 一種新的通用視覺主干模型Vision Mamba
一種新的通用視覺主干模型Vision Mamba
Vision Mamba
最具潛力的下一代通用視覺主干網絡
CNN和Transformer常作為深度學習模型的首選基礎模塊,被應用于各種場景,如文本、視覺、語音信號處理及其各種下游應用。然而這兩個基礎模塊都有著其固有而互補的缺陷:CNN具有固定大小窗口的卷積核,使其計算量為線性,但也由此而面臨著窗口化局部感受野的缺陷,使其在全局場景感知和場景語義理解上之力;Transformer通過全局的注意力計算,使其具有長上下文的全局感知能力,但其二次方復雜度的計算量使得在算力有限的端側設備上運行變得很困難。
針對這一問題,我們提出了VisionMamba,來打破線性復雜度與全局感受野不可兼得的困境。基于自然語言處理中的Mamba狀態空間模型SSM,我們設計了雙向SSM,并引I入了位置編碼來專門處理具有二維多向性的視覺信號。在各種分類、檢測、分割任務中,Vim相比現有的視覺Transformer在精度上具有顯著提升,同時在計算和內存效率上也有顯著改進。例如,在進行分辨率為1248x1248的批量推理時,Vim比DeiT快2.8倍,GPU內存節省86.8%
? Vision Mamba 論文鏈接:
https://arxiv.org/abs/2401.09417
? 項目主頁:
https://github.com/hustvl/Vim
簡介
本文的工作Vision Mamba[1]發表在ICML 2024。研究的問題是如何設計新型神經網絡來實現高效的視覺表示學習。該任務要求神經網絡模型能夠在處理高分辨率圖像時既保持高性能,又具備計算和內存的高效性。先前的方法主要依賴自注意力機制來進行視覺表示學習,但這種方法在處理長序列時速度和內存使用上存在挑戰。論文提出了一種新的通用視覺主干模型Vision Mamba,簡稱Vim1,該模型使用雙向狀態空間模型(SSM)對圖像序列進行位置嵌入,并利用雙向SSM壓縮視覺表示。在ImageNet[2]分類、COCO[2]目標檢測和ADE20k[3]語義分割任務中,Vim相比現有的視覺Transformer[4](如DeiT[5])在性能上有顯著提升,同時在計算和內存效率上也有顯著改進。例如,在進行分辨率為1248×1248的批量推理時,Vim比DeiT快2.8倍,GPU內存節省86.8%。這些結果表明,Vim能夠克服在高分辨率圖像理解中執行Transformer樣式的計算和內存限制,具有成為下一代視覺基礎模型主干的潛力。
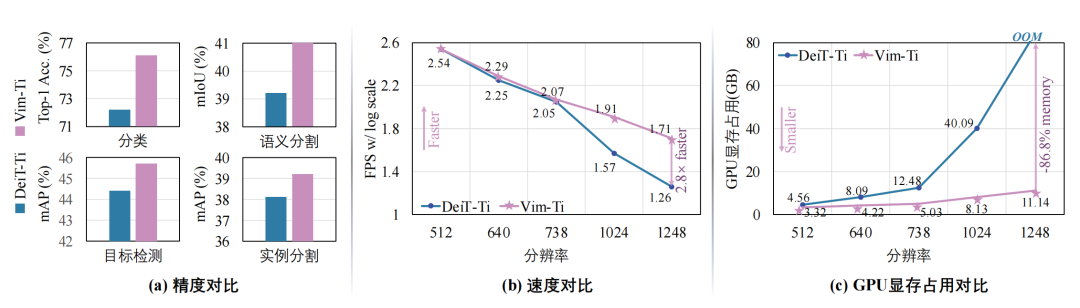
圖1 本文所提出的Vision Mamba (Vim)和基于Transformer的DeiT模型進行精度與效率對比:Vim在圖像分類、目標檢測、語義分割、實例分割任務上獲得了更好的精度,且在高清分辨率圖像處理上呈現出巨大的優勢。
研究背景
圖像表示學習是計算機視覺領域的重要研究課題,其目的是通過模型學習從圖像中提取有意義的特征,從而應用于各種視覺任務中。目前,視覺Transformer(Vision Transformer, ViT[4])和卷積神經網絡(Convolutional Neural Networks, CNNs)是圖像表示學習中最常用的方法。然而,這些方法在理論上存在一些局限性。
視覺Transformer利用自注意力機制能夠取得全局的感受野,在大規模自監督預訓練和下游任務中表現出色,但其自注意力機制在處理長序列依賴和高分辨率圖像時,帶來了計算和內存的巨大開銷。具體而言,自注意力機制的計算復雜度是輸入的圖像塊序列長度的平方,這使得其在處理高分辨率圖像時非常耗時且占用大量內存。盡管一些研究提出了改進方法,如窗口注意力機制[6,7],但這些方法雖然降低了復雜度,但導致感受野被局限在局部的窗口內部,失去了原本全局感受野的優勢。
另一方面,卷積神經網絡在處理圖像時,通過使用固定大小的卷積核來提取局部特征。然而,卷積神經網絡在捕捉全局上下文信息方面存在局限性,因為卷積核的感受野是有限的,雖然一些研究引入了金字塔結構或大卷積核來增強全局信息提取能力,但這些改進仍然無法完全克服CNN在處理長序列依賴方面的不足。
在自然語言處理領域,Mamba[11]方法的出現給高效率長序列建模帶來了很好的發展契機。Mamba是狀態空間模型(state space model, SSM)方法的最新演進。Mamba提出了一種輸入自適應的狀態空間模型,能夠更高質量地完成序列建模任務。與此同時,該方法在處理長序列建模問題時有著次二次方的復雜度與更高的處理效率。然而,Mamba方法并不能夠直接應用于視覺表征學習,因為Mamba方法是為自然語言領域的因果建模而設計的,它缺少對于二維空間位置的感知能力以及缺少全局的建模能力。
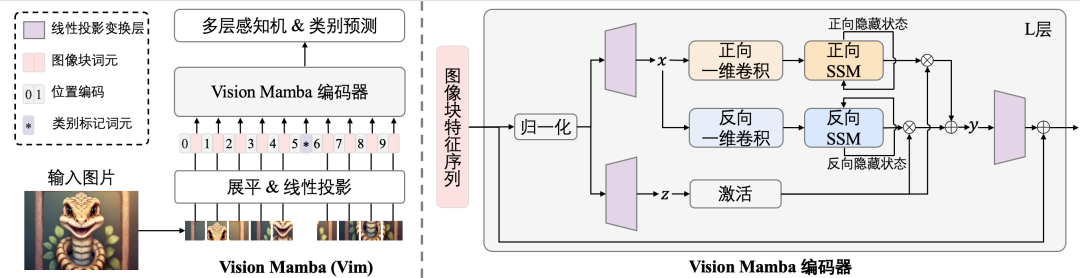
圖2 本文所提出的Vim模型的網絡構架圖。
為了克服上述Transformer和CNN的理論局限性,啟發于自然語言處理領域Mamba的成功,本文提出了一種新的通用視覺主干模型——Vision Mamba (Vim)。該模型基于狀態空間模型[10](State Space Models, SSMs),利用其在長序列建模中的高效性,提供了一種新的視覺表示學習方法。該模型提出了雙向狀態空間模型來適配視覺特征的多方向性,并引入位置編碼來針對圖像單元進行標記。本文提出的Vim模型通過雙向SSM對圖像序列進行位置嵌入和壓縮,不僅在ImageNet分類任務上表現出色,還在COCO目標檢測和ADE20k語義分割任務中展示了優異的性能。與現有的視覺Transformer如DeiT相比,Vim在計算和內存效率上有顯著提升。
Vision Mamba方法介紹
“
狀態空間模型
狀態空間模型,比如結構化狀態空間序列模型[10](S4)和Mamba[11]是啟發于連續系統,該系統通過隱藏狀態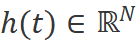 將一維函數或序列
將一維函數或序列 映射到
映射到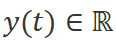 。該系統使用
。該系統使用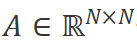 作為演化參數,并使用
作為演化參數,并使用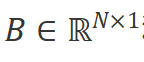 和
和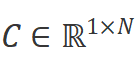 作為投影參數。連續系統的工作方式如下: ?
作為投影參數。連續系統的工作方式如下: ?
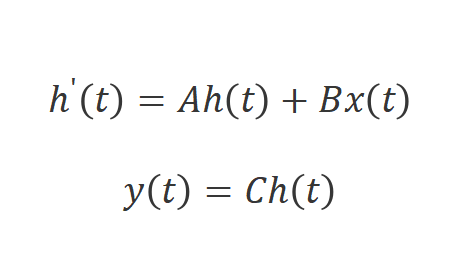
S4和Mamba是連續系統的離散版本,它們包含一個時間尺度參數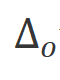 ,用于將連續參數A和B轉換為離散參數
,用于將連續參數A和B轉換為離散參數
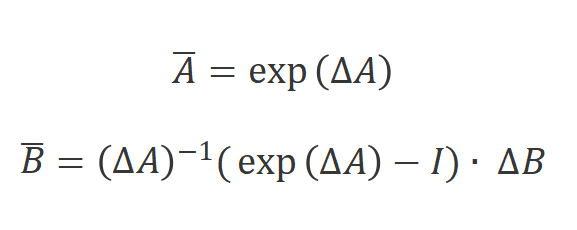
和
。常用的方式是零階保持,其定義如下:
將
和
離散化后,使用步長的離散版本可以重寫為:
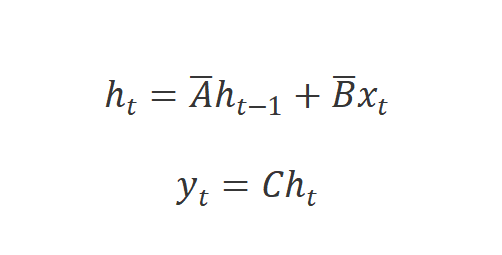
最后,模型可以使用全局的卷積來并行的計算:
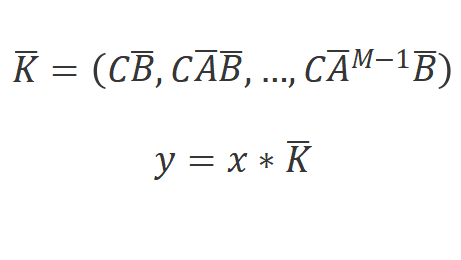
其中

是輸入序列
的長度,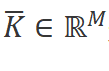 是結構化的卷積核。 ?
是結構化的卷積核。 ?
“
Vision Mamba結構
所提出的Vision Mamba如圖1所示。標準的Mamba模塊是為一維的文本序列所設計的。為了適配視覺信號,我們首先將二維圖像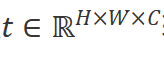 轉換為展平的二維圖像塊序列
轉換為展平的二維圖像塊序列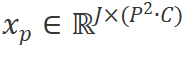 ,其中
,其中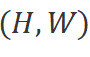 是輸入圖像的尺寸,C是通道數,P是圖像塊的尺寸。接下來,我們將
是輸入圖像的尺寸,C是通道數,P是圖像塊的尺寸。接下來,我們將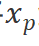 線性投影到大小為D的向量,并添加位置編碼
線性投影到大小為D的向量,并添加位置編碼
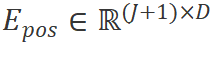
,如下所示:
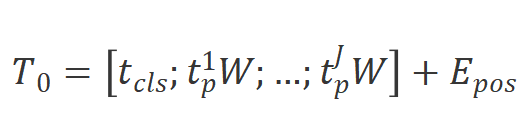
其中

是
中的第
個圖像塊,
是可學習的投影變換矩陣。受ViT[4]的啟發,我們也使用類別標記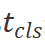 來表示整個圖像塊序列。然后,我們將標記序列
來表示整個圖像塊序列。然后,我們將標記序列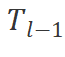 輸入到Vim編碼器的第
輸入到Vim編碼器的第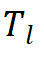 層,并得到輸出。最后我們對輸出類別標記
層,并得到輸出。最后我們對輸出類別標記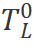 進行歸一化,并將其送入多層感知機(MLP)分類頭以獲得最終類別預測
進行歸一化,并將其送入多層感知機(MLP)分類頭以獲得最終類別預測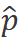 :
:
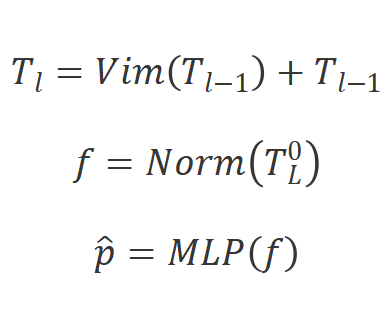
其中Vim是提出的視覺Mamba模塊,

是層數,
是歸一化層。
算法1:Vim模塊流程
輸入:圖像塊序列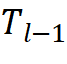
輸出:圖像塊序列

“
Vim模塊
原始的Mamba模塊是為一維序列設計的,不適用于需要空間感知理解的視覺任務。我們創新性提出Vision Mamba編碼的基本構建模塊Vim模塊,如圖2右側所示。具體來說,像我們在算法1中所展示的操作。輸入的標記序列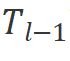 首先通過歸一化層進行歸一化。接下來,我們將歸一化后的序列線性投影到維度大小為
首先通過歸一化層進行歸一化。接下來,我們將歸一化后的序列線性投影到維度大小為 的
的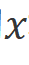 和
和 。然后,我們從前向和后向兩個方向處理
。然后,我們從前向和后向兩個方向處理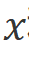 。對于每個方向,我們首先對進行一維卷積,得到
。對于每個方向,我們首先對進行一維卷積,得到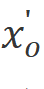 。然后,我們將線性投影到
。然后,我們將線性投影到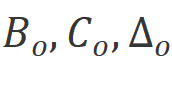 。然后用于分別離散化得到
。然后用于分別離散化得到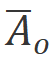 和
和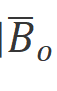 。最后我們通過SSM計算前向輸出
。最后我們通過SSM計算前向輸出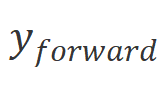 和反向輸出
和反向輸出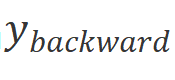 ,并通過進行門控,并加在一起得到輸出標記序列。 ?
,并通過進行門控,并加在一起得到輸出標記序列。 ?
“
效率優化
Vim通過借助于Mamba的硬件友好的實現方式確保運行的效率。優化的關鍵思想是避免GPU的I/O瓶頸和內存瓶頸。
IO高效性。高帶寬存儲器(HBM)和SRAM是GPU的兩個重要組成部分。其中,SRAM具有更大的帶寬,而HBM具有更大的存儲容量。標準的Vim的SSM操作在HBM上需要的I/O數量是O(BMEN),其中B為批量大小,M為圖像塊序列長度,E 表示擴展狀態維度,N 表示 SSM 維度。受到Mamba的啟發,Vim首先將O(BME+EN)字節的內存從較慢的HBM讀取到較快的SRAM中。然后Vim在SRAM中獲取對應的參數,并執行SSM操作,最終將輸出結果寫回HBM。此方法可以講I/O數量從O(BMEN)降低到O(BME+EN)從而大幅度提升效率。
內存高效性。為了避免內存不足問題并在處理長序列時降低內存使用,Vim選擇了與 Mamba 相同的重計算方法。對于尺寸為 (B.M,E,N)的中間狀態來計算梯度,Vim在網絡的反向傳遞中重新計算它們。對于激活函數和卷積的中間激活值,Vim 也重新計算它們,以優化 GPU 的內存需求,因為激活值占用了大量內存,但重新計算速度很快。
計算高效性。Vim模塊中的SSM算法和Transformer中的自注意力機制都在自適應地提供全局上下文方面起到了關鍵作用。給定一個視覺序列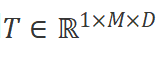 和默認的設置
和默認的設置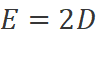 。全局注意力機制和SSM的計算復雜度分別為:
。全局注意力機制和SSM的計算復雜度分別為:
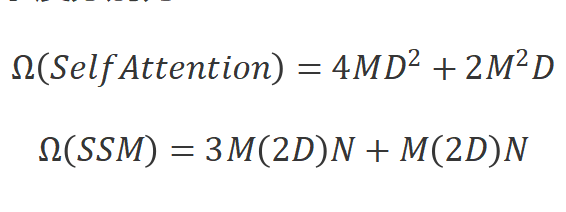
其中,自注意力機制的計算復雜度和序列長度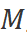 成平方關系,而SSM的計算復雜度和序列長度呈線性關系。這種計算效率使得Vim在處理具有長序列長度的千兆像素級別應用時具有良好的擴展性。
成平方關系,而SSM的計算復雜度和序列長度呈線性關系。這種計算效率使得Vim在處理具有長序列長度的千兆像素級別應用時具有良好的擴展性。
實驗結果
該方法在標準的大型圖片分類數據集ImageNet-1K上進行驗證。并將分類訓練好的模型作為預加載權重用于下游圖片密集型預測任務中去,如COCO數據集上的目標檢測和實力分割任務, ADE20K上的像素級別的語義分割任務。
“
分類對比
如表1與當前主流的分類模型對比Vim顯示出了相當的精度,將Vim和基于CNN、Transformer和SSM的主干網絡進行比較,Vim顯示了相當甚至更優的性能。例如,在參數量相同的情況下Vim-Small的準確率80.3%,比ResNet50[12]高出了4.1個百分點。與傳統的基于自注意力機制的ViT[4]相比,Vim在參數數量和準確率上均有顯著提升。與視覺Transformer ViT高度優化的變種DeiT相比,Vim在不同模型尺度上均以相似的參數數量取得了更好的精度。
如圖1所示,Vim的優越的效率足以支持更細粒度的微調,在通過細粒度微調后,與基于SSM的S4ND-ViT-B[13]相比,Vim在參數數量減小3倍的情況下達到了相似的精度,Vim-Ti+,Vim-S+和Vim-B+的結果均有所提高。其中,Vim-S+甚至達到了與DeiT-B相似的效果。
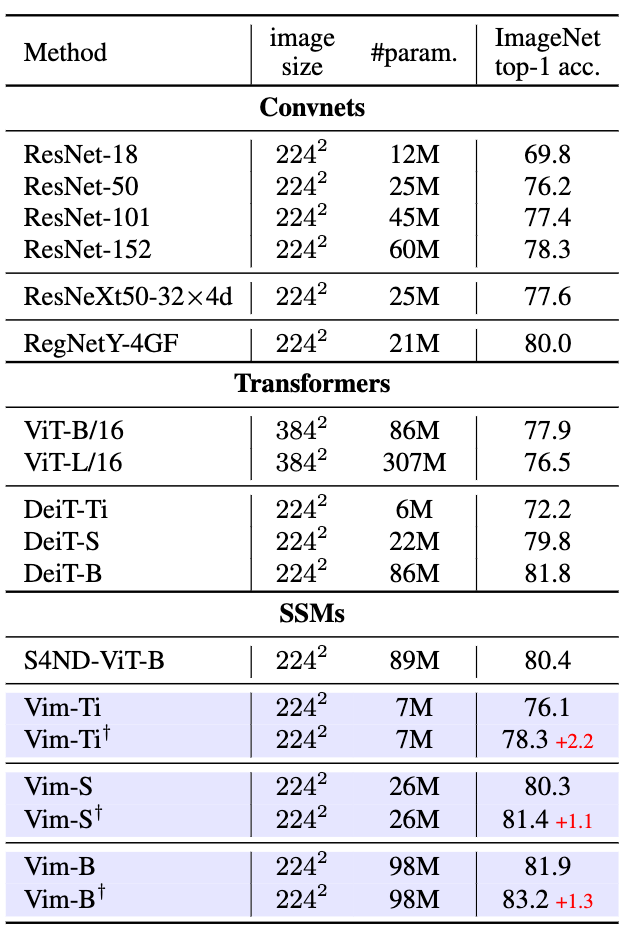
表1ImageNet-1K分類骨干網絡對比
“
語義分割對比
在ADE20K語義分割數據集上,我們將ImageNet-1K上訓練好的權重加載到UperNet[14]分割器中,使用Vim作為骨干網絡進行特征提取,如表3所示,Vim取得了相比于CNN網絡ResNet更少的參數量以及更高的精度,去Transformer模型DeiT相比,Vim取得了更優的精度。
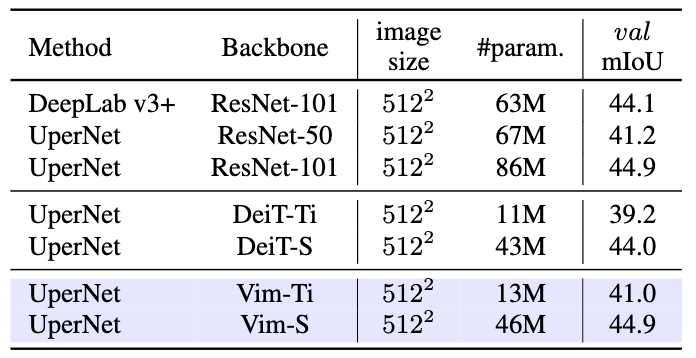
表2ADE20k語義分割對比
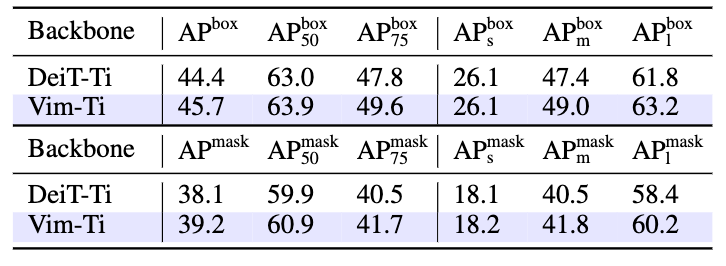
表3 COCO目標檢測和實例分割對比
“
目標檢測與實例分割對比
在COCO目標檢測與實例分割數據集上,我們將ImageNet-1K上訓練好的權重加載到Cascade-RCNN框架中,使用Vim作為骨干網絡進行特征提取,如表3所示,Vim取得相對于Transformer的DeiT更好的檢測框精度和實例分割精度。值得注意的是,在高清圖像輸入的目標檢測任務上,圖像輸入分辨率為1024×1024,由于Transformer的平方復雜度,需要將自注意力機制限制在固定大小的窗口內, 而Vim得意于其線性復雜度,無需窗口化,可以進行全局的視覺特征感知,從而取得了相對于表3中窗口化DeiT更好的精度。
“
消融實驗
雙向SSM。如表4所示,雙向SSM相較于原本的單向SSM取得了更高的分類精度, 且在下游的密集型預測任務上取得更為顯著的優勢。這一結果顯示了本文提出的雙向設計對于視覺特征學習的必要性與重要性。
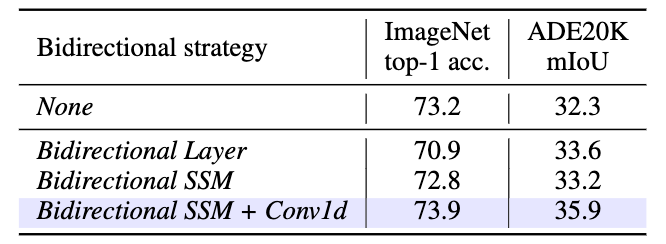
表4 雙向SSM建模消融實驗
分類策略。在表5中,我們探索了以下幾種分類策略:
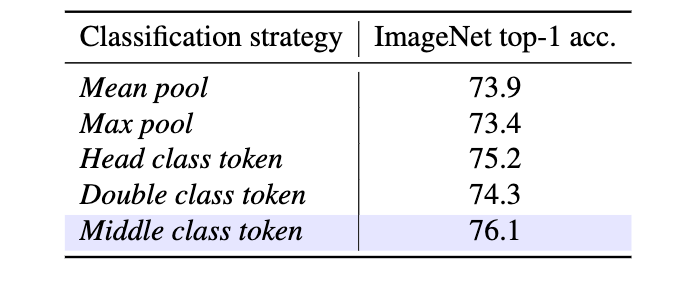
表5 分類策略消融實驗
·Mean pool,將最后Vision Mamba編碼器輸出的特征進行平均池化。
·Max pool,將最后Vision Mamba編碼器輸出的特征進行最大化池化。
·Head class token,將類別標記詞元置于圖像塊序列頭部。
·Double class token,將類別標記詞元置于圖像塊序列兩端。
·Middle class token,將類別標記詞元置于圖像塊序列中間。
如表5所示,實驗結果表明,中間類別標記策略能夠充分利用SSM的循環特性和ImageNet中的中心對象先驗,展示了最佳的top-1準確率76.1。
總結
該論文提出了Vision Mamba (Vim),以探索最新的高效狀態空間模型Mamba作為通用視覺主干網絡。與以往用于視覺任務的狀態空間模型采用混合架構或等效的全局二維卷積核不同,Vim以序列建模的方式學習視覺表示,并未引入圖像特定的歸納偏置。得益于所提出的雙向狀態空間建模,Vim實現了數據依賴的全局視覺上下文,并具備與Transformer相同的建模能力,同時計算復雜度更低。受益于Mamba的硬件感知設計,Vim在處理高分辨率圖像時的推理速度和內存使用顯著優于ViTs。在標準計算機視覺基準上的實驗結果驗證了Vim的建模能力和高效性,表明Vim具有成為下一代視覺主干網絡的巨大潛力。
-
網絡
+關注
關注
14文章
7580瀏覽量
88928 -
模型
+關注
關注
1文章
3260瀏覽量
48911 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13579 -
地平線
+關注
關注
0文章
346瀏覽量
14968
原文標題:地平線Vision Mamba:超越ViT,最具潛力的下一代通用視覺主干網絡
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LabVIEW Vision Assistant的圖像處理,NI視覺助手教程免費閱讀
視頻教程-創建labveiw視覺通用平臺(一)采集攝像頭圖像Uni-vision@qq.com
用 NI Vision Development Module(VDM)視覺開發模塊 還是用 NI Vision Assistant視覺助手?
還在為非標項目單獨開發視覺軟件?你out了!labview通用視覺框架,真香!
一種基于檢索頻度的網格資源描述模型
一種改進的視覺詞袋方法
一種融合視覺詞匯空間信息的主題模型
微軟視覺語言模型有顯著超越人類的表現
Transformer迎來強勁競爭者 新架構Mamba引爆AI圈!

微軟發布PhI-3-Vision模型,提升視覺AI效率
用Ollama輕松搞定Llama 3.2 Vision模型本地部署

Mamba入局圖像復原,達成新SOTA
港大提出SparX:強化Vision Mamba和Transformer的稀疏跳躍連接機制

地平線ViG基于視覺Mamba的通用視覺主干網絡





 工商網監
工商網監
評論