") 傳統(tǒng)機(jī)器學(xué)習(xí)方法和應(yīng)用指導(dǎo)
傳統(tǒng)機(jī)器學(xué)習(xí)方法和應(yīng)用指導(dǎo)
在上一篇文章中,我們介紹了機(jī)器學(xué)習(xí)的關(guān)鍵概念術(shù)語(yǔ)。在本文中,我們會(huì)介紹傳統(tǒng)機(jī)器學(xué)習(xí)的基礎(chǔ)知識(shí)和多種算法特征,供各位老師選擇。
01
傳統(tǒng)機(jī)器學(xué)習(xí)
傳統(tǒng)機(jī)器學(xué)習(xí),一般指不基于神經(jīng)網(wǎng)絡(luò)的算法,適合用于開(kāi)發(fā)生物學(xué)數(shù)據(jù)的機(jī)器學(xué)習(xí)方法。盡管深度學(xué)習(xí)(一般指神經(jīng)網(wǎng)絡(luò)算法)是一個(gè)強(qiáng)大的工具,目前也非常流行,但它的應(yīng)用領(lǐng)域仍然有限。與深度學(xué)習(xí)相比,傳統(tǒng)方法在給定問(wèn)題上的開(kāi)發(fā)和測(cè)試速度更快。開(kāi)發(fā)深度神經(jīng)網(wǎng)絡(luò)的架構(gòu)并進(jìn)行訓(xùn)練是一項(xiàng)耗時(shí)且計(jì)算成本高昂的任務(wù),而傳統(tǒng)的支持向量機(jī)(SVM)和隨機(jī)森林等模型則相對(duì)簡(jiǎn)單。此外,在深度神經(jīng)網(wǎng)絡(luò)中估計(jì)特征重要性(即每個(gè)特征對(duì)預(yù)測(cè)的貢獻(xiàn)程度)或模型預(yù)測(cè)的置信度仍然不是一件容易的事。即使使用深度學(xué)習(xí)模型,通常仍應(yīng)訓(xùn)練一個(gè)傳統(tǒng)方法,與基于神經(jīng)網(wǎng)絡(luò)的模型進(jìn)行比較。
傳統(tǒng)方法通常期望數(shù)據(jù)集中的每個(gè)樣本具有相同數(shù)量的特征,但是生物學(xué)檢測(cè)數(shù)據(jù)很難滿足這個(gè)需求。舉例說(shuō)明,當(dāng)使用蛋白質(zhì)、RNA的表達(dá)水平矩陣時(shí),每個(gè)樣本表達(dá)的蛋白質(zhì)、RNA數(shù)量不同。為了使用傳統(tǒng)方法處理這些數(shù)據(jù),可以通過(guò)簡(jiǎn)單的技術(shù)(如填充和窗口化)將數(shù)據(jù)調(diào)整為相同的大小。“填充”意味著將每個(gè)樣本添加額外的零值,直到它與數(shù)據(jù)集中最大的樣本大小相同。相比之下,窗口化將每個(gè)樣本縮短到給定的大小(例如,使用在所有樣品中均表達(dá)的蛋白質(zhì)、RNA)。
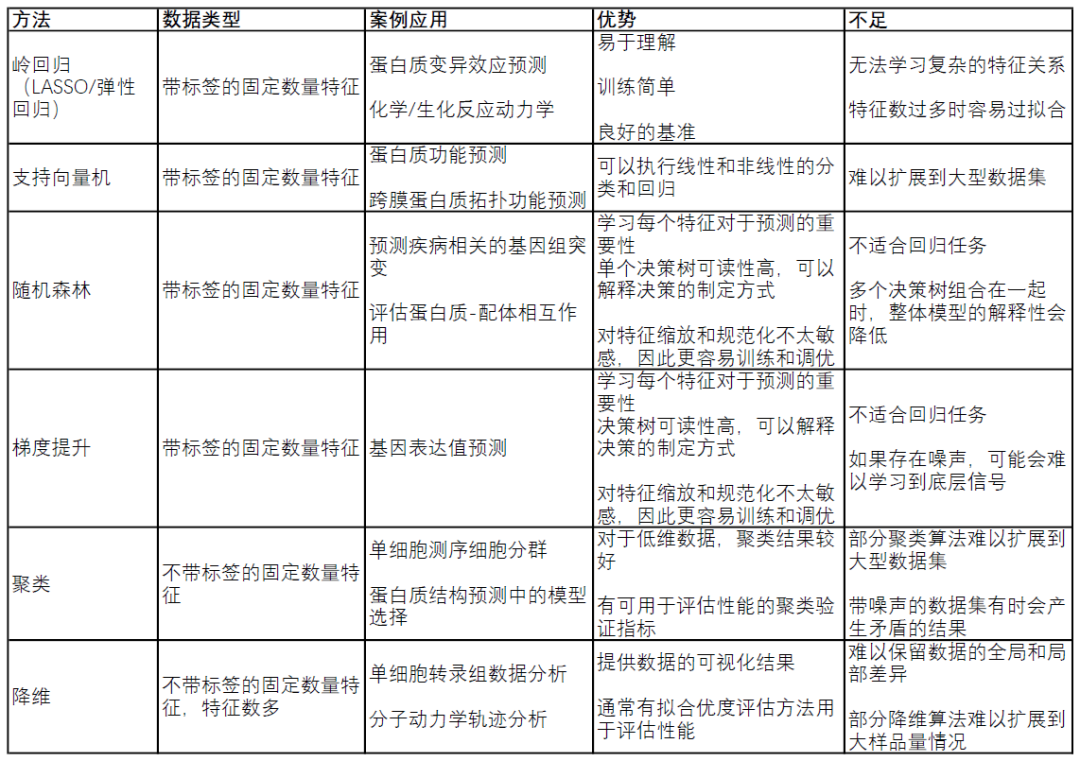
表1. 傳統(tǒng)機(jī)器學(xué)習(xí)方法比較
02
回歸模型
對(duì)于回歸問(wèn)題,嶺回歸(帶有正則化項(xiàng)的線性回歸)通常是開(kāi)發(fā)模型的良好起點(diǎn)。因?yàn)樗梢詾榻o定任務(wù)提供快速且易于理解的基準(zhǔn)。當(dāng)希望減少模型依賴的特征數(shù)時(shí),比如篩選生物標(biāo)志物研究時(shí),其他線性回歸變體如LASSO回歸和彈性網(wǎng)絡(luò)回歸也是值得考慮的。數(shù)據(jù)中特征之間的關(guān)系通常是非線性的,因此在這種情況下使用如支持向量機(jī)(SVM)的模型通常是更合適的選擇。SVM是一種強(qiáng)大的回歸和分類模型,它使用核函數(shù)將不可分的問(wèn)題轉(zhuǎn)換為更容易解決的可分問(wèn)題。根據(jù)使用的核函數(shù),SVM可以用于線性回歸和非線性回歸。一個(gè)開(kāi)發(fā)模型的好方法是訓(xùn)練一個(gè)線性SVM和一個(gè)帶有徑向基函數(shù)核的SVM(一種通用的非線性SVM),以量化非線性模型是否能帶來(lái)任何增益。非線性方法可以提供更強(qiáng)大的模型,但代價(jià)是難以解釋哪些特征在影響模型。
03
分類模型
許多常用的回歸模型也用于分類。對(duì)于分類任務(wù),訓(xùn)練一個(gè)線性SVM和一個(gè)帶有徑向基函數(shù)核的SVM也是一個(gè)好的默認(rèn)起點(diǎn)。另一種可以嘗試的方法是k近鄰分類(KNN)。作為最簡(jiǎn)單的分類方法之一,KNN提供了與其他更復(fù)雜的模型(如SVM)進(jìn)行比較的有用基線性能指標(biāo)。另一類強(qiáng)大的非線性方法是基于集成的模型,如隨機(jī)森林和XGBoost。這兩種方法都是強(qiáng)大的非線性模型,具有提供特征重要性估計(jì)和通常需要最少超參數(shù)調(diào)優(yōu)的優(yōu)點(diǎn)。由于特征重要性值的分配和決策樹(shù)結(jié)構(gòu),這些模型可分析哪些特征對(duì)預(yù)測(cè)貢獻(xiàn)最大,這對(duì)于生物學(xué)理解至關(guān)重要。
無(wú)論是分類還是回歸,許多可用的模型都有令人眼花繚亂的變體。試圖預(yù)測(cè)特定方法是否適合特定問(wèn)題可能會(huì)有誤導(dǎo)性,因此采取經(jīng)驗(yàn)性的試錯(cuò)方法來(lái)找到最佳模型是明智的選擇。選擇最佳方法的一個(gè)好策略是訓(xùn)練和優(yōu)化上述多種方法,并選擇在驗(yàn)證集上表現(xiàn)最好的模型,最后再在獨(dú)立的測(cè)試集上比較它們的性能。
04
聚類模型和降維
聚類算法在生物學(xué)中廣泛應(yīng)用。k-means是一種強(qiáng)大的通用聚類方法,像許多其他聚類算法一樣,需要將聚類的數(shù)量設(shè)置為超參數(shù)。DBSCAN是一種替代方法,不需要預(yù)先定義聚類的數(shù)量,但需要設(shè)置其他超參數(shù)。在聚類之前進(jìn)行降維也可以提高具有大量特征的數(shù)據(jù)集的性能。
降維技術(shù)用于將具有大量屬性(或維度)的數(shù)據(jù)轉(zhuǎn)換為低維形式,同時(shí)盡可能保留數(shù)據(jù)點(diǎn)之間的不同關(guān)系。例如,相似的數(shù)據(jù)點(diǎn)(如兩個(gè)同源蛋白序列)在低維形式中也應(yīng)保持相似,而不相似的數(shù)據(jù)點(diǎn)(如不相關(guān)的蛋白序列)應(yīng)保持不相似。通常選擇兩維或三維,以便在坐標(biāo)軸上可視化數(shù)據(jù),盡管在機(jī)器學(xué)習(xí)中使用更多維度也有其用途。這些技術(shù)包括數(shù)據(jù)的線性和非線性變換。生物學(xué)中常見(jiàn)的例子包括主成分分析(PCA)、均勻流形逼近和投影(UMAP)以及t分布隨機(jī)鄰域嵌入(t-SNE)。
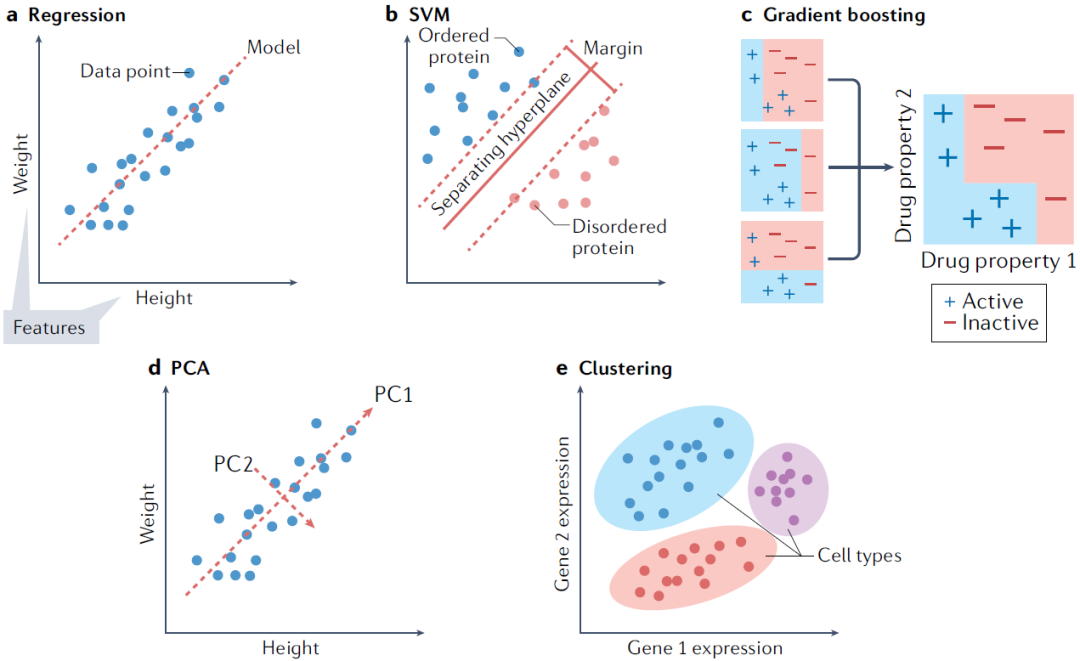
圖1. 各種傳統(tǒng)機(jī)器學(xué)習(xí)模型
本文詳細(xì)介紹了傳統(tǒng)機(jī)器學(xué)習(xí)方法和應(yīng)用指導(dǎo),下一篇文章將介紹深度神經(jīng)網(wǎng)絡(luò)算法模型,敬請(qǐng)期待。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100835 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8421瀏覽量
132710
原文標(biāo)題:生物學(xué)家的機(jī)器學(xué)習(xí)指南(三)
文章出處:【微信號(hào):SBCNECB,微信公眾號(hào):上海生物芯片】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是機(jī)器學(xué)習(xí)?通過(guò)機(jī)器學(xué)習(xí)方法能解決哪些問(wèn)題?

NPU與機(jī)器學(xué)習(xí)算法的關(guān)系
LLM和傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)
麻省理工學(xué)院推出新型機(jī)器人訓(xùn)練模型
AI大模型與傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
【《時(shí)間序列與機(jī)器學(xué)習(xí)》閱讀體驗(yàn)】+ 了解時(shí)間序列
機(jī)器學(xué)習(xí)中的數(shù)據(jù)分割方法
機(jī)器學(xué)習(xí)中的交叉驗(yàn)證方法
深度學(xué)習(xí)中的無(wú)監(jiān)督學(xué)習(xí)方法綜述
人工神經(jīng)網(wǎng)絡(luò)與傳統(tǒng)機(jī)器學(xué)習(xí)模型的區(qū)別
深度學(xué)習(xí)的基本原理與核心算法
機(jī)器人視覺(jué)技術(shù)中圖像分割方法有哪些
深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)的對(duì)比
機(jī)器學(xué)習(xí)8大調(diào)參技巧





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論