") Facebook發(fā)布高性能AI代碼
Facebook發(fā)布高性能AI代碼
Facebook今天宣布發(fā)布Tensor Comprehensions,能夠自動(dòng)將數(shù)學(xué)符號(hào)快速轉(zhuǎn)換成高性能機(jī)器學(xué)習(xí)代碼,將原本幾天乃至幾周的過程縮短為幾分鐘,大幅提高生產(chǎn)力。
Facebook AI Research(FAIR)今天宣布發(fā)布Tensor Comprehensions,這是一個(gè)C++庫和數(shù)學(xué)語言,旨在幫助彌合研究人員和工程師在從事機(jī)器學(xué)習(xí)任務(wù)時(shí),在溝通上的差距;研究人員習(xí)慣使用數(shù)學(xué)運(yùn)算,而工程師則專注在不同的硬件后端運(yùn)行大規(guī)模ML模型的實(shí)際需求。
相比其他庫,Tensor Comprehensions 的主要不同是對(duì)Just-In-Time編譯有獨(dú)特的研究,能夠自動(dòng)按需生成機(jī)器學(xué)習(xí)社區(qū)需要的高性能代碼。
只需幾分鐘生成高性能CPU/GPU代碼,生產(chǎn)力實(shí)現(xiàn)數(shù)量級(jí)提高
要?jiǎng)?chuàng)建新的高性能機(jī)器學(xué)習(xí)(ML)層,典型的工作流程一般包含兩個(gè)階段,時(shí)間往往需要好幾天乃至數(shù)周:
1、首先,一位研究人員在numpy級(jí)別的抽象中編寫了一個(gè)新的層,并將其與像PyTorch這樣的深度學(xué)習(xí)庫鏈接起來,然后在小規(guī)模實(shí)驗(yàn)中對(duì)其進(jìn)行測試。想法得到驗(yàn)證后,相關(guān)的代碼,性能需要加快一個(gè)數(shù)量級(jí)才能運(yùn)行大規(guī)模實(shí)驗(yàn)。
2、接下來,一位工程師為GPU和CPU編寫高效代碼,而這又需要:
這名工程師需要是高性能計(jì)算的專家,這方面人才數(shù)量有限
這名工程師需要獲取上下文,制定策略,編寫和調(diào)試代碼
將代碼移到后端需要進(jìn)行一些枯燥但必須完成的任務(wù),例如反復(fù)進(jìn)行參數(shù)檢查和添加Boilerplate集成代碼
因此,在過去的幾年中,深度學(xué)習(xí)社區(qū)在很大程度上都依靠CuBLAS,MKL和CuDNN等高性能庫來獲得GPU和CPU上的高性能代碼。不使用這些庫提供的原語來進(jìn)行試驗(yàn),需要極高的工程水平,這對(duì)不少研究人員都構(gòu)成了很大的挑戰(zhàn)。
如果有套件能夠?qū)⑸鲜鲞^程從幾周縮短為幾分鐘,我們預(yù)期,將這樣一個(gè)套件開源將具有重大實(shí)用價(jià)值。有了Tensor Comprehensions,我們的愿景是讓研究人員用數(shù)學(xué)符號(hào)寫出他們的想法,這個(gè)符號(hào)自動(dòng)被我們的系統(tǒng)編譯和調(diào)整,結(jié)果就是具有良好性能的專用代碼。
在這次發(fā)布的版本中,我們將提供:
表達(dá)一系列不同機(jī)器學(xué)習(xí)概念的數(shù)學(xué)符號(hào)
用于這一數(shù)學(xué)符號(hào)的基于Halide IR的C++前端
基于Integer Set Library(ISL)的多面體Just-in-Time(JIT)編譯器
基于進(jìn)化搜索的多線程、多GPU自動(dòng)調(diào)節(jié)器
使用高級(jí)語法編寫網(wǎng)絡(luò)層,無需明確如何運(yùn)行
最近在高性能圖像處理領(lǐng)域很受歡迎的一門語言是Halide。Halide使用類似的高級(jí)函數(shù)語法來描述圖像處理流水線,然后在單獨(dú)的代碼塊中,明確將其調(diào)度(schedule)到硬件上,詳細(xì)指定運(yùn)算如何平鋪、矢量化、并行和融合。這對(duì)于擁有架構(gòu)專業(yè)知識(shí)的人來說,是一種非常高效的語言,但對(duì)于大多數(shù)機(jī)器學(xué)習(xí)從業(yè)者卻很難使用。目前有很多研究積極關(guān)注Halide的自動(dòng)調(diào)度(Automatic scheduling),但對(duì)于在GPU上運(yùn)行的ML代碼,還沒有很好的解決方案。
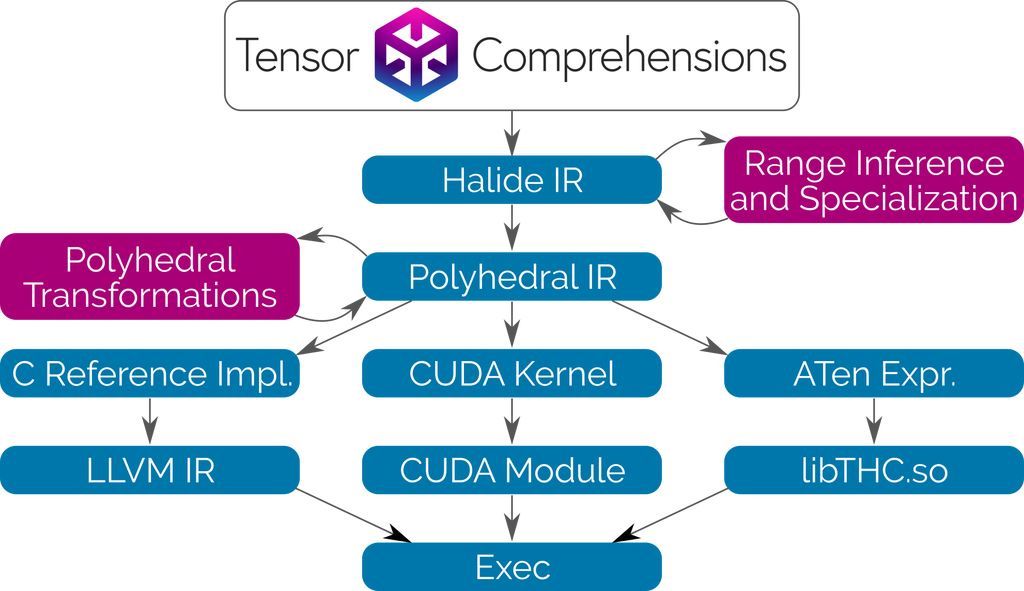
Tensor Comprehensions使用Halide編譯器作為庫。在Halide的中間表示(IR)和分析工具的基礎(chǔ)上,將其與多面體編譯技術(shù)相結(jié)合,使用者可以用類似的高級(jí)語法編寫網(wǎng)絡(luò)層,而無需明確它將如何運(yùn)行。我們還成功使語言更加簡潔,無需指定減法(reduction)的循環(huán)邊界。

Tensor Comprehensions使用Halide和Polyhedral Compilation 技術(shù),自動(dòng)合成CUDA內(nèi)核。這種轉(zhuǎn)換會(huì)為通用算子融合、快速本地內(nèi)存、快速減法和JIT類型特化進(jìn)行優(yōu)化。由于沒有或者沒有去優(yōu)化內(nèi)存管理,我們的流程可以輕松高效地集成到任何ML框架和任何允許調(diào)用C++函數(shù)的語言中。
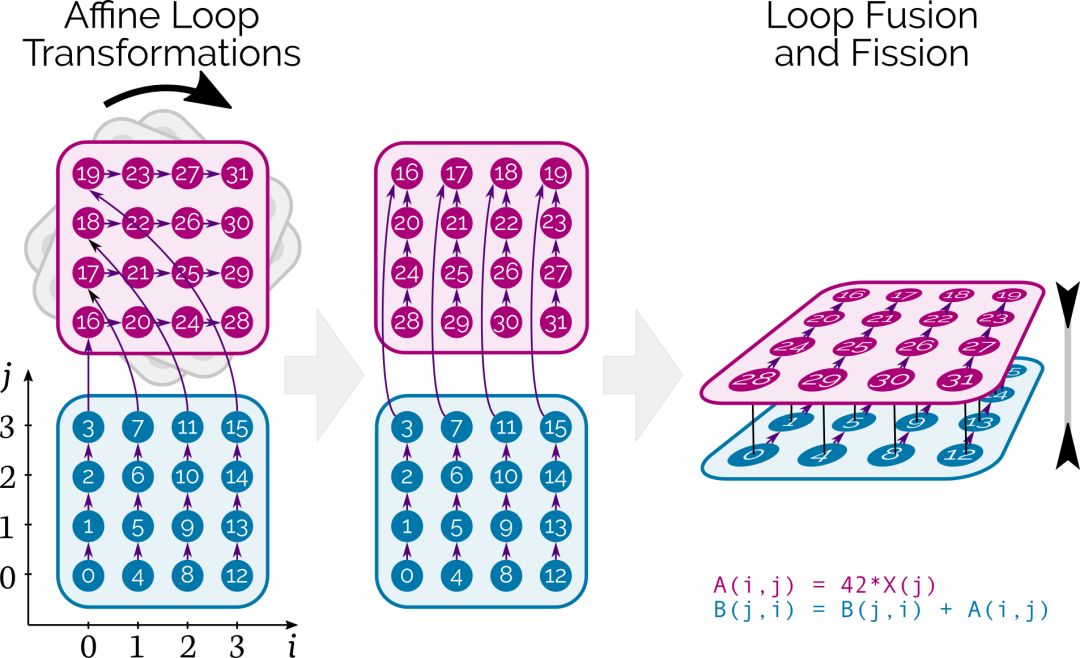
與傳統(tǒng)的編譯器技術(shù)和庫的方法相反,多面編譯(Polyhedral Compilation)讓Tensor Comprehensions為每個(gè)新網(wǎng)絡(luò)按需調(diào)度單個(gè)張量元素的計(jì)算。
在CUDA層面,Tensor Comprehensions結(jié)合了affine loop transformations,fusion/fission和自動(dòng)并行處理,同時(shí)確保數(shù)據(jù)在存儲(chǔ)器層次結(jié)構(gòu)中正確移動(dòng)。
圖中的數(shù)字表示最初計(jì)算張量元素的順序,箭頭表示它們之間的依賴關(guān)系。在這個(gè)例子中,數(shù)字旋轉(zhuǎn)對(duì)應(yīng)loop interchange,深度算子融合就發(fā)生在這個(gè)過程中。
性能媲美乃至超越Caffe2+cuBLAS
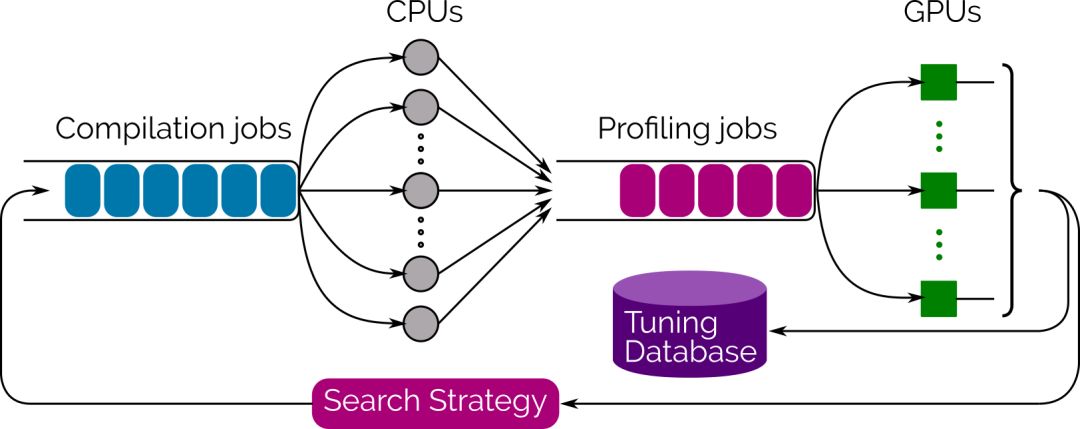
為了推動(dòng)搜索過程,我們還提供了一個(gè)集成的多線程、多GPU自動(dòng)調(diào)諧庫(autotuning library),它使用Evolutionary Search來生成和評(píng)估數(shù)千種實(shí)現(xiàn)方案,并從中選擇性能最佳的方案。只需調(diào)用Tensor Comprehension的tune函數(shù),你就能實(shí)時(shí)地看著性能提高,到你滿意時(shí)停止即可。最好的策略是通過protobuf序列化,立即就可重用,或在離線情況下。
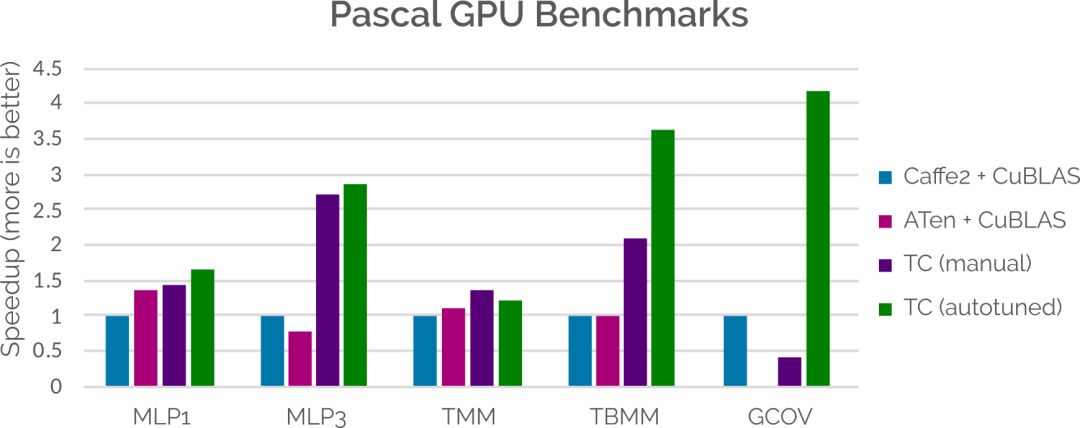
在性能方面,盡管我們還有很多需要改進(jìn)的地方,但在某些情況下,Tensor Comprehensions 已經(jīng)可以媲美甚至超越當(dāng)前整合了手動(dòng)調(diào)整庫的ML框架。這主要通過將代碼生成策略適應(yīng)特定問題大小的能力來實(shí)現(xiàn)的。下面的條形圖展示了將Tensor Comprehensions自動(dòng)生成的內(nèi)核與Caffe2和ATen(使用CuDNN)相比較時(shí)的結(jié)果。更多信息,請(qǐng)參閱論文(見文末鏈接)。
隨著我們擴(kuò)大至更多硬件后端,Tensor Comprehensions將補(bǔ)充硬件制造商(如NVIDIA和Intel)編寫的速度很快的庫,并將與CUDNN,MKL或NNPack等庫一起使用。
未來計(jì)劃
這次發(fā)布的版本將讓研究人員和程序員用與他們?cè)谡撐闹惺褂玫臄?shù)學(xué)語言來編寫網(wǎng)絡(luò)層,并簡明地傳達(dá)他們程序的意圖。同時(shí),研究人員還能在幾分鐘之內(nèi)將他們的數(shù)學(xué)符號(hào)轉(zhuǎn)化成能夠快速實(shí)施的代碼。隨著工具鏈的不斷增長,我們預(yù)計(jì)可用性和性能將會(huì)增加,并使整個(gè)社區(qū)受益。
我們將在稍后發(fā)布PyTorch的Tensor Comprehensions集成。
我們感謝與框架團(tuán)隊(duì)的頻繁交流和反饋,并期待著將這一令人興奮的新技術(shù)帶入你最喜愛的ML框架。
FAIR致力于開放科學(xué)并與機(jī)器學(xué)習(xí)社區(qū)合作,進(jìn)一步推動(dòng)AI研究。Tensor Comprehensions(已經(jīng)在Apache 2.0協(xié)議下發(fā)布)已經(jīng)是Facebook,Inria,蘇黎世聯(lián)邦理工學(xué)院和麻省理工學(xué)院的合作項(xiàng)目。目前工作還處于早期階段,我們很高興能夠盡早分享,并期望通過社區(qū)的反饋來改進(jìn)它。
-
機(jī)器人
+關(guān)注
關(guān)注
211文章
28620瀏覽量
207929 -
AI
+關(guān)注
關(guān)注
87文章
31442瀏覽量
269836 -
代碼
+關(guān)注
關(guān)注
30文章
4820瀏覽量
68882
原文標(biāo)題:【AI大紅包】Facebook發(fā)布張量理解庫,幾分鐘自動(dòng)生成ML代碼
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
廣和通發(fā)布Fibocom AI Stack,助力客戶快速實(shí)現(xiàn)跨平臺(tái)跨系統(tǒng)的端側(cè)AI部署

廣和通發(fā)布Fibocom AI Stack,助力客戶快速實(shí)現(xiàn)跨平臺(tái)跨系統(tǒng)的端側(cè)AI部署
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應(yīng)用
國芯科技與賽昉科技合作,高性能AI MCU芯片CCR7002測試成功
賽昉聯(lián)合國芯推出高性能AI MCU芯片,實(shí)現(xiàn)RISC-V+AI新應(yīng)用

德晟達(dá)推出高性能醫(yī)療專用AI一體機(jī)
國芯科技:高性能AI MCU芯片CCR7002內(nèi)部測試成功
國芯科技攜手賽昉科技發(fā)布高性能AI MCU芯片
使用AMD Versal AI引擎加速高性能DSP應(yīng)用
AI高性能計(jì)算平臺(tái)是什么
銘瑄發(fā)布高性能800系列主板
GPU高性能服務(wù)器配置
SiFive發(fā)布MX系列高性能AI加速器IP
基于瑞薩RZ/V2H AI微處理器的解決方案:高性能視覺AI系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論