 AVA新技術讓劇照清晰又好看
AVA新技術讓劇照清晰又好看
電影、劇集等視頻的創作、生產、分銷等環節已經可以通過算法優化提升效率。Netflix的AVA平臺可以自動的甄選最有代表性的劇照,從而針對不同人群推送最能打動觀眾的劇照。
在Netflix公司,無論是內容平臺工程師團隊,還是全球產品創意團隊都知道,觀眾在尋找新的節目和電影觀看時,封面插圖扮演著非常重要的角色。我們可以透過封面插圖,揭示故事的獨特元素,而這些元素將我們的觀眾與不同的角色和故事線索聯系起來。我們為此感到很自豪。隨著我們的原創內容不斷增多,我們的技術專家的任務是尋找新的方式來處理不多擴展的資源,并使我們的創意可以擺脫不斷增長的令人厭煩的數字宣傳需求。其中的一個方法是直接從我們的源視頻中采集靜態圖像幀,以提供更加靈活的原始插圖來源。
商業案例
宣傳劇照是直接從源視頻內容中獲取的靜態視頻幀,用于擴大Netflix服務的標題范圍。在一個一小時的新劇集中,有近86,000個靜態視頻幀。
通常來說,這些宣傳劇照是由影片的策劃人或編輯人工選擇的,他們需要對打算呈現的源內容有深入的了解。通過A / B測試我們了解到,通過盡可能多地變換各種不同的標題,我們可以有效地推動預期和意外受眾群體進行更多地觀看。說到標題藝術,我們喜歡測試一個標題的許多藝術表現形式,以便為正確的觀眾找到“正確的”作品插圖。雖然這為創新和測試提供了一個令人興奮的機會,但它同時也提出了一個非常嚴峻的挑戰,即在我們不斷增長的全球內容目錄中的每個標題上實踐這種體驗。
AVA
AVA是一個工具和算法的集合,旨在從我們服務的視頻中提取高質量的圖像。平均一個電視節目(約10集)包含近900萬個總幀數。要求創意編輯們從許多視頻幀中有效篩選出來一個能夠吸引觀眾注意力的視頻幀是乏味并且缺乏效率的。我們著手構建了一個工具,能夠快速有效地識別Netflix服務上哪些幀能夠最佳地表達主題和標題。
為了實現這個目標,我們首先提出了客觀信號,它可以促使我們使用幀注解來衡量視頻的每一幀。因此,我們可以收集視頻的每個幀的有效表示。隨后,我們創建了排序算法,使我們能夠對符合審美、創意和多樣性目標的視頻幀子集進行排序,以準確地為我們產品的各種畫面呈現內容。
由AVA提供的備選圖像
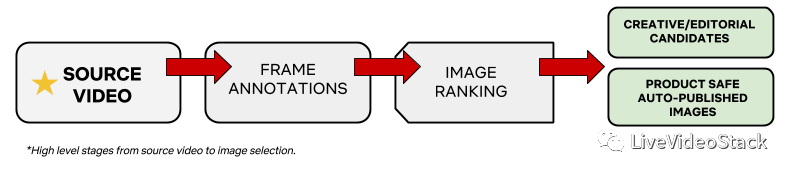
從源視頻到編輯備選圖像的高級階段
幀注解
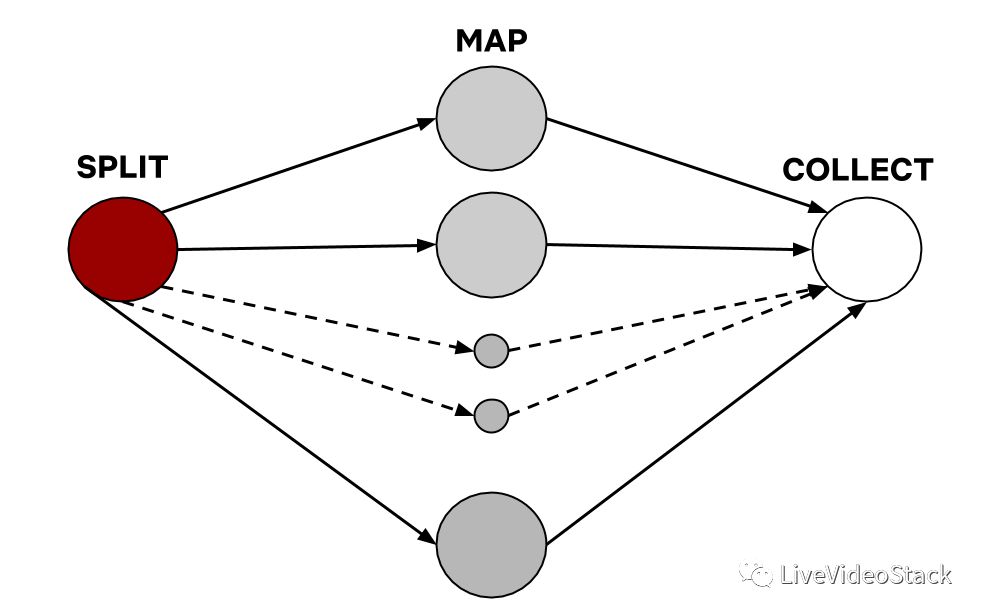
作為我們自動化流水線的一部分,我們在視頻的每個幀中都處理和注釋不同的變量,以便最好地得出幀的內容,并理解該幀對于故事是否重要。為了進行橫向擴展,并為不斷增長的內容目錄提供可預測的SLA,我們利用Archer框架更有效地處理視頻。Archer允許我們把視頻分成更小的可以并行處理的視頻塊。這使我們能夠通過提高視頻處理流水線的效率來擴展規模,并允許我們將越來越多的內容智能算法集成到我們的工具集中。
通過一系列計算機視覺算法處理一段內容中的每一幀視頻,以收集客觀幀元數據、幀的潛在表示,以及這些幀所包含的一些上下文元數據。我們處理和應用到視頻幀的注解屬性大致可以分為三大類:
視覺元數據
通常這些屬性是客觀的、可測量的,并且主要包含在像素級。視覺屬性包括亮度、顏色、對比度和運動模糊等等。
我們在幀級捕獲到的一些視覺屬性的例子。
上下文元數據
上下文元數據由多個元素的組合組成,這些元素被聚合以從幀的角色、對象和攝影機的動作或移動中獲得含義。下面是一些例子:
人臉識別。使用面部特征跟蹤、姿態估計和情感分析技術 —— 這使我們能夠估計該幀中主體的姿勢和情緒。
運動估計—— 這使我們能夠估計特定鏡頭中包含的運動量(包括攝影機運動和主體運動)。這使我們能夠控制諸如運動模糊之類的元素,以及識別產生高質量靜止圖像的攝影機移動。
攝影機拍攝識別—— (例如,近距離拍攝與移動攝影車拍攝)這提供了對電影攝影師意圖的洞察,使我們能夠快速識別并顯現出攝影師選擇的體裁風格,以提供對主題表達的情緒、基調和流派的更深入洞察。
對象檢測—— 道具和動畫對象的分割檢測使我們能夠找到該幀中重要的非人類主體。
面部特征和姿勢估計的例子; 我們用一些因子來檢測幀特征,發現有令人信服的面部表情出現。
用于預測攝影機運動的光流分析示例,以估計Black Mirror的拍攝手法(縮小和平移鏡頭)。
構圖元數據
構圖元數據是指我們根據攝影、電影拍攝和視覺美學設計中的一些核心原理確定和定義的一組特殊的啟發式特征。有一些構圖的基本原則:三分法原則、景深原則和對稱原則。
對象檢測和語義分割的例子,以識別三分法美學的前景對象。
圖像排名
在給定視頻中的每一幀都經過處理和注解后,下一步就是通過一個自動藝術品流水線從這些幀中選出最佳的候選圖像。這樣,當我們的創意團隊準備好開始一段內容的工作時,他們會自動提供一個高質量的圖像集供您選擇。下面,我們概述一些我們用來為給定標題提供最佳圖像的關鍵考慮元素。
演員
演員在藝術品中起著非常重要的作用。我們確定給定情節的關鍵角色的一種方法是利用臉部聚類和角色識別的組合來對主要角色,而不是次要角色或額外角色進行優先順序。為了達到這個目的,我們訓練了一個深度學習模型,從所有符合幀注解的候選幀中追蹤面部相似性,以找到并排序該標題的主要演員,而不知道該劇演員的任何情況。
除了演員重要性之外,我們還會考慮演員的姿勢,面部標志以及角色的整體位置。
Wynona Ryder出演Joyce Byers時的幀排名和最佳選擇范例。
由于次優的面部表情、姿勢和動作模糊而排名較低的圖像的示例
幀分類
創意和視覺分類是一個非常主觀的學科,因為有很多不同的方式來感知和定義圖像的多樣性。在該解決方案中,圖像分類更具體地指的是算法捕捉在單個電影或情節中自然發生的具有啟發式變化的能力。在此過程中,我們希望為設計師和創意人員提供一個可擴展的機制,以便快速了解哪些視覺元素最能代表主題,以及哪些元素無法準確代表主題。我們在AVA中引入的一些視覺啟發式變量為一個標題提供了不同的圖像集,包括攝影機鏡頭類型(遠景vs中景)、視覺相似性(三分法則,亮度,對比度)、顏色(最突出的顏色)和顯著圖(識別負面空間和復雜度)。通過結合這些啟發式變量,我們可以基于定制矢量對圖像幀進行有效聚類后再分類。此外,通過合并多個向量,我們能夠構建一個多樣性指數,針對某個特定情節或電影的所有候選圖像進行評分。
AVA的鏡頭檢測分集的例子; (左)中景,(中心)特寫,(右)極端特寫。
成人圖像過濾器
考慮到內容敏感度和受眾成熟度等原因,我們還需要確保排除了包含有害或令人反感元素的幀。編輯排除的標準示例,比如: 性/裸露、文字、標志/未經授權的品牌,以及暴力/血腥。為了降低含有這些元素的幀的優先級,我們將這些變量中的每一個的概率作為向量,使我們能夠量化并最終為這些幀賦予較低的分數。
我們還添加了標題流派,內容格式,成人度評分等元素作為次要元素或次要特征,并作為反饋,提供給排名預測模型。
-
算法
+關注
關注
23文章
4608瀏覽量
92844 -
甄別
+關注
關注
0文章
2瀏覽量
5390
原文標題:AVA:Netflix的劇照個性化甄選平臺
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
不銹鋼激光打標技術:讓產品標識更清晰、更持久

FLIR Ex Pro熱像儀的OTA無線更新技術
OTA無線更新技術:一鍵升級系統,隨時暢享FLIR最新技術!

當今數據中心新技術趨勢
示波器測量的是U13的輸出,輸出的波形不清晰是什么原因導致的?
揭秘能耗管理系統:如何讓你的建筑綠色又省錢?
采用ava+BS架構開發的工業級UWB室內定系統源碼UWB Ultra-Wideband定位系統技術接口及技術特點
凌度被評為高新技術企業,正式躋身國家高新技術企業隊伍!

北極芯微榮獲“國家高新技術企業”稱號

Type-C PD無線麥克風OTG讓聲音更清晰!!!LDR6028方案!
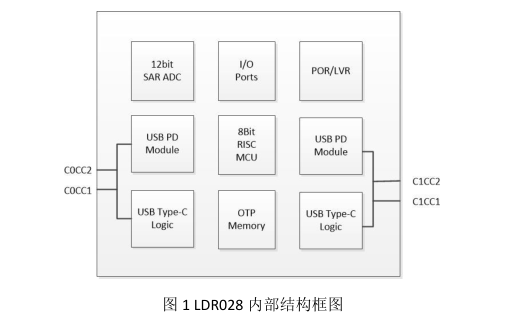
Type-C PD無線麥克風OTG讓聲音更清晰!!!LDR6028方案!
紫光展銳探索讓“夜空中最亮的星”清晰可見的Local Dimming技術
智芯傳感連續榮獲國家“高新技術企業”稱號

矽朋微無錫子公司榮獲“國家高新技術企業”認定!






 工商網監
工商網監
評論