 從AI遠見到中國速度:Scaling Law發現者為何引全球熱議?
從AI遠見到中國速度:Scaling Law發現者為何引全球熱議?

從20世紀50年代起,AI技術經歷了70多年的發展。其間多種技術曾占據不同時代的高位,而當時間來到21世紀20年代,抵達我們今天正在經歷的新一輪AI崛起,預訓練大模型毫無疑問就是這個時代的主角。
那么,究竟是誰點燃了這次AI爆發的星星之火,推開了大模型的大門?相信你把這個問題拋給不那么了解AI的朋友,他也會脫口而出:是OpenAI啊。但就像大模型會出現幻覺一樣,最近外網全面熱議的一件事告訴我們,這個答案也可能摻雜了一些幻覺成分。
Scaling Law規模化法則,也被稱為大模型的尺度定律。這一定律揭示了大語言模型的模型性能與其規模、訓練數據集大小,以及訓練資源之間存在著一種可預測的關系。也就是說投入資源越多,模型規模越大,最終的模型效果也就可能越好。從AI模型走向AI大模型,以及采取預訓練機制的必要性都是由此而產生。因此Scaling Law也被業界廣泛認為是模型預訓練的第一性原理。
但就這項核心理論的起源,最近卻有一項討論火爆外網。根據AI大佬爆料,以及《南華早報》等權威媒體的報道,中國科技巨頭百度比OpenAI更早發現了這一原理。這也意味著中國AI在大模型時代的前瞻性探索上可能更為超前。
而“AI突破總來自百度”這一現象的背后,更展示了體系化AI創新的核心價值。如何在全球AI競賽的大背景下,全面釋放出百度的體系化AI創新價值,將是未來中國AI發展的核心課題。

事情的起源是這樣的。11月12日,在Lex Fridman的播客節目中,Anthropic聯合創始人&CEO Dario Amodei探討了Claude、AI模型的擴展規律、AGI、AI未來等多個話題。其中,作為AI領軍人物的Dario Amodei也談到了Scaling Law這個關鍵規律的發現。他提到了他最早發現這個規律,始于此前在百度工作時的相關研究。根據資料顯示,Dario Amodei于2014 年 11 月到2015 年 10 月期間在百度工作,當時他在百度硅谷人工智能實驗室(SVAIL)工作,致力于將深度學習模型擴展到大規模高性能計算系統。
Dario Amodei提到,2014年與吳恩達在百度研究AI的時候,他就已經發現了模型發展的規律Scaling Law,“隨著你給它們提供更多數據,隨著你讓模型變大,隨著你訓練它們的時間越來越長,模型的表現開始越來越好。當時我并沒有精確地衡量,但我和同事們都非常非正式的感覺到,給這些模型的數據越多、計算越多、訓練越多,它們的表現就越好”。
這個說法很快也得到了其他途徑的權威證明。11月27日,Meta研究員、康奈爾大學博士候選人Jack Morris在X上表示,“大多數人不知道,關于Scaling Law的原始研究來自2017年的百度,而不是2020年的OpenAI”。
這個說法的來源是,在百度于2017年發表的論文《DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY》論文當中,已經對Scaling Law做出了詳細研究,并探討了機器翻譯、語言建模等領域的Scaling現象。業內人士認為,這篇論文的重要性被嚴重忽視了。
而透過這次全球AI界的正本清源,我們真正能夠看到的是百度在AI領域的前瞻性與系統化創新能力。很多AI的答案總是由百度來找到,已經成為業界的全新共識。

十年之前,互聯網技術正在持續發展,移動時代正處在高位。當時幾乎沒有哪家科技公司愿意從眼前的利益中抽身,去看看更遙遠的未來。
但如果每家科技企業都固守短期利益,那么當科技拐點到來,下一輪技術突破開啟,整個社會的科技競爭力不足就會暴露出來。我們只能重復一次又一次科技模仿者的角色。
好在百度決定打破這個循環,用預判能力提前點燃AI的星星之火。這種預判性,已經為百度,乃至為整個中國AI領域帶來了極大效益。比如盡管外部剛剛爆料出百度更早發現Scaling Law的信息。但百度早已經基于對Scaling Law的研究和理解,很早就投入到預訓練大模型的工作當中。于是可以在全球第一梯隊發布大模型技術,率先打造投入應用的AIGC產品。
早在2013年1月的百度年會上,李彥宏宣布成立了深度學習研究院,并親自任院長。李彥宏認為,“這應該是全球企業界第一家用深度學習來命名的研究院”。這意味著,在全球大多數科技企業對AI的認知停留在科幻電影的階段,百度已經率先將AI技術作為學術研究與業務落地的發展方向,繼而開始體系化、系統化進行AI創新。
多年以來,百度在硬件、基礎軟件、模型算法、業務落地等維度進行了AI探索。后來的事實也證明,對單項AI技術的投入只能是模仿,只有從源頭上進行體系化研發投入,才能提供源源不斷的AI創新成果。由李彥宏的前瞻性出發,啟動搭建的百度AI系統,讓百度十年來成為AI人才、AI技術與AI基礎設施的策源地。
從人才角度看,全球AI人才看到了百度AI的未來,爭相加入到這個體系中來。比如說2014年,吳恩達加入百度并在研究院首席科學家,擔任百度公司首席科學家,負責百度研究院的領導工作。2014年5月19日,百度宣布任命吳恩達博士為百度首席科學家,全面負責百度研究院。同樣在2014年,Dario Amodei斯坦福博士后畢業后加入百度硅谷AI實驗室。之后,Dario amodei又招募了Jim fan來百度實習。這些人后來都成為AI爆發的全球領軍人物,將百度的AI積淀帶向世界。
從業務發展的角度看,百度在自然語言處理、機器視覺、知識圖譜等領域打下了堅實的技術底座,并率先將AI技術帶到搜索、信息流、地圖、自動駕駛等核心業務,全面迭代了科技行業與AI技術的關系,為未來千行百業的智能化指定了航標。
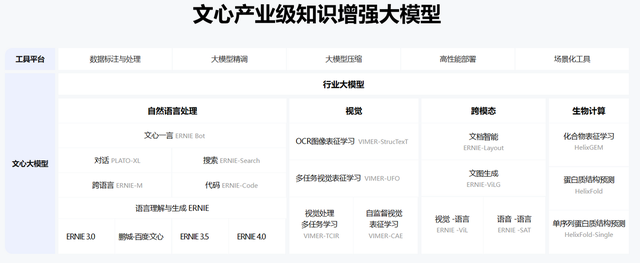
從基礎設施的角度看,百度打造的飛槳+文心大模型體系已經成為AI開發者與產業智能化共同依托的技術底座。目前,飛槳文心開發者數量已達1808萬,服務了43萬家企業,創建了101萬個模型。百度已經成為AI模型與AI開發者的搖籃。
不至Scaling Law,百度在AI領域點燃了無數星星之火。它們燃燒盛放,成為中國AI在全球賽場上的動力引擎。

時間來到今天,預訓練大模型驅動全球新一輪科技革命。在這個階段當中,百度憑借跨越十年的AI洞見,以及由此打造的體系化AI創新,全面提升了中國AI的發展加速度。
比如說,百度在2019年發布了第一代文心大模型,幾乎與OpenAI處于同一時期;2023年,百度是全球第一家推出生成式AI產品的科技大廠,讓中國用戶有了與無時間差的AI革命體驗。
今天,百度文心大模型日調用量已經超過15億。對比今年5月2億的日調用量,半年時間達到了原來的7.5倍,對比一年前5000萬的日調用量,達到了30倍。文心已經真正成為中國預訓練大模型的底牌與王炸。
而把百度的前瞻能力與體系化AI創新,放在更大的全球科技競賽背景中看,會發現其有著極其深遠的意義。
日前,外媒Axios援引知情人士消息,美國候選總統特朗普計劃任命一位人工智能部長(AI czar),以協調聯邦政策和政府對新興技術的使用。“AI部長”將在集中公共和私人資源方面發揮作用,確保美國在全球范圍內占有人工智能發展的領先地位。這預示著特朗普下一個任期內AI技術發展將加速迎來變局。AI對于社會經濟、國家戰略的意義正被推升到史無前例的高度。
在全球AI競賽的必然趨勢下,百度的深入積累的AI技術路徑、研究方法與工程化實踐、應用探索,都將成為未來中國AI加速度的來源。
如何透過Scaling Law的全球熱議,看清百度AI基座的不可替代性,并將這種價值應用在未來必將發生的AI競賽中,將是中國AI接下來一個深刻且富有想象力的命題。

審核編輯 黃宇
-
AI
+關注
關注
87文章
31000瀏覽量
269331 -
大模型
+關注
關注
2文章
2476瀏覽量
2814
發布評論請先 登錄
相關推薦
行芯亮相2024中國AI芯片開發者論壇
2024深圳 | 中國AI芯片開發者論壇

OpenAI開啟推理算力新Scaling Law,AI PC和CPU的機會來了
多項AI新成果發布,涂鴉智能引領全球開發者共繪GenAI發展藍圖

浪潮信息趙帥:開放計算創新 應對Scaling Law挑戰

RISC-V在中國的發展機遇有哪些場景?
全球智慧領袖共襄2024 TUYA全球開發者大會,開啟智慧商業新紀元
全球智慧領袖共襄2024 TUYA全球開發者大會,開啟智慧商業新紀元

2024 TUYA全球開發者大會盛大啟幕,Cube AI大模型重磅首發!
2024 TUYA全球開發者大會盛大啟幕,Cube AI大模型重磅首發!

王力新一代AI靈犀系列旗艦新品震撼發布,遙感技術3.0引行業熱議!
華為Pura70 Ultra手機AI消除功能引公眾熱議
吉利多款轎車與小米SU7撞期,引行業熱議,楊學良發聲
機構預測:今年全球AI服務器數量可超160萬臺,增長40%






 工商網監
工商網監
評論