 MVTRF:多視圖特征預測SSD故障
MVTRF:多視圖特征預測SSD故障
固態硬盤( Solid State Drive,SSD )在大型數據中心中發揮著重要作用。SSD故障會影響存儲系統的穩定性,造成額外的維護開銷。為了提前預測和處理SSD故障,本文提出了一種多視角多任務隨機森林( MVTRF )方案。MVTRF基于從SSD的長期和短期監測數據中提取的多視圖特征預測SSD故障。特別地,采用多任務學習,通過同一模型同時預測什么類型的故障以及何時發生。本文還提取了MVTRF的關鍵決策來分析為什么會發生故障。這些故障細節將有助于驗證和處理SSD故障。在來自數據中心的大規模真實數據上對提出的MVTRF進行評估。實驗結果表明,與現有方案相比,MVTRF具有更高的故障預測準確率,準確率平均提高了46.1 %,召回率平均提高了57.4 %。
一、背景及動機
以往的工作仍然面臨以下挑戰。首先,大部分基于SSD故障進行預測都建立在一個或幾個短期監控日志上,而較少關注SSD的長期日志。然而,通過分析,一些SSD故障可能并不體現在短期的局部信息中,而是隱藏在長期信息中。少數工作使用長短時記憶( LSTM )等序列模型直接從長期數據中學習,但SSD監測數據的序列長度過長且長度差異較大,影響序列模型的性能。對于長期數據,它們的趨勢和分布對于判斷SSD故障實際上很重要。第二,盡管失效預測對可能失效的SSD進行了篩選,但對驗證和處理失效缺乏指導性建議。操作者只知道一個故障可能發生,而不知道它是什么,何時以及為什么會發生。預測或分析更多的失效類型、壽命(故障前剩余工作時間)、失效原因等信息,有助于操作人員驗證是否是內部SSD失效,判斷采取何種措施以及是否具有緊迫性。例如,運營商會以不同的緊急程度處理不同類型的故障,并測量。
二、數據集
從騰訊云數據中心采集了三星PM1733和PM9A3固態硬盤的大規模SSD監測數據集。該數據集包含了騰訊數據中心30多萬個不同壽命的SSD在9個月內超過7000萬條監控日志。日志信息由SSD序列號、服務器序列號、時間戳和SSD內部屬性值組成。除了SMART屬性外,三星還定制了更多的內部屬性來增強SSD的自我監控能力,使得預測和分析更多的故障信息成為可能。PM1733共有40個內部屬性,PM9A3共有85個內部屬性。本文將所有這些屬性,包括標準的SMART屬性和自定義屬性統稱為Telemetry屬性。
PM1733和PM9A3的故障列表也由騰訊公司提供。列表中包含了騰訊運營商收集的SSD故障信息,包括故障SSD的序列號、故障上報日期、故障描述以及處理時間和措施。清單中共有409條失效記錄。經操作人員檢查,大部分為SSD故障,少數為服務器背板等其他設備的故障。
通過分析騰訊故障列表中的故障描述和處理措施,故障可以分為8種類型,在不同的時間采取不同的措施來處理不同類型的故障。這些失效類型分別稱為Check Failed、Cancelling I / O、Media Error、SSD Drop、Fail Mode、PLP、Read Only和可靠性降級,相關描述如表1所示。
三、故障分析
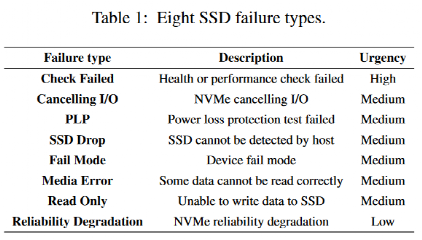
圖1和圖2分別比較了具有nand_bytes_write和temperature屬性的失效SSD和健康SSD的數據分布。橫坐標為桶指數,縱坐標為落在桶中的數據比例。圖1顯示失效SSD和健康SSD的nand_bytes_write值大部分落在桶1 -桶7中。然而,在后期桶中,失效SSD的值比健康SSD有更大的比例。由圖2可知,在溫度屬性的第20 ~ 23個桶中,故障SSD和健康SSD的數據分布差異較大,但在第17個桶之前的分布較為相似。總的來說,失效SSD和健康SSD存在一定差異,但在某些范圍內的分布相似。
為了進一步區分失效SSD和健康SSD的屬性相似分布,深入探究了長期遙測數據的統計量分布差異。即每個SSD的每個屬性在長時間內的多個值落入桶中,計算每個桶中這些值的數量占所有桶中值數量的比例,稱為桶比例。
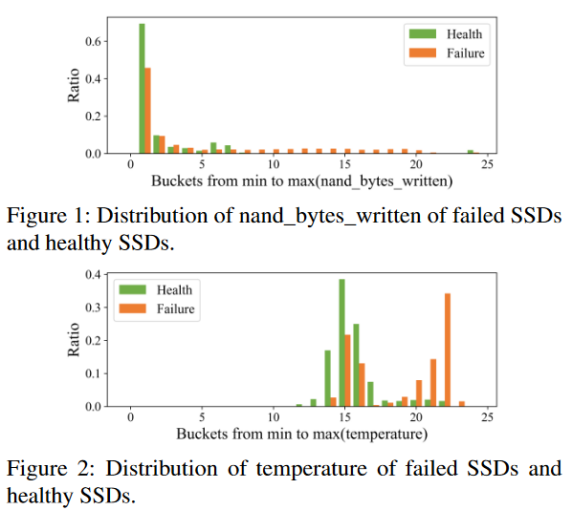
對于nand_bytes_write屬性,圖3給出了桶1 - 7的長期數據的桶比例,橫坐標仍為桶指數,縱坐標為長期數據的桶比例。表明在這些值分布相似的桶上,失效SSD和健康SSD的長期數據的桶比例分布不同。在nand _ bytes _ write較小的桶3 ~ 7上,健康SSD的長期數據的桶比例明顯大于故障SSD。這表明,健康的固態硬盤在長期中受到的寫操作更少,因此更不容易發生故障。對于溫度屬性,圖4給出了圖2中分布較為相似的桶17之前的長期數據的桶比例。在低溫桶1 ~ 13中,健康SSD長期數據的桶比例明顯較大,說明低溫有利于SSD健康。總之,基于長期SSD數據的統計,失效SSD和健康SSD之間的差異有被放大的趨勢。
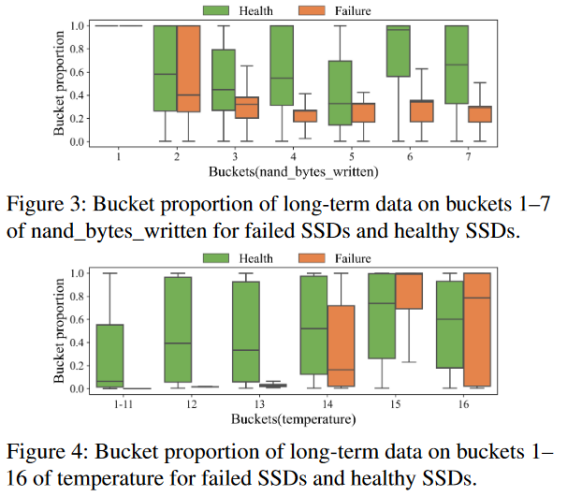
接下來,分析Telemetry屬性的長期變化趨勢,以探究故障SSD和健康SSD之間的差異。由于同一臺服務器上的大多數SSD的工作負載通常是相似的,因此在故障發生之前,比較故障SSD與同一臺服務器上其他健康SSD的屬性變化趨勢。圖5展示了不同失效類型的失效SSD主要異常屬性的變化趨勢。橫坐標表示采集時間,縱坐標表示屬性值。從圖5可以看出,同一服務器上健康SSD的屬性趨勢相似,而故障SSD的屬性趨勢在長期上存在差異。此外,失效SSD的曲線可能涉及緩慢變化、快速變化和穩定等多個階段。
四、設計與實現
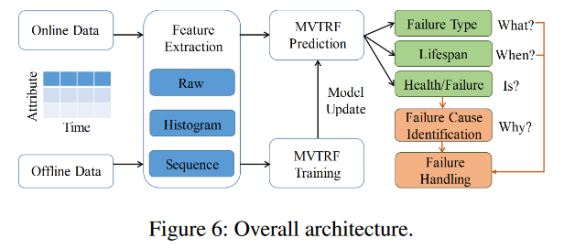
多視角多任務隨機森林( MVTRF )方案的總體架構如圖6所示。MVTRF設計主要遵循3個思路:1 )設計長期數據的分布和趨勢相關特征以捕捉長期失效模式;2 )將不同視角的特征結合分組學習和聯合決策,準確預測SSD故障;3 )預測并提取詳細的故障信息,提高故障處理效率。
4.1 Multi-view特征提取
根據先前對SSD故障征兆的觀察,可以發現SSD故障不僅體現在短期數據的異常值上,還隱藏在長期數據的分布和趨勢上。將長期數據直接輸入到LSTM等序列模型中是一種選擇。但由于使用周期不同、采集不規范等原因,不同SSD的遙測日志數量相差很大。序列模型很難處理如此不同長度的序列數據。此外,過長的序列也會影響序列模型(例如, LSTM在長序列情況下存在梯度消失問題)的性能,導致過高的計算復雜度和開銷。
為了避免直接使用長期數據,通過從長期數據中提取特征來表示其分布和趨勢。引入基于桶統計量的直方圖特征和序列相關特征,可以刻畫序列波動和變化的程度。直方圖特征和序列相關特征從長期數據中提取關鍵信息,丟棄冗余信息。這些特征和短期原始數據構成了SSD故障預測的多視圖信息。
4.1.1 原始特征
經過預處理和數據清洗后,遙測日志數據為原始特征。假設經過數據清洗后剩余N個屬性,定義SSD第T次遙測數據的原始特征為DT = { a1T,a2T,..,anT,..,aNT },其中a1T,a2T,..,anT,..,aNT為N個屬性的值。主要使用原始特征來捕獲屬性的短期異常值,因此它們默認來自單個遙測日志。
4.1.2 直方圖特征
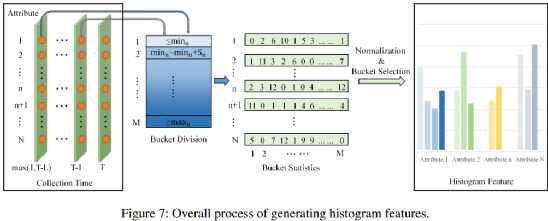
直方圖特征利用了先前提到過的桶概念。首先對SSD進行長度為256的日志收集,因為256個日志大致跨度在三個月以上能夠覆蓋失效癥狀的時間跨度。依據最小值和最大值在100個桶上進行分布,最終篩選出有效的桶分布。
4.1.3 序列相關特征
提出序列相關特征來表示SSD的長期原始特征DT - L - DT的波動和趨勢。引入變異系數來表征屬性的波動性,引入峰度和斜率來表征屬性的趨勢性。為了捕捉長期數據中可能存在的多個變化階段,還在時間維度( G默認為4)中將DT - L - DT等分為G段,并分別計算每段的變異系數、峰度和斜率。
變異系數。變異系數可以衡量屬性在較長時期內的離散程度。相對于方差或標準差,變異系數可以消除不同屬性、不同SSD的不同尺度的影響。第n個屬性第g段的變異系數CVARng的計算公式如下:
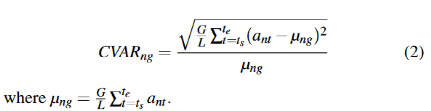
峰度。峰度反映了一個屬性長期分布的陡峭程度。第n個屬性的第g段峰度KURTng的計算公式如下所示:
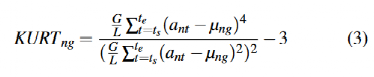
斜率。斜率可以反映某一屬性隨時間的變化趨勢。第n個屬性第g段的斜率SLOPEng計算如下:
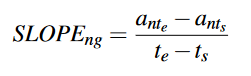
在同一臺服務器上,故障SSD的某些屬性的變化趨勢可能與其他健康SSD有較大差異。因此,對于上述的CVAR、KURT和SLOPE,分別計算它們在一個SSD上的值與同一服務器上其他SSD相同特征的平均值的差值,定義為CVAR _ diff、KURT _ diff、SLOPE _ diff。然后,將所有N個屬性的G個窗口的CVAR、KURT、SLOPE和CVAR _ diff、KURT _ diff、SLOPE _ diff進行拼接,得到N × G × 6的SSD序列相關特征。
4.2 MVTRF
為了學習提取特征的模式,選擇隨機森林作為基模型,原因有三。首先,已有研究證明了隨機森林在SSD失效預測上的良好性能。其次,隨機森林由多棵決策樹組成,每棵決策樹通過對特征的一系列判斷將樣本分為不同的類。其可解釋性較好,有助于通過判斷過程進一步識別失效原因。第三,與神經網絡相關模型相比,隨機森林的計算復雜度更低,有利于減少離線訓練和在線預測過程中的開銷。
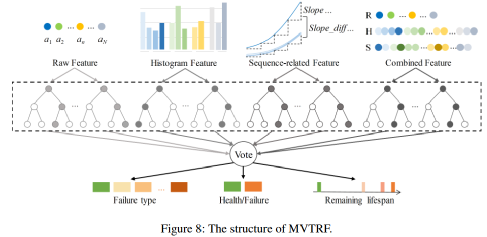
如圖8所示,隨機森林的所有決策樹被平均分為四個集合,分別學習原始特征、直方圖特征、序列相關特征和組合特征。然后,對四個集合的所有決策樹進行投票,得到最終的預測結果。投票最多的類為預測類,投票份額為置信概率。通過這種方式,將來自不同視圖的特征進行組合以獲得最終的判斷。
三個任務的具體定義如下。
1 ) 故障預測。將其定義為二分類任務。將健康SSD和失效SSD的數據分別標記為0和1。
2 ) 故障類型預測。將其定義為多分類任務。健康SSD和失效SSD的數據分別標記為0和1 - O。數據集有8種失效類型,因此O = 8。
3 ) 剩余壽命預測。回歸更適合該任務,但為了與上述兩個任務保持一致,也將其定義為多分類任務。將距離故障一周以上的數據標記為0,距離故障一天到一周的數據標記為1,距離故障一天以內的數據標記為2,距離故障時間前后的數據標記為3。
4.3 原因識別和故障處理
在生產環境中,一些SSD異常實際上可能是由其他設備的故障引起的,例如服務器底板。當預測到故障時,操作員需要了解故障的癥狀和原因,以準確確認設備故障。事實上,使用隨機森林算法的原因之一在于其可解釋性。隨機森林基于決策樹,決策樹本質上是一系列閾值決策。它符合人類的思維,即通過多種判斷的綜合得出最終結果。通過分析決策過程,可以揭示為什么會出現失敗,從而識別失敗的癥狀和原因。然而,隨機森林是多個決策樹的集合,很難分析如此多的決策過程。因此,本文提出相似決策抽取( SDE )方法,從MVTRF中的多棵決策樹中獲取關鍵決策,以反映整體決策過程,發現失效原因。

圖9展示了SDE的工作原理,包括三個步驟。首先,每個決策由于其區分能力被決策樹選擇,提取多個決策樹中出現頻率較高的相似決策作為關鍵決策。兩個決策在滿足以下條件時被認為是相似的:1 )兩個決策的特征和決策邏輯(即≤或>)相同;2 )兩種決策的決策閾值相似,兩個閾值的差值在∝(默認為10 %)內。本文為每個決策在其他決策樹中尋找相似決策,并將相似決策的數量作為該決策的權重。
在計算出所有決策的權重后,第二步是去除冗余的相似決策。借鑒非極大值抑制思想,SDE保留權重較高的決策作為關鍵決策,舍棄權重較低的相似決策。主要過程如下。1 )對所有決策的權重進行排序;2 )從未處理的決策中選擇權重最高的決策;3 )刪除與本決策類似的其他決策;4 )重復上述操作2和操作3,直到所選決策的權重小于全局最高權重的一半。這樣,冗余的相似決策由權重較高的關鍵決策表示。最后,可以將具有相同特征和決策邏輯的關鍵決策的權重進行整合,保留最嚴格的閾值(即>的最大值和≤的最小值)來顯示異常值。
通過SDE提取的關鍵決策可以揭示故障原因,從而有助于確認是否為SSD內部故障。許多故障的關鍵決策涉及SSD內部錯誤(例如,過多的媒體錯誤、壞塊或程序故障),表明SSD發生故障。當關鍵決策涉及通信或環境,如PCI錯誤或溫度時,操作員除了需要檢查SSD外,還需要檢查外部設備(例如背板)或環境。關鍵決策揭示的失效原因能夠顯著提高操作者驗證失效的效率。
五、實驗
5.1 性能對比
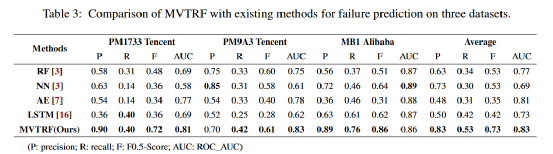
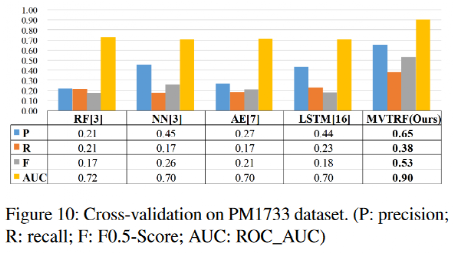
從表3和圖10都可以看出,MVTRF在各個指標上都有著不錯的提升。
5.2 Multi-view特征的討論
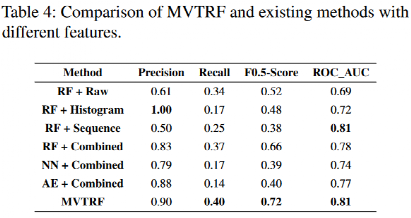
表4展示了在PM1733騰訊數據集上的結果。原始特征關注異常屬性值,易于判斷,因而其召回率相對較高。而短期原始特征無法捕捉到長期信息中的一些失敗癥狀,因此ROC _ AUC最低( 0.69 ),難以發現更多在較低的判別閾值下SSD失效。直方圖特征和序列相關特征反映了長期數據的分布和趨勢,可以發現更多的失敗癥狀,因此它們的ROC _ AUC更高。組合特征包含上述3個特征。由于包含多視角信息,組合特征的RF在各個指標上表現良好。
5.3 多任務學習與預測
在原始特征的基線RF和MVTRF上,評估了多任務學習對每個任務的影響。表5比較了兩種模型在單任務學習和多任務學習下對三種任務的表現。對于失敗預測,通過多任務學習和預測,性能較好,兩個模型的F0.5 - Score平均提高了0.05。
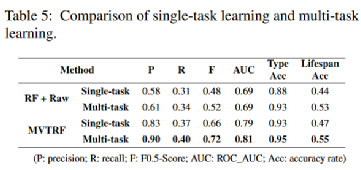
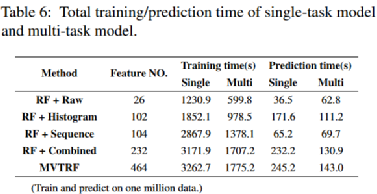
使用單個模型進行多任務學習的另一個好處是,與使用3個模型預測3個任務相比,可以減少模型訓練和預測時間。表6展示了不同特征的維度,并比較了基于這些特征在三個任務上單獨訓練/預測和聯合訓練/預測所需的總時間。表6顯示,在大多數情況下,采用多任務學習可以減少訓練/預測時間。這也說明MVTRF的訓練/預測時間主要取決于維度最高的組合特征的訓練/預測時間。此外,基于多任務學習的MVTRF在三分鐘內完成百萬條遙測數據的預測,能夠完全支持大規模SSD的在線實時預測。
5.4 類似決策抽取
根據MVTRF模型的決策過程,本文提出了SDE來獲取關鍵決策并找到導致失效的原因。表7展示了失效SSD的決策過程中提取的關鍵決策。SDE從總共3825個原始決策中提取出5個關鍵決策并賦予其權重。
將這些關鍵決策重新應用到所有數據中,根據它們引入的誤報來評估它們的有效性。由表7可知,權重最高的決策僅有3次虛警,說明提取的關鍵決策具有較強的區分能力。然后,通過結合后續的關鍵決策來消除所有的虛警。可以得出結論,SDE方法提取的決策是關鍵的,能夠代表主要的決策過程。根據關鍵決策,認為導致該故障的直接原因是介質誤差( media _ error _ slope > 126.44 , media _ error > 6015.5)的快速增加,因此被驗證為SSD的內部故障。此外,溫度的變化和磨損水平的變化可能是(溫度_ kurt < = -1.11 ,磨損_ level _ max _ kurt > -0.047)的潛在影響因素。

本文還從所有失效SSD的判斷過程中提取了幾組關鍵決策來評估關鍵決策的整體判別能力,如表8所示。結果顯示,對于失敗的固態硬盤,共有53,663個決策,而SDE方法提取了49個關鍵決策。將這些關鍵決策重新應用到所有數據中,獲得了與所有原始決策相同的精度和召回率。49個關鍵決策在區分失效SSD和健康SSD上的表現與原始的53,663個決策幾乎相同,說明了所提SDE方法的有效性。然后,基于這些決策可以識別和分析故障原因,為驗證和處理SSD故障奠定基礎。
-
SSD
+關注
關注
21文章
2863瀏覽量
117469 -
存儲系統
+關注
關注
2文章
413瀏覽量
40866
原文標題:MVTRF:多視圖特征預測SSD故障
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺談架空暫態特征型遠傳故障指示器
什么是SSD硬盤 SSD硬盤的優勢和劣勢
SSD故障排查與解決方案
如何選擇適合的SSD SSD和HDD的區別
建筑物邊緣感知和邊緣融合的多視圖立體三維重建方法

特征工程實施步驟

電梯按需維保——“故障預測”算法模型數據分析
分布式故障在線監測|高精度技術選用 行波特征 故診模型
變電站常見故障類型及特征

示波器觀察波形的視圖模式詳解
鋼鐵工廠故障監測告警與預測性維護如何實現
微軟將在6月為Outlook日歷新增分屏視圖,提升工作效率
SCG客戶應用ZETA預測性維護方案,精準發現設備故障





 工商網監
工商網監
評論