極限,最大限度地縮小了計算和內存之間的距離,使用大量高帶寬、低延遲的互聯將它們連接在一起。這不僅降低了延遲,還能使用更高效的協議交換數據,提高了性能。
在計算核心方面,Trainium2 由少量大型 NeuronCore 組成,每個 NeuronCore 內部集成了張量引擎、矢量引擎、標量引擎和 GPSIMD 引擎,各司其職協同工作。這種設計思路與傳統 GPGPU 使用大量較小張量核心形成鮮明對比,大型核心在處理 Gen AI 工作負載時能夠有效減少控制開銷。目前大模型參數量級常常到達數千億甚至數萬億,Trainium2 是面向 AI 大模型的高性能訓練芯片,與第一代 Trainium 芯片相比,Trainium2 訓練速度提升至 4 倍,能夠部署在多達 10 萬個芯片的計算集群中,大幅降低了模型訓練時間,同時能效提升多達 2 倍。
Scale Up超節點間互聯
在競爭愈發激烈的 AI 大模型領域中,如何能夠更高效的、更低成本的、更快速擴容滿足算力需求的能力,就成為了贏得市場的關鍵之一。正如亞馬遜云科技公用計算高級副總裁 Peter 所言:“在推動前沿模型的發展的進程中,對于極為苛刻的人工智能工作負載來說,再強大的計算能力也永遠不夠。”Scale Up 所帶來的好處就是為大模型訓練提供了更大的訓練成功率、更高效的梯度數據匯聚與同步、更低的能源損耗。基于 Trainium2 UltraServer 支撐的 Amazon EC2 Trn2 UltraServer 可以提供高達 83.2 FP8 PetaFLOPS 的性能以及 6TB 的 HBM3 內存,峰值帶寬達到 185 TB/s,并借助 12.8 Tb/s EFA(Elastic Fabric Adapter)網絡進行互連。讓 AI 工程師能夠考慮在單臺 64 卡一體機內以更短的時間訓練出更加復雜、更加精準的 AI 模型。
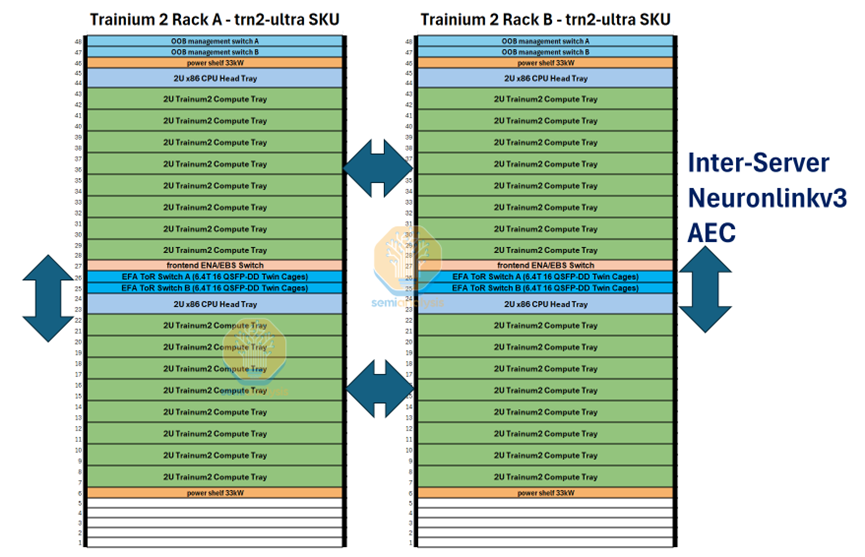
AWS Scale Up也是一個超節點的HBD域, 其機架互聯結構和NVL36類似,由2個機架緊密耦合組成。一個機架32個GPU計算卡,超節點HBD域共64個GPU計算卡互聯。Scale Up超節點是業界目前正在積極探索的領域,盡管生態存在技術路徑的差異,但基于開放協議的技術路徑將是未來GPU互聯的關鍵,也是國內未來構建更大規模、更高效率集群的必經之路。
(來源:Semianalysis)
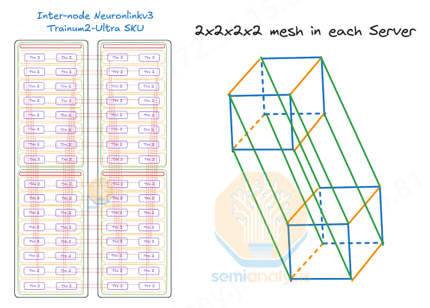
Trn2-Ultra SKU 由每個縱向擴展域的 4 個 16 芯片物理服務器組成,因此每個縱向擴展域由 64 個芯片組成,由兩個機架組成,其配置類似于 GB200 NVL36x2。為了沿 z 軸形成圓環,每個物理服務器都使用一組有源銅纜連接到其他兩個物理服務器。
NeuronLink 私有協議構成TB級互聯
Trainium2 UltraServer 一定要提及的就是 NeuronLink,它是一種亞馬遜云科技專有的網絡互聯技術,可使多臺 Trainium2 Server 連接起來,成為一臺邏輯上的服務器。我們可以理解Neuronlink和NVlink類似是一種基于私有的GPU/xPU片間通信協議。
NeuronLink 技術可以讓 Trainium2 Server 之間直接訪問彼此的內存,并提供每秒 2 TB 的帶寬(高于目前的NVlink),延遲僅為 1 微秒。NeuronLink 技術使得多臺 Trainium2 Server 就像是一臺超級計算機一樣工作,故稱之為 “UltraServer”。“這正是訓練萬億級參數的大型人工智能模型所需要的超級計算平臺,非常強大!” Peter 介紹道。
(來源:Semianalysis)
Scale Out 十萬卡集群網間互聯
在 Scale Out 層面,亞馬遜云科技正在與 Anthropic 合作部署 Rainier 項目,Anthropic 聯合創始人兼首席計算官 Tom Brown 宣布下一代 Claude 模型將在 Project Rainier 上訓練。Rainier 項目是一個龐大的 AI 超級計算集群,包含數十萬個 Trainium2 芯片,預計可提供約 130 FP8 ExaFLOPS 的超強性能,運算能力是以往集群的 5 倍多,將為 Anthropic 的下一代 Claude AI 模型提供支持。Rainier 項目將會幫助 Anthropic 的客戶可以用更低價格、更快速度使用到更高智能的 Claude AI 大模型服務。
(來源:Semianalysis)
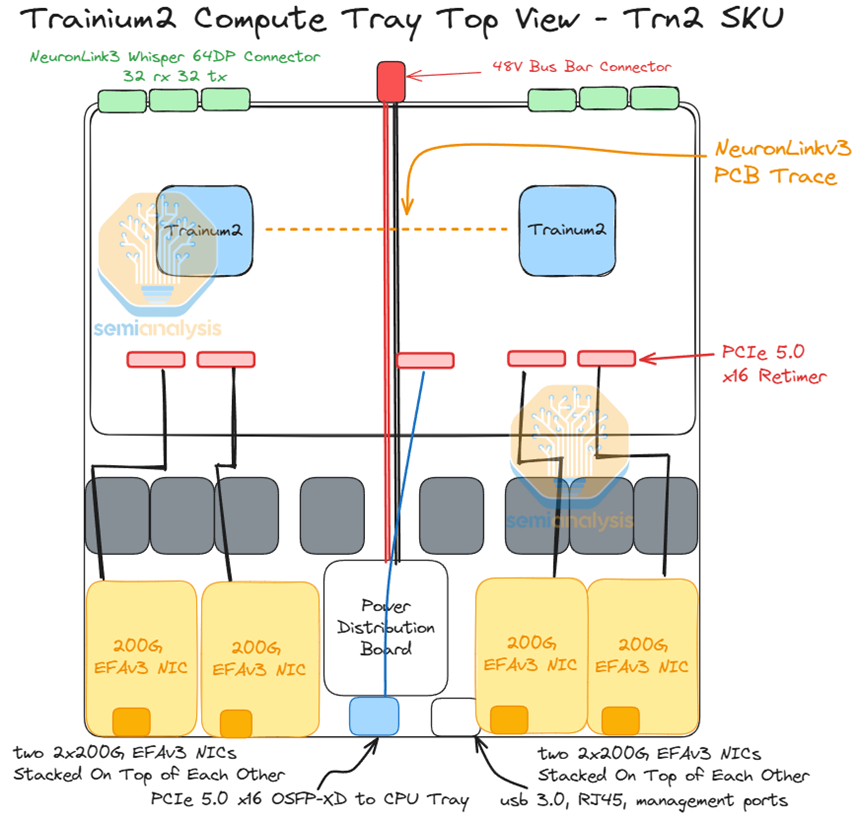
對于 Trn2,每個計算托盤最多有 8 個 200G EFAv3 NIC網卡,每個橫向擴展以太網芯片可提供高達 800Gbit/s 的速度。從計算托盤連接到 CPU 托盤的籠子也需要一個重定時器。計算托盤左側的 Trainium2 芯片將使用與 CPU 托盤連接的前 8 個通道,而右側的 Trainium2 芯片將使用連接到 CPU 托盤的最后 8 個通道。
對于 Leaf 和 Spine 交換機,AWS 將使用基于 Broadcom Tomahawk4的 1U 25.6T 白盒交換機。AWS 不使用多個交換機來組成基于機箱的模塊化交換機,因為這種設置的爆炸半徑很大。如果機箱發生故障,則機箱連接的所有線卡和鏈路都會發生故障。這可能涉及數百個 Trainium2 芯片。
Front End 前端網絡
我們提及一下連接傳統以太網的前端網絡,亞馬遜使用的Nitro 芯片作為世界上最早發布的 DPU 之一,其旨在實現 Network、Storage、Hypervisor、Security 等虛擬化技術方面的 Workload offloading,消除了傳統虛擬化技術對 CPU 資源的性能開銷。同時還集成了多種功能,包括 Security Root 信任根、內存保護、安全監控等,以此來加強 Amazon EC2 實例的高性能和高安全性。安全性以及加密功能對于云計算中心的多租戶網絡安全至關重要。我們在之前的一期Kiwi Talks有講述智能網卡與DPU在應用上的主要區別,亞馬遜的前端網絡案例可以讓我們更清楚的了解兩者在應用上的不同
用于AI網絡Scale Out的智能網卡作為更輕量級的硬件多用于網絡加速,與交換機等組件共同完成擁塞控制、自適應理由、選擇性重傳等系列AI網絡傳輸問題。SmartNIC和DPU的技術路徑存在顯著不同。
在 2024 re:Invent 中,我們看到亞馬遜云將 Nitro DPU 與 Graviton CPU 之間的 PCIe 鏈路都進行了加密,創建了一個相互鎖定的信任網絡,使 CPU 到 CPU、CPU 到 DPU 的所有連接都由硬件提供安全保護。
寫在最后,全球主流超大規模云廠商已經成功搭建萬卡集群并朝著十萬卡集群目標邁進。但礙于生態壁壘,部分廠商還基于私有協議在構建自有網絡體系。與此同時,國內的萬卡集群在異構芯片調度、軟硬件打通、超節點HBD域構建等方面仍然面臨挑戰,未來人工智能網絡還有很長一段路要走,還有待行業積極擁抱開源開放的協議與物理接口,以實現更緊密的協同發展。
關于我們AI網絡全棧式互聯架構產品及解決方案提供商
奇異摩爾,成立于2021年初,是一家行業領先的AI網絡全棧式互聯產品及解決方案提供商。公司依托于先進的高性能RDMA 和Chiplet技術,創新性地構建了統一互聯架構——Kiwi Fabric,專為超大規模AI計算平臺量身打造,以滿足其對高性能互聯的嚴苛需求。我們的產品線豐富而全面,涵蓋了面向不同層次互聯需求的關鍵產品,如面向北向Scale out網絡的AI原生智能網卡、面向南向Scale up網絡的GPU片間互聯芯粒、以及面向芯片內算力擴展的2.5D/3D IO Die和UCIe Die2Die IP等。這些產品共同構成了全鏈路互聯解決方案,為AI計算提供了堅實的支撐。
奇異摩爾的核心團隊匯聚了來自全球半導體行業巨頭如NXP、Intel、Broadcom等公司的精英,他們憑借豐富的AI互聯產品研發和管理經驗,致力于推動技術創新和業務發展。團隊擁有超過50個高性能網絡及Chiplet量產項目的經驗,為公司的產品和服務提供了強有力的技術保障。我們的使命是支持一個更具創造力的芯世界,愿景是讓計算變得簡單。奇異摩爾以創新為驅動力,技術探索新場景,生態構建新的半導體格局,為高性能AI計算奠定穩固的基石。
-
gpu
+關注
關注
28文章
4743瀏覽量
128984 -
服務器
+關注
關注
12文章
9196瀏覽量
85514 -
AI
+關注
關注
87文章
30985瀏覽量
269271 -
亞馬遜
+關注
關注
8文章
2668瀏覽量
83404
原文標題:十萬卡集群的必經之路:亞馬遜云科技AI Networking片內/片間/網間互聯解決方案回顧
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
亞馬遜云科技與Adobe攜手推出AEP解決方案
亞馬遜云科技與SAP推出GROW with SAP解決方案
基于亞馬遜云科技的GROW with SAP解決方案 助力企業簡化云端ERP部署
NVIDIA亮相2024亞馬遜云科技re:Invent全球大會
Infor選擇Amazon Bedrock支持生成式AI解決方案
亞馬遜云科技助力Shulex打造生成式AI應用
亞馬遜云科技與伊克羅德信息攜手,共推AI賦能產業升級
涂鴉智能借助亞馬遜云科技全面擁抱生成式AI打造智慧解決方案
涂鴉智能借助亞馬遜云科技全面擁抱生成式AI打造智慧解決方案 提升開發者效率
店匠科技選擇亞馬遜云科技為首選云服務供應商
亞馬遜云科技與SAP攜手云ERP體驗,引領AI新紀元
亞馬遜云科技攜手SAP通過生成式AI解鎖創新潛力
掌閱科技選擇亞馬遜云科技為重要云服務供應商
亞馬遜云科技助力沐瞳應用生成式AI技術打造卓越游戲體驗 賦能業務決策






 工商網監
工商網監
評論